前言
毫无疑问,2024将是人工智能丰收年,开始寒假的我,准备先把LangChain捋一遍。
这篇文章来学习下callback机制, 之前聊过AutoGen的callback机制,我们来对比下。
回调和异步
作为js开发者,对于回调函数和异步编程非常熟悉。在事件监听、Ajax请求和定时器中,我们常会使用回调函数和打理异步任务。我们通过代码来熟悉下python的方式。
# Python asyncio模块是用于异步编程的标准库,实现了协程、事件循环和异步I/O等功能
import asyncio
async def rectangleArea(w, h, callback):
print("开始计算矩形的面积...")
# 等待0.5秒
await asyncio.sleep(0.5)
= x * y
print("计算结束")
async def circleArea():
print("开始圆形计算")
await asyncio.sleep(1)
print("完成圆形计算")
# async 和 在js里一样, 是函数修饰符,内部可以使用await
async def main():
print("主线程开始...")
task1 = asyncio.create_task(rectangleArea(3, 4, print_result))
task2 = asyncio.create_task(circleArea())
await task1
await task2
print("主线程结束...")
asyncio.run(main())当代码执行到sleep时,task会暂停,并开始执行另一个任务,这就是异步,跟js 里的async await 有些区别。

LangChain的Callback机制
LangChain在打理AI应用时,有太多需要通过CallbackHandler来实现,比如日志记录、监控、数据流处理等。
我们来看一个需求,要求在LangChain执行完一个LLM工作后,将输出写入output.log文件
from loguru import logger
# langchain callback 机制提供了各种callbackHandler,这里是File,处理文件加调
from langchain.callbacks import FileCallbackHandler
# 最基本的LLM工作Chain,
from langchain.chain from LLMChain
# Prompt模板
from langchain.prompts import PromptTemplate
logFile = "output.log"
logger.add(logfile, colorize=True, enqueue=True)
handler = FileCallbackHandler(logfile)
llm = OpenAI()
prompt = PromptTemplate.from_template("1 + {number} = ")
chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler], verbose=True)
answer = chain.run(number=2)
logger.info(answer)上面是一个简单的callback例子。在之前熟悉的LLMChain实例化过程中,我们传入了callbacks参数,它是一个数组,里面是我们定义的文件回调处理。当大模型交互完成后,将结果写入logger。
自定义回调函数
我们来看一个老喻干货店客服中的例子。
# Python asyncio模块是用于异步编程的标准库,实现了协程、事件循环和异步I/O等功能
import asyncio
# 从typing模块导入Any Dict List 类型
from typing import Any, Dict, List
# ChatOpenAI
from langchain.chat_models import ChatOpenAI
# 从schema 中引入LLMResult、HumanMessage
from langchain.schema import LLMResult, HumanMessage
from langchain.callbacks.base import AsyncCallbackHandler, BaseCallbackHandler上述代码引入了AsyncCallbackHandler 异步任务处理器、BaseCallbackHandler LangChain回调基类,等下可以自定义
基于 BaseCallbackHandler 创建异步任务处理类
class MyDryFoodShopSyncHandler(BaseCallbackHandler):
# 当llm 接收到新token时 触发
def on_llm_new_token(self, token: str, **kwargs) -> None:
print(f"干货数据: token: {token}")
# 创建异步回调处理器
class MyDryFoodAsyncHandler(AsyncCallbackHandler):
# 在llm 开始工作前
async def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> None:
print("正在获取干货数据...")
await asyncio.sleep(0.5) # 模拟异步操作
print("干货数据获取完毕。提供建议...")
async def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
print("整理干货建议...")
await asyncio.sleep(0.5) # 模拟异步操作
print("祝你买货愉快!")
# 异步函数
async def main():
drayfood_shop_chat = ChatOpenAI(
max_tokens=100,
streaming=True,
callbacks=[MyDryFoodShopSyncHandler(), MyDryFoodAsyncHandler()], ) # 异步生成聊天回复
await drayfood_shop_chat.agenerate([[HumanMessage(content="哪种干货最适合炖鸡?只简单说3种,不超过60字")]])
# 运行主异步函数
asyncio.run(main())当用户在我的干货店里提出关于营养汤相关的问题时,我们的AI客服,每当新的Token生成时,会有打印。在与OpenAI进行交互前后,又有打印,并最后祝客户买货愉快。
计算Tokens 开销及成本控制
from langchain import OpenAI
# 聊天chain
from langchain.chains import ConversationChain
# memory
from langchain.chains.conversation.memory import ConversationBufferMemory
# 初始化大语言模型
llm = OpenAI(
temperature=0.5,
model_name="gpt-3.5-turbo-instruct")
# 初始化对话链
conversation = ConversationChain(
llm=llm,
memory=ConversationBufferMemory()
)
# 第一天的对话
# 回合1
conversation("我家明天要开party,我需要一些干海货。")
print("第一次对话后的记忆:", conversation.memory.buffer)
# 回合2
conversation("爷爷喜欢虾干,一两一只的。")
print("第二次对话后的记忆:", conversation.memory.buffer)
# 回合3 (第二天的对话)
conversation("我又来了,还记得我昨天为什么要买干海货吗?")
print("/n第三次对话后时提示:/n",conversation.prompt.template)
print("/n第三次对话后的记忆:/n", conversation.memory.buffer)如果我们需要确切计算tokens开销,就需要用到calblack。
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferMemory
from langchain.callbacks import get_openai_callback
# 初始化大语言模型
llm = OpenAI(temperature=0.5, model_name="gpt-3.5-turbo-instruct")
# 初始化对话链
conversation = ConversationChain(
llm=llm,
memory=ConversationBufferMemory()
)
# 使用context manager进行token counting
with get_openai_callback() as cb:
# 第一天的对话
# 回合1
conversation("我家明天要开party,我需要一些干海货。")
print("第一次对话后的记忆:", conversation.memory.buffer)
# 回合2
conversation("爷爷喜欢虾干,一两一只的。")
print("第二次对话后的记忆:", conversation.memory.buffer)
# 回合3 (第二天的对话)
conversation("我又来了,还记得我昨天为什么要买干海货吗?")
print("/n第三次对话后时提示:/n",conversation.prompt.template)
print("/n第三次对话后的记忆:/n", conversation.memory.buffer)
# 输出使用的tokens
print("\n总计使用的tokens:", cb.total_tokens)get_openai_callback 可以监控ConversationChain 的开销。正好我们可以计算在这些对话中使用的总 Tokens 数。
总计使用的tokens: 1023总结
通过callback, 我们可以去处理一些token开销,或LLM 任务log等的工作,收获还是可以的。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
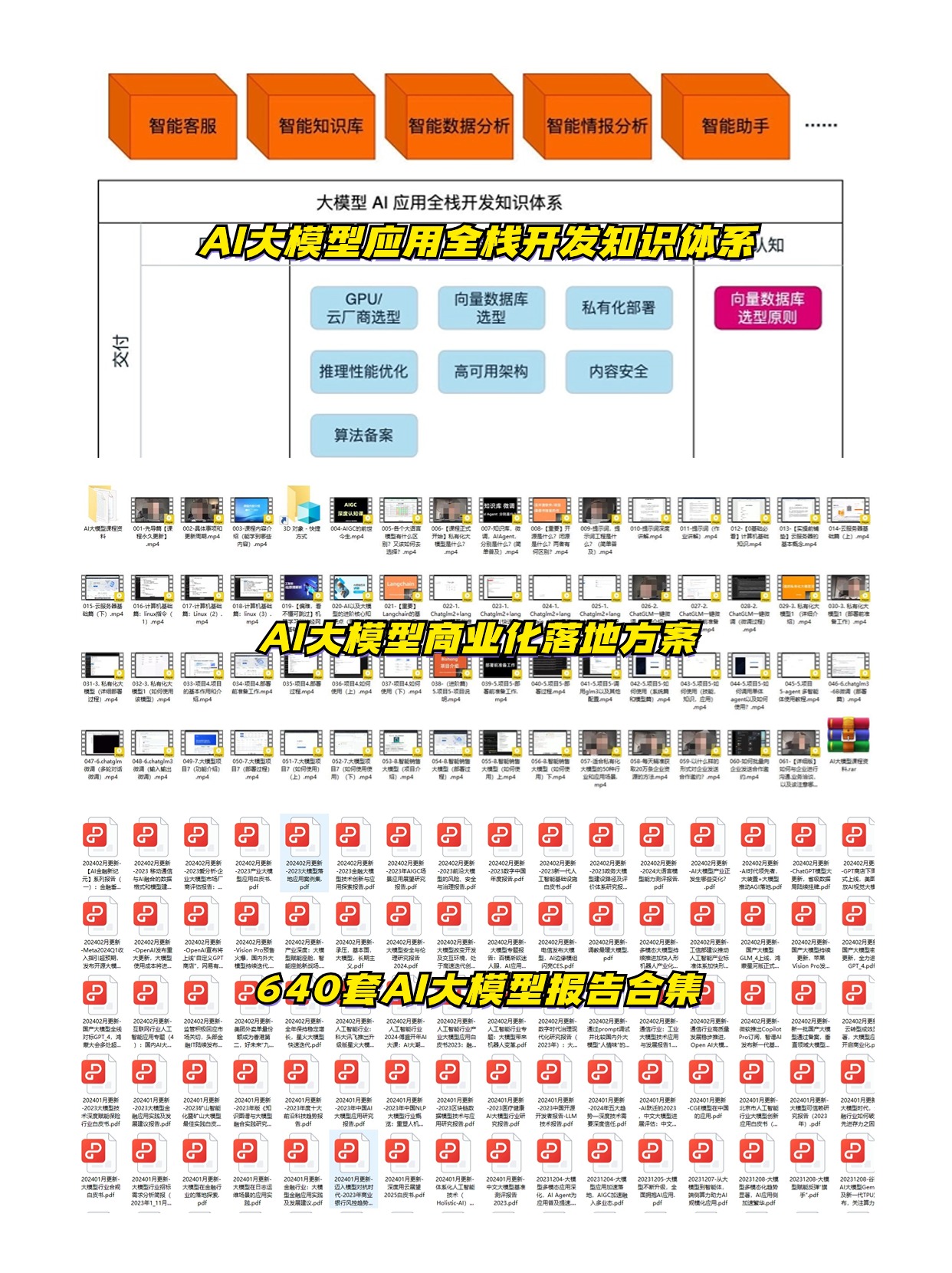
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
