41~44目标检测算法综述:R-CNN、SSD和YOLO
1. 区域卷积神经网络 (R-CNN 系列)
1.1 R-CNN
- 使用启发式搜索算法来选择锚框。
- 使用预训练模型对每个锚框提取特征(每个锚框视为一张图片,使用 CNN 提取特征)。
- 训练 SVM 进行类别分类(在神经网络之前进行)。
- 训练线性回归模型预测边界框偏移(bounding box prediction)。
- 利用兴趣区域(RoI)池化层:
- 给定一个锚框,均匀分割成 n x m 块,输出每块的最大值(max pooling)。
- 无论锚框大小,总是输出 n x m 个值。
- 目的是将每个锚框转换为固定形状。
python
# 提取特征
def extract_features(image, boxes, model):
features = []
for box in boxes:
cropped_image = image[box[1]:box[3], box[0]:box[2]]
resized_image = cv2.resize(cropped_image, (224, 224)) # 假设使用的是 224x224 的输入尺寸
feature = model.predict(resized_image)
features.append(feature)
return features
# 训练 SVM 分类器
svm = SVM()
svm.fit(features, labels)1.2 Fast R-CNN
- R-CNN 需要对每个锚框进行 CNN 运算,这些特征提取计算存在重复且计算量大。
- Fast R-CNN 改进了这种计算量大的问题:
- 使用 CNN 对整张图片提取特征(关键在于提高速度)。
- 使用 RoI 池化层对每个锚框(将在原图片中搜索到的锚框映射到 CNN 结果上)生成固定长度的特征。
python
# 使用整图进行特征提取
feature_map = cnn_model(image)
# RoI 池化层
roi_pooling = RoIPoolingLayer(pool_size=(7, 7), num_rois=num_rois)
pooled_features = roi_pooling([feature_map, rois])
1.3 Faster R-CNN
- 在 Fast R-CNN 的基础上进一步提速。
- 使用区域提议网络 (RPN) 取代启发式搜索以获得更好的锚框:
- 将 CNN 结果输入到卷积层,然后用锚框圈定区域,这些锚框很多有好有坏,然后进行预测。二元预测用于预测锚框的好坏,即是否有效圈住物体。bounding box prediction 用于对锚框进行改进,最后使用 NMS(非极大值抑制)对锚框进行合并。
具体步骤如下:
1. 使用 3x3 卷积层变换 CNN 输出,并将输出通道数记为 c。这样,CNN 为图像抽取的特征图中的每个单元均得到一个长度为 c 的新特征。
2. 以特征图的每个像素为中心,生成多个不同大小和宽高比的锚框并标注它们。
3. 使用锚框中心单元长度为 c 的特征,分别预测该锚框的二元类别(含目标或背景)和边界框。
4. 使用非极大值抑制,从预测类别为目标的预测边界框中移除相似结果。最终输出的预测边界框即是兴趣区域汇聚层所需的提议区域。
python
# RPN 网络
rpn_conv = Conv2D(512, (3, 3), padding='same', activation='relu')(base_layers)
rpn_class = Conv2D(num_anchors * 2, (1, 1), activation='softmax')(rpn_conv)
rpn_bbox = Conv2D(num_anchors * 4, (1, 1))(rpn_conv)
# 非极大值抑制
proposals = proposal_layer([rpn_class, rpn_bbox, anchors], num_proposals)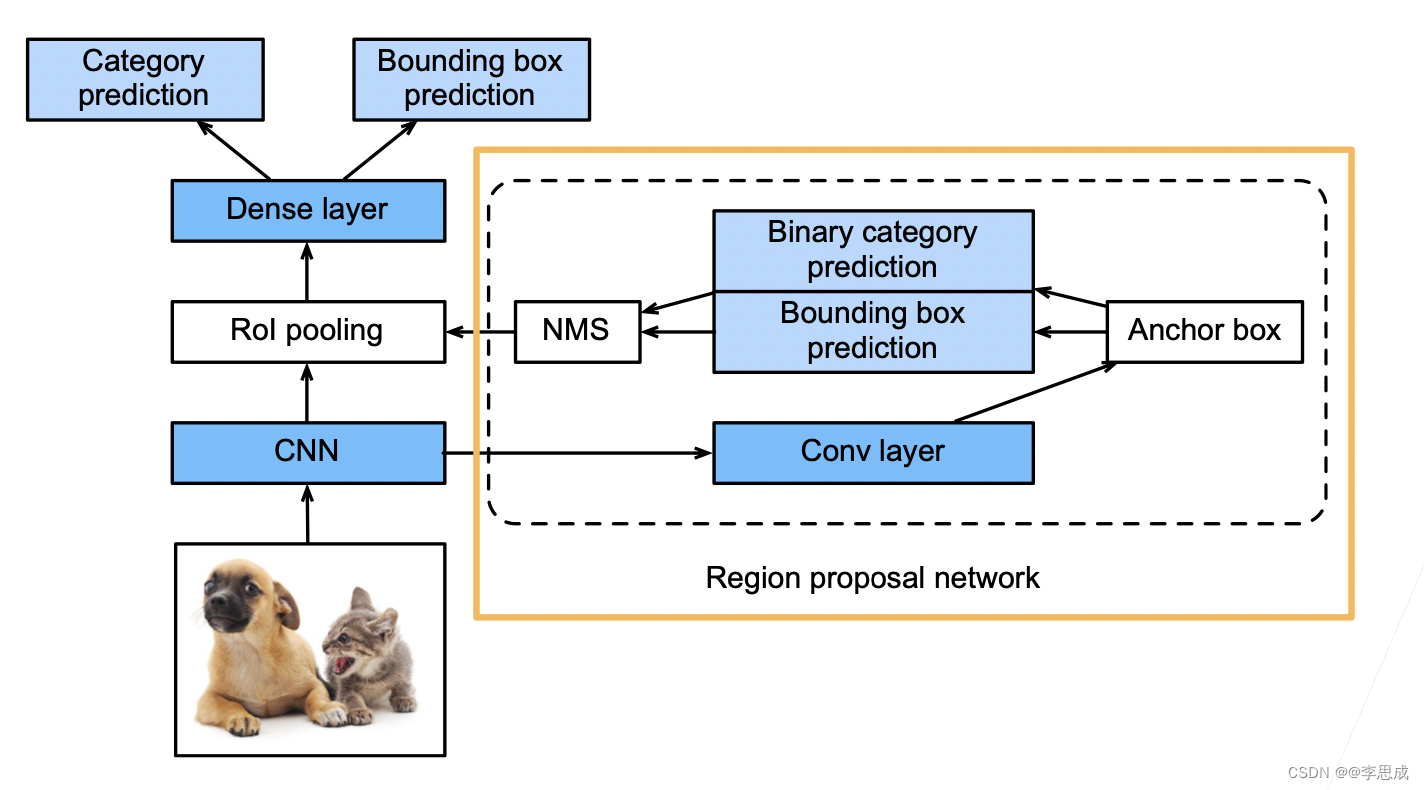
1.4 Mask R-CNN
- 如果有像素级别的标注,使用全卷积网络 (FCN) 利用这些信息可以提升性能。
- RoI 对齐 (RoI align):避免 RoI 池化中的取整误差,使用 RoI align 对每个像素值进行按比例分配。具体来说,Mask R-CNN 将兴趣区域汇聚层替换为兴趣区域对齐层,使用双线性插值保留特征图上的空间信息,适用于像素级预测。输出包含所有与兴趣区域形状相同的特征图,用于预测每个兴趣区域的类别和边界框,并通过额外的全卷积网络预测目标的像素级位置。
python
# RoI align
roi_align = RoiAlignLayer(pool_size=(14, 14), num_rois=num_rois)
aligned_features = roi_align([feature_map, rois])
# 全卷积网络
mask_conv1 = Conv2D(256, (3, 3), padding='same', activation='relu')(aligned_features)
mask_output = Conv2D(num_classes, (1, 1), activation='sigmoid')(mask_conv1)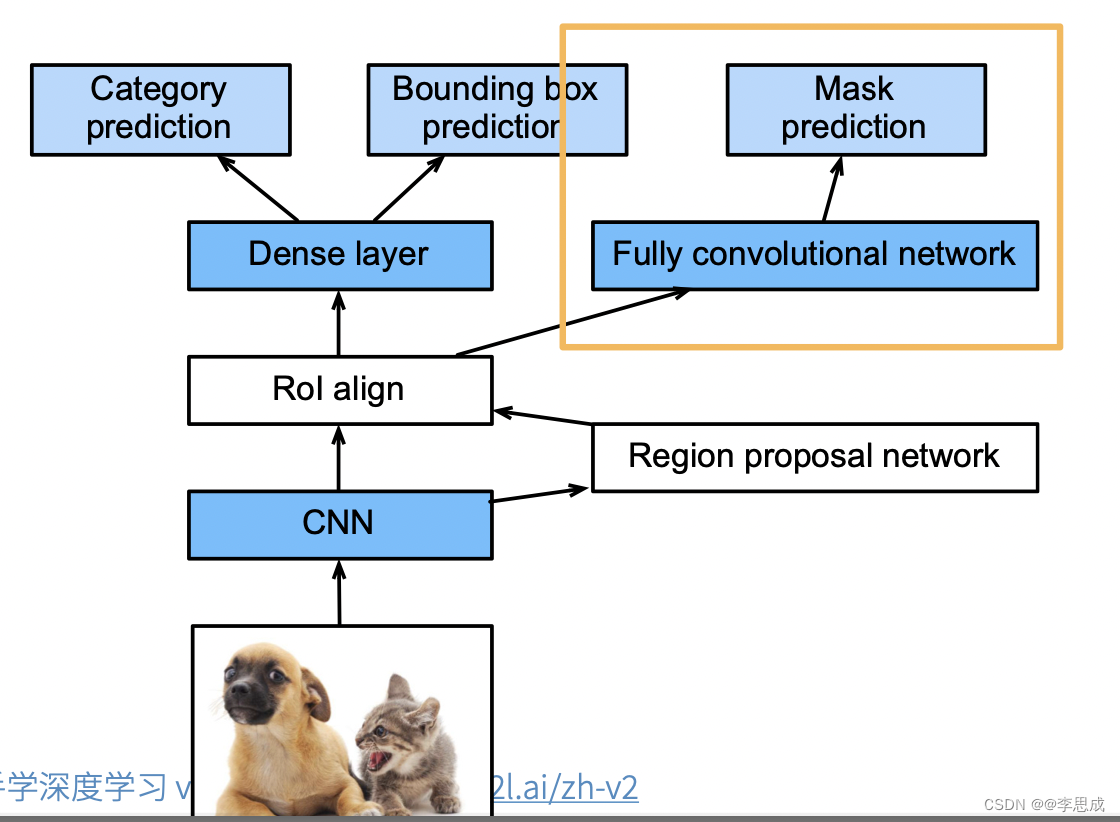
1.5 总结
- R-CNN 是最早也是最有名的一类基于锚框和 CNN 的目标检测算法。
- Fast R-CNN 和 Faster R-CNN 持续提升性能。
- Faster R-CNN 和 Mask R-CNN 常用于高精度要求的场景,但速度相对较慢。
2. 单发多框检测 (SSD)
- 生成锚框:
- 对每个像素生成多个以其为中心的锚框。
- 给定 n 个大小 s 1 , . . . , s n s_1,...,s_n s1,...,sn和m个高宽比,生成n+m-1个锚框,其大小和高宽比分别为: ( s 1 , r 1 ) , ( s 2 , r 1 ) . . . , ( s n , r 1 ) , ( s 1 , r 2 ) , . . . , ( s 1 , r m ) (s_1,r_1),(s_2,r_1)...,(s_n,r_1),(s_1,r_2),...,(s_1,r_m) (s1,r1),(s2,r1)...,(sn,r1),(s1,r2),...,(s1,rm)
- SSD 模型:
- 对多个分辨率下的卷积特征生成锚框并进行预测。
- 使用一个基础网络提取特征,然后用多个卷积层来减半高宽。
- 在每个层生成锚框:
- 底部层拟合小物体。
- 顶部层拟合大物体。
- 对每个锚框预测类别和边界框。
python
# 锚框生成
def generate_anchors(feature_map_shape, scales, ratios):
anchors = []
for scale in scales:
for ratio in ratios:
width = scale * np.sqrt(ratio)
height = scale / np.sqrt(ratio)
for i in range(feature_map_shape[0]):
for j in range(feature_map_shape[1]):
center_x = (j + 0.5) / feature_map_shape[1]
center_y = (i + 0.5) / feature_map_shape[0]
anchors.append([center_x, center_y, width, height])
return np.array(anchors)
# SSD 网络
base_model = SSDBaseNetwork(input_shape=(300, 300, 3))
feature_maps = base_model.extract_features(image)
for feature_map in feature_maps:
anchors = generate_anchors(feature_map.shape, scales, ratios)
predictions = predict_bboxes_and_classes(feature_map, anchors)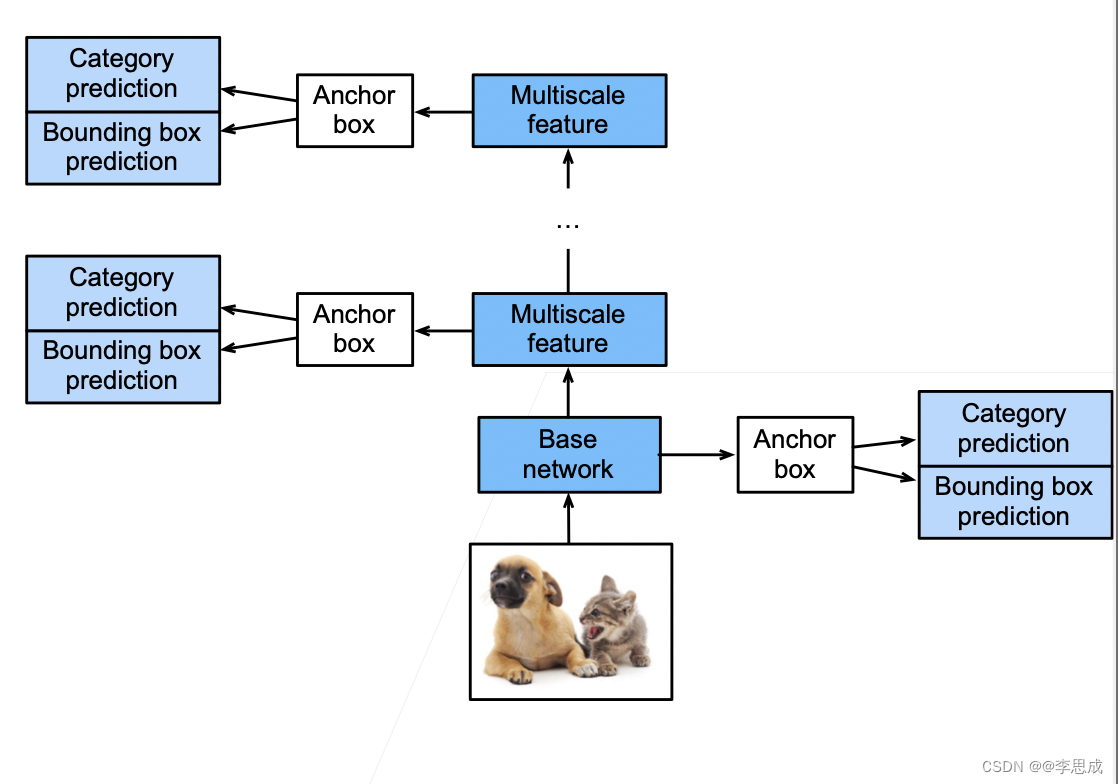
总结
- 速度快但精度较低。虽然作者没有持续提升,但 SSD 启发了一系列后续工作,实现上相对简单。
- SSD 通过单神经网络进行检测(single shot)。
- 以像素为中心产生多个锚框,在多个层的输出上进行多尺度检测。
3. YOLO (You Only Look Once)
- SSD 中锚框大量重复,浪费计算资源。
- YOLO 将图片均分为 S x S 个网格。
- 每个网格预测 B 个边界框(防止多个物体出现在一个网格内)。
- 后续版本 YOLOv2、YOLOv3 和 YOLOv4 持续改进,非锚框算法。
python
# YOLO 网络
def yolo_model(input_shape, num_classes, num_bboxes):
inputs = Input(shape=input_shape)
x = Conv2D(32, (3, 3), padding='same', activation='relu')(inputs)
x = MaxPooling2D(pool_size=(2, 2))(x)
# 添加更多卷积和池化层
x = Flatten()(x)
x = Dense(4096, activation='relu')(x)
outputs = Dense(S * S * (num_classes + 5 * num_bboxes), activation='sigmoid')(x)
model = Model(inputs, outputs)
return model
# 预测
yolo = yolo_model((448, 448, 3), num_classes, num_bboxes)
predictions = yolo