SCI一区 | Matlab实现DBO-TCN-LSTM-Attention多变量时间序列预测
目录
预测效果
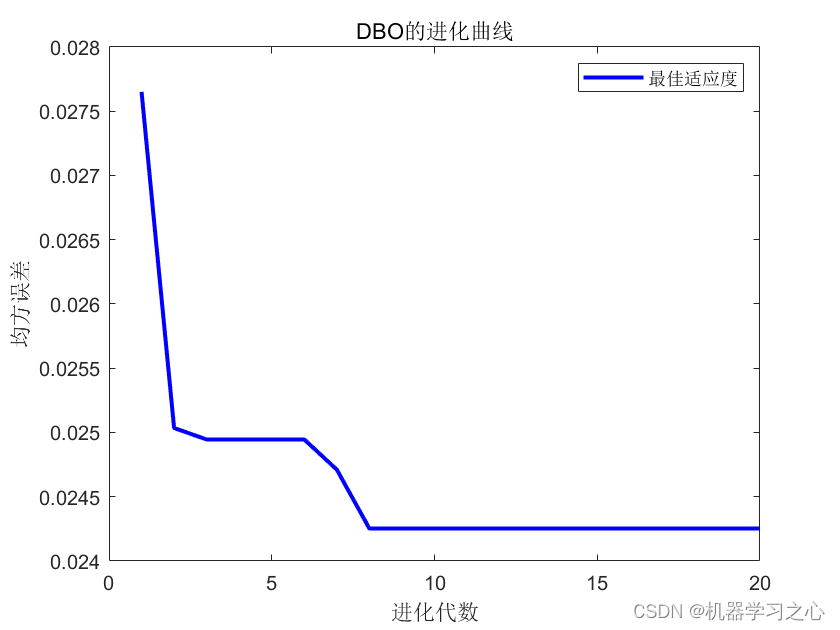
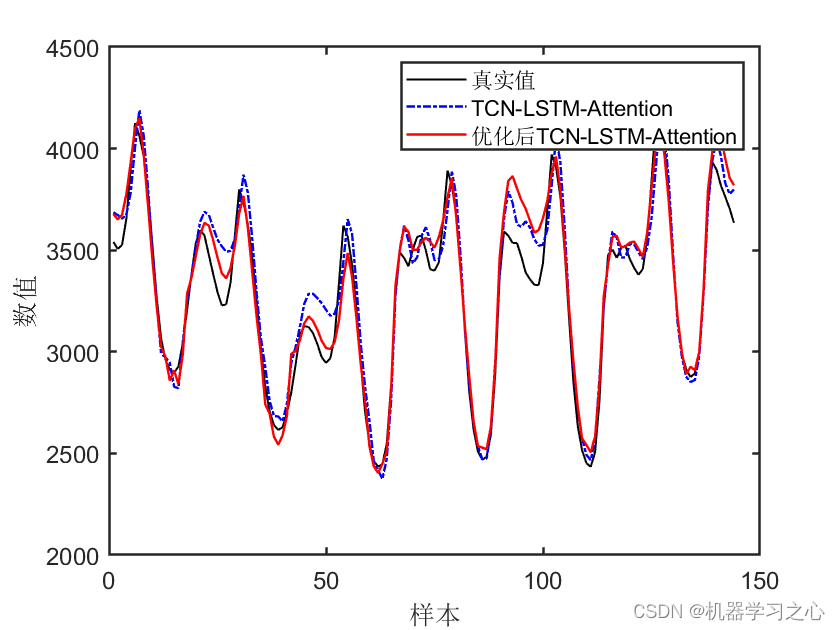
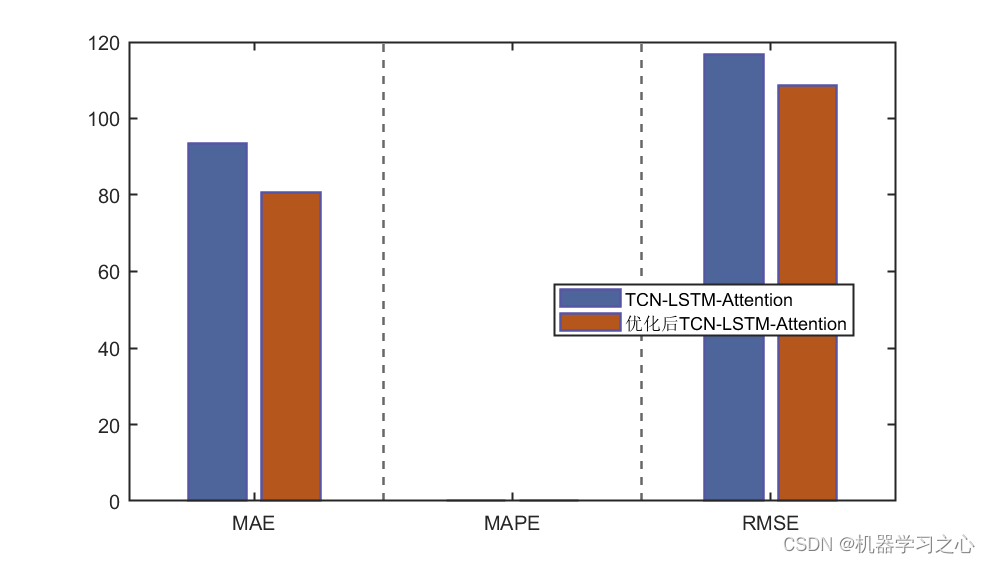
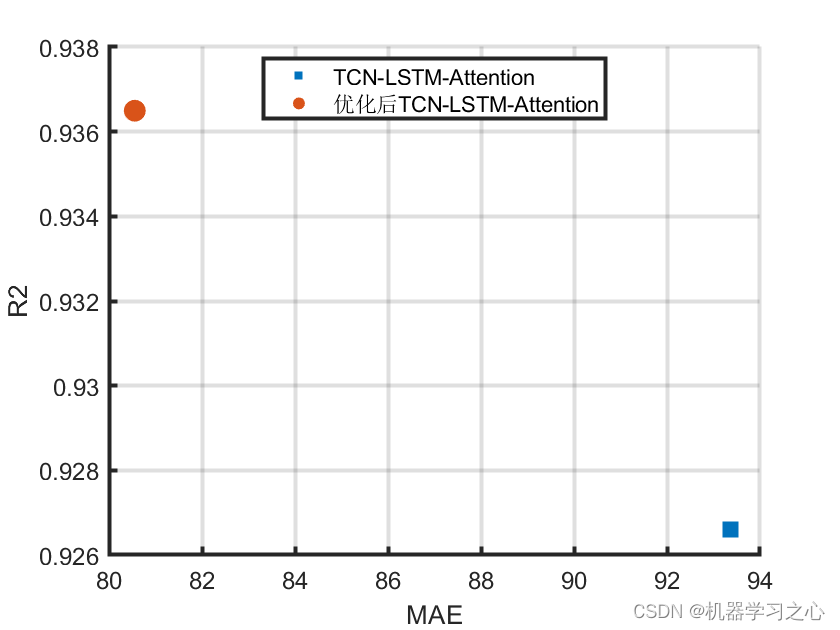
基本介绍
1.【SCI一区级】Matlab实现DBO-TCN-LSTM-Attention多变量时间序列预测(程序可以作为SCI一区级论文代码支撑);
2.基于DBO-TCN-LSTM-Attention蜣螂算法优化时间卷积长短期记忆神经网络融合注意力机制多变量时间序列预测,要求Matlab2023版以上,自注意力机制,一键单头注意力机制替换成多头注意力机制;
3.输入多个特征,输出单个变量,考虑历史特征的影响,多变量时间序列预测;
4.data为数据集,main.m为主程序,运行即可,所有文件放在一个文件夹;
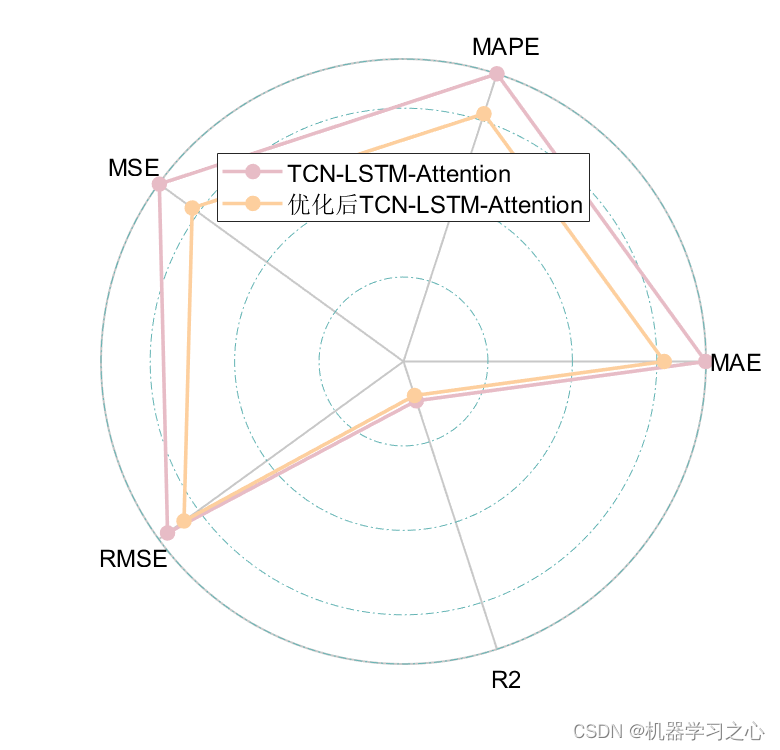
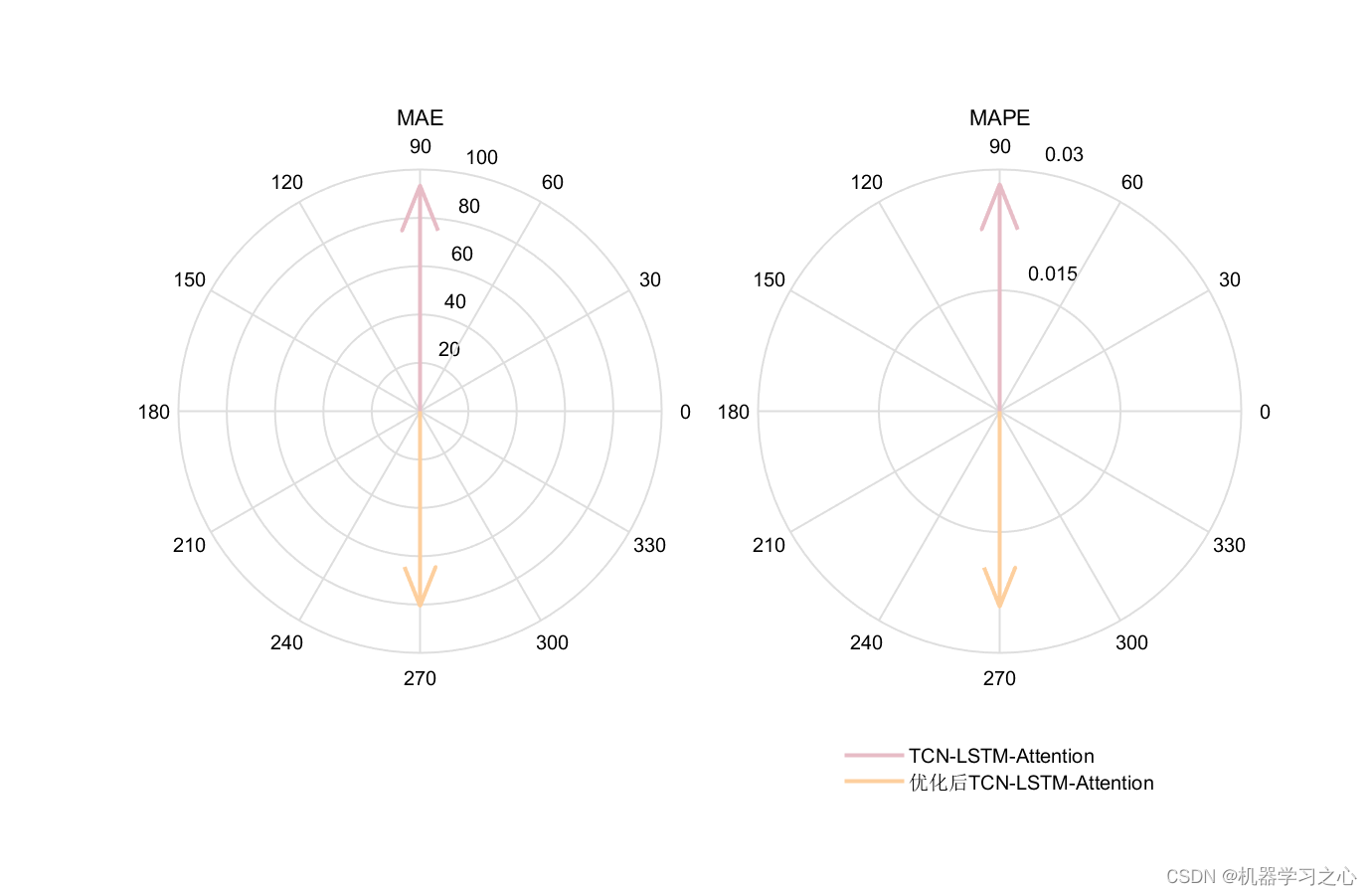
5.命令窗口输出R2、MSE、MAE、MAPE和RMSE多指标评价;
6.优化学习率,神经元个数,注意力机制的键值, 正则化参数。
程序设计
- 完整源码和数据获取方式私信博主回复Matlab实现DBO-TCN-LSTM-Attention多变量时间序列预测。
clike
%% DBO算法优化TCN-LSTM-Attention,实现多变量输入单步预测
clc;
clear
close all
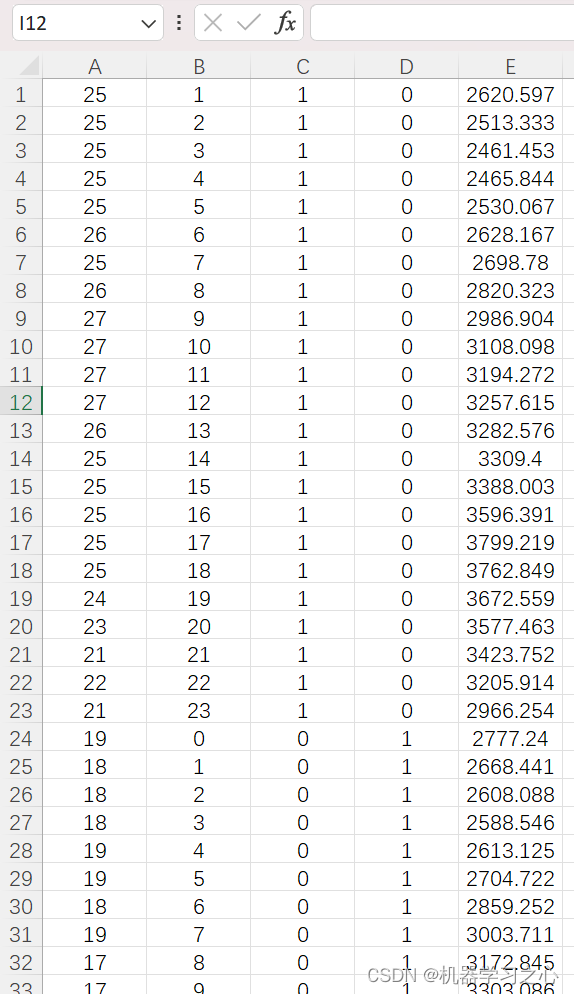
X = xlsread('data.xlsx');
num_samples = length(X); % 样本个数
kim = 6; % 延时步长(kim个历史数据作为自变量)
zim = 1; % 跨zim个时间点进行预测
or_dim = size(X,2);
% 重构数据集
for i = 1: num_samples - kim - zim + 1
res(i, :) = [reshape(X(i: i + kim - 1,:), 1, kim*or_dim), X(i + kim + zim - 1,:)];
end
% 训练集和测试集划分
outdim = 1; % 最后一列为输出
num_size = 0.9; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
% 格式转换
for i = 1 : M
vp_train{i, 1} = p_train(:, i);
vt_train{i, 1} = t_train(:, i);
end
for i = 1 : N
vp_test{i, 1} = p_test(:, i);
vt_test{i, 1} = t_test(:, i);
end参考资料
1 https://blog.csdn.net/kjm13182345320/article/details/128577926?spm=1001.2014.3001.5501
2 https://blog.csdn.net/kjm13182345320/article/details/128573597?spm=1001.2014.3001.5501