为什么要用MongoDB
两个关键:灵活性和横向扩展能力
- MongoDB是灵活的文档模型,也就是说,如果预计我的数据可以被一个稳定的模型来描述,会倾向于使用MySQL等关系型数据库。而一旦我认为我的数据模型会经常变动,比如我很难预料到用户会输入什么数据,这种情况下更加倾向于使用MongoDB。
- MongoDB更容易进行横向扩展。虽然关系型数据库也可以通过分库分表来达成横向扩展的目标,但是扩展和运维都比MongoDB要困难复杂的多,而这一切在MongoDB里都是自动的,你基本上不需要操心。
MongoDB的分片机制
当下,跟数据存储和检索有关的中间件基本上都会支持分片,或者步入分布式时代后诞生的中间件,基本都会考虑分片机制。
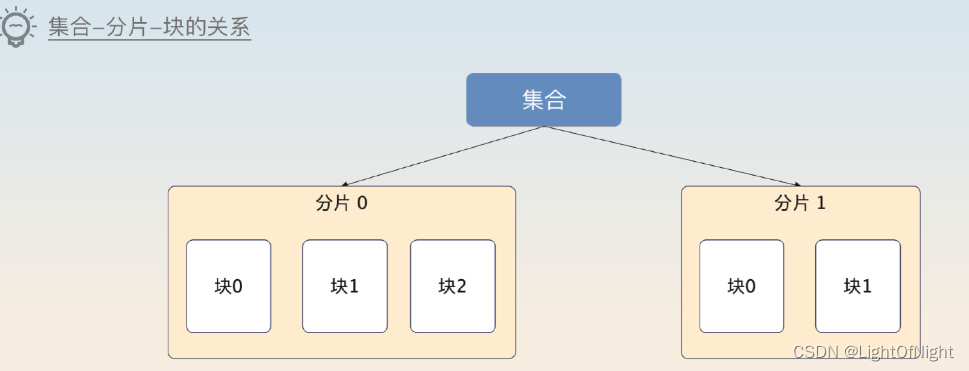
在MongoDB里,可以使用所谓的分片集合(collection)。每一个分片集合都被分成若干个分片,如果按照关系型数据库分库分表的说法,那么集合就是逻辑表,分片就是物理表。每个分片又由多个块(chunk)组成,在最新版本的默认情况下,一个块的大小是128MB
如果一个块满足了下面的任何一个条件,就会被拆分成两个块,简单来说就是数据太多或文档太多:
- 数据过多:默认一个块是128MB,但是这个块上放的数据超过了128MB,就会被拆分
- 文档太多:阈值是平均每个块包含的文档数量的1.3背,也就是,如果平均每个块可以放1000个文档,但是当前块上放了超过1300个文档,这个块也会被切分

在分库分表里,经常会遇到的一个问题是,不同表之间的数据并不均衡,有的多有的少。所以这就要求在设计分库分表方案的时候,要尽可能准确预估每一个物理表的数据,确保均衡。
在MongoDB里,会自动平衡不同分片的数据,尽量做到每个分片都有差不多的数据量,整个机制也叫做负载均衡。只不过一般意义上的负载均衡强调的是流量负载均衡,而这里强调的是数据量负载均衡。
而发现数据不均匀之后,迁移数据的过程也叫做再平衡,本质上就是挪动块。
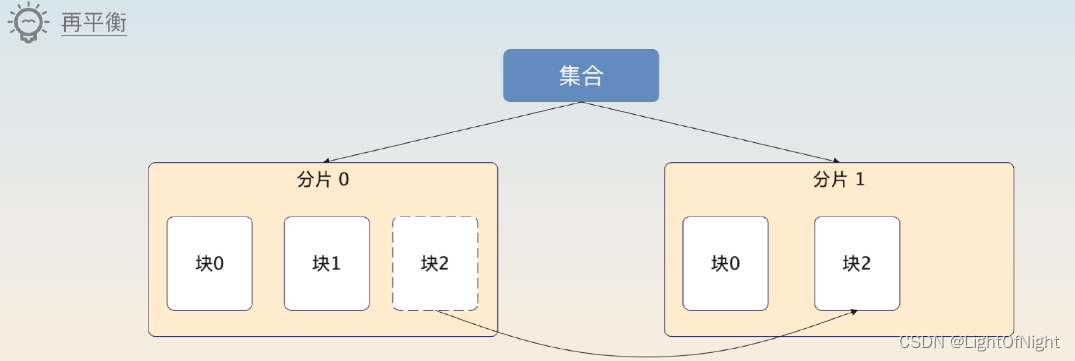
什么时候才会触发再平衡过程呢?MongoDB设定了一些阈值,超过了这个阈值就会触发再平衡的过程,具体的阈值表如下:
| 块数量 | 阈值 |
|---|---|
| 少于20 | 2 |
| 20~79 | 4 |
| 大于等于80 | 8 |
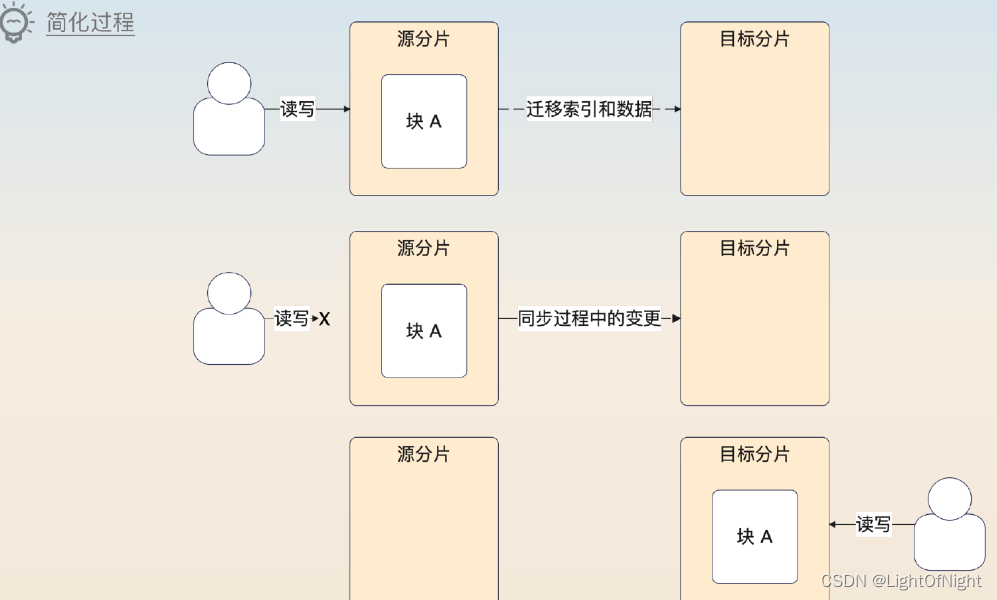
举个例子,如果一个集合里面最大的分片有9个块,最少的集合有7个块,就会触发再平衡。假设我们要迁移块A,过程如下:
- 平衡器发送moveChunk命令到源分片上
- 源分片执行moveChunk命令,这个时候读写块A的操作都是源分片来负责的
- 目标分片创建对应的索引
- 目标分片同步块A的数据
- 当块A最后一个文档都同步给目标分片后,目标分片会启动一个同步过程,把迁移过程中的数据变更也同步过来。
- 整个数据同步完成之后,源分片更新元数据,告知块A已经迁移到了目标分片
- 当源分片上的游标都关闭后,他就可以删除块A了。
整个过程和别的中间件的数据迁移过程都差不多