
字节数据分析发展过程中所遭遇的挑战
三个核心议题:
- 海量数据分析性能:会议指出Spark分析性能不足成为了一个显著问题,尤其是在需要毫秒级响应的业务场景中。
- 实时导入与查询能力:目前Kylin只能以T+1的形式提供分析服务,无法实时查询新入库数据,且数据导入速度的高要求也加剧了这一挑战。
- 新业务开发的便捷性:宽表开发需要一定时间,限制了业务的快速调整和维度增加。
旨在找到解决方案以支持更多业务发展,并满足高效数据分析的需求。


字节跳动在数据分析发展过程中遇到的挑战
面临的主要挑战是数据量的急剧增长,这导致集群的弹性和可用性成为了一个重要问题。具体来说,存算一体的架构难以跟随业务的快速伸缩和扩容,硬件成本高昂,计算和存储资源存在冗余现象。此外,运维压力也显著增加,包括Zookeeper的承压、磁盘损坏以及大查询的处理等问题。
在字节内部,拥有庞大的节点总数(18,000个),最大集群规模达到2,400个,数据量高达700PB,每日查询量更是达到了惊人的1.2亿次。这些数字凸显了在数据分析领域所面临的巨大挑战。
为了应对这些挑战,字节需要深入探讨并寻找有效的解决方案,以确保数据分析的准确性和效率,同时降低运维成本和风险。
云时代数据仓库的关键要求,涵盖了资源高效利用、数据安全、读写性能以及集群架构等方面
- 强调了资源高效利用的重要性,指出只有高效利用资源,才能实现成本和查询体验的最优平衡。例如,10核计算10秒与100核计算1秒的资源成本相同,但用户体验存在显著差异。此外,还提到了集群资源应能快速响应业务变更,以及存储和计算解耦,甚至对存储进行冷热分层,以进一步提高资源利用效率。
- 其次,会议还强调了资源隔离和多租户的重要性,以避免业务间资源抢占,确保数据安全。数据安全是数据仓库不可或缺的一部分,必须得到充分的重视和保障。
- 还讨论了读写数据库性能的影响,指出应尽可能降低读写操作对系统性能的影响,确保数据仓库的稳定性和高效性。
深入探讨了云时代数据仓库的关键要求,旨在通过优化资源使用效率、确保数据安全和隔离、提高读写性能等方面,为数据仓库的建设和运营提供有力支持。
ByConity如何解决一系列技术难题。
首先,服务层 (Cloud Service)包含了元数据管理 (FoundationDB)、服务器服务 以及资源管理器等核心组件,这些组件共同构成了ByConity系统的服务框架。
在计算组(Virtual Warehouse, VW)部分,ByConity利用TSO来确保数据的一致性和准确性,同时通过Daemon Manager进行任务的调度和管理。
存储层(Cloud Storage)方面,ByConity通过Worker节点执行数据的读写操作,并利用Local Disk Cache来提升数据访问的效率。此外,每个表都可以设定默认的Read VW和Write VW,以满足不同的数据处理需求。
特别是,ByConity的虚拟仓库部分包含了负责数据读取和写入的Read Worker和Write Worker,这些Worker节点通过数据缓存和数据缓冲区来优化数据处理的性能。
最后,ByConity还支持包括HDFS和S3在内的多种云存储选项,为用户提供了灵活的存储方案选择。整个会议通过技术架构图详细展示了ByConity的各个组成部分及其协同工作方式,帮助与会者更好地理解了ByConity如何解决技术难题并提升系统的可靠性和性能。
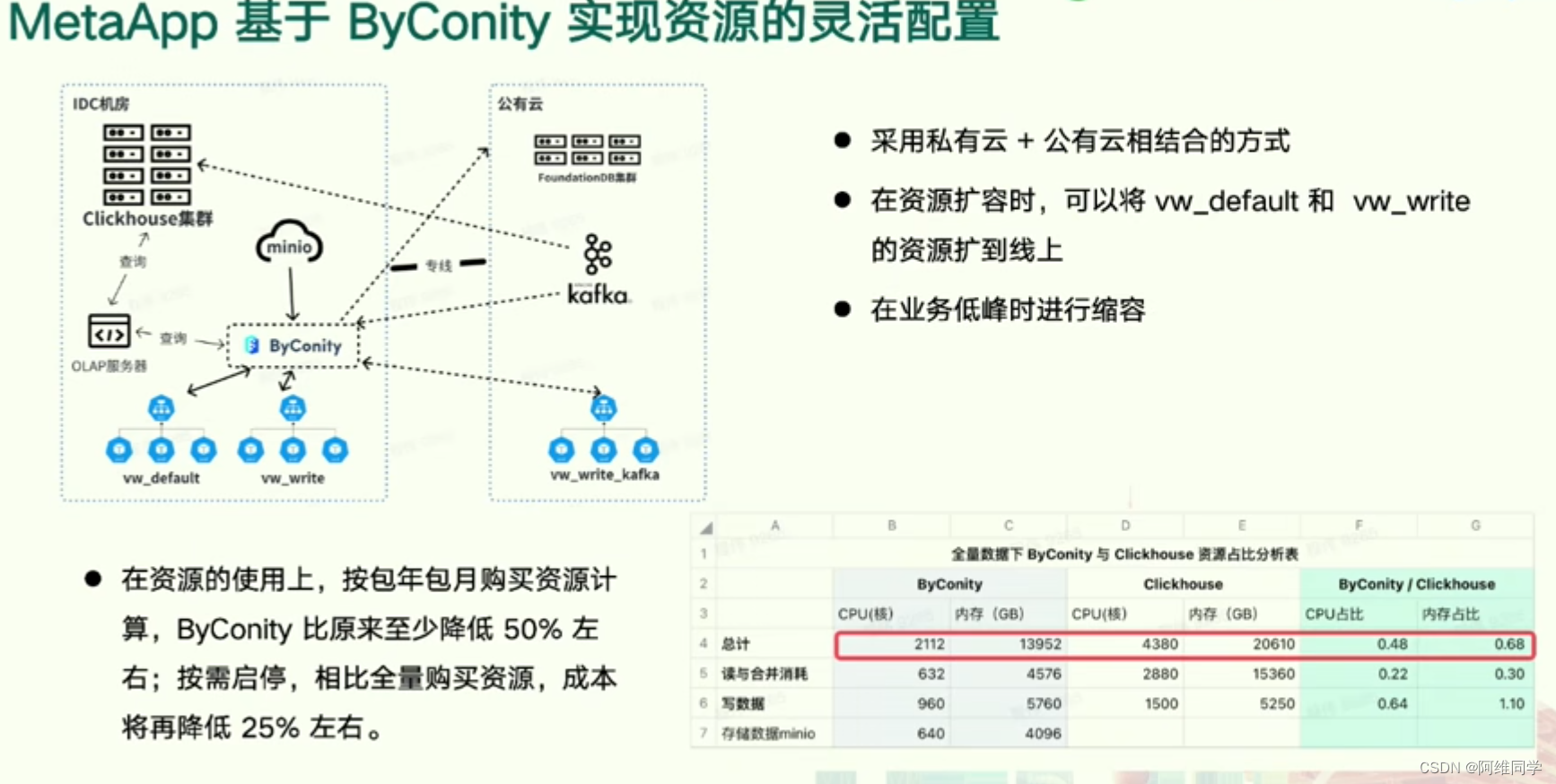
MetaApp通过ByConity实现了资源的灵活配置,主要策略包括结合私有云和公有云的使用,以及在需要时快速将vw_default和vw_write的资源扩展到线上,同时在业务低峰期进行资源缩容。这种配置方式显著降低了资源成本,按包年包月购买资源计算,ByConity相比传统方式至少降低了50%的成本,而按需启停的策略则能进一步降低约25%的成本。
图表详细展示了全量数据下ByConity与Clickhouse的资源占比情况。从数据中可以看出,ByConity在CPU和内存的使用效率上均优于Clickhouse,CPU使用率ByConity为0.48,而Clickhouse为0.68;内存使用率ByConity为0.64,Clickhouse则高达1.10。此外,系统还采用了Kafka作为消息队列,以减少数据库查询次数,并通过将计算任务拆分成多个小任务来提高处理速度,进一步提升了整体性能。
ByConity开源、协同的云原生数据仓库在2023年5月至2024年6月期间取得了显著成果。在此期间,我们迎来了2057位Star用户,并收到了503个Issue(问题报告),同时我们的贡献者团队也积极投入,贡献了30+的Pull Requests(PR)。此外,我们成功发布了1202次更新,并发表了72篇相关文章。这些成果不仅体现了我们团队的辛勤工作和卓越能力,也进一步巩固了ByConity在云原生数据仓库领域的领先地位。同时,我们的影响力也在不断扩大,获得了20+的积极反馈和认可。
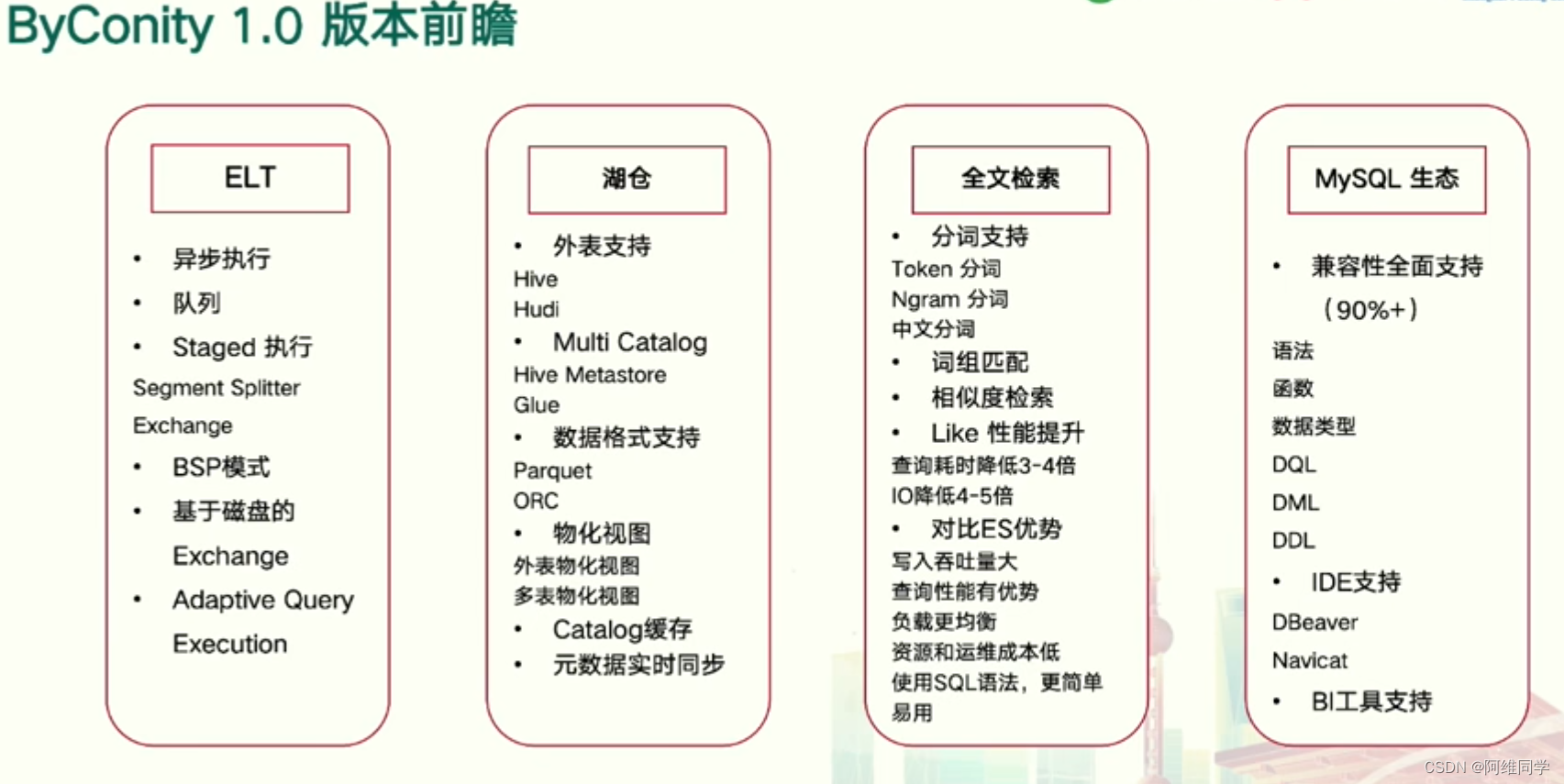
ByConity 1.0版本在数据库管理系统(DBMS)领域
内容涵盖了ELT数据流处理、湖仓存储、全文检索优化以及MySQL生态的兼容性等多个方面,展示了该版本的功能与优势,旨在满足用户在数据处理、存储、检索及生态兼容性的需求。
展示了ByConity 1.0版本在数据库管理系统(DBMS)领域的全面前瞻内容,涵盖了ELT数据流处理、湖仓存储、全文检索优化以及MySQL生态的兼容性等多个方面。
在ELT部分,ByConity 1.0提供了异步执行、队列管理、Staged执行、Segment Splitter等高级功能,确保数据流的高效处理。同时,通过Exchange和BSP模式,系统能够灵活应对各种数据处理需求,并通过基于磁盘的Exchange和Adaptive Query Execution技术,实现查询性能的优化。
湖仓部分则强调了外表支持,包括Hive、Hudi等工具的集成,以及Multi Catalog和Hive Metastore的支持,为数据存储提供了丰富的选择。此外,系统还支持Parquet、ORC等数据格式,并通过物化视图、多表物化视图等技术,进一步提升了数据访问的效率和灵活性。Catalog缓存和元数据实时同步功能,则确保了数据的一致性和可靠性。
在全文检索方面,ByConity 1.0提供了分词支持、词组匹配、相似度检索等高级功能,支持Token分词、Ngram分词和中文分词等多种分词方式,使得文本搜索更加精准高效。同时,系统还通过Like性能提升、查询耗时降低等技术,进一步提升了全文检索的性能。
在MySQL生态方面,ByConity 1.0提供了全面的兼容性支持,包括语法、函数和数据类型等方面的支持。此外,系统还支持多种IDE工具,如DBeaver、Navicat等,以及BI工具的支持,使得用户能够更加方便地使用和管理数据库。
感谢持续关注阿维同学
VX:AWTX550W
