240701_昇思学习打卡-Day13-Vision Transformer图像分类
Transformer最开始是应用在NLP领域的,拿过来用到图像中取得了很好的效果,然后他就要摇身一变,就叫Vision Transformer。
该部分内容还是参考太阳花的小绿豆-CSDN博客大佬的视频11.1 Vision Transformer(vit)网络详解_哔哩哔哩_bilibili及查阅资料,以下为本人学习总结,肯定没有大佬详尽,建议去看大佬视频。
模型网络结构
Vision Transformer(ViT)模型主要由三个模块组成,以下是模型框架:
- Linear Projection of Flattened Patches(Embedding层)
- Transformer Encoder(图右侧有给出更加详细的结构)
- MLP Head(最终用于分类的层结构)
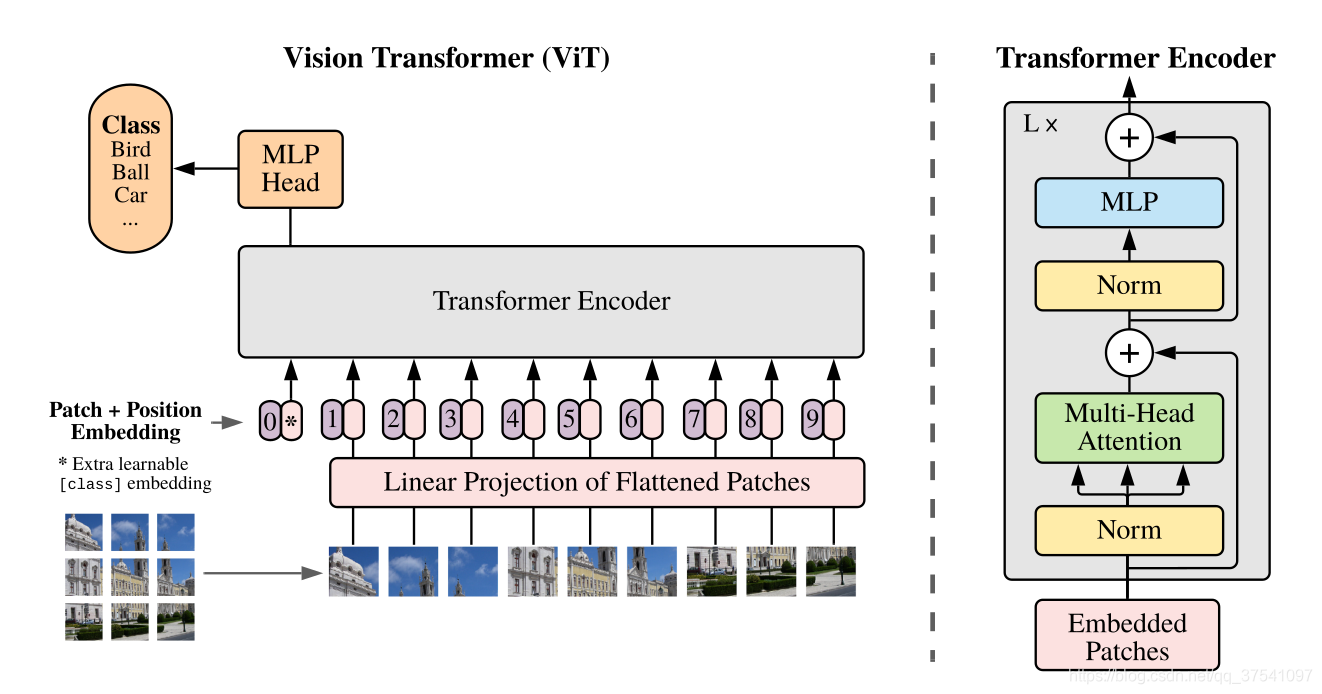
首先,Transformer是从NLP领域学习改进过来的嘛,所以人家训练的认识的是字,也就是一串token(向量)序列,而我们直接给模型输入一个图片,人认识都不认识,更别说预测了。
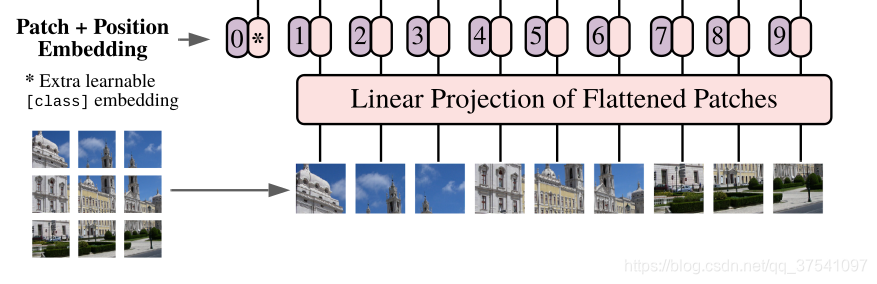
Embedding层(Linear Projection of Flattened Patches)结构
对于图像数据而言,其数据格式为H,W,C,我们就要先通过Embedding层(图中的Linear Projection of Flattened Patches)给他转换一下,尝试把图片分为一堆小的Patches,此处把输入图片按照16*16的Patch进行划分(就图中左下角画的九宫格这个意思),每个Patch数据shape会变为16,16,3,通过映射得到一个长度为768的向量(token),即16,16,3->768。
代码实现中直接使用卷积层,ViT也有好几种类型,此处以ViT-B/16为例,直接使用shape=16X16,stride=16,个数768的卷积层,原输入图像通过这层卷积后维度由224,224,3变成14,14,768,然后把H和W两个维度展平(两个14),即14,14,768->196,768,此时这个二维矩阵正是Transformer想要的。
在输入Transformer Encoder之前要加上classtoken以及Position Embedding。这个classtoken是用于分类的,是一个可训练的参数,数据格式和上面得到的token一样都是一个向量,此处就是一个长度为768的向量,维度为1,768,与上面的token拼接在一起就是197,768,此外,还要添加一个Position Embedding用于定位,定位拆出来的这个块在原图的什么位置,如果没有这个Position Embedding,这就是一堆乱的拼图,有时候我们不知道原图的情况下,玩儿4*4的拼图都费劲,更别说让机器啥都不知道来拼16X16的拼图了,这个Position Embedding原理如下:

图片右侧有色条,最上面最黄色的部分就是相似度最高的,可以看图中左上角第一张图,他的左上角(1,1)的位置就是它本身嘛,肯定就是最像自己的地方,所以在颜色表现上就是最黄的,第一行和第一列都是和他相似度比较高的,所以颜色都在色条的上半部分。就通过这个表现记录了其位置。
Position Embedding是直接在原来的token上进行相加,所以shape应该与原来的token保持一致,为197,768,在这个加法过程中维度不会发生变化,是直接相加。
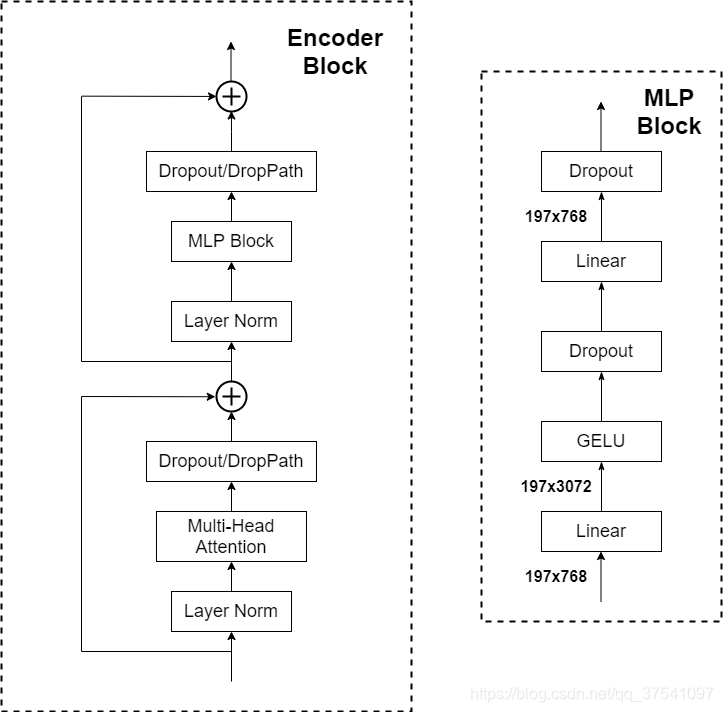
Transformer Encoder
Transformer Encoder其实就是重复堆叠Encoder Block L次,下图是大佬绘制的Encoder Block,主要由以下几部分组成:
- Layer Norm,这种Normalization方法主要是针对NLP领域提出的,这里是对每个token进行Norm处理
- Multi-Head Attention,这个结构之前在讲Transformer中很详细的讲过,见上期240630_昇思学习打卡-Day12-Transformer中的Multiple-Head Attention-CSDN博客
- Dropout/DropPath,在原论文的代码中是直接使用的Dropout层,在但
rwightman实现的代码中使用的是DropPath(stochastic depth),可能后者会更好一点。- MLP Block,如图右侧所示,就是全连接+GELU激活函数+Dropout组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻4倍
[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]
MLP Head
在Transformer Encoder中,输出的shape和输入得shape是一样的,输出的还是197,768,出来之后我们要添加一个Layer Norm层,把我们之前添加进去的classtoken拿出来,这么费工夫不就是为了最后得到这个分类信息嘛,然后通过MLP Head得到最终的分类结果,在训练自己的数据集时,这一层只需要一个简单的Linear,在原论文训练数据集上较为复杂,由Linear+tanh激活函数+Linear组成。
以下为大佬本人画的整个流程图,极其详尽,吹爆了:

因为近期期末周,所以记录的可能较为简单
打卡图片:
参考博客:
11.1 Vision Transformer(vit)网络详解_哔哩哔哩_bilibili
详解Transformer中Self-Attention以及Multi-Head Attention_transformer multi head-CSDN博客
以上图片均引用自以上大佬博客,如有侵权,请联系删除