前言
学习大模型Agent相关知识,使用llama_index实现python版的Agent demo,根据AI解题场景知识密集型任务特点,需要实现一个偏RAG的Agent WorkFlow,辅助AI解题。
使用Java结合Langchain4j支持的RAG流程一些优化点以及自定义图结构的workflow,创建Agentic RAG,实现AI解题demo,并测试解题效果。
Agent概述
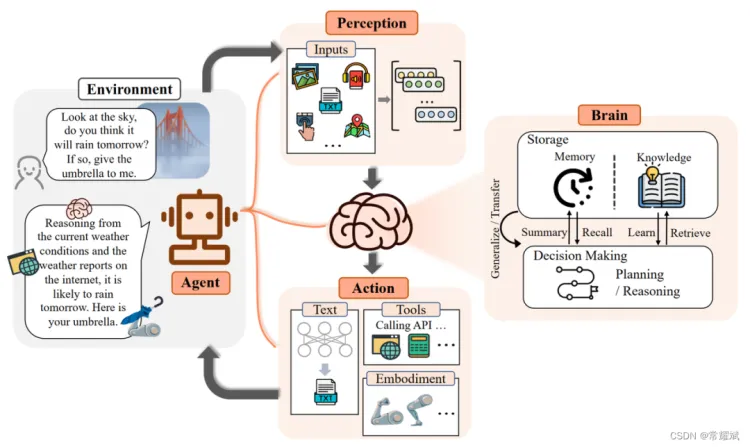
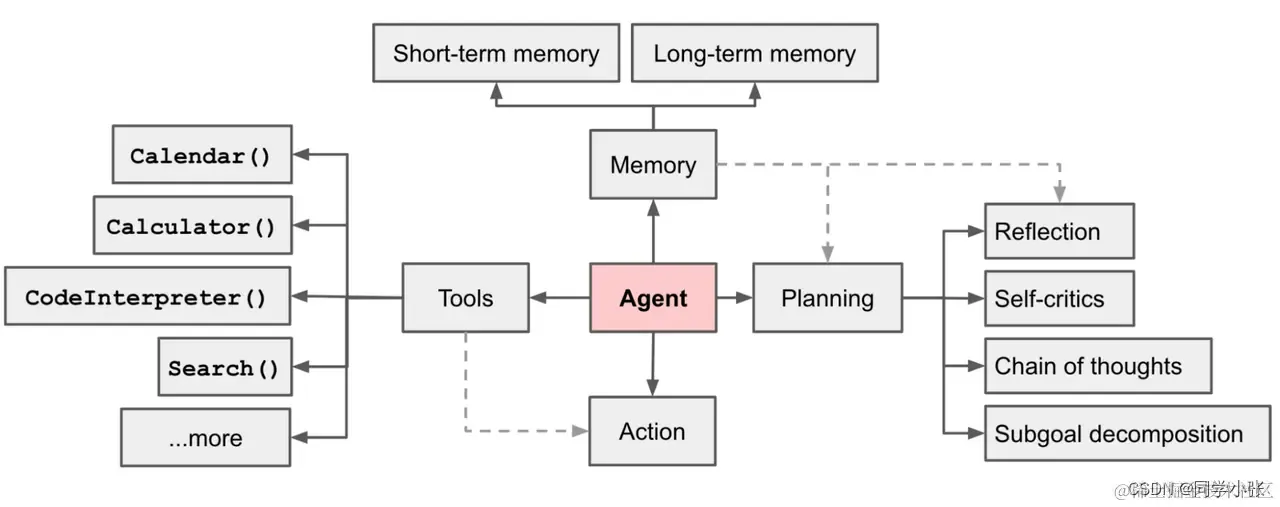
Agent智能体(Agent)是指在特定环境中能够自主感知、决策和行动的计算机系统或软件实体。Agent智能体通常具备以下几个关键特性:
- 自主性(Autonomy):Agent智能体能够独立运行,不需要持续的人工干预。它们可以根据自身的感知和内部状态做出决策。
- 感知能力(Perception):Agent智能体能够感知其环境,通过传感器或数据输入获取外部信息。这些信息可以是物理环境中的数据,也可以是其他系统或Agent智能体提供的信息。
- 决策能力(Decision-Making):Agent智能体能够基于感知到的信息和内部状态进行分析和决策。决策过程可能涉及规则、逻辑推理、机器学习算法等。
- 行动能力(Action):Agent智能体能够执行特定的动作或任务,以实现其目标。这些动作可以是物理操作(如机器人移动)或虚拟操作(如发送数据、修改文件等)。
- 目标导向(Goal-Oriented):Agent智能体通常被设计为实现特定的目标或任务。它们会根据目标调整其行为,以最大化目标的实现。
- 交互能力(Interactivity):许多Agent智能体能够与其他Agent智能体或人类用户进行交互。这种交互可以是协作性的,也可以是竞争性的。
开源的一些Agent框架
主要是python生态使用的,可以参考思想。
推荐收藏!九大最热门的开源大模型 Agent 框架来了_agent框架-CSDN博客
AI解题11-RAG流程优化以及Agent学习
agent demo
RAG相关优化思路
RAG流程的一些优化思路
- Query理解(Query NLU):使用LLM作为基础引擎来重写用户Query以提高检索质量,涉及Query意图识别、消歧、分解、抽象等
- Query路由(Query Routing):查询路由是LLM支持的决策步骤,根据给定的用户查询下一步该做什么
- 索引(Indexing):是当前RAG中比较核心的模块,包括文档解析(5种工具)、文档切块(5类)、嵌入模型(6类)、索引类型(3类)等内容
- Query检索(Query Retrieval):重点关注除典型RAG的向量检索之外的图谱与关系数据库检索(NL2SQL)
- 重排(Rerank):来自不同检索策略的结果往往需要重排对齐,包括重排器类型(5种),自训练领域重排器等
- 生成(Generation):实际企业落地会遇到生成重复、幻觉、通顺、美化、溯源等问题,涉及到RLHF、偏好打分器、溯源SFT、Self-RAG等等
- 评估与框架:RAG需要有全链路的评价体系,作为RAG企业上线与迭代的依据
一个基于RAG的Agentic RAG智能体最终目的是让大模型回答内容是完全以及事实文档的,不要根据幻觉输出内容。
java
向Lv2-智能体提出一个问题。
while (Lv2-智能体无法根据其记忆回答问题) {
Lv2-智能体提出一个新的子问题待解答。
Lv2-智能体向Lv1-RAG提问这个子问题。
将Lv1-RAG的回应添加到Lv2-智能体的记忆中。
}
Lv2-智能体提供原始问题的最终答案langchain4j-agent-demo
langchain4j提供多种优化策略优化RAG流程,对于Java中构建一个Agent,需要使用langchain4j实现RAG流程以及系列优化(如借助Function Call等实现问题重写、文档打分、幻觉检查、答案评分等),然后重写一套流程图工作流,支持定义行为节点、条件边、流转条件,节点输出状态等。
参考:https://github.com/bsorrentino/langgraph4j
为了兼容在jdk21,支持copy了所有类,代码地址:https://git.xkw.cn/mp-alpha/qai/-/tree/feat-agent
构建Graph
java
public CompiledGraph<NodeData> buildGraph() throws Exception {
var workflow = new StateGraph<>(NodeData::new);
// Define the nodes
workflow.addNode("web_search", node_async(this::webSearch)); // web search
workflow.addNode("retrieve", node_async(this::retrieve)); // retrieve
workflow.addNode("grade_documents", node_async(this::retrievalGrader)); // grade documents
workflow.addNode("generate", node_async(this::generate)); // generate
workflow.addNode("transform_query", node_async(this::transformQuery)); // transform_query
// Build graph
// 入口节点
workflow.setConditionalEntryPoint(
edge_async(this::routeQuestion),
Map.of(
"web_search", "web_search",
"retrieve", "retrieve"
));
workflow.addEdge("web_search", "generate");
workflow.addEdge("retrieve", "grade_documents");
// 条件边
workflow.addConditionalEdges(
"grade_documents",
edge_async(this::decideToGenerate),
Map.of(
"transform_query", "transform_query",
"web_search", "web_search",
"generate", "generate"
));
workflow.addEdge("transform_query", "retrieve");
// 条件边
workflow.addConditionalEdges(
"generate",
edge_async(this::gradeHallucination),
Map.of(
"not supported", "generate",
"useful", END,
"not useful", END,
"not support ready web search", "web_search"
));
return workflow.compile();
}
本质还是尽可能防止大模型幻觉输出,借助一些工具让大模型自行决策,希望大模型的输出都是来自于文档事实。
- 试题重写,生成相似试题,增强RAG召回内容。
- 文档相关性评分:对RAG的文档进行相关性打分。
- 支持接入web search:增强文档召回。
- 幻觉检查:检查生成的答案是否是有召回的文档上下文为依据的。
- 答案评分:评估答案是否正确解答了试题。
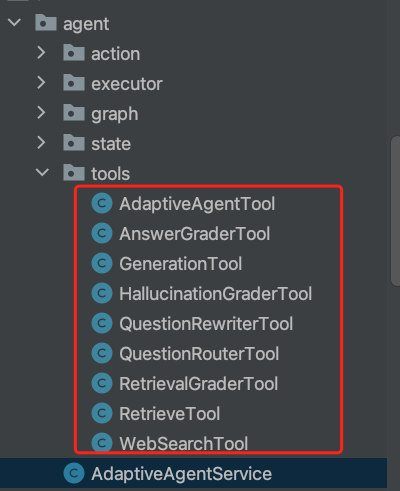
入口会先进行retrieve、web_search路由
- 优先进行retrieve流程,接着一系列文档相关性评分、问题/试题重写、评估是否答案幻写、评估答案得分(是否基于文档事实)、答案生成等。如果retrieve最终结果为not sure开启web_search流程。
- web_search流程:文档search、文档相关性评分、问题/试题重写、答案生成。
拓展一些图状态节点元数据,实现循环次数限制,防止进入死循环
- 总的图状态转移的最大次数设置为xx,得不到结果,就返回答案未知。
- 设置maxTransformQueryCount,控制transform_query 和 grade_documents 图节点转移的最大次数为x,判定检索到文档没有帮助,就不再转换查询,终止状态循环,生成结果。
- 设置maxHallucinationGraderCount,grade_hallucation 和 generate 图节点转移最大次数为x,判定生成的答案不是基于文档、事实,就不再重复生成,终止循环状态,进行 grade_answer。
- 设置maxWebSearchCount,grade_hallucation 和 web search 图节点转移最大次数为x,判断RAG之后答案仍不以文档为依据进行web search,然后在评分,加上异常捕获和控制最大次数;
另外需要对transform_query做一些处理,因为是解答试题场景,需要保存最初的试题,最后生成答案是基于最初的试题,中间转换生成的试题,只起到 增强RAG召回以及辅助解题上下文的作用。
解题测试
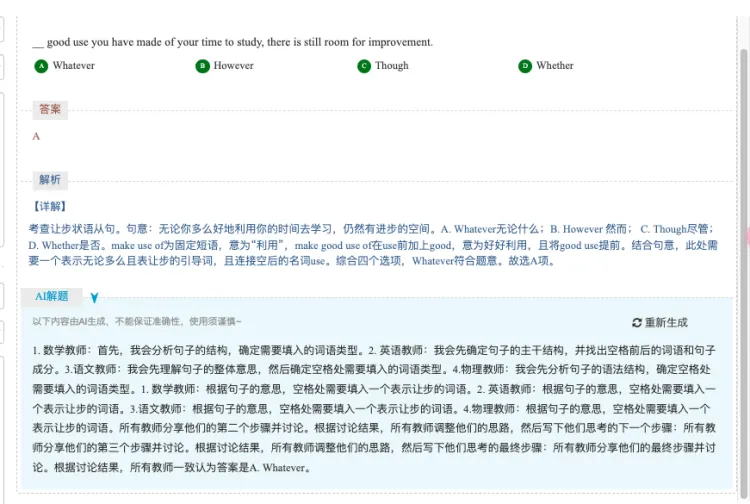
AI解题12-解题场景智能体Agentic RAG预研demo
100道高中英语单选,模型使用base4o,RAG参数设置召回数量为5,召回最小阈值为20.0
- 使用Agent大概能解答对94;
- 直接使用RAG解答的话大概能解答对90;
使用该Agent之后,token消耗会增多,解题时间也会变长。
综合测试结果分析,可以考虑使用在那些直接RAG解答错误的试题,可以使用此Agent重新生成答案,一定几率会生成正确答案。
llama-index-agent-lats-demo
Language Agent Tree Search - LlamaIndex
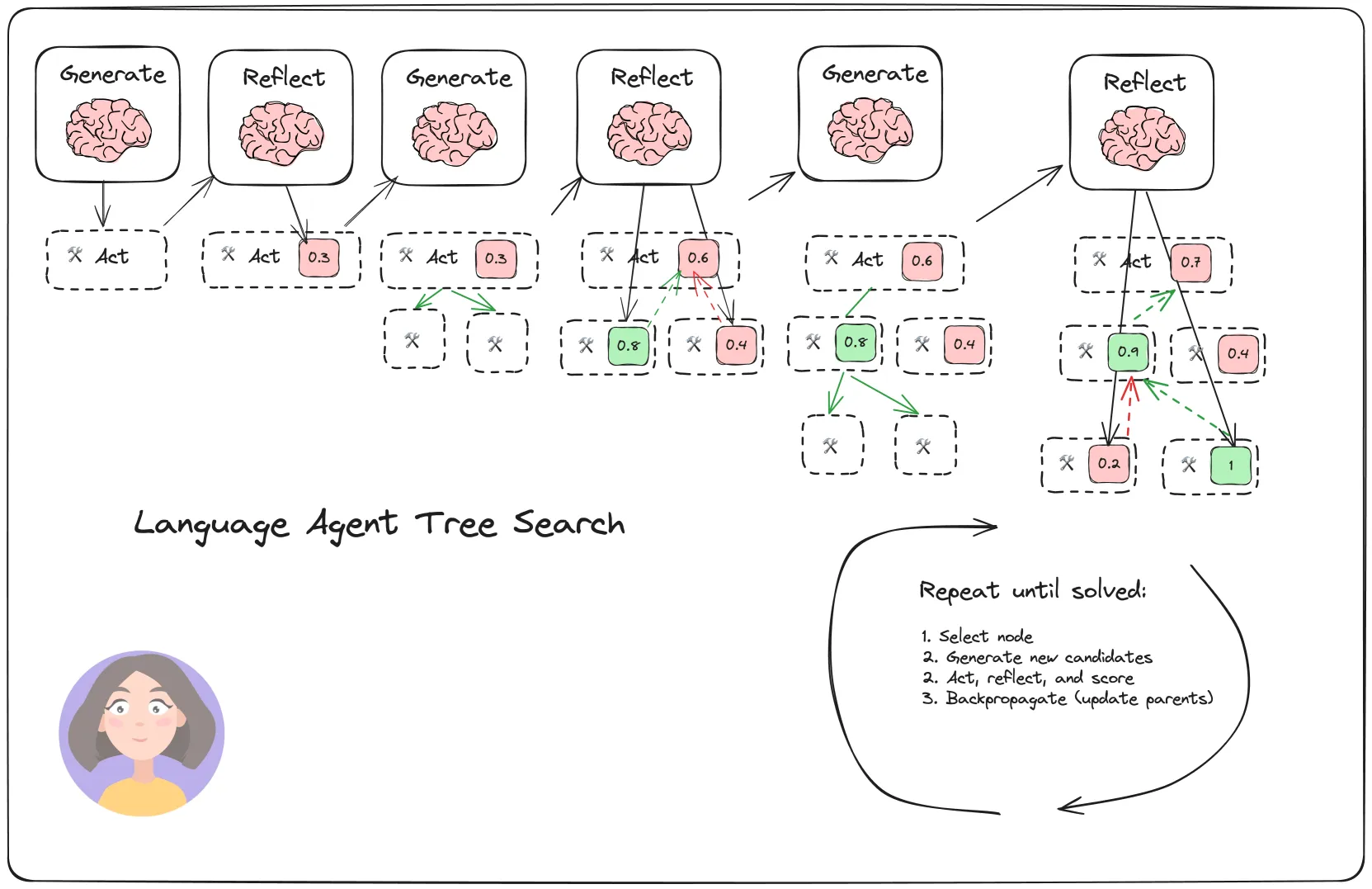
使用python实现的llamaindex-lats-agent-demo,java版的应该还没框架直接支持。
目前的提示词场景ToT
原理类似上面,有状态节点,拆分子任务,号称是ToT的加强版,具有反思、外部反馈
改善推理和决策,反向传播等
demo见文档:https://mxkw.yuque.com/dsd6et/qbm/fqoi5viogs1g0rd8#BI6Rn