想要认识神经网络,个人认为还是需要先从回归开始理解
线性回归
回归(regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。 在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。
在机器学习领域 中的大多数任务通常都与预测(prediction)有关。 当我们想预测一个数值时,就会涉及到回归问题。 常见的例子包括:预测价格(房屋、股票等)、预测住院时间(针对住院病人等)、 预测需求(零售销量等)。
线性回归有比较简单直接的比例关系,通常表示为一个线性方程,如:
y=kx+b
| 房屋大小 | 100 | 110 | 120 | 130 | 1400 | 150 | 160 |
|---|---|---|---|---|---|---|---|
| 房屋价格 | 3 | 5 | 7 | 9 | 9.5 | 14 | 16 |
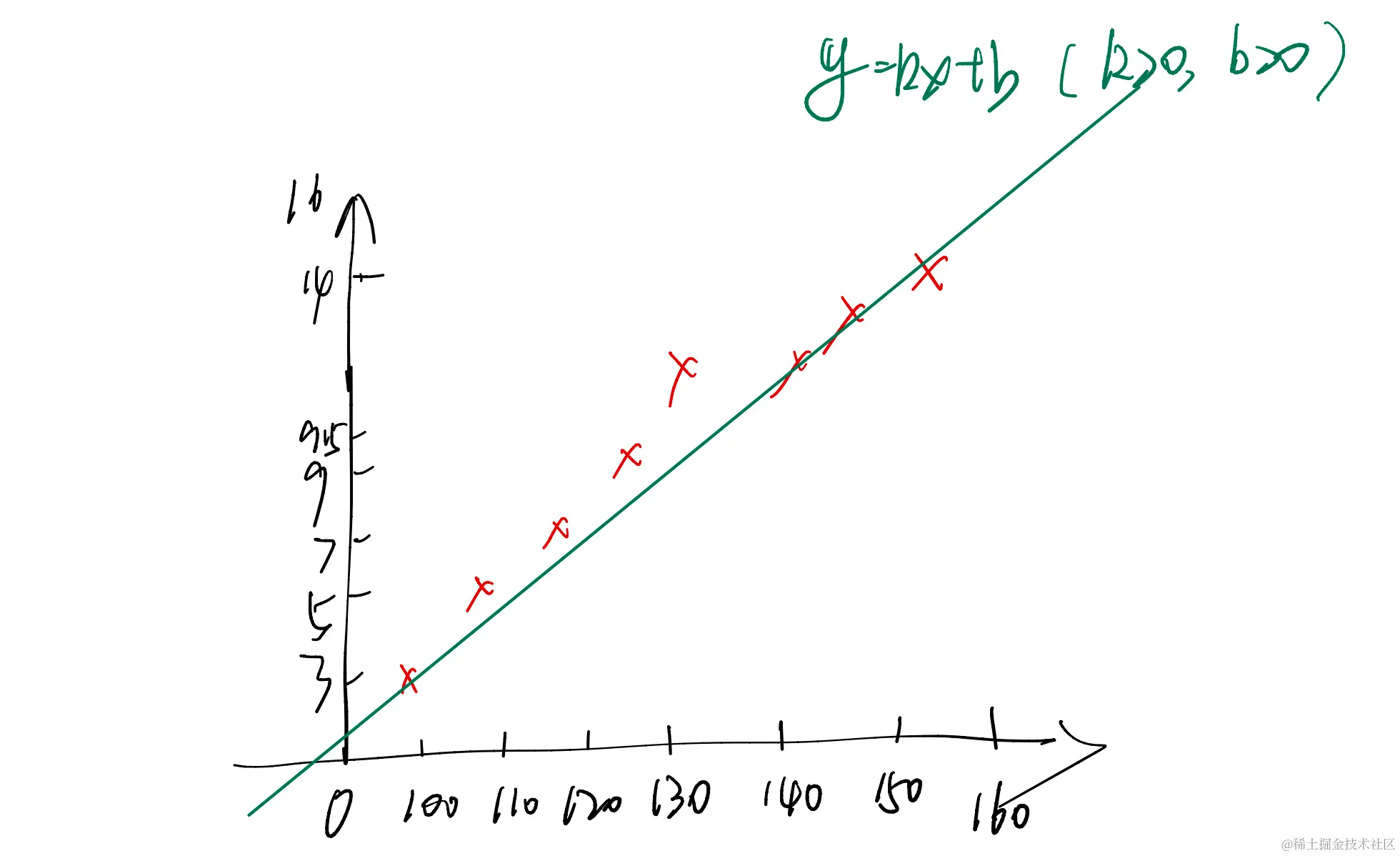
k代表了平面直线的斜率 ,b是y轴截距 但是一开始的k和b不一定是什么,咱们暂且先随便给俩,所以有可能是下面这张图的样子

有什么办法可以确认k和b的值,能够很好的拟合现有的数据,并且能为其他数据作出预测呢?(暂停1分钟时间想想)
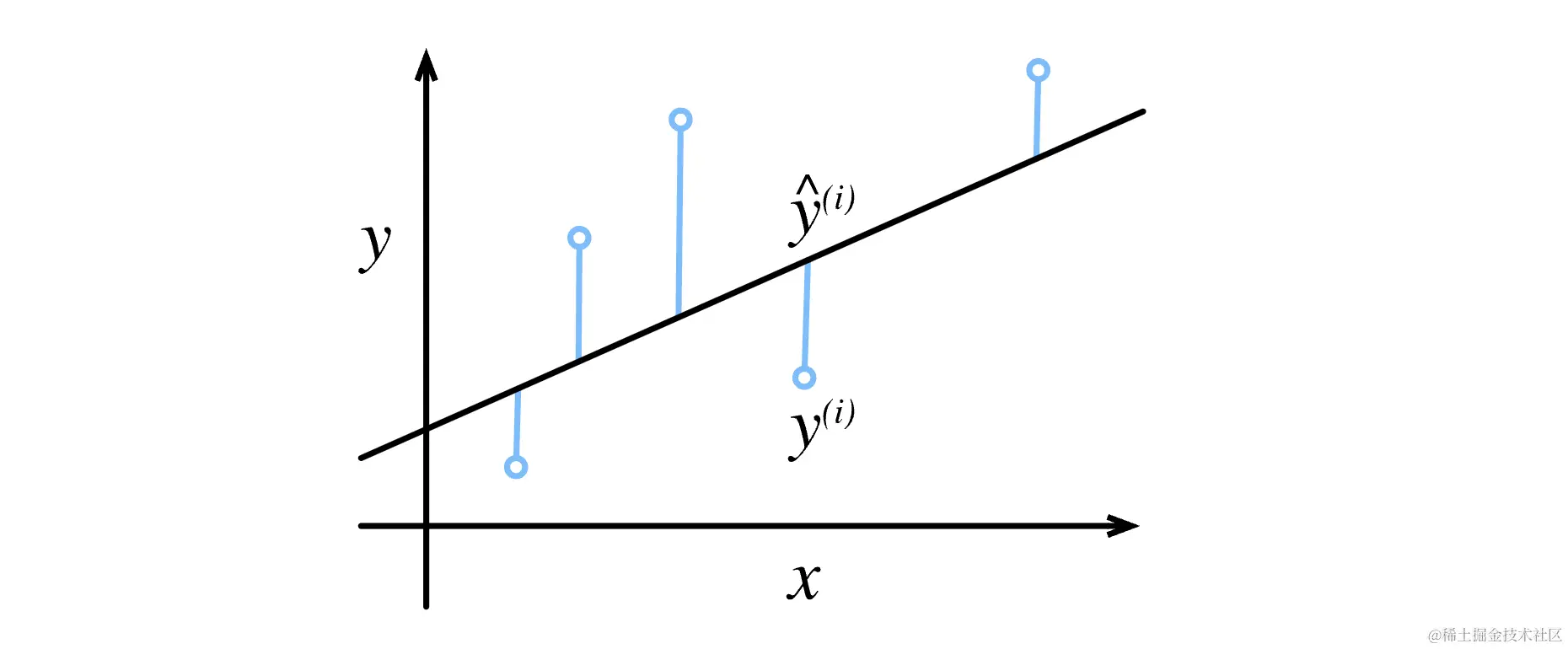
Think!!! 是不是我们计算出每一个点数距离直线的距离加起来最短就行了?这样直线所在的位置能是平面坐标系中最拟合数据(也就是预测能力最强)的直线
那么如何确定这条直线的k和b呢?
损失函数
平方误差函数:
由于平方误差函数中的二次方项, 估计值和观测值之间较大的差异将导致更大的损失。 为了度量模型在整个数据集上的质量,需计算在训练集n个样本上的损失均值(也等价于求和)
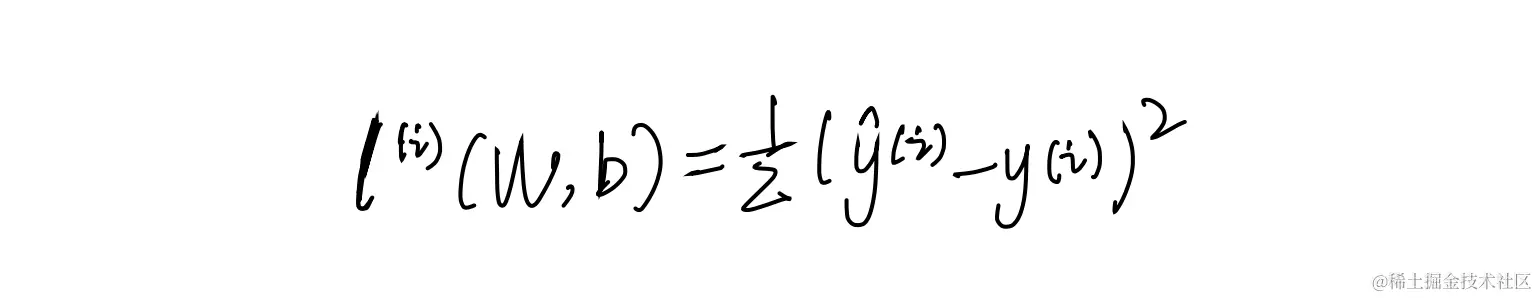
y上面带小尖帽的指的是预测值,不戴帽的是实际值
所以,最终目的就变成了,让损失函数越小越好。
损失函数(Loss Function),也被称为代价函数(Cost Function),在机器学习和统计学中扮演着至关重要的角色。它是一个用来估量模型预测值和实际值之间差异的函数。损失函数的定义可以根据不同的问题和上下文有所变化,但其核心目的是衡量模型的预测准确性。在优化过程中,目标是最小化这个损失函数,从而提高模型的预测能力。

梯度下降
这种方法几乎可以优化所有深度学习模型。 它通过不断地在损失函数递减的方向上更新参数来降低误差
Loss函数是一个关于w和b的二元二次方程,为阐述方便,先把w, b看做为一个合并变量t.

当导数值逐渐变为0的时候,我们认为找到了当前函数的局部最小值,也就是说在这个位置,往哪里走都比它原来的位置大小更大。
当你的生活最糟糕的时候,做什么选择都不能再糟糕了
为什么说是局部最小值呢?
三维图像:

它实际上长这个样子

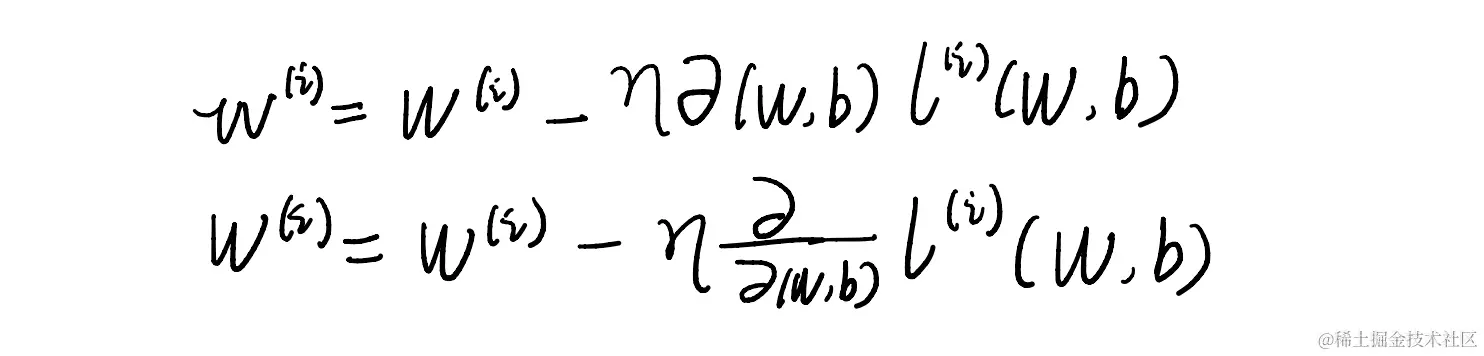
以上三维图像是截取自吴恩达老师的神经网络视频学习课程。
咱们在图像上随机选一个点,尝试着往各个方向走(也就是求偏导数),找到一个往下走最快的地方,咱们就往那里走一步,这样一步一步走到山谷中,代表我们找到了局部最低点。 在如上所画的公式展示来看,偏导左边那个希腊字母,我打不出来。。用n代替吧。 n就代表学习率,代表的一次性的步长,步长长了容易扯着蛋,短了会变慢。
公式的意思就是用旧值减去学习率乘以当前函数在这个方向上的往下走的步长,偏导数可以求出往哪里走,学习率n决定咱们走多长,这样减去就得到了一个新的值,这样一次一次的往下减。
学习率:
梯度下降的步长,在模型训练中不断调整自己
偏导数:
假设有一个多变量函数 f(x,y,z,...),那么函数 f 关于变量 x 在点 (a,b,c,...) 的偏导数是指当 ...y,z... 保持不变时,f 在 x 方向的瞬时变化率。数学上通常表示为 round _f _ /round _x _ 。类似地,可以定义 f 关于 y、z 等其他变量的偏导数。
逻辑回归:
线性回归可以预测,那么逻辑回归就是解决二分类问题,是或者不是。
| 肿瘤(Size) | 年龄 | 是否良性(Y or N) |
|---|---|---|
| 2m | 49 | N (0.42) |
| 5 | 25 | N(0.49) |
| 7 | 73 | Y(0.98) |
| 9 | 32 | Y(0.73) |
| DNA相似 | 是否亲生(Y or N) |
|---|---|
| 95 | N |
| 97 | N |
| 99.1 | Y |
| 99.9 | Y |
比如肿瘤大小和年龄大小 跟当前的瘤是否是阳性的都是有一定关系的,但是最终我们只需要一个预测结果,到底是不是良性?
再比如亲子鉴定,是否是亲生的?
根据图表所示,我们又可以得到一个平面图像,因为人类的dna和香蕉dna的相似率都几乎有一半,所以判断是否是亲生的 只在很高的值域上才能判断,所以图像是这样的:
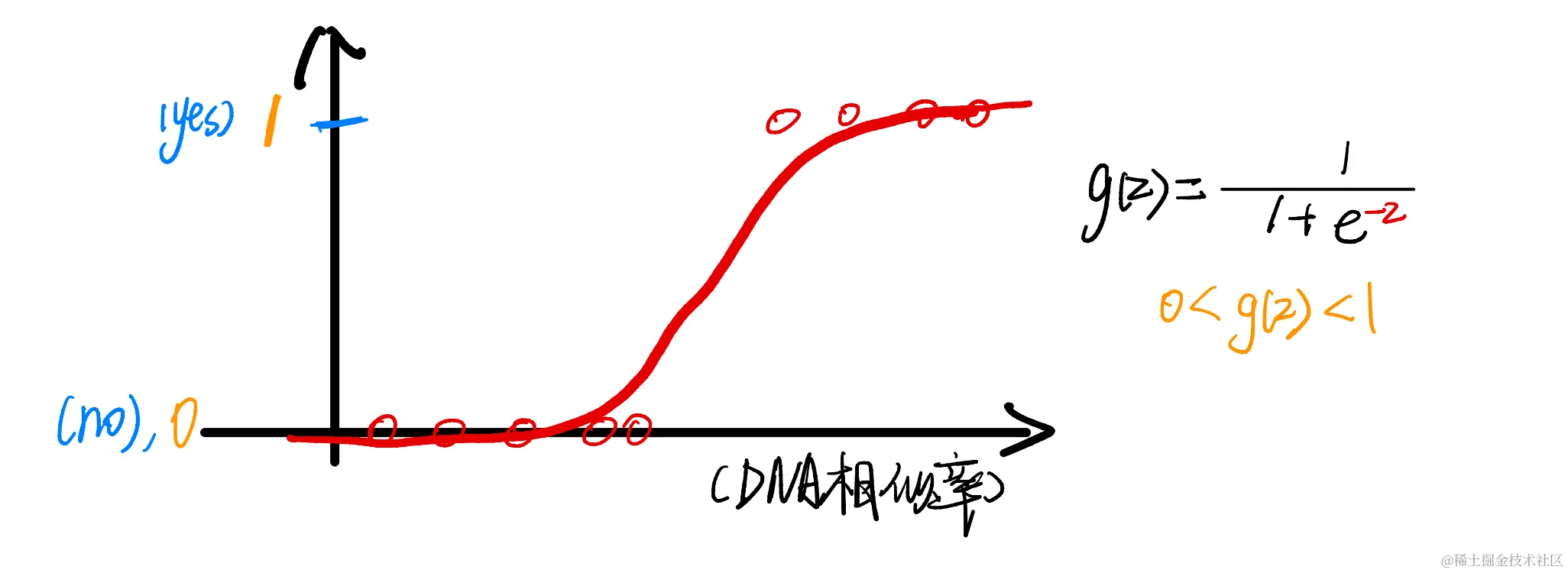

公式如图上所示。
那么既然之前说了,线性回归有损失函数,逻辑回归一定也有
逻辑回归的损失函数:
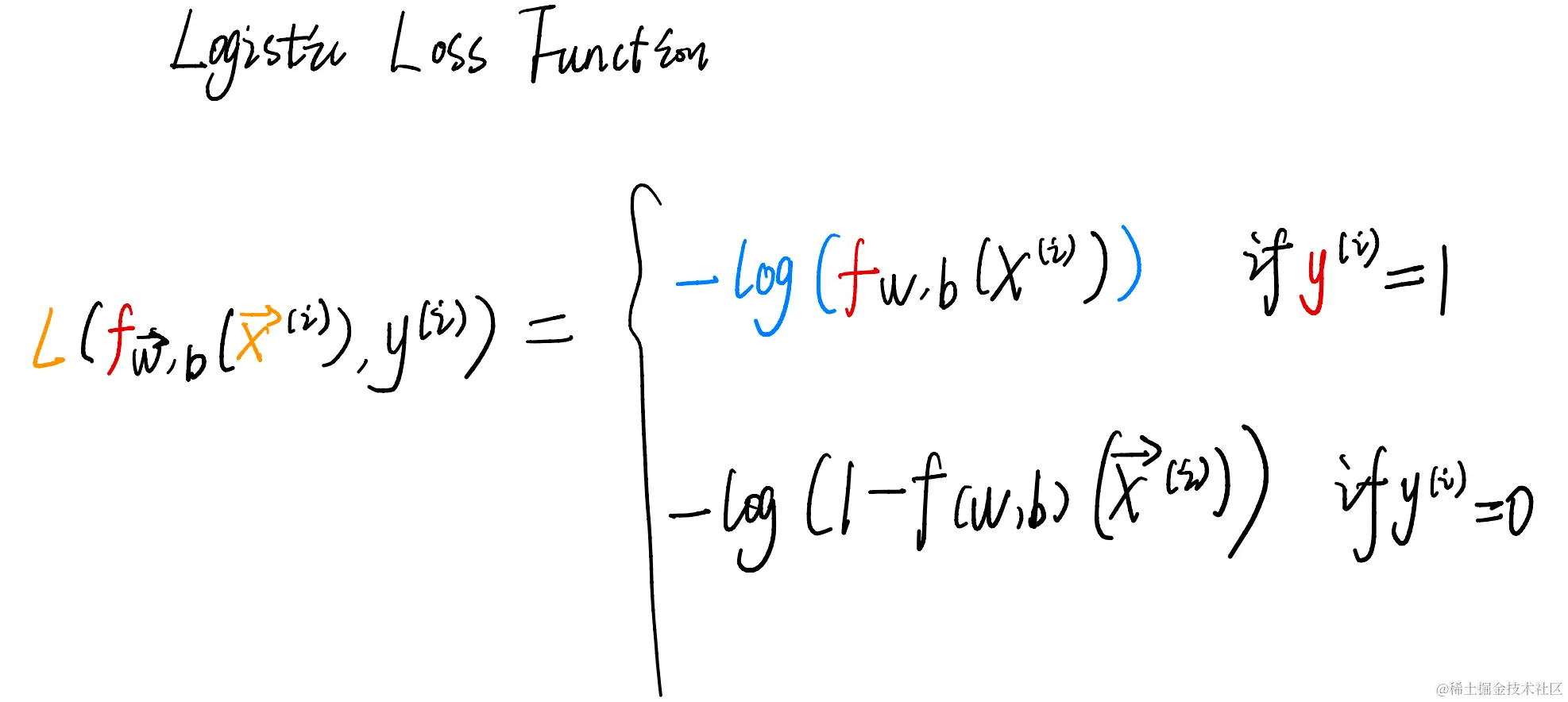
当y=1时,图像应该是:
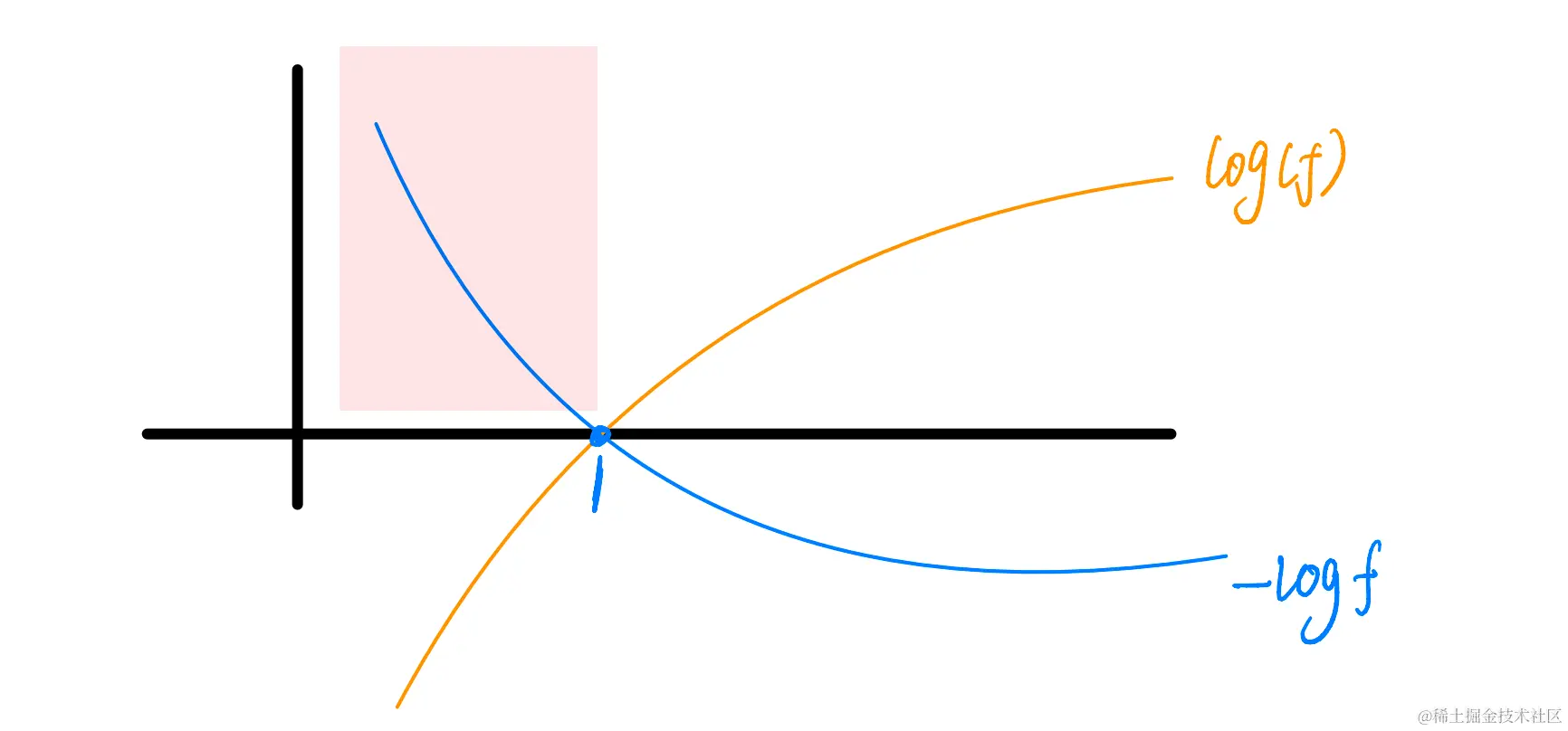
这是一个分段函数,当y为真或者为假的时候,使用的损失函数是不一样的。回想一下,上面说过咱们的目的是让损失函数越小越好。 所以 当y为真(1)的时候,咱们使用黄色的log对数图像,
原因是因为在x轴0-1的部分,函数是持续上升的,也就是说,在越接近1时,函数值的损失函数越小,越远离1,损失函数越大,也就是说惩罚机制越严重。
我举个例子:你儿子明明是你亲生的,但预测值不是,也就是说明你这个烂方法根本不顶用啊,此时损失函数的值非常高,我要惩罚你,你预测的不对!
这块损失函数的设计非常美妙,强烈建议要弄懂
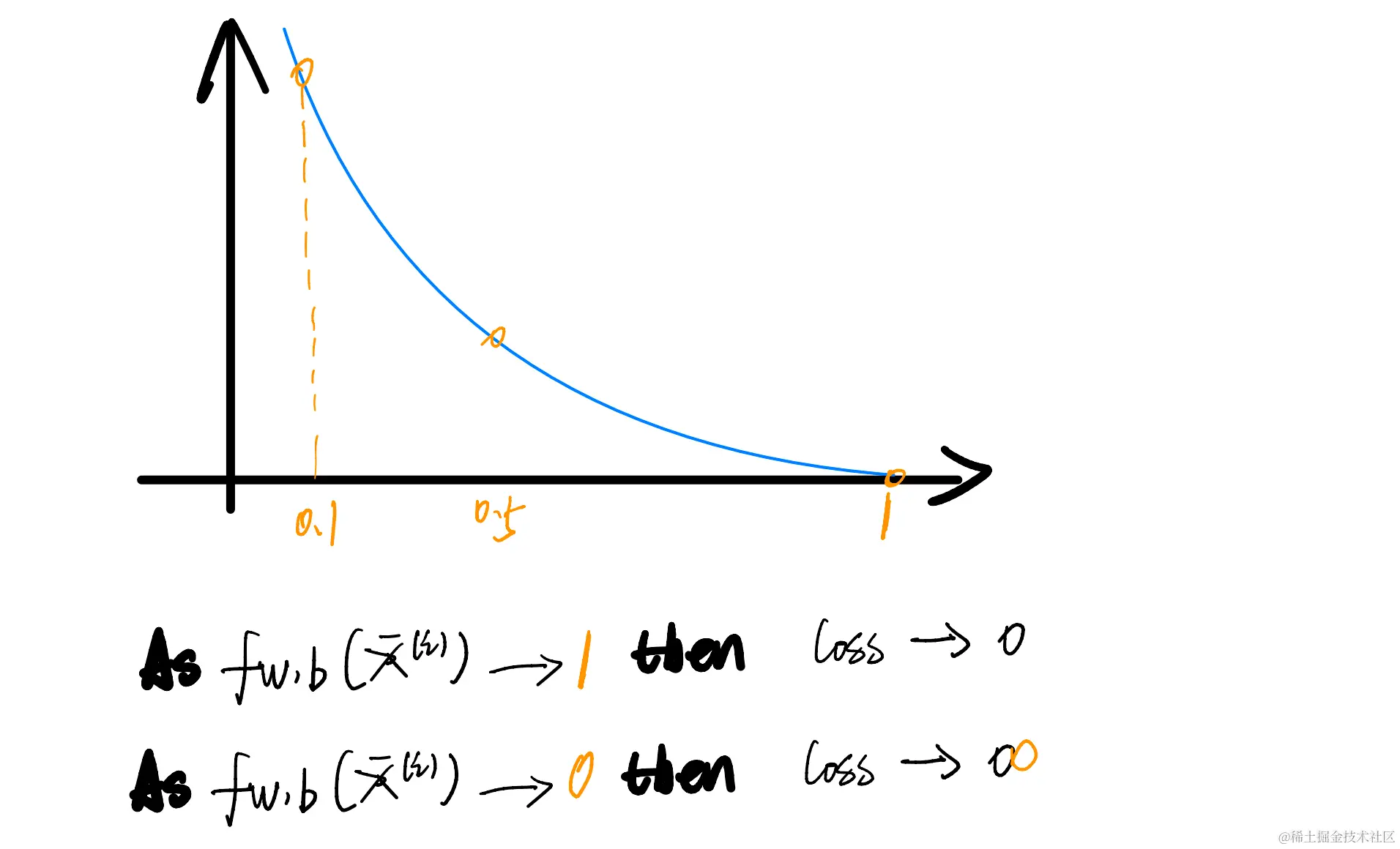
当目标值越趋近1,代表损失值越小
当目标值越趋近0,代表损失值越大
当y=0时,图像:(与之相反,当y为假时,需要用到蓝色log图像)

当目标值越趋近1,代表损失值越大
当目标值越趋近0,代表损失值越小

公式可以自己推导,看着麻烦其实拆分下来一看其实就那么回事,就是上面分段函数的合并。
激活函数:
1.决定了神经元是否应该被激活,从而影响网络的输出
2.它将神经元的加权输入(线性组合)转换为非线性输出
- 如果没有激活函数,不管网络有多少层,最终的输出都是输入的线性组合,这极大地限制了网络处理复杂问题(如图像识别、语音处理)的能力。
- 非线性激活函数使得神经网络可以任意逼近任何复杂函数,提高了网络的表示能力。
Sigmoid:
将输入转换为0到1之间的输出。常用于二分类问题。
SoftMax:
将输入转换为概率分布,常用于多分类问题的输出层

高斯分布:
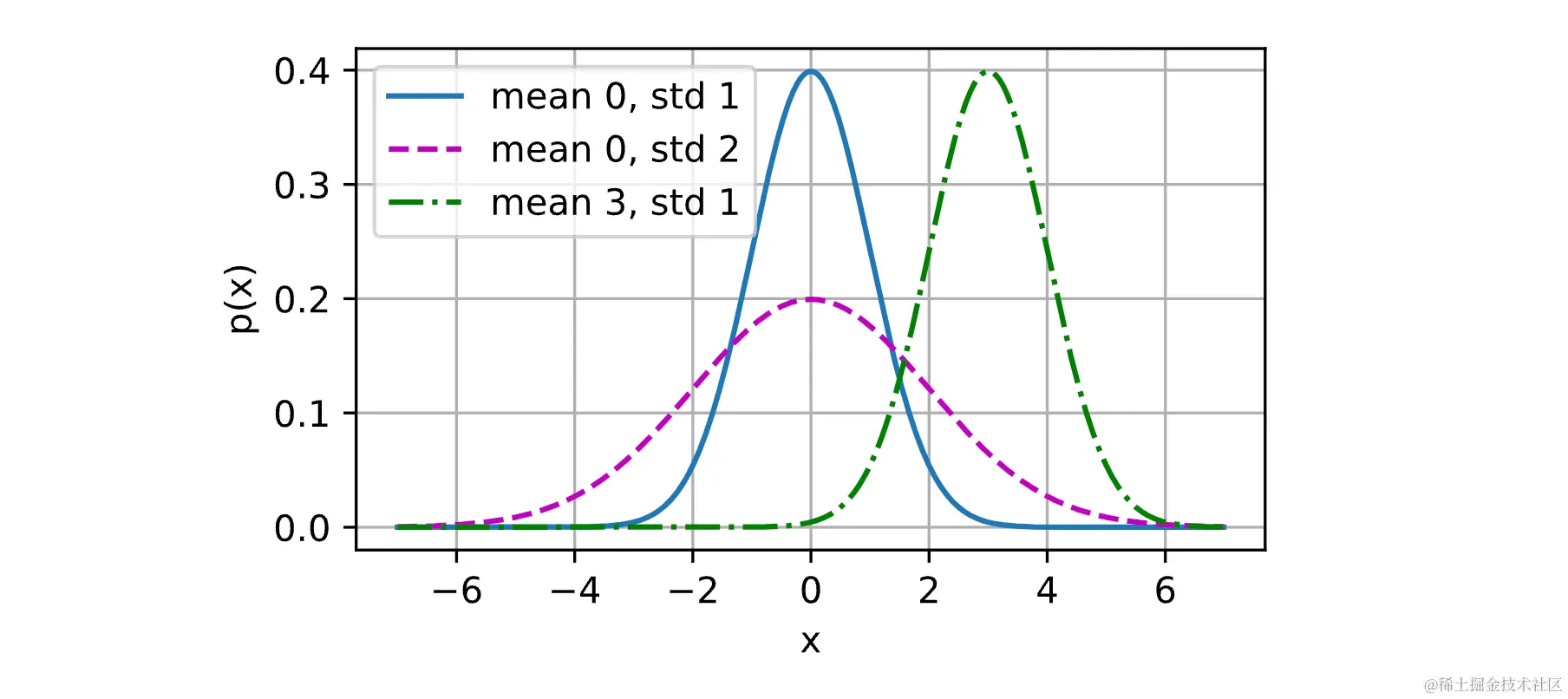
高斯分布就是正态分布,就是为了让一开始神经网络的输入能够有多样性
神经网络:
一种受生物大脑启发的计算系统,通过大量简单的、互相连接的节点(类似于生物神经元)来进行信息处理
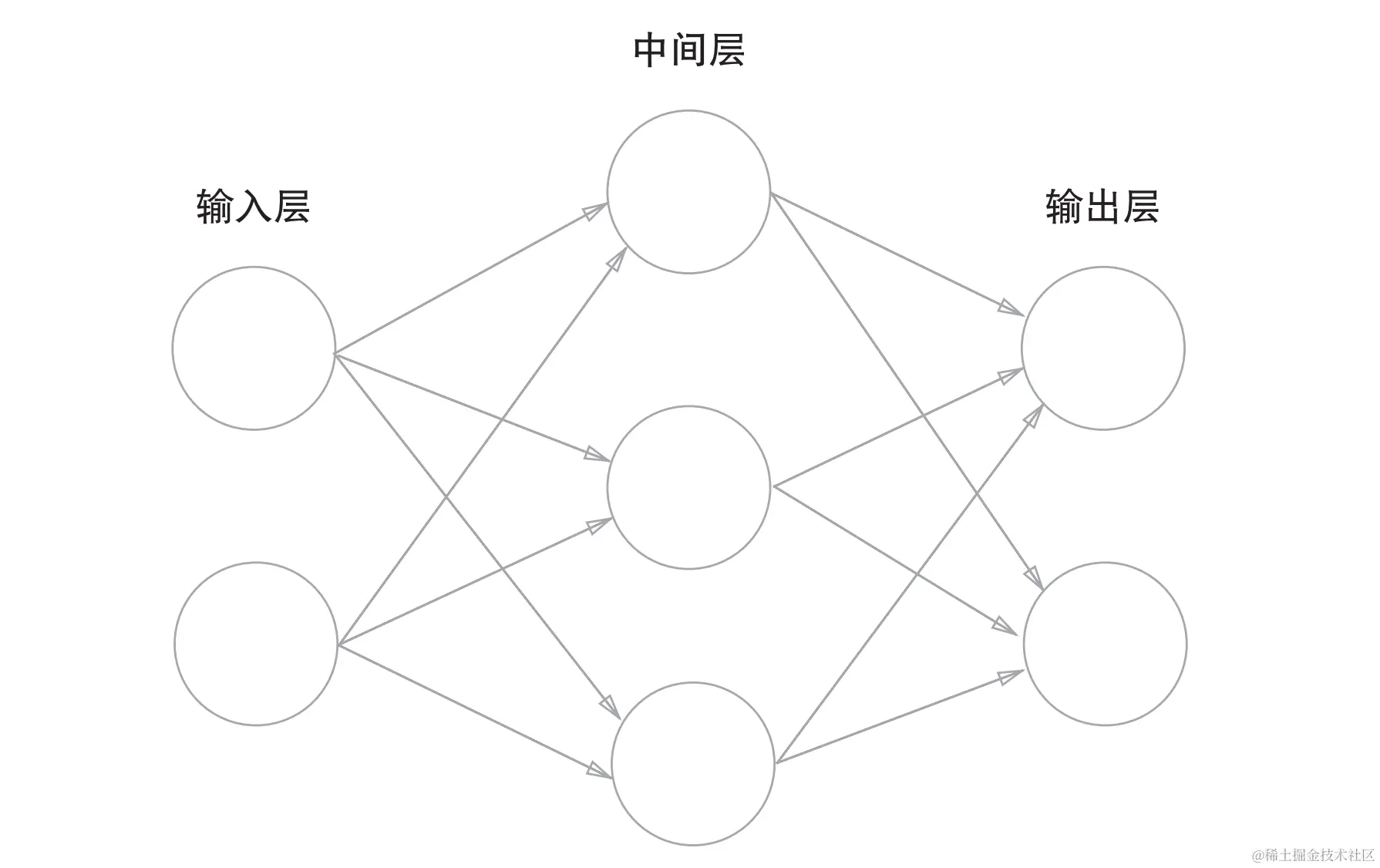

这里不从感知机开始讲解,反而不好懂这样。
其实神经网络搭建满足三个条件即可: 输入和输出,权重w和b,多层结构
其实最难的地方就是确定权重w和b,那么w和b是什么玩意呢: 就是刚才线性回归和逻辑回归那个k和b(道理是一样的,这里用w和b指定),也就是说就是训练权重w和b偏执而已 ,如何确定上面已经说的非常清楚啦。
神经网络最重要的特征就是可以从数据中学习,能从数据中不断学习调整权重参数,解决复杂问题。比如下面是一个图的像素数据,把它理解为一个矩阵
[ [ 33, 155, 116],
[ 45, 213, 184],
[212, 121, 106],
[209, 95, 138],
[225, 41, 28],
[199, 28, 198],
[253, 39, 133],
[216, 252, 150],
[ 26, 128, 44],
[ 3, 54, 167],
[ 35, 46, 231],
[ 50, 58, 226],
[ 20, 60, 164],
[243, 62, 163],
[ 80, 49, 123],
[200, 45, 234],
[ 45, 29, 157],
[ 83, 230, 199],
[ 39, 210, 241],
[202, 57, 103],
[232, 208, 158],
[ 12, 239, 60],
[151, 100, 254],
[104, 226, 150],
[214, 120, 232],
[148, 75, 62],
[ 77, 87, 19],
[202, 211, 254],
[ 27, 194, 169],
[ 42, 219, 138],
[ 37, 82, 104],
[179, 126, 89],
[174, 228, 183],
[160, 49, 163],
[133, 255, 143],
[246, 9, 0],
[ 47, 1, 241],
[173, 186, 18],
[233, 227, 158],
[214, 213, 74],
[ 58, 16, 148],
[248, 6, 239],
[133, 4, 120],
[205, 130, 250],
[[ 86, 2, 3],
[213, 103, 1],
[217, 244, 129],
[135, 166, 48],
[ 60, 125, 6],
[191, 220, 202],
[212, 165, 15],
[168, 194, 84],
[156, 246, 189],
[143, 100, 11],
[152, 168, 61],
[250, 232, 156],
[ 94, 180, 37],
[122, 239, 82],
[150, 146, 31],
[185, 172, 152],
[159, 71, 225],
[ 43, 107, 139],
[192, 101, 228],
[199, 50, 71],
[ 63, 197, 87],]
]
用一个例子说明下这个图:比如一堆猫的图像,我要根据这个图像去训练这个模型去识别为别的图像是不是猫,这个模型我定义了三层,那么第一层就是先找图像里边像素点的各种边角料,第二层找一些更具体的特征,比如胡须,嘴巴,尾巴,第三层找猫的身子,头这样。 在训练完成后,我拿这一套检测是否是猫的模型去验证别的图像
训练数据和测试数据:
机器学习中,一般将数据分为训练数据和测试数据两部分来进行学习和
实验等。首先,使用训练数据进行学习,寻找最优的参数;然后,使用测试
数据评价训练得到的模型的实际能力
过拟合:
是指过于紧密或精确地匹配特定数据集,以致于无法良好地拟合其他数据或预测未来的观察结果的现象
举个有意思的例子,平面直角坐标系里一共有随机分布的20个点,数据为了完全拟合这些数据,最后得出来的图像,七拐八拐歪歪扭扭,看起来挺牛逼,其实再来个数据就歇逼了 根本预测不出来。
以下知识仅做扩展:
反向传播:
正向传播求数值微分的方式虽然简单,但是计算要耗费较多的时间,一般采用误差反向传播法。

卷积神经网络
全连接层存在什么问题呢?
数据的形状被"忽视"了,CNN比全连接更能正确理解图像形状数据
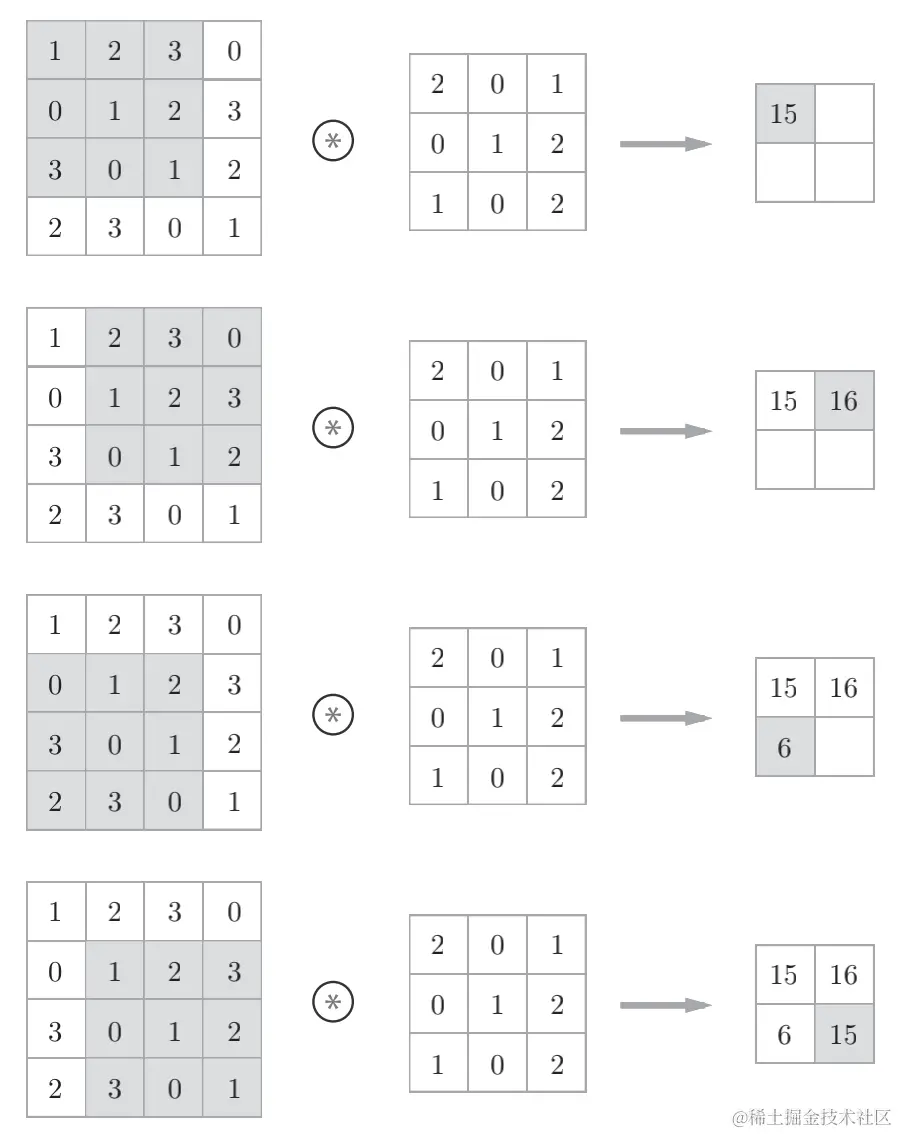
CNN解决了什么问题?
在 CNN 出现之前,图像对于人工智能来说是一个难题,有2个原因:
-
图像需要处理的数据量太大,导致成本很高,效率很低
-
图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高
-
降维
三大组成部分
1.卷积层
负责提取图像中的局部特征
2.池化层
池化层用来大幅降低参数量级(降维)
3.全连接层
全连接层类似传统神经网络的部分,用来输出想要的结果

CNN现实领域实际应用
1.图像分类、检索
2.安防,医疗:
2.目标定位检索:自动驾驶

3.目标分割:

4.人脸识别,骨骼识别
人工智能三大要素
1.算法
2.数据
3.算力
算力基托于芯片的性能提升
1.CPU并行能力差
2.GPU本意用于图形处理,后被发现显卡并行计算的潜力用于训练网络
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
