在深度学习与大规模预训练的推动下,视觉基础模型展现出了令人印象深刻的泛化能力。这些模型不仅能够对任意图像进行分类、分割和生成,而且它们的中间表示对于其他视觉任务,如检测和分割,同样具有强大的零样本能力。然而,这些模型是否能够理解图像所描绘的三维世界结构,仍然是一个值得探讨的问题。
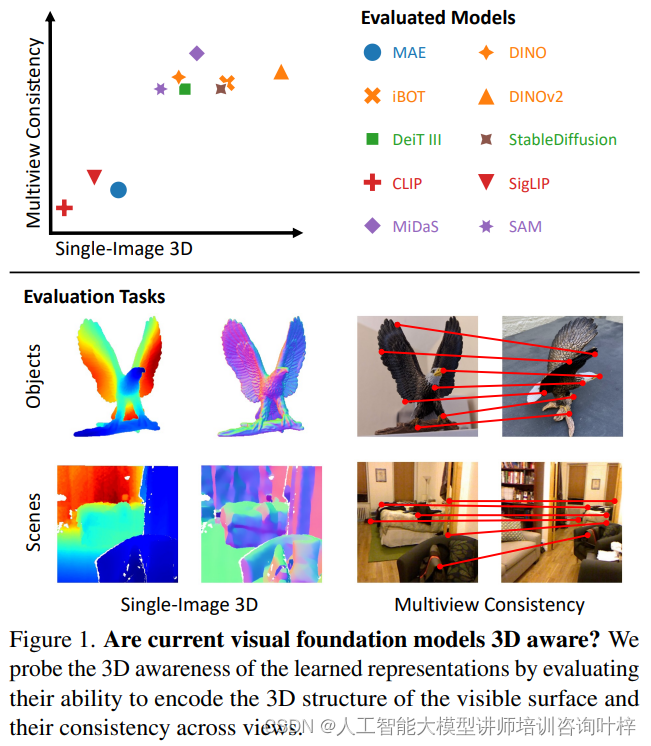
研究者们通过评估模型对可见表面的3D结构编码能力以及在不同视角下的一致性来探测它们的3D意识。他们使用了特定的任务探针和零样本推理程序来评估冻结特征的3D意识。
实验结果揭示了现有模型在3D意识方面存在一些局限性。例如,一些模型虽然能够在小视角变化下准确匹配对象和场景,但在大视角变化下性能急剧下降,这表明它们缺乏3D一致性。
尽管某些模型在单视图任务上表现良好,但它们在多视图任务上的表现却不尽如人意。这些发现表明,尽管视觉基础模型在2D数据上训练,但它们在一定程度上能够学习到3D结构的表示,但这种学习并不完美,尤其是在处理复杂视角变化时。
在视觉计算领域,3D感知视觉表示是指模型能够理解和表达场景的三维几何结构的能力。这种能力对于实现高级视觉任务至关重要,如三维重建、物体识别和场景理解等。这种表示的核心在于模型能够准确地编码场景的基本三维属性,主要包括深度和方向。
深度感知意味着模型能够为图像中的每个像素点估计其相对于观察者或相机的距离。这不仅仅是一个简单的任务,因为深度信息通常不会直接在图像中给出。模型必须通过分析图像中的各种线索,比如物体的大小、遮挡关系以及光线和阴影,来推断出深度信息。
方向感知则关注于模型对物体表面朝向的识别能力。在三维空间中,物体的每个表面都有其特定的朝向,这影响了它在图像中的表现形式。模型需要能够识别出这些表面的方向,以便更准确地理解物体的形状和空间布局。
3D感知还强调了在不同视角下观察同一物体或场景时,模型表示的一致性。这种一致性至关重要,因为它使得模型能够在视角变化时维持对物体和场景的理解。例如,无论物体是从正面、侧面还是顶部观察,模型都应该能够识别出物体的关键特征,并保持对这些特征的空间关系的一致性理解。
这种多视角一致性的能力对于实现高级的视觉任务至关重要,如三维重建、物体识别和场景理解。它要求模型不仅要在单个图像上表现出强大的三维理解能力,还要能够在多个图像之间建立准确的对应关系,即使这些图像是从不同的角度和条件下捕获的。
3D感知视觉表示要求模型在没有任何明确三维信息的情况下,通过分析二维图像来推断出场景的三维结构。这需要模型具备深度和方向的感知能力,并且在不同视角下保持这种感知的一致性,从而实现对三维世界的准确理解和表达。
对3D形状的表示方法经历了从简单到复杂,再从复杂到简洁的演变过程。在早期,研究者们尝试使用2.5D草图来捕捉场景的深度信息。这种方法通过为每个像素点分配一个深度值来创建一个深度图,从而在二维图像上模拟三维空间的感知。然而,2.5D草图并没有提供一个完整的三维结构,它更多地被看作是一种过渡性的表示方法,它为后续更高级的3D建模奠定了基础。
进一步,广义圆柱体等参数化几何形状被用来近似物体的三维形态。这些方法通过定义物体的基本几何属性,如大小、方向和形状,来构建一个简化的三维模型。尽管这些模型在某些应用中非常有用,但它们通常无法捕捉到物体复杂和多变的几何细节。
随着计算能力的提升和深度学习的发展,现代的3D表示方法开始转向使用密集特征网格。这些方法利用卷积神经网络(CNN)和变换器模型(如Vision Transformer)的强大能力,从图像中提取丰富的特征信息。这些特征不仅包含了图像的局部细节,还涵盖了全局的上下文信息,为3D理解和重建提供了更为丰富的数据基础。
在这种方法中,图像被处理成一个密集的网格,每个网格点都关联了一系列的特征向量。这些特征向量捕捉了图像在该点的多尺度和多维度信息,从而使得模型能够更准确地理解和重建三维空间中的细节。
除了密集特征网格,一些模型也开始使用标记集来表示图像内容。这些标记是通过聚类或其他无监督学习方法获得的,它们代表了图像中的不同区域或物体。这种方法的优势在于它的灵活性和可扩展性,可以适应不同的视觉任务和数据集。
总的来说早期的3D表示方法在直观上具有明显的3D意识,因为它们直接处理和建模三维空间中的几何形状。然而,现代的基于特征的方法,尽管在许多视觉任务上表现出色,但它们是否以及如何在没有明确3D结构的情况下编码3D信息,仍然是一个开放的问题。
现代方法的一个关键优势是它们的灵活性和可扩展性。通过使用密集的特征表示,模型能够捕捉到更加丰富和细微的视觉信息,这在处理复杂场景和多样化任务时尤其有用。然而,这也带来了新的挑战,即如何解释和理解这些高维特征空间中的信息。
为了评估视觉基础模型的3D意识,研究者们设计了一系列实验,包括单图像3D理解和多视角一致性评估。实验使用了特定任务的探针和零样本推理方法,对冻结的特征进行了评估。研究者们主要关注视觉变换器模型,这些模型被提出作为通用的骨干网络,或者在跨任务或领域的泛化性能上表现出色。
 评估的视觉模型的概览,包括它们的架构、监督类型和使用的数据集
评估的视觉模型的概览,包括它们的架构、监督类型和使用的数据集
研究者们发现,尽管模型能够为图像中的每个像素点估计深度,但它们在准确性上存在显著差异。一些模型能够生成准确且详细的深度图,捕捉到场景中的细微结构,例如动物的耳朵或椅子的腿。然而,也有模型生成的深度估计模糊且不准确,这表明它们可能只捕获到了粗糙的先验信息,如"地面像素靠近观察者"。
 不同预训练模型在单图像深度估计任务上的表现,包括它们对深度的编码能力
不同预训练模型在单图像深度估计任务上的表现,包括它们对深度的编码能力
在表面法线估计方面,结果与深度估计类似。一些模型表现出色,能够捕捉到物体和场景表面的粗糙方向,而其他模型则难以捕捉到超出基本先验的任何信息。这在比较对象和场景的预测时变得更加明显,因为对象由于姿态变化大而具有更少的先验信息。
 不同模型在表面法线估计任务上的表现,包括它们对物体和场景表面方向的编码能力
不同模型在表面法线估计任务上的表现,包括它们对物体和场景表面方向的编码能力
在多视图一致性方面,研究者们分析了模型在不同视角下估计图像对应关系的能力。这些能力对于正确聚合跨视角信息至关重要,是重建和定位流程的核心。
实验结果表明,尽管模型能够在小视角变化下准确匹配对象和场景,但在大视角变化下性能迅速下降。这一发现表明,尽管模型能够编码表面属性,但它们在多视角一致性方面仍然存在不足。特别是,一些模型在小视角变化下表现出色,但在大视角变化下性能急剧下降,这暗示了它们缺乏三维一致性。
 不同模型在几何对应估计任务上的表现,特别是在小视点变化和大视点变化下的表现
不同模型在几何对应估计任务上的表现,特别是在小视点变化和大视点变化下的表现
研究者们还探讨了语义对应与几何对应之间的关系。尽管自监督和生成模型在估计语义对应方面表现出色,但这并不直接转化为良好的三维一致性。例如,某些模型在小视角变化下能够准确估计对应关系,但在大视角变化下则表现出系统性的错误,这些错误似乎局限于语义相关的类别。
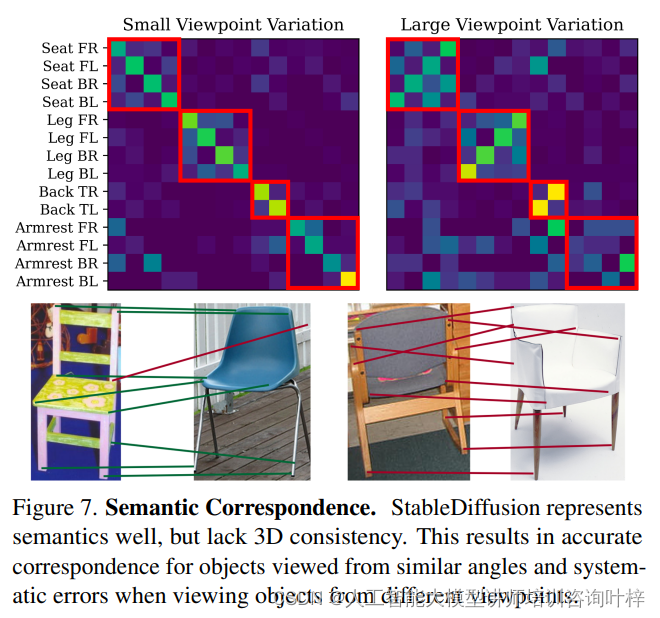 StableDiffusion模型在语义对应和几何对应任务上的表现,揭示了模型在3D一致性方面的限制
StableDiffusion模型在语义对应和几何对应任务上的表现,揭示了模型在3D一致性方面的限制
实验结果强调了当前视觉模型在3D意识方面的局限性。尽管它们在编码可见表面的深度和方向方面取得了一定的进展,但在多视角一致性方面仍然面临挑战。这些发现为进一步研究视觉模型的三维意识提供了有价值的见解,并可能激发对更全面基准测试的兴趣,以更好地理解视觉模型如何表示和处理三维信息。
论文链接:https://arxiv.org/abs/2404.08636
GitHub 地址:https://github.com/Cornell-RL/drpo