2024年6月25日,10:11,好几天没看论文了,一直在摸鱼写代码(虽然也没学会多少),今天看一篇师兄推荐的。
论文:Soft Contrastive Learning for Time Series
或者是:Soft Contrastive Learning for Time Series
GitHub:https://github.com/seunghan96/softclt
ICLR 2024的论文。
(从这篇开始,pretext task翻译为代理任务,更专业一点,也符合训练模型的辅助任务的意思.)
摘要
对比学习已被证明能有效地以自监督的方式从时间序列中学习表征。然而,对比相似的时间序列实例或时间序列中相邻时间戳的值会忽略其内在的相关性,从而导致学习到的表征质量下降。 (是的!我也是这么想的,呜呜呜,但是我没想到作者是在实例数据上直接操作的)为了解决这个问题,我们提出了 SoftCLT,这是一种简单而有效的时间序列软对比学习策略。这是通过引入从 0 到 1 的软赋值的实例和时间对比损失来实现的。具体来说,我们通过数据空间中时间序列之间的距离来定义 **1) 实例对比损失的软赋值,以及 2) 时间对比损失的软赋值,即时间戳的差值。**SoftCLT 是一种即插即用的时间序列对比学习方法,它能提高所学表征的质量,而不需要任何附加功能。在实验中,我们证明了 SoftCLT 能够持续提高分类、半监督学习、迁移学习和异常检测等各种下游任务的性能,显示出最先进的性能。代码可从该资源库获取:https://github. com/seunghan96/softclt。
1 引言
时间序列(TS)数据在金融、能源、医疗保健和交通等许多领域无处不在(Ding 等人,2020 年;Lago 等人,2018 年;Solares 等人,2020 年;Cai 等人,2020 年)。然而,对 TS 数据进行注释可能具有挑战性,因为这通常需要大量的领域专业知识和时间。为了克服这一限制并利用无标注数据,自监督学习不仅在自然语言处理(Devlin 等人,2018 年;Gao 等人,2021 年)和计算机视觉(Chen 等人,2020 年;Dosovitskiy 等人,2021 年)中,而且在 TS 分析(Franceschi 等人,2019 年;Yue 等人,2022 年)中,都已成为一种前景广阔的表征学习方法。尤其是对比学习(CL)在不同领域都表现出了卓越的性能(Chen 等人,2020 年;Gao 等人,2021 年;Yue 等人,2022 年)。由于在自监督学习中确定实例的相似性具有挑战性,最近的对比学习工作应用了数据增强技术,为每个数据生成两个视图,并将来自同一实例的视图作为正对视图,将其他视图作为负对视图(陈等,2020)。然而,我们认为标准的CL目标可能对TS表示学习有害,因为在CL中忽略了TS中类似TS实例和时间戳附近值的固有相关性,而这种相关性可能是一种强大的自我监督。例如,动态时间扭曲(DTW)等距离指标已被广泛用于测量 TS 数据的相似性,而对比 TS 数据可能会丢失此类信息。此外,在自然 TS 数据中,时间戳相近的值通常是相似的,因此像以前的 CL 方法(Eldele 等人,2021 年;Yue 等人,2022 年)那样对所有时间戳不同的值进行同等程度的惩罚对比可能不是最优的 。(是这样的,这也是个问题)受此启发,我们探讨了以下研究问题:如何考虑时间序列数据的相似性,以更好地进行对比表示学习?为此,我们提出了时间序列软对比学习(SoftCLT)。具体来说,我们建议**不仅考虑正对的 InfoNCE 损失(Oord 等人,2018 年),还要考虑所有其他对的 InfoNCE 损失,并在实例性 CL 和时间性 CL 中计算其加权求和,其中实例性 CL 对比的是 TS 实例的表征,而时间性 CL 对比的是单个 TS 中时间戳的表征,**如图 1 所示。我们建议在实例性 CL 中根据 TS 之间的距离进行软分配,在时间性 CL 中根据时间戳的差异进行软分配。如果我们将软分配替换为硬分配(负为 0 或正为 1),那么提出的损失就变成了对比损失。
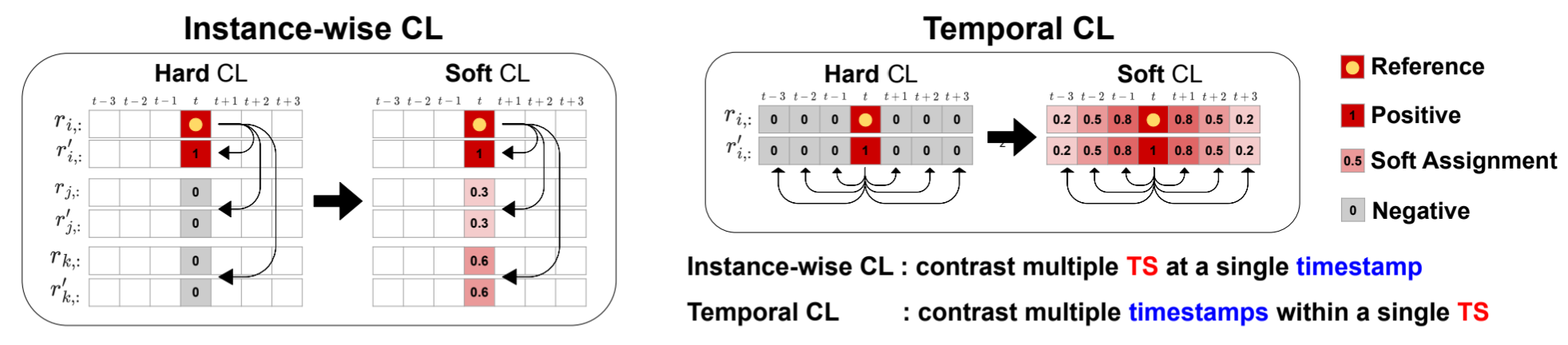
图 1:SoftCLT 的整体框架。传统的硬式 CLT 对样本对给出正或负的赋值,与之不同的是,SoftCLT 对实例关系和时间关系都给出了软赋值。同一样本的两个视图分别表示为 r 和 r˜。
我们在各种任务中进行了广泛的实验,包括 TS 分类、半监督分类、迁移学习和异常检测任务,以证明所提方法的有效性。实验结果验证了我们的方法提高了之前 CL 方法的性能,在一系列下游任务中达到了最先进(SOTA)的性能。本文的主要贡献概述如下:
-
我们提出了用于 TS 的简单而有效的软对比学习策略 SoftCLT。具体来说,我们分别针对实例维度和时间维度提出了软对比损失,以解决以往用于 TS 的 CL 方法的局限性。
-
我们提供了针对 TS 的各种任务的大量实验结果,表明我们的方法提高了 SOTA 在一系列下游任务中的性能。例如,与分类任务的 SOTA 无监督表示法相比,SoftCLT 将 125 个 UCR 数据集和 29 个 UEA 数据集的平均准确率分别提高了 2.0% 和 3.9%。
-
通过引入软赋值,SoftCLT 很容易应用于其他 TS CL 框架,而且其开销可以忽略不计,因此非常实用。
(乱七八糟的事情有点多,明天再看.)
(现在是6月26日,10:32,继续看.)
(呜呜呜,我工位的这个破抽屉又坏了,第一层关不上,下面两层打不开锁上了,哈哈哈哈哈哈,麻了,又找师兄给我修,师兄给我修了无数次了(让师兄看到了我爆满的抽屉,哈哈哈哈).)
2 相关工作
自监督学习。 近年来,自监督学习(self-supervised learning)因其能够从大量无标记数据中学习到强大的表征而备受关注。自监督学习是在没有监督的情况下,通过训练一个模型来解决从数据的某一方面衍生出来的代理任务。作为自监督代理任务,下一个标记预测(Brown 等人,2020 年)和掩码标记预测(Devlin 等人,2018 年)常用于自然语言处理中,而解决拼图游戏(Noroozi & Favaro,2016 年)和旋转预测(Gidaris & Komodakis,2018 年)则是在计算机视觉中提出的。其中,对比学习(Hadsell 等人,2006 年)已被证明是跨领域的有效代理任务,它能最大化正对的相似性,同时最小化负对的相似性(Gao 等人,2021 年;Chen 等人,2020 年;Yue 等人,2022 年)。
**时间序列中的对比学习。**在时间序列分析领域,考虑到时间序列的不变特性,已经提出了几种正对和负对的对比学习设计。表 1 比较了包括我们在内的各种 TS 对比学习方法的若干特性。T-Loss(Franceschi 等人,2019 年)从一个 TS 中随机抽样一个子序列,如果属于该 TS 的子序列,则将其视为正序列;如果属于其他 TS 的子序列,则将其视为负序列。Self-Time(Fan 等人,2020 年)通过将同一 TS 的增强样本定义为正样本和负样本来捕捉 TS 之间的样本间关系,并通过解决分类任务来捕捉 TS 内部的时间关系,其中类标签使用子序列之间的时间距离来定义。TNC(Tonekaboni 等人,2021 年)使用正态分布定义窗口的时间邻域,并将邻域内的样本视为正样本。TS-SD(Shi 等人,2021 年)使用三元组相似性判别任务训练模型,目标是识别两个 TS 中哪个与给定的 TS 更相似,使用 DTW 来定义相似性。TS-TCC(Eldele 等人,2021 年)提出了一种时间对比损失,即让增强预测彼此的未来,而 CA-TCC(Eldele 等人,2023 年)是 TS-TCC 在半监督设置下的扩展,采用了相同的损失。TS2Vec(Yue 等人,2022 年)将 TS 分成两个子序列,并在实例和时间维度上定义了分层对比损失。Mixing-up(Wickstrøm 等人,2022 年)通过混合两个 TS 生成新的 TS,目标是预测混合权重。CoST(Woo 等人,2022 年)利用时域和频域对比损失来学习季节趋势表征。TimeCLR(Yang 等人,2022 年)引入了相移和振幅变化增强,这是一种基于 DTW 的数据增强方法。TF-C(Zhang 等人,2022 年)同时学习基于时间和频率的 TS 表示,并提出了一种新颖的时频一致性架构。在医疗领域,Subject-Aware CL(Cheng 等人,2020 年)提出了一种实例化的 CL 框架,通过架构设计将时间信息纠缠在一起;CLOCS(Kiyasseh 等人,2021 年)提出考虑其应用中特别可用的空间维度,这与一般 TS 中的信道接近。以前用于 TS 的 CL 方法计算的是硬对比损失,即所有负对之间的相似性同样最小化,而我们为 TS 引入了软对比损失。

表 1:时间序列对比学习方法对比表。
软对比学习。 软对比学习通常是通过batch实例判别来实现的,其中每个实例都被视为属于一个不同的类别。然而,这种方法有可能会将相似样本在嵌入空间中推得更远。为了解决这个问题,人们提出了几种方法,其中包括一种基于特征距离和几何接近度量,利用图像软分配的方法(Thoma 等人,2020 年)。NNCLR(Dwibedi 等人,2021 年)通过提取特征空间中的前 k 个邻域,为每个视图定义额外的正值。NCL(Yeche`等人,2021 年)利用医学领域知识的监督来查找邻近物,并通过权衡共同优化两个相互冲突的损失:邻近物对齐损失最大化邻近物和正对的相似性,邻近物辨别损失最大化正对的相似性,同时最小化邻近物的相似性。SNCLR(Ge 等人,2023 年)用软分配扩展了 NNCLR,采用注意力模块来确定当前样本和邻近样本之间的相关性。**CO2(Wei 等人,2021 年)引入了一致性正则化,以加强不同正向视图和所有负向视图之间的相对分布一致性,从而形成样本之间的软关系。ASCL(Feng 和 Patras,2022 年)通过将原始实例判别任务转化为多实例软判别任务,引入了样本间的软关系。**之前非 TS 领域的软性 CL 方法计算嵌入空间上的软分配,因为数据空间上的实例相似性很难测量,尤其是在计算机视觉领域(Chen 等人,2020 年)。相比之下,我们建议根据数据空间中 TS 实例之间的距离来计算软分配。(有疑问,在数据空间中判断距离合适吗?)
**时间序列中的掩码建模。**除 CL 外,掩码建模最近也被作为 TS 中自监督学习的代理任务进行了研究,其方法是掩码掉一部分 TS 并预测缺失值。CL 在高级分类任务中表现出了不俗的性能,而掩码建模则在低级预测任务中表现出色(Dong 等人,2023 年;Huang 等人,2022 年;Xie 等人,2022 年)。TST(Zerveas 等人,2021 年)采用了掩码建模范式来进行 TS,目标是重建掩码时间戳。PatchTST (Nie 等人,2023 年)旨在预测被掩码的子序列级补丁,以捕捉局部语义信息并减少内存使用。SimMTM (Dong 等人,2023 年)从多个掩码 TS 重建原始 TS。
(这篇论文里引用的参考文献,我要都去找一下看一下)
3 方法
在本节中,我们通过对实例对比损失和时间对比损失引入软赋值来分别捕捉样本间关系和样本内关系,从而提出了 SoftCLT。对于实例对比损失,我们使用数据空间中 TS 之间的距离来捕捉样本间的关系;对于时间对比损失,我们使用时间戳之间的差异来考虑单个 TS 内的时间关系。SoftCLT 的整体框架如图 1 所示。
3.1 问题定义
本文的任务是,在给定一批 N 个时间序列 X = {x 1 ,......x N } 的情况下,学习非线性嵌入函数 f θ : x → r。我们的目标是学习将时间序列 x i ∈R T×D 映射到表示向量 r i =r i,1 ,...,r i,T ⊤ ∈R T×M 的 f θ,其中 T 是序列长度,D 是输入特征维度,M 是嵌入特征维度。
3.2 软实例对比学习
将一批实例中的所有实例进行对比可能对 TS 表示学习有害,因为相似的实例在嵌入空间上的学习距离很远。与计算机视觉等其他领域不同,在数据空间上计算出的 TS 数据之间的距离有助于衡量它们之间的相似性。例如,两张不同图像的逐像素距离一般与它们的相似性无关,而两个 TS 数据的逐像素距离则有助于衡量它们的相似性。通过最小-最大归一化距离度量 D(-,-),我们使用 sigmoid 函数 σ(a) = 1/(1+exp(-a))为一对数据索引(i, i ′)定义了一个软赋值,用于实例对比损失:
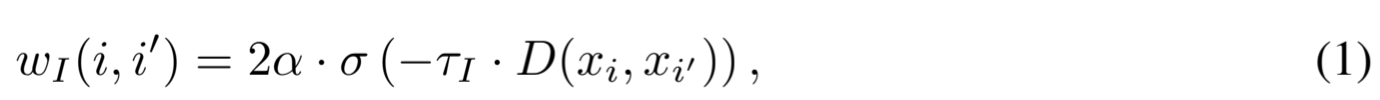
其中,τ I 是控制锐度的超参数,α 是0, 1范围内的上限,用于区分相同的 TS 对和彼此接近的不同 TS 对;当 α = 1 时,我们给距离为零的 TS 对和相同的 TS 对赋值为 1。请注意,TS 之间的距离是用原始 TS 而不是增强视图计算的,因为成对距离矩阵可以离线预计算或缓存以提高效率。
对于距离度量 D 的选择,我们在表 6d 中进行了一项消融研究,比较了 1)余弦距离、2)欧氏距离、3)动态时间扭曲(DTW)和 4)时间配准测量(TAM)(Folgado et al.) 其中,根据表 6d 中的结果,我们选择 DTW 作为整个实验的距离度量。虽然对于长度为 T 的两个 TS,DTW 的计算复杂度为 O(T 2 ),这对于大规模数据集来说可能成本较高,但它可以离线预计算或缓存以提高计算效率,也可以使用其快速版本,如复杂度为 O (T )的 FastDTW(Salvador & Chan,2007)。我们通过经验证实,DTW 和 FastDTW 的输出几乎是一样的,因此 CL 结果也是一致的。
为简洁起见,让 r i,t = r i+2N,t 和 r˜ i,t = r i+N,t 分别为 x i 在时间戳 t 处的两次增强的嵌入向量。受对比度损失可以解释为交叉熵损失这一事实的启发(Lee 等人,2021 年),我们将计算损失时考虑的所有相似性中相对相似性的软最大概率定义为:
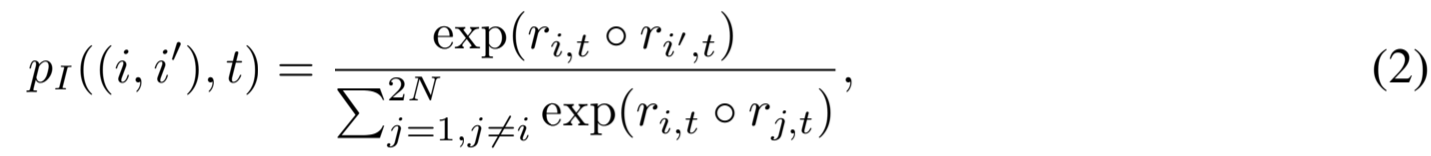
其中,我们使用点积作为相似度量 o。那么,时间戳 t 时 x i 的软实例反差损失定义为:
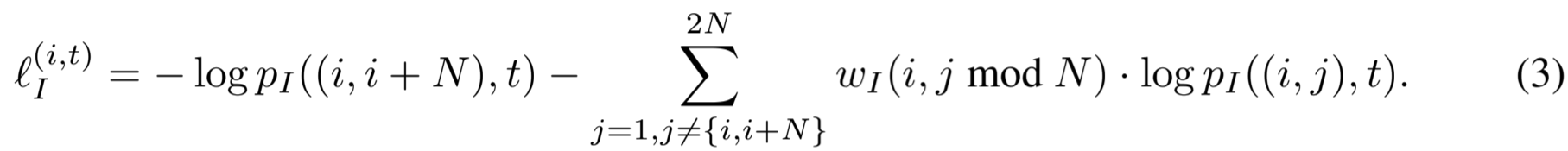
ℓ (i,t) I 中的第一项对应的是正向配对的损失,第二项对应的是由软赋值 w I (i, i ′ ) 加权的其他配对的损失。请注意,这种损失可以看作是硬实例对比损失的一般化,即当 ∀w I (i, i ′ )=0 时的损失。
3.3 软时间对比学习
根据相邻时间戳中的值是相似的这一直觉,我们建议根据时间戳之间的差异来计算软赋值,以获得时间对比损失。与软实例对比损失类似,当时间戳越来越近时,赋值接近于 1,而当时间戳越来越远时,赋值为 0。我们将一对时间戳(t,t ′)的软赋值定义为时间对比损失:
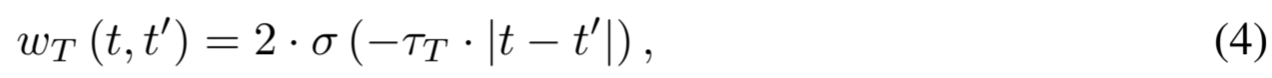
其中,τ T 是控制锐度的超参数。由于不同数据集的时间戳之间的接近程度各不相同,我们调整 τ T 来控制软分配的程度。图 2a 展示了不同 τ T 下时间戳差异的软分配示例。
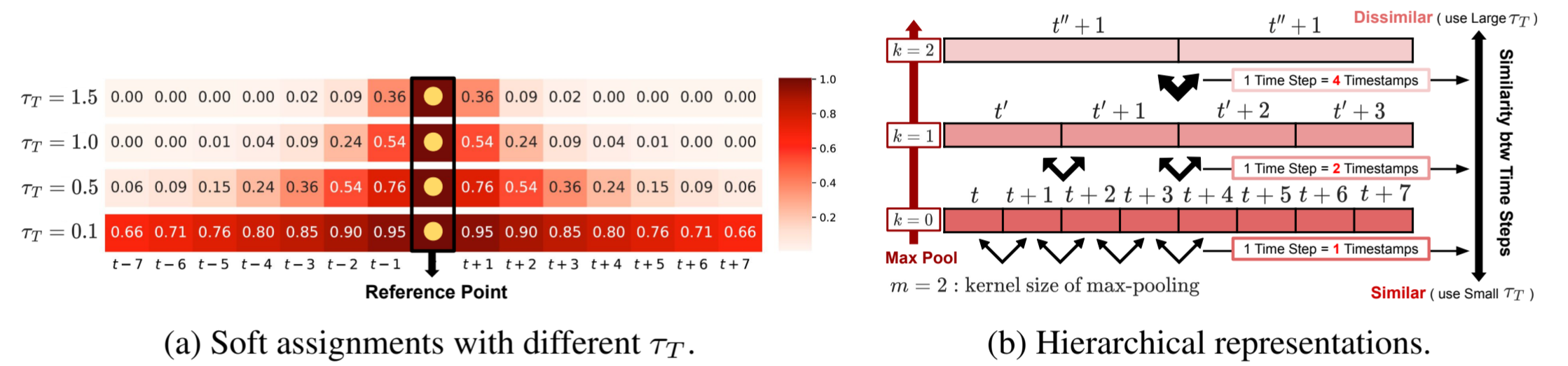
图 2:(a) 显示了软时态 CL 的软分配示例,τ T 越小,分配越平滑。(b)是分层表示法的示例,表明层深度的增加会导致相邻时间步之间的语义差异增大,因此应增加 τ T 以弥补这种差异。
**分层损失。**对于时态 CL,我们考虑对网络 f θ 中的中间表示进行分层对比,就像之前的 TS CL 方法一样。具体来说,我们采用了 TS2Vec(Yue 等人,2022 年)中提出的分层对比损失,即在沿时间轴的每个最大池化层之后对中间表征计算损失,然后汇总。如图 2b 所示,池化后相邻时间步之间的相似性降低,我们通过乘以公式 4 中的 m k 来调整 τ T,即 τ T =m k -τ˜ T,其中 m 是池化层的核大小,k 是深度,τ˜ T 是基础超参数。
现在,为简洁起见,让 r i,t =r i,t+2T 和 r˜ i,t =r i,t+T 分别为 x i 在时间戳 t 处的两次增强的嵌入向量。与公式 2 类似,在计算损失时,我们定义了所有相似性中相对相似性的软最大概率:
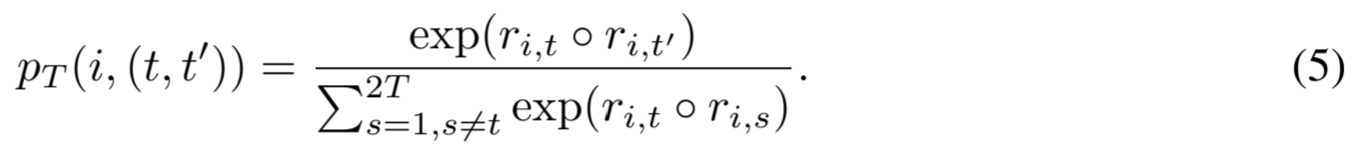
那么,时间戳 t 处 x i 的软时间对比损失定义为:
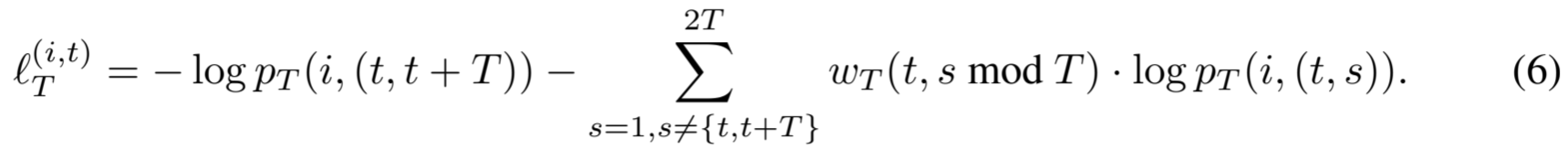
与软实例对比损失类似,这种损失可视为硬时间对比损失的一般化,即当 ∀w T (t, t ′ )=0 时的情况。
SoftCLT 的最终损失是软实例损失和时间对比损失的总和:
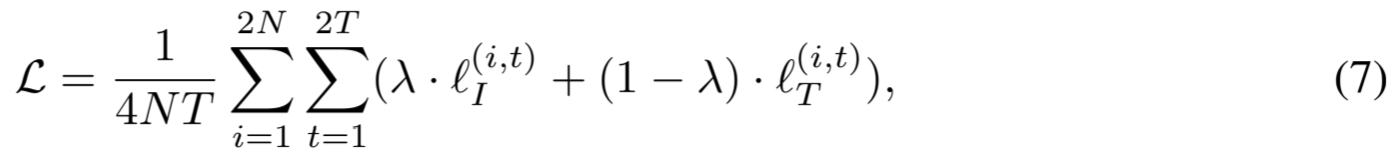
其中,λ 是一个超参数,用于控制每种损失的贡献,除非特别指定,否则设为 0.5。所提出的损失有一个有趣的数学解释,即它可以看作是软最大概率与归一化软分配的缩放 KL 散度,其中缩放是软分配的总和。我们将在附录 D 中提供更多细节。
4 实验
我们进行了大量实验来验证所提出的方法,并评估其在不同任务中的性能:(1) 单变量和多变量 TS 分类,(2) 通过(i) 自监督学习后进行微调和(ii) 半监督学习进行半监督分类,(3) 域内和跨域场景中的迁移学习,以及 (4) 正常和冷启动设置中的异常检测。我们还进行了消融研究,以验证 SoftCLT 的有效性及其设计选择。最后,我们将时间表示的成对距离矩阵和 t-SNE(Van der Maaten 和 Hinton,2008 年)可视化,以显示 SoftCLT 与之前方法相比的效果。我们将 SoftCLT 应用于各种方法的数据增强策略: TS2Vec 将两个视图生成为具有重叠的 TS 段,而 TS-TCC/CA-TCC 将两个视图生成为具有弱增强和强增强的视图,分别使用抖动和缩放策略以及排列和抖动策略。
4.1 分类
我们使用 125 个 UCR 档案数据集(Dau 等人,2019 年)进行单变量 TS 分类任务实验,使用 29 个 UEA 档案数据集(Bagnall 等人,2018 年)进行多变量 TS 分类任务实验。具体来说,我们将 SoftCLT 应用于 TS2Vec(Yue 等人,2022 年),该数据集在上述数据集上表现出了 SOTA 性能。作为基准方法,我们考虑了 DTW-D(Chen 等人,2013 年)、TNC(Tonekaboni 等人,2021 年)、TST(Zerveas 等人,2021 年)、TS-TCC(Eldele 等人,2021 年)、T-Loss(Franceschi 等人,2019 年)和 TS2Vec(Yue 等人,2022 年)。实验方案沿用了 T-Loss 和 TS2Vec 的实验方案,其中带有 RBF 内核的 SVM 分类器是在所有时间戳的最大池化表示所获得的实例级表示之上进行训练的。表 2 和图 3 所示的基于 Wilcoxon-Holm 方法(Ismail Fawaz 等人,2019 年)的临界差(CD)图表明,在这两个数据集上,所提出的方法在准确率和等级方面都显著提高了 SOTA 性能。在图 3 中,每个数据集的最佳结果和次佳结果分别用红色和蓝色表示。如果在置信度为 95% 的情况下,各方法的平均排名差异在统计上不显著,我们也会用粗线将其连接起来,这表明所提方法的性能提升是显著的。(没看懂这个连线)
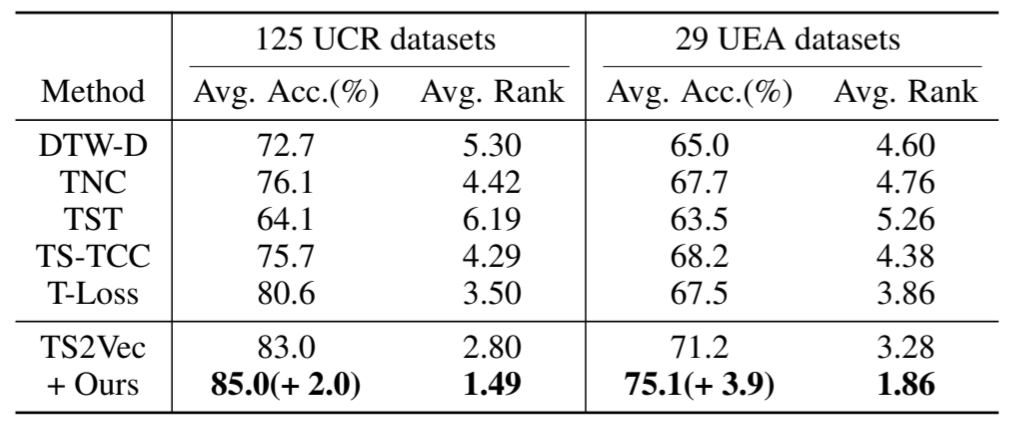
表 2:UCR/UEA 的准确率和排名。
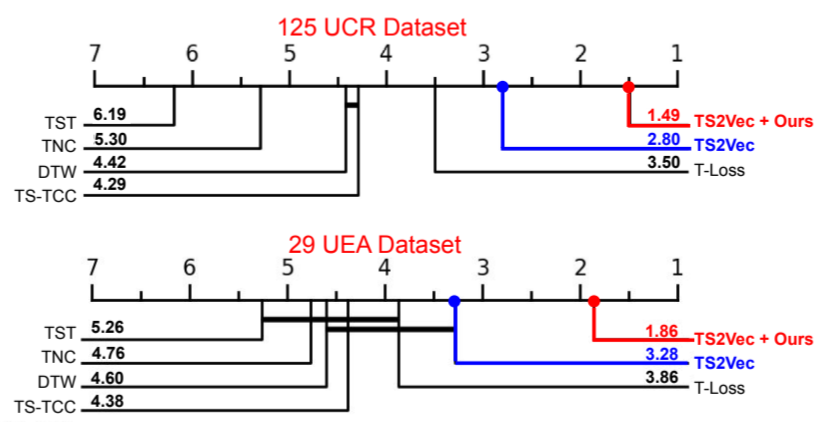
图 3:UCR/UEA 的 CD 图。
4.2 半监督分类
我们在半监督分类任务中采用 SoftCLT 对 TS-TCC (Eldele 等人,2021 年)及其扩展 CA-TCC (Eldele 等人,2023 年)进行实验,这些方法分别将 CL 纳入自监督和半监督学习。作为基线方法,我们考虑了 SSL-ECG (Sarkar & Etemad, 2020)、CPC (Oord et al., 2018)、SimCLR (Chen et al., 2020) 和 TS-TCC (Eldele et al., 2021) 等自监督学习方法、 2021 年)用于自监督学习,Mean-Teacher(Tarvainen & Valpola,2017 年)、DivideMix(Li 等人,2020 年)、SemiTime(Fan 等人,2021 年)、FixMatch(Sohn 等人,2020 年)和 CA-TCC (Eldele 等人,2023 年)用于半监督学习。需要注意的是,TS-TCC 和 CA-TCC 都能进行实例和时间对比,但它们的时间对比是通过预测一个视图与另一个视图的未来来实现的,这与传统的正负对对比损失不同。因此,我们采用软时间对比损失作为这两种方法的附加损失。为了进行评估,我们采用了与 CA-TCC 相同的实验设置和数据集,其中包括八个数据集(Anguita 等人,2013;Andrzejak 等人,2001;Dau 等人,2019),其中六个数据集来自 UCR 档案库。我们考虑了两种半监督学习方案:(1)使用未标注数据进行自监督学习,然后使用标注数据进行监督微调;(2)同时使用标注和未标注数据进行半监督学习,遵循 CA-TCC(Eldele 等人,2023 年)。表 3 列出了这两种方法在 1%和 5%标注数据集情况下的实验结果,结果表明,在这两种情况下,应用 SoftCLT 在大多数数据集上都取得了最佳的整体性能。
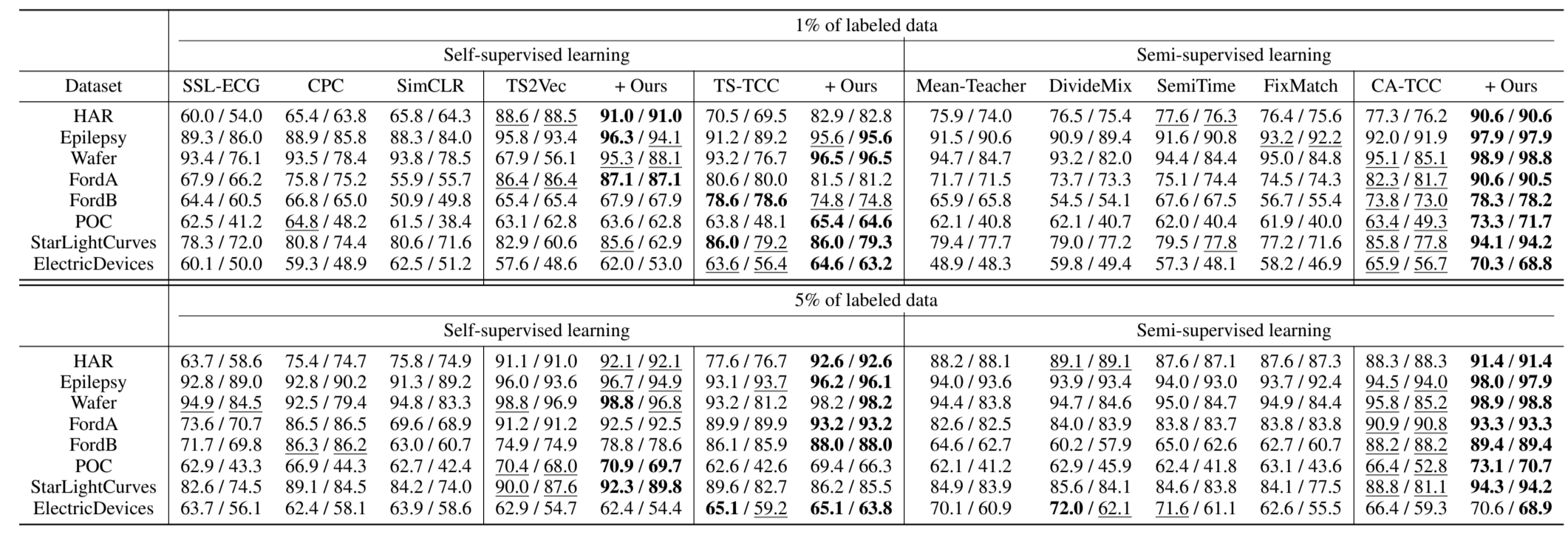
表 3:半监督分类结果。表中显示了使用 1%和 5%标签对自我和半监督模型进行微调的结果。每个数据集的最佳结果用粗体表示,次佳结果用下划线表示。准确率和 MF1 分数按顺序报告。
4.3 迁移学习
我们将软CLT应用于TS-TCC和CA-TCC,进行了用于域内和跨域分类的迁移学习实验,这在之前的研究中已有应用(Zhang等人,2022;Eldele等人,2021;2023;Dong等人,2023)。作为基线方法,我们考虑了 TS-SD(Shi 等人,2021 年)、TS2Vec(Yue 等人,2022 年)、Mixing-Up(Wickstrøm 等人,2022 年)、CLOCS(Kiyasseh 等人,2021 年)、CoST(Woo 等人,2022 年)、LaST(Wang 等人,2023 年)、CA-TCC(Wang 等人,2023 年)、 2022 年)、LaST(Wang 等人,2022 年)、TF-C(Zhang 等人,2022 年)、TS-TCC(Eldele 等人,2021 年)、TST(Zerveas 等人,2021 年)和 SimMTM(Dong 等人,2023 年)。在域内迁移学习中,模型在 SleepEEG(Kemp 等人,2000 年)上进行预训练,并在 Epilepsy(Andrzejak 等人,2001 年)上进行微调,这两个数据集都是 EEG 数据集,因此被认为属于相似域。跨领域迁移学习包括在一个数据集上进行预训练,然后在不同的数据集上进行微调。在跨领域迁移学习中,模型在 SleepEEG 上进行预训练,然后在三个不同领域的数据集上进行微调,这三个数据集是 FD-B(Lessmeier 等人,2016 年)、Gesture(刘等人,2009 年)和 EMG(Goldberger 等人,2000 年)。此外,我们还在自监督和半监督设置下进行了无适应迁移学习,其中源数据集和目标数据集共享相同的类集,但源数据集只有 1%的标签可用,且不允许在目标数据集上进行进一步训练。具体来说,模型在故障诊断(FD)数据集(Lessmeier 等人,2016 年)中的四个条件(A、B、C、D)之一上进行训练,并在另一个条件上进行测试。表 4a 显示了域内和跨域迁移学习的结果,表 4b 显示了使用 FD 数据集的自监督和半监督设置的结果。值得注意的是,应用于 CA-TCC 的 SoftCLT 将使用 FD 数据集的 12 个迁移学习场景的平均准确率提高了 10.68%。

表 4:跨域和域内迁移学习任务的结果。
4.4 异常检测
我们采用 SoftCLT 对 TS2Vec(Yue 等,2022)进行单变量 TS 异常检测(AD)任务的实验,实验有两种不同的设置:正常设置是将每个数据集按照时间顺序分成两半,分别用于训练和评估;冷启动设置是在 UCR 档案中的 FordA 数据集上预训练模型,然后在每个数据集上进行评估。作为基线方法,我们考虑正常设置下的 SPOT(Siffer 等人,2017 年)、DSPOT(Siffer 等人,2017 年)、DONUT(Xu 等人,2018 年)、SR(Ren 等人,2019 年),以及冷启动设置下的 FFT(Rasheed 等人,2009 年)、Twitter-AD(Vallis 等人,2014 年)、Luminol(LinkedIn,2018 年)和 TS2Vec(Yue 等人,2022 年)。按照 TS2Vec 的方法,异常得分由从掩码和未掩码输入中编码的两个表征的 L1 距离计算得出。我们在雅虎(Laptev 等人,2015 年)和 KPI(Ren 等人,2019 年)数据集上评估了所比较的方法。我们发现,抑制实例中的 CL 平均会带来更好的 AD 性能,(???没懂)因此我们报告了 TS2Vec 和 SoftCLT 在没有实例中的 CL 的情况下的性能;更多详情可参见附录 G。如表 5 所示,就 F1 分数、精确度和召回率而言,SoftCLT 在两种情况下都优于基线。具体来说,在正常设置和冷启动设置下,应用于 TS2Vec 的 SoftCLT 都能将两个数据集的 F1 分数提高约 2%。
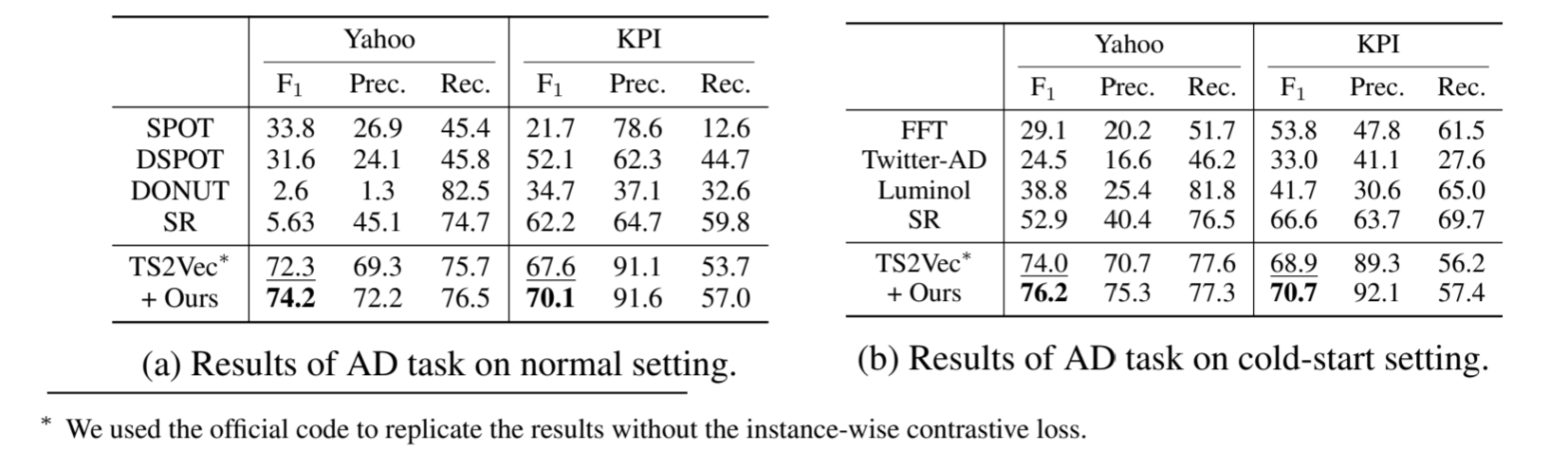
表 5:异常检测结果。
4.5 消融研究
**软CLT 的效果。**表 6a 显示了标准硬 CL 软分配的效果。将软分配应用于实例或时态 CL 会带来性能提升,而将软分配应用于两个维度会带来最佳性能,在 UCR 和 UEA 数据集上的准确率分别提高了 2.7% 和 3.7%。
**软时态 CL 的设计选择。**表 6b 比较了软分配 w T 的不同选择。Neighbor 将参考点周围窗口内的邻域视为正邻域,其他邻域视为负邻域。线性软分配与参考点的时间差成线性比例,其中最远的软分配值为零。高斯(Gaussian)软分配基于高斯分布,以参考点的平均值和标准偏差作为超参数。其中,公式 4 中的 Sigmoid 表现最好,如表 6b 所示。
**软实例对比度的上限。**在软实例广义对比度损失中,α 的引入是为了避免相同 TS 对和距离为零的不同 TS 对的赋值相同,其中 α = 1 使两种情况的赋值相同。表 6c 研究了调整 α 的效果。根据结果,α = 0.5 是最好的,即相同 TS 对的相似度应严格大于其他 TS 对,但不会相差太多。
**软实例 CL 的距离度量。**表 6d 在 128 个 UCR 数据集上比较了公式 1 中距离度量 D 的不同选择:余弦距离(COS)、欧氏距离(EUC)、动态时间扭曲(DTW)和时间对齐测量(TAM)(Folgado et al. 结果表明,软实例化 CL 的改进对距离度量的选择是稳健的。我们在所有其他实验中都使用了 DTW,因为 DTW 已被充分研究,在文献中得到了广泛应用,而且有 FastDTW 等快速算法可用。

表 6:消融研究结果。
4.6 分析
与计算机视觉中的软 CL 方法的比较。 虽然其他领域也提出了软CL方法,但它们都是在嵌入空间上计算软赋值,因为很难测量数据空间上的相似性,尤其是在计算机视觉领域。**但我们认为,数据空间上的相似性确实是一种强大的自监督,能带来更好的表征学习。**为了证实这一点,我们将 SoftCLT 与其他领域提出的嵌入空间软 CL 方法进行了比较: NNCLR(Dwibedi 等人,2021 年)和 ASCL(Feng 和 Patras,2022 年)。为了进行公平比较,我们将所有比较方法应用于相同设置下的 TS2Vec。如表 7 所示,与建议的方法不同,NNCLR 和 ASCL 使 TS2Vec 的性能变差,这意味着在数据空间上测量的相似性具有很强的自监督能力,而在可学习嵌入空间上测量的相似性在某些领域可能并不实用。为了进一步研究以往方法的失效模式,我们在表 7 中按平均 TS 长度为 200 的数据集进行了分类,发现以往的方法无法捕捉到长 TS 数据的相似性。(这就有点颠覆性的想法了,所以到底是在嵌入空间上度量相似性效果好,还是在数据空间上度量相似性效果好?还是说两个效果都好或者是都不好?)
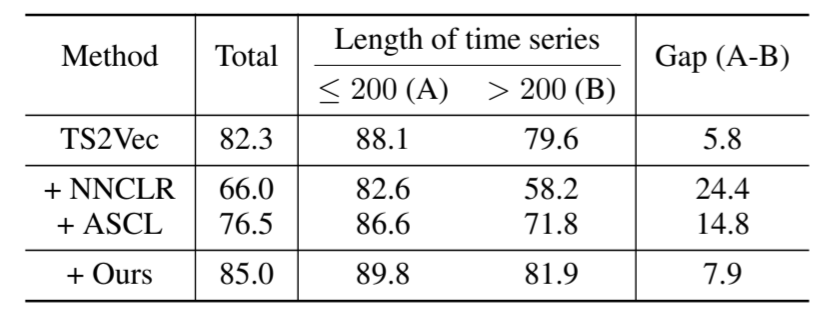
表 7:软 CL 方法的比较。
**对季节性的鲁棒性。**所提出的软时间 CL 背后的一个假设是相邻时间戳中的值是相似的,这可能会让人担心无法捕捉 TS 中的季节性。为了解决这个问题,我们通过 ADF 检验(Sims 等人,1990 年)在 p = 0.05 的显著性水平下根据季节性对 UCR 数据集进行分类。如表 8 所示,无论季节性如何,SoftCLT 的性能增益都是一致的。我们的猜想是,正如 ADF 检验结果所示,现实世界中的 TS 通常不会表现出完美的季节性,因此 SoftCLT 可以利用非季节性部分。与此同时,以前的研究也曾试图分解 TS 中的趋势和季节性以进行表征学习(Wang 等人,2022 年;Woo 等人,2022 年)。然而,这对于既非同时自回归也非静态的 TS 来说可能并不现实(Shen 等,2022 年)。总之,我们不直接考虑 TS 中的季节性,因为提取季节性不仅具有挑战性,而且在实践中不考虑季节性也能取得良好的性能。(所以,时序上提取季节趋势等是否合理,或者说是不是不同数据集效果不同,如果使用weather天气或者是电力数据集,或者是有周期性或者是趋势性的数据集,会不会就和这个UCR数据集的效果不一样???因为不是所有的时序数据都会有很明显的季节趋势,这也引发了一种思考,并不是所有的时序数据都有周期性,确实是这样的,只能说是受时间影响的,但是不一定会有趋势或者是周期性变化)
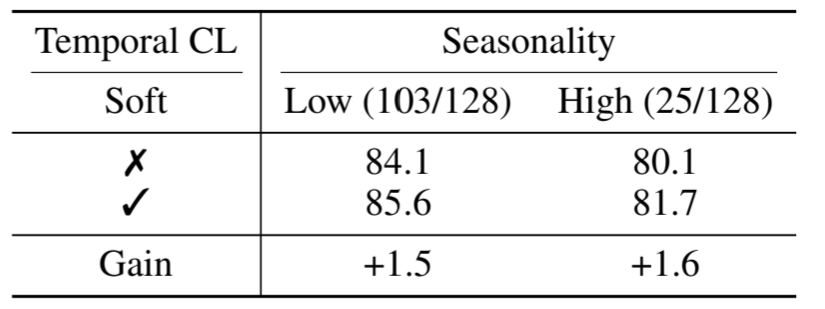
表 8:按季节划分的软时间性 CL 的效果。
**实例关系。**为了了解编码器中是否保留了实例间的关系,我们将从 UCR 档案库(Dau 等人,2019 年)中提取的 InsectEPGRegularTrain 数据集上各层表征的成对实例间距离矩阵可视化,颜色越亮表示实例间的距离越小。图 4 的顶部和底部面板分别显示了采用硬 CL 和软 CL 时,随着深度的增加,表征的成对距离矩阵的变化。结果表明,在整个编码过程中,软CLT保留了TS实例之间的关系,而标准的硬CL则未能保留这些关系。
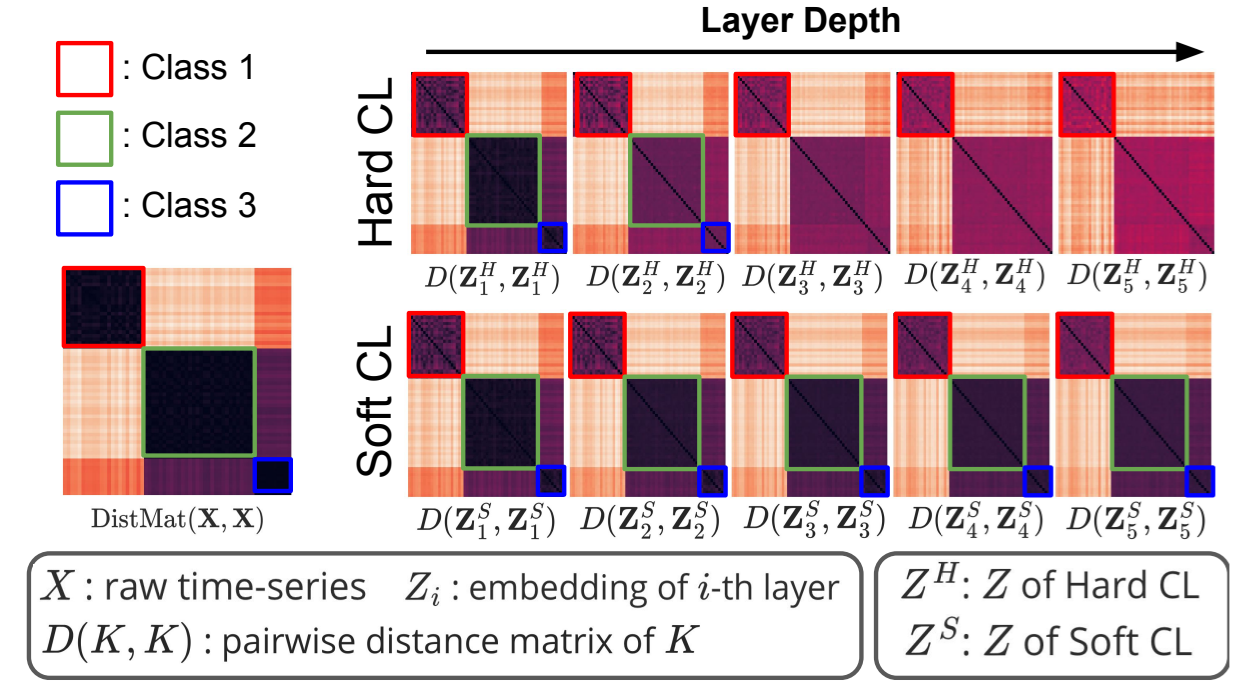
图 4:成对距离矩阵。
**时间关系。**为了评估 SoftCLT 所捕捉的时间关系的质量,我们应用 t-SNE(Van der Maaten & Hinton,2008 年)来可视化时间表示,即单个 TS 中每个时间戳的表示。图 5 比较了硬 CL 和软 CL 在不同训练epochs中学习到的表示的 t-SNE,随着时间的推移,点的颜色越来越深。硬 CL 发现了粗粒度的邻域关系,因此无法区分深红色的晚期时间戳,而软 CL 则发现了更细粒度的关系。
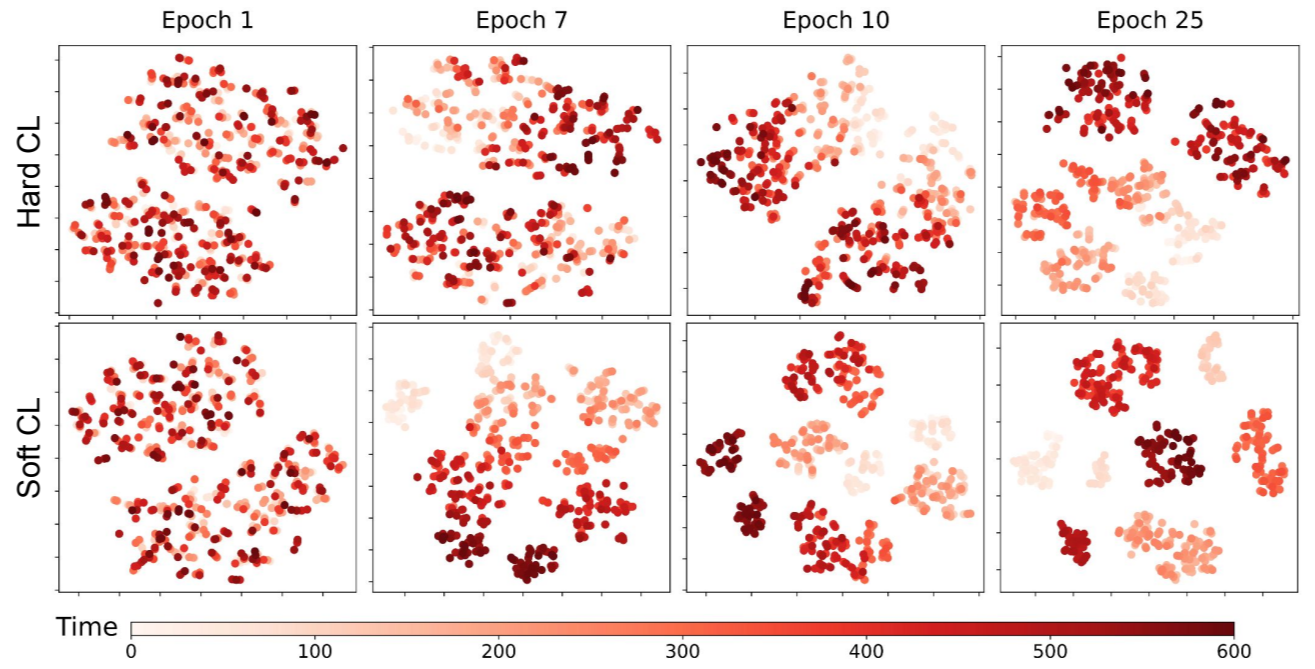
图 5:时间表示的可视化。
5 结论
本文提出了一种时间序列软对比学习框架。与以往对样本对进行硬分配的方法不同,我们的方法基于数据空间的实例和时间关系进行软分配。我们在一系列任务中证明了我们方法的有效性,从而显著提高了性能。我们希望我们的工作能启迪人们从数据空间进行自监督的有效性,并激励未来在不同领域进行对比表示学习的工作考虑到这一点。
伦理声明
所提出的时间序列软对比学习算法有可能对时间序列数据的表征学习领域产生重大影响。将该算法应用于各种任务并解决时间序列表示学习的一般问题的能力是很有前途的。特别是,该算法可以应用于迁移学习,这在下游任务数据集较小的情况下可能会很有用。此外,我们期望利用数据空间的自监督来进行对比表示学习的想法能激励未来在各个领域的工作。
然而,与任何算法一样,我们也需要考虑伦理问题。其中一个潜在的伦理问题是,该算法有可能使用于预训练的数据集中可能存在的偏差永久化。例如,如果预训练数据集在某些人口属性方面不平衡,这种偏差可能会转移到微调中,从而可能导致有偏差的预测。在实际场景中使用该算法之前,必须评估并解决预训练数据集中的潜在偏差。
为确保负责任地使用该算法,我们将公开数据集和代码。公开数据集和代码可以提高透明度和可重复性,使其他研究人员能够评估和解决潜在的偏差和误用问题。
(17:08,看完了,有一说一,还得再好好看看,哈哈哈哈哈哈哈哈哈.)