
RAG面临的挑战和问题
在当前AI的落地应用中,最火热的应用首推检索增强生成(Retrieval-Augmented Generation)。它的目的是根据用户的问题,从一个大规模的文档集合中检索出相关的文档,并从中抽取出最合适的答案。RAG的应用场景非常广泛,例如智能客服、知识图谱构建、对话系统等。 
然而,幻觉是笼罩在RAG应用上,挥之不去的乌云。一般来说RAG会经历,原始数据向量化->语义搜索数据召回->大模型整合输出。RAG因此也面临着一些挑战和问题,其中最主要的有以下三个方面:
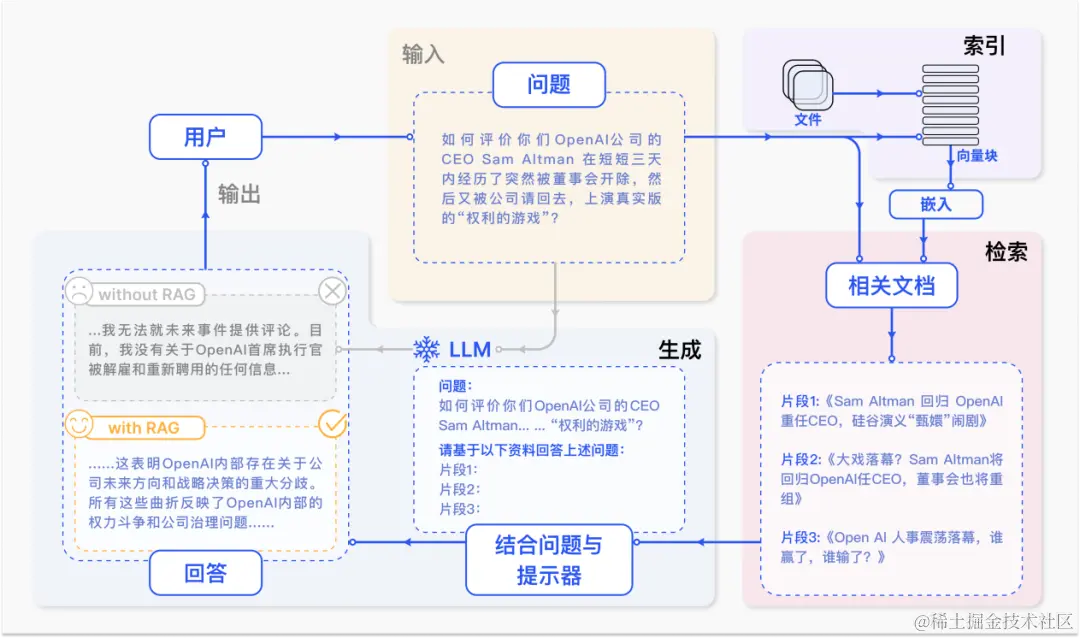
-
数据向量化的信息损失。为了实现高效的文档检索,通常需要将原始的文本数据转化为数值向量,这一过程又称为数据向量化(Data Embedding)。数据向量化的目的是将文本数据映射到一个低维的向量空间中,使得语义相似的文本在向量空间中的距离较近,而语义不相似的文本在向量空间中的距离较远。然而,数据向量化也会导致一定程度的信息损失,因为文本数据的复杂性和多样性很难用有限的向量来完全表达。因此,数据向量化可能会忽略一些文本数据的细节和特征,从而影响文档检索的准确性。
-
语义搜索的不准确。在RAG中,语义搜索(Semantic Search)是指根据用户的问题,从文档集合中检索出与问题语义最相关的文档,这一过程又称为数据召回(Data Retrieval)。语义搜索的难点在于如何理解用户的问题和文档的语义,以及如何衡量问题和文档之间的语义相似度。目前,语义搜索的主流方法是基于数据向量化的结果,利用向量空间中的距离或相似度来度量语义相似度。然而,这种方法也存在一些局限性,例如向量空间中的距离或相似度并不一定能反映真实的语义相似度,而且向量空间中的噪声和异常值也会干扰语义搜索的结果。因此,语义搜索的准确率也无法有100%的保证。
-
LLM的幻觉。在RAG中,LLM(Large Language Model)是指一个大规模的预训练语言模型,它的作用是根据用户的问题和检索到的文档,生成最合适的答案,这一过程又称为数据整合(Data Integration)。LLM的优势在于它能够利用海量的文本数据进行自我学习,从而具备强大的语言理解和生成能力。然而,LLM也存在一些问题,例如LLM可能会产生一些与事实不符或者逻辑不通的答案,这种现象又称为LLM的幻觉(Hallucination)。LLM的幻觉的原因有很多,例如LLM的预训练数据可能存在一些错误或偏见,LLM的生成过程可能存在一些随机性或不确定性,LLM的输出可能受到一些外部因素的影响等。因此,LLM的准确率也是不可靠的。
综上所述,我们可以得到这样一个公式,
RAG的输出的准确率=
向量信息保留率 * 语义搜索准确率 * LLM准确率由于这三个环节是串行的,准确率最终是三者的乘积,因而任何一个环节的短板都将导致整体的准确率完全无法保证。
目前来看,业界针对RAG的优化也主要是围绕这三个环节开展
- 通过COT等方式提升LLM对问题的理解程度
- 使用sentence window retrive、rerank等方式提升语义搜索的准确率
- 通过针对的选择和优化embedding算法来最大化的保留原始数据的信息。
然而由于最终结果是三者的乘积,即便是耗费大量精力将每个环节都优化到90%,最终乘积也只有72%。
那么,有没有一种方法,可以避免数据向量化和语义搜索的问题,直接利用原始数据和LLM的交互,提高RAG的准确率和效率呢?本文的目的就是介绍一种不用向量也可以RAG的方法,它基于结构化数据和LLM的交互,实现了一种新颖的RAG模式,具有准确、高效、灵活、易扩展等优势。
基于结构化数据来RAG
我们不妨换个思路,上文拆解的三个环节,LLM是自然语言对话的根基无可替代,但是RAG是否必须向量化,必须基于语义召回呢?
并非如此,在未引入LLM之前,传统检索信息的方式是通过将数据结构话,将特征提前抽象为列,通过有限的标签集进行描述,最终通过行式数据库存储,以标准sql来查询。传统数据检索的方式胜在准确且高效,弱势则在于查询存在一定门槛,交互上缺少人味。如果原始数据本身就是结构化,标签化的,那么我们大可不必将这部分的数据做embeding。

结构化数据的特点是数据的特征和属性都是明确的,可以用有限的标签集进行描述,可以用标准的查询语言进行检索。不用向量也可以RAG的方法的基本思路就是利用结构化数据和LLM的交互,避免数据向量化和语义搜索的问题,直接使用标准查询和原始数据进行回复。
基于这个思路,以餐饮生活助手为例,整体的交互处理思路如下:
-
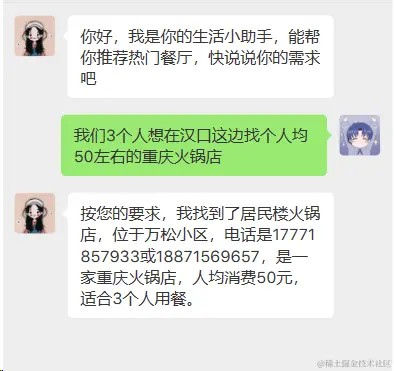
用户提问。用户输入一个自然语言的问题,例如"我们3个人想找个人均50左右的重庆火锅店"。
-
LLM提取核心信息并形成标准查询。LLM根据用户的问题,提取出核心的信息和条件,例如人数、价格、类型等,并形成一个标准的查询语句,例如
{
"numOfPeople": 3,
"avgOfAmount": 50,
"type": "重庆火锅"
} -
查询结构化数据。LLM用这个查询语句去检索结构化数据,得到相关的数据记录,例如:
{
"shopType": 10,
"shopName": "居民楼火锅",
"branchName": "万松园店",
"address": "万松小区",
"phoneNo": "17771857933",
"phoneNo2": "18871569657"
} -
LLM整合回复。LLM根据这些数据记录,生成最合适的答案,输出给用户,例如"按您的要求,我找到了居民楼火锅店,位于万松小区,电话是17771857933或18871569657,是一家重庆火锅店,人均消费50元,适合3个人用餐。"
这就是基于结构化数据RAG的基本流程,它的优势和特点有以下几点:
-
准确。基于结构化数据RAG避免了数据向量化和语义搜索的问题,直接利用原始数据和LLM的交互,提高了RAG的准确率。因为结构化数据的特征和属性都是明确的,可以用有限的标签集进行描述,可以用标准的查询语言进行检索,因此不会出现信息损失或语义不匹配的情况。而且,LLM只需要根据用户的问题,提取出核心的信息和条件,并形成标准的查询语句,而不需要理解整个文档的语义,因此也减少了LLM的幻觉的可能性。
-
高效。基于结构化数据RAG提高了RAG的效率,因为它省去了数据向量化和语义搜索的过程,直接使用标准查询和原始数据进行回复。数据向量化和语义搜索的过程是非常耗时和资源密集的,因为它们需要对海量的文本数据进行处理和计算,而且还需要存储和更新大量的向量数据。而结构化数据RAG只需要对结构化数据进行标准查询,这是一个非常快速和简单的过程,而且结构化数据的存储和更新也比向量数据更容易和更节省空间。
-
灵活。基于结构化数据RAG提高了RAG的灵活性,因为它可以适应不同的数据源和查询需求,只要数据是结构化的,就可以用这种方法进行RAG。结构化数据是一种非常通用和广泛的数据格式,它可以表示各种各样的信息和知识,例如表格、数据库、XML等。而且,结构化数据的查询语言也是非常标准和通用的,例如SQL、SPARQL等。因此,结构化数据RAG的方法可以应用于不同的领域和场景,只要将用户的问题转化为相应的查询语言,就可以实现RAG。
-
易扩展。基于结构化数据RAG提高了RAG的易扩展性,因为它可以方便地增加或修改数据和查询,而不需要重新进行数据向量化和语义搜索。数据向量化和语义搜索的过程是非常固定和封闭的,一旦数据或查询发生变化,就需要重新进行数据向量化和语义搜索,这是一个非常耗时和复杂的过程,而且可能会影响已有的数据和查询的结果。而结构化数据RAG只需要对结构化数据进行增加或修改,就可以实现数据的更新,而且不会影响其他数据的查询。而且,结构化数据RAG也可以方便地增加或修改查询,只要修改查询语句,就可以实现查询的更新,而且不会影响其他查询的结果。
基于结构化数据来RAG实战
为了更好地展示结构化数据来RAG的方法的实际效果,我们以餐饮生活助手为例,给出用户提问和回复的示例,以及餐饮生活助手RAG的代码实战。
餐饮生活助手是一个基于结构化数据RAG的方法的应用,它的目的是根据用户的需求,从一个大规模的餐饮数据集中检索出最合适的餐厅,并提供相关的信息和服务。餐饮数据集是一个结构化的数据集,它包含了各种各样的餐厅的信息,例如名称、类型、地址、电话、价格、评分、评论等。餐饮生活助手的核心是一个LLM,它能够根据用户的问题,提取出核心的信息和条件,并形成标准的查询语句,然后用这个查询语句去检索餐饮数据集,得到相关的数据记录,再根据这些数据记录,生成最合适的答案,输出给用户。

为了实现餐饮生活助手RAG的Langchain代码实战,我们需要完成以下几个步骤:
-
定义餐饮数据源。我们需要将餐饮数据集转化为Langchain可以识别和操作的数据源,例如数据库、文件、API等,注册到Langchain中,并提供统一的接口和方法,让LLM的代理可以方便地访问和查询数据源。例如,我们可以将餐饮数据封装为一个API后,并结构化描述该接口的调用方式,并通过以下的代码,将其注册到Langchain中:
from langchain.chains.openai_functions.openapi import get_openapi_chain
fucntion_call_template = '{"openapi":"3.0.1","info":{"version":"v1","title":"Restaurant Query API"},"servers":[{"url":"https://www.example.com"}],"paths":{"/restaurant":{"post":{"tags":["restaurant-query"],"summary":"Query restaurants","operationId":"queryRestaurants","requestBody":{"content":{"application/json":{"schema":{"ref":"#/components/schemas/QueryRequest"}}}},"responses":{"200":{"description":"Query results","content":{"application/json":{"schema":{"ref":"#/components/schemas/QueryResponse"}}}}}}}},"components":{"schemas":{"QueryRequest":{"type":"object","properties":{"numOfPeople":{"type":"integer","description":"Number of people dining"},"avgOfAmount":{"type":"integer","description":"Average spending amount per person"},"type":{"type":"string","description":"Cuisine type"}}},"QueryResponse":{"type":"object","properties":{"shopType":{"type":"integer","description":"Restaurant type code"},"shopName":{"type":"string","description":"Restaurant name"},"branchName":{"type":"string","description":"Branch name"},"address":{"type":"string","description":"Address"},"phoneNo":{"type":"string","description":"Phone number"},"phoneNo2":{"type":"string","description":"Secondary phone number"}}}}}}'
chain = get_openapi_chain(
spec = fucntion_call_template
) -
定义LLM的代理。我们需要定义一个LLM的代理,它可以根据用户的问题,提取出核心的信息和条件,并形成标准的查询语句,然后用这个查询语句去检索餐饮数据源,得到相关的数据记录,再根据这些数据记录,生成最合适的答案,输出给用户。这可以通过Langchain的代理(Agent)来实现。代理管理器可以让开发者通过简单的编程,定义不同的LLM的代理,以及它们的功能和逻辑,并提供统一的接口和方法,让用户可以方便地与LLM的代理进行交互。
通过Langchain内置的openapi-function call来实现复杂逻辑内置在函数内了
chain("我们3个人想找个人均50左右的重庆火锅店")
-
运行LLM的代理。我们需要运行LLM的代理,让用户可以与之进行交互,将LLM的代理部署到不同的平台和渠道,例如Web、微信、Telegram等,并提供统一的接口和方法,让用户可以方便地与LLM的代理进行交互。
本文直接通过Langchain内置的openapi-function call来实现,代码仅作为演示,实际业务情况可能得结合代码内置业务流程来实现。比如通过function call解析用户问题之前还需要判断用户的问题是否与餐厅咨询相关,当解析到的查询维度太少时,需要引导式提问等等。
总结和展望
随着chatbot的流行,基于向量化的RAG模型似乎已然形成了RAG的标准模式。本文试图跳出向量化的RAG模型的模式束缚,从RAG的基础定义出发提出不用向量也可以RAG的想法。通过结构化数据和LLM的交互,这并非一种新颖的RAG模式,但在现阶段,却是让chatbot达到可落地目标的最优手段。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
