LangChain是一个能够利用大语言模型(LLM,Large Language Model)能力进行快速应用开发的框架:
- 高度抽象的组件,可以像搭积木一样,使用LangChain的组件来实现我们的应用
- 集成外部数据到LLM中,比如API接口数据、文件、外部应用等;
- 提供了许多可自定义的LLM高级能力,比如Agent、RAG等等;
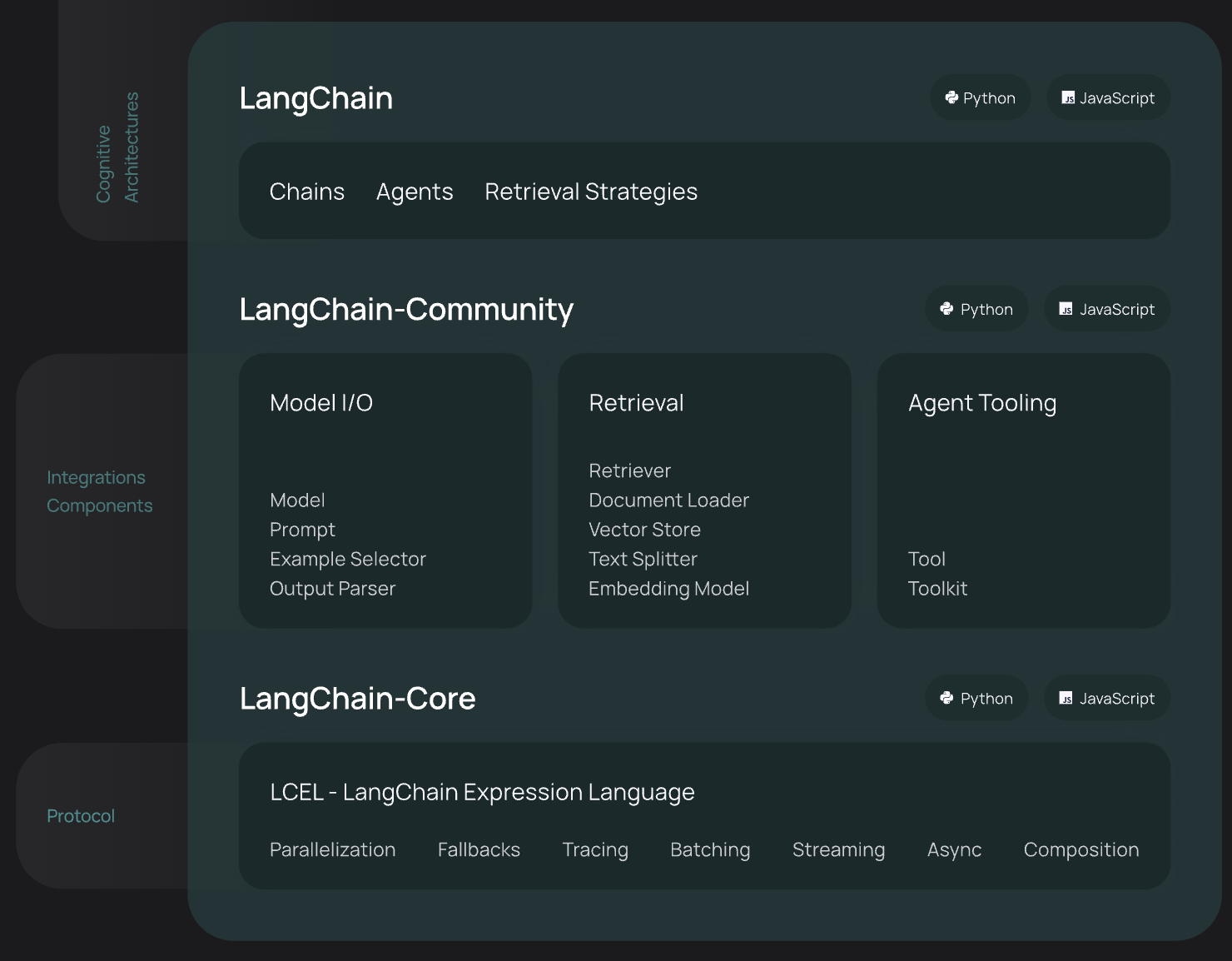
LangChain框架主要由以下六个部分组成:
- Model IO:格式化和管理LLM的输入和输出
- Retrieval:检索,与特定应用数据交互,比如RAG,与向量数据库密切相关,能够实现从向量数据库中搜索与问题相关的文档来作为增强LLM的上下文
- Agents:决定使用哪个工具(高层指令)的结构体,而tools则是允许LLM与外部系统交互的接口
- Chains:构建运行程序的block-style组合,即能将多个模块连接起来,实现复杂的功能应用
- Memory:在运行一个链路(chain)时能够存储程序状态的信息,比如存储历史对话记录,随时能够对这些历史对话记录重新加载,保证长对话的准确性
- Callbacks:回调机制,可以追踪任何链路的步骤,记录日志
- 该系列的第一篇文章介绍了LangChain Model I/O 涉及的Prompts、LLMs、Chat model、Output Parser等概念及其使用,
- 第二篇文章则介绍了RAG(Retrieval Augmented Generation,检索增强生成):在生成过程中,外部的数据会通过检索然后传递给LLM,让LLM能够利用这些新知识作为上下文。
今天这篇文章则要介绍另外一个核心且当前非常热门的组件:Agent。
- 在前面两个章节,已经出现过了许多关于Chains的概念和实践例子了,Chains是一系列的动作(actions)序列,这些动作可以是请求一个LLM、执行检索召回或者调用一个本地函数,但这些动作序列是硬编码(hardcoded in code)的,即动作的执行顺序是固定的,编写在代码逻辑中。
- 而Agents则是使用一个LLM(大型语言模型,Large Language Model)从动作集合中进行选择,也就是基于LLM的推理引擎(reasoning engine)来决定选择哪些actions和执行顺序 , 并且在agents中,这些actions一般都是tools。
初识Tools
LangChain官方文档:https://python.langchain.com/v0.1/docs/modules/tools/
实例代码:tools_agents.ipynb
Tools是Agents与外部世界交互的一种接口,它由以下几种东西构成:
- 工具的名称
- 工具的描述,即描述工具是用来做什么的
- 工具的输入,需要描述工具需要哪些输入,JSON schema
- 工具对应的函数
- 工具执行的结果是否需要直接返回给用户(这个是LangChain独有的设计,对于Openai等是不需要的)
这些信息是十分有用且重要的,它们会作为Prompt的一部分去指示LLM选择哪些actions也即tools,并且从用户输入中提取tools的输入内容,然后调用tools对应的function,LangChain称之为action-taking systems,从LLM选择了一个工具并调用其函数,便是take that action。
因此工具的名称、描述和输入参数的描述需要十分清晰,能够被LLM理解。
下面,让我们来看看一个工具实例的这些上述内容:
python
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_community.tools import WikipediaQueryRun
api_wrapper = WikipediaAPIWrapper(top_k_results=1, doc_content_chars_max=100)
tool = WikipediaQueryRun(api_wrapper=api_wrapper)
{'name': tool.name,
'description': tool.description,
'input': tool.args,
'return_direct': tool.return_direct,
}
"""
{'name': 'wikipedia',
'description': 'A wrapper around Wikipedia. Useful for when you need to answer general questions about people, places, companies, facts, historical events, or other subjects. Input should be a search query.',
'input': {'query': {'title': 'Query', 'type': 'string'}},
'return_direct': False}
"""
tool.run({"query": "langchain"})
"""
'Page: LangChain\nSummary: LangChain is a framework designed to simplify the creation of applications '
"""可以看到一个工具定义的name、description、input json schema(输入参数)和return_direct(结果是否直接返回用户),以及调用工具对应的函数 tool.run。
function call
OpenAI文档:https://platform.openai.com/docs/guides/function-calling
实例代码:tools_agents.ipynb
Agents是依托ChatGPT这类LLM的能力,而LangChain只是对其实现过程进行封装,便于开发者直接使用。因此,我们其实还是需要了解Agents脱离LangChain是如何运行的,或者说Agents原本是如何运行,这对我们使用Agents会有很大帮助。
更具体一点,Agents依托的是LLM的function call能力 ,在该系列的开篇 LangChain入门开发教程:Model I/O中提到了LLM的role包括system、assistant(AI)、user(human),但其实还有另外一种role:tool。
下面我们仍然使用我们的老朋友通义千问来演示Agents的演示,因为它是完全兼容Openai SDK的,当然你也可以使用Openai,仅需要替换api_key和base_url即可。
python
from openai import OpenAI
from datetime import datetime
import json
import os
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如果您没有配置环境变量,请在此处用您的API Key进行替换
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)定义工具列表
tools所需的基本要素仍然是一样的(除了LangChain自定义的return_direct):工具名称-name、工具描述-description、工具需要的参数描述-parameters、工具对应的函数-如get_current_time
python
# 定义工具列表,模型在选择使用哪个工具时会参考工具的name和description
tools = [
# 工具1 获取当前时刻的时间
{
"type": "function",
"function": {
"name": "get_current_time",
"description": "当你想知道现在的时间时非常有用。",
"parameters": {} # 因为获取当前时间无需输入参数,因此parameters为空字典
}
},
# 工具2 获取指定城市的天气
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "当你想查询指定城市的天气时非常有用。",
"parameters": { # 查询天气时需要提供位置,因此参数设置为location
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市或县区,比如北京市、杭州市、余杭区等。"
}
}
},
"required": [
"location"
]
}
}
]
# 模拟天气查询工具。返回结果示例:"北京今天是晴天。"
def get_current_weather(location):
return f"{location}今天是雨天。 "
# 查询当前时间的工具。返回结果示例:"当前时间:2024-04-15 17:15:18。"
def get_current_time():
# 获取当前日期和时间
current_datetime = datetime.now()
# 格式化当前日期和时间
formatted_time = current_datetime.strftime('%Y-%m-%d %H:%M:%S')
# 返回格式化后的当前时间
return f"当前时间:{formatted_time}。"Agents迭代
python
# 封装模型响应函数
def get_response(messages):
completion = client.chat.completions.create(
model="qwen-plus",
messages=messages,
tools=tools
)
return completion.model_dump()
def call_with_messages():
print('\n')
messages = [
{
"content": "杭州和北京天气怎么样?现在几点了?",
"role": "user"
}
]
print("-"*60)
# 模型的第一轮调用
i = 1
first_response = get_response(messages)
assistant_output = first_response['choices'][0]['message']
print(f"\n第{i}轮大模型输出信息:{first_response}\n")
if assistant_output['content'] is None:
assistant_output['content'] = ""
messages.append(assistant_output)
# 如果不需要调用工具,则直接返回最终答案
if assistant_output['tool_calls'] == None: # 如果模型判断无需调用工具,则将assistant的回复直接打印出来,无需进行模型的第二轮调用
print(f"无需调用工具,我可以直接回复:{assistant_output['content']}")
return
# 如果需要调用工具,则进行模型的多轮调用,直到模型判断无需调用工具
while assistant_output['tool_calls'] != None:
# 如果判断需要调用查询天气工具,则运行查询天气工具
if assistant_output['tool_calls'][0]['function']['name'] == 'get_current_weather':
tool_info = {"name": "get_current_weather", "role":"tool"}
# 提取位置参数信息
arguments = assistant_output['tool_calls'][0]['function']['arguments']
if 'properties' in arguments:
location = arguments['properties']['location']
else:
location = arguments['location']
tool_info['content'] = get_current_weather(location)
# 如果判断需要调用查询时间工具,则运行查询时间工具
elif assistant_output['tool_calls'][0]['function']['name'] == 'get_current_time':
tool_info = {"name": "get_current_time", "role":"tool"}
tool_info['content'] = get_current_time()
print(f"工具输出信息:{tool_info['content']}\n")
print("-"*60)
messages.append(tool_info)
assistant_output = get_response(messages)['choices'][0]['message']
if assistant_output['content'] is None:
assistant_output['content'] = ""
messages.append(assistant_output)
i += 1
print(f"第{i}轮大模型输出信息:{assistant_output}\n")
print(f"最终答案:{assistant_output['content']}")
call_with_messages()
"""
------------------------------------------------------------
第1轮大模型输出信息:{'id': 'chatcmpl-aaf6e713-622a-9a7c-9024-b3d5056830f9', 'choices': [{'finish_reason': 'tool_calls', 'index': 0, 'logprobs': None, 'message': {'content': '', 'role': 'assistant', 'function_call': None, 'tool_calls': [{'id': 'call_88713c110c0b4442af9039', 'function': {'arguments': '{"properties": {"location": "杭州市"}}', 'name': 'get_current_weather'}, 'type': 'function', 'index': 0}]}}], 'created': 1721742531, 'model': 'qwen-plus', 'object': 'chat.completion', 'system_fingerprint': None, 'usage': {'completion_tokens': 21, 'prompt_tokens': 230, 'total_tokens': 251}}
工具输出信息:杭州市今天是雨天。
------------------------------------------------------------
第2轮大模型输出信息:{'content': '', 'role': 'assistant', 'function_call': None, 'tool_calls': [{'id': 'call_e302c8e9f6f64cdebe2720', 'function': {'arguments': '{"properties": {"location": "北京市"}}', 'name': 'get_current_weather'}, 'type': 'function', 'index': 0}]}
工具输出信息:北京市今天是雨天。
------------------------------------------------------------
第3轮大模型输出信息:{'content': '', 'role': 'assistant', 'function_call': None, 'tool_calls': [{'id': 'call_a91a2b8fe5624c728bca82', 'function': {'arguments': '{}', 'name': 'get_current_time'}, 'type': 'function', 'index': 0}]}
工具输出信息:当前时间:2024-07-23 21:48:53。
------------------------------------------------------------
第4轮大模型输出信息:{'content': '目前,杭州市和北京市的天气都是雨天。现在的具体时间是2024年07月23日21点48分53秒。请记得带伞出行!', 'role': 'assistant', 'function_call': None, 'tool_calls': None}
最终答案:目前,杭州市和北京市的天气都是雨天。现在的具体时间是2024年07月23日21点48分53秒。请记得带伞出行!
"""- 在普通的LLM completion调用的基础上,将要素齐全的tools传递给LLM
- LLM会自己决定是否调用某一个tool,其信息存储在
tool_calls中,包括tool的名称、tool需要的实参。如果tool_calls=None,则不需要调用tool - 在Agents的迭代过程中,每一次function call的结果需要拼接在message列表,其role为上述的tool,content为tool对应的function执行结果
- 然后继续传递给LLM,来LLM来决定是否结束function call迭代,即可以将内容返回给用户了,或者继续循环上述的function call过程
LangChain Tools
实例代码:tools_agents.ipynb
接下来,我们再看看如何使用LangChain的封装来实现上一个章节同样功能的Agents迭代过程。
自定义工具
首先仍然是定义工具,在LangChain中,它提供了许多种自定义tools的方式。
1. @tool decorator
python
# Import things that are needed generically
from langchain.pydantic_v1 import BaseModel, Field
from langchain.tools import BaseTool, StructuredTool, tool
@tool
def get_current_weather(location: str) -> str:
"""当你想查询指定城市的天气时非常有用。"""
return f"{location}今天是雨天。"
get_current_weather.name, get_current_weather.description, get_current_weather.args
"""
('get_current_weather',
'get_current_weather(location: str) -> str - 当你想查询指定城市的天气时非常有用。',
{'location': {'title': 'Location', 'type': 'string'}})
"""这种方法的缺点是无法添加工具参数的描述。
2. tool decorator with JSON args
tool装饰器其实是支持传参的,我们可以通过pydantic定义tool的输入,加上输入的description,传参给tool装饰器。
python
class InputSchema(BaseModel):
location: str = Field(description="城市或县区,比如北京市、杭州市、余杭区等。")
@tool("get_current_weather", args_schema=InputSchema)
def get_current_weather(location: str):
"""当你想查询指定城市的天气时非常有用。"""
return f"{location}今天是雨天。"
get_current_weather.name, get_current_weather.description, get_current_weather.args
"""
('get_current_weather',
'get_current_weather(location: str) - 当你想查询指定城市的天气时非常有用。',
{'location': {'title': 'Location',
'description': '城市或县区,比如北京市、杭州市、余杭区等。',
'type': 'string'}})
"""3. BaseTool的子类
继承BaseTool,重写_run函数,_run便对应tool的function call
python
from typing import Optional, Type
from langchain.callbacks.manager import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
class InputSchema(BaseModel):
location: str = Field(description="城市或县区,比如北京市、杭州市、余杭区等。")
class GetCurrentWeatherTool(BaseTool):
name = "get_current_weather"
description = "当你想查询指定城市的天气时非常有用。"
args_schema: Type[BaseModel] = InputSchema
def _run(
self, location: str, run_manager: Optional[CallbackManagerForToolRun] = None
) -> str:
"""Use the tool."""
return f"{location}今天是雨天。"
get_current_weather = GetCurrentWeatherTool()
get_current_weather.name, get_current_weather.description, get_current_weather.args
"""
('get_current_weather',
'当你想查询指定城市的天气时非常有用。',
{'location': {'title': 'Location',
'description': '城市或县区,比如北京市、杭州市、余杭区等。',
'type': 'string'}})
"""4. StructuredTool
通过StructuredTool的from_function方法来构建tool
python
class InputSchema(BaseModel):
location: str = Field(description="城市或县区,比如北京市、杭州市、余杭区等。")
def get_current_weather_func(location: str):
"""当你想查询指定城市的天气时非常有用。"""
return f"{location}今天是雨天。"
get_current_weather = StructuredTool.from_function(
func=get_current_weather_func,
name="get_current_weather",
description="当你想查询指定城市的天气时非常有用。",
args_schema=InputSchema
)
get_current_weather.name, get_current_weather.description, get_current_weather.args
"""
('get_current_weather',
'get_current_weather(location: str) - 当你想查询指定城市的天气时非常有用。',
{'location': {'title': 'Location',
'description': '城市或县区,比如北京市、杭州市、余杭区等。',
'type': 'string'}})
"""LangChain function call
第一步,仍然需要定义工具。 同样使用前面的例子来我们使用上一小节的方法tool装饰器来定义工具:
python
class WeatherSchema(BaseModel):
location: str = Field(description="城市或县区,比如北京市、杭州市、余杭区等。")
@tool("get_current_weather", args_schema=WeatherSchema)
def get_current_weather(location: str):
"""当你想查询指定城市的天气时非常有用。"""
return f"{location}今天是雨天。"
# 查询当前时间的工具。返回结果示例:"当前时间:2024-04-15 17:15:18。"
@tool("get_current_time")
def get_current_time():
"""当你想知道现在的时间时非常有用。"""
# 获取当前日期和时间
current_datetime = datetime.now()
# 格式化当前日期和时间
formatted_time = current_datetime.strftime('%Y-%m-%d %H:%M:%S')
# 返回格式化后的当前时间
return f"当前时间:{formatted_time}。"第二步,将自定义的LangChain工具转化为OpenAI接口要求的格式。
- LangChain1.x许多涉及function calling及tools相关的实现要么对应OpenAI的旧实现(Legacy):新的都是使用tools参数返回tool_calls,旧的是用function参数返回function_calls,这点需要注意,许多其他的LLM都是仅支持tools的
- 要么就根本解析没有function call的返回结果
在这里,我将这些旧实现进行转换(主要转换代码在tools&chat_model),可以更好地理解整个过程。当然,你可以直接使用LangChain2.x,这是更好的解决方法。
python
from tongyi.function_calling import convert_to_openai_tool
functions = [get_current_weather, get_current_time]
tools = [convert_to_openai_tool(t) for t in functions]
tools
"""
[{'type': 'function',
'function': {'name': 'get_current_weather',
'description': 'get_current_weather(location: str) - 当你想查询指定城市的天气时非常有用。',
'parameters': {'type': 'object',
'properties': {'location': {'description': '城市或县区,比如北京市、杭州市、余杭区等。',
'type': 'string'}},
'required': ['location']}}},
{'type': 'function',
'function': {'name': 'get_current_time',
'description': 'get_current_time() - 当你想知道现在的时间时非常有用。',
'parameters': {'type': 'object', 'properties': {}}}}]
"""第三步,可以直接使用LangChain的LCEL调用。我们先来看看加入tools之后,LLM的返回变成了什么:
(如上所述,这里的LLM实现比如Tongyi也需要进行改造,来兼容其function call接口)
如下代码所示,LangChain只是将原生function call的返回进行包装,将其放在了AIMessage.tool_calls,仍然包括LLM选择的工具名称和所需参数。
python
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
from tongyi.chat_model import CustomChatTongyi
model = CustomChatTongyi(model='qwen-plus')
messages = [HumanMessage(content="杭州和北京天气怎么样?现在几点了?")]
assistant_output = model.invoke(messages, tools=tools)
assistant_output
"""
AIMessage(content='', additional_kwargs={'tool_calls': [{'function': {'name': 'get_current_weather', 'arguments': '{"location": "杭州市"}'}, 'index': 0, 'id': 'call_c72afbea224b4de6bc3957', 'type': 'function'}]}, response_metadata={'model_name': 'qwen-plus', 'finish_reason': 'tool_calls', 'request_id': '6ee616af-aa17-9600-bd04-8bcaf00e2f56', 'token_usage': {'input_tokens': 261, 'output_tokens': 18, 'total_tokens': 279}}, id='run-63bc17f2-8f36-41c2-b890-96d3a7ab7376-0', tool_calls=[{'name': 'get_current_weather', 'args': {'location': '杭州市'}, 'id': 'call_c72afbea224b4de6bc3957'}])
"""最后一步,迭代整个function call过程,直到不再需要调用工具,将LLM的最终结果进行返回。
python
functions_to_call = {'get_current_weather': get_current_weather, 'get_current_time': get_current_time}
while assistant_output.tool_calls:
messages.append(assistant_output)
for tool in assistant_output.tool_calls:
args = tool['args'] if 'properties' not in tool['args'] else tool['args']['properties']
tool_content = functions_to_call[tool['name']].invoke(args)
messages.append(ToolMessage(name=tool['name'],
tool_call_id=tool['id'],
content=tool_content)
)
print(f"工具输出信息:{tool_content}\n")
print("-"*60)
assistant_output = model.invoke(messages, tools=tools)
print(f"大模型输出信息:{assistant_output}\n")
"""
工具输出信息:杭州市今天是雨天。
------------------------------------------------------------
大模型输出信息:content='' additional_kwargs={'tool_calls': [{'function': {'name': 'get_current_weather', 'arguments': '{"location": "北京市"}'}, 'index': 0, 'id': 'call_6dfa56e25ab84322b5cc2f', 'type': 'function'}]} response_metadata={'model_name': 'qwen-plus', 'finish_reason': 'tool_calls', 'request_id': '88873f57-7d98-962f-af86-7e4b3e2c9a80', 'token_usage': {'input_tokens': 294, 'output_tokens': 20, 'total_tokens': 314}} id='run-6d079aaa-9469-4be9-9c22-7a0f97e9dd85-0' tool_calls=[{'name': 'get_current_weather', 'args': {'location': '北京市'}, 'id': 'call_6dfa56e25ab84322b5cc2f'}]
工具输出信息:北京市今天是雨天。
------------------------------------------------------------
大模型输出信息:content='' additional_kwargs={'tool_calls': [{'function': {'name': 'get_current_time', 'arguments': '{"properties": {}}'}, 'index': 0, 'id': 'call_97f6441d9b9d4503ae2dea', 'type': 'function'}]} response_metadata={'model_name': 'qwen-plus', 'finish_reason': 'tool_calls', 'request_id': '62145e44-b81a-9bf9-aa5f-26f76f598fd3', 'token_usage': {'input_tokens': 330, 'output_tokens': 19, 'total_tokens': 349}} id='run-e8cbd101-d23e-48e5-8b20-24a4e88589d2-0' tool_calls=[{'name': 'get_current_time', 'args': {'properties': {}}, 'id': 'call_97f6441d9b9d4503ae2dea'}]
工具输出信息:当前时间:2024-07-26 12:16:34。
------------------------------------------------------------
大模型输出信息:content='目前杭州市和北京市的天气都是雨天。现在的时间是2024年7月26日12点16分34秒。记得带伞出门哦!' response_metadata={'model_name': 'qwen-plus', 'finish_reason': 'stop', 'request_id': 'e7c81621-8e39-981a-8a9f-de3f2a172106', 'token_usage': {'input_tokens': 380, 'output_tokens': 42, 'total_tokens': 422}} id='run-d5d14038-4454-4ad5-9375-c4f1384e0b70-0'
"""bing tools
在上一个小节中,我们是通过将工具列表传递给invoke函数的**kwargs,最终会传递到LLM的tools参数,去调用Tongyi的原生接口,来实现function call的功能。
但这似乎不够"LangChain",其实可以将LLM和tools进行绑定(bind),这样我们也无需显式地将LangChain形式的tools转化为OpenAI形式:
python
model_with_tools = model.bind_tools(functions)
messages = [HumanMessage(content="杭州和北京天气怎么样?现在几点了?")]
assistant_output = model_with_tools.invoke(messages)
assistant_output
"""
AIMessage(content='', additional_kwargs={'tool_calls': [{'function': {'name': 'get_current_weather', 'arguments': '{"location": "杭州市"}'}, 'index': 0, 'id': 'call_72d4e08d6ddc4fe5974f72', 'type': 'function'}]}, response_metadata={'model_name': 'qwen-plus', 'finish_reason': 'tool_calls', 'request_id': '86640a08-c7fd-9c0a-a350-0deb481bf5d1', 'token_usage': {'input_tokens': 261, 'output_tokens': 18, 'total_tokens': 279}}, id='run-c663249c-2967-41e6-a695-88269dcc4446-0', tool_calls=[{'name': 'get_current_weather', 'args': {'location': '杭州市'}, 'id': 'call_72d4e08d6ddc4fe5974f72'}])
"""Agents
LangChain官网文档:https://python.langchain.com/v0.1/docs/modules/agents/
实例代码:tools_agents.ipynb
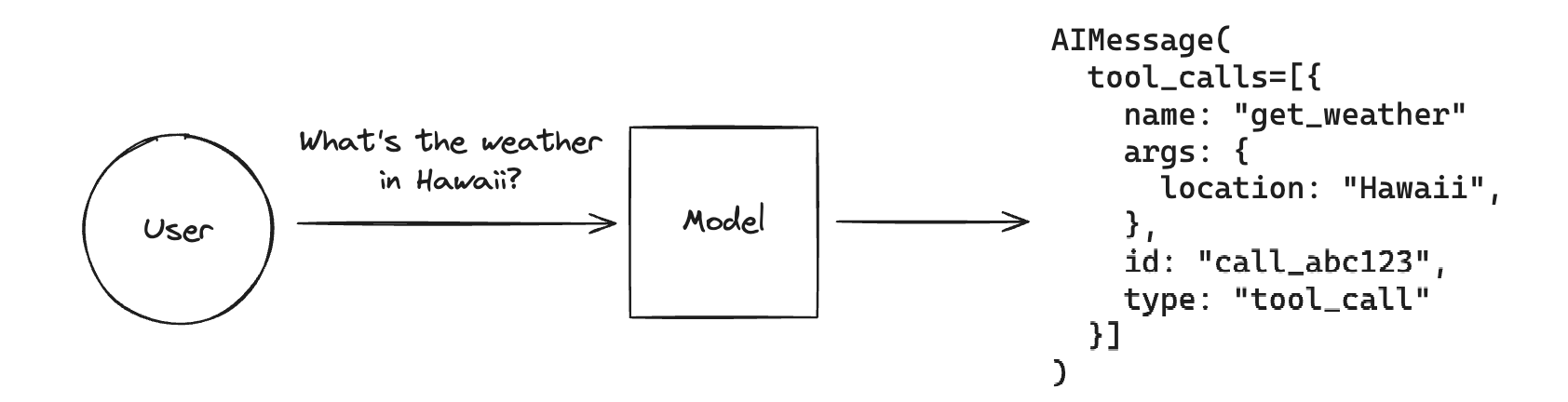
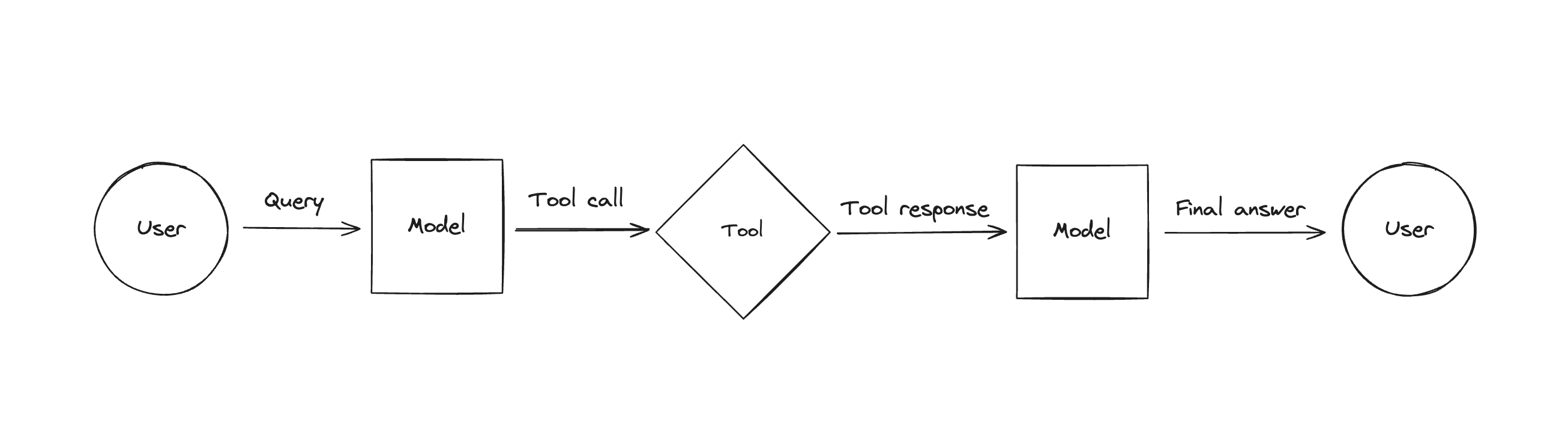
其实上一个章节对于tools的介绍,基本上是已经涵盖了agents的整个过程了,包括:
- 对LLM对tools的选择(如下图-function call)
- tools执行,然后把执行结果拼接到Prompt中,继续调用LLM的迭代过程(如下图-agents)。
但是,这个过程LangChain也进行了封装了,我们下面来看看。
第一步,设计提示词模板。
这里加入了chat_history来存放对轮对话历史。还有,可以根据需要加入SystemMessage来保持LLM的人设,指导LLM更精准的回复。
python
from langchain.prompts import (
ChatPromptTemplate,
PromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
)
prompt = ChatPromptTemplate.from_messages(
[MessagesPlaceholder(variable_name='chat_history', optional=True),
HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input'], template='{input}')),
MessagesPlaceholder(variable_name='agent_scratchpad')]
)**第二步,跟前面一样,自定义工具列表。**这里便不再重复。
python
tools = [get_current_weather, get_current_time]**第三步,创建自己的Agent。**主要是通过create_tool_calling_agent将工具与LLM进行绑定,并构建LLM调用和tools call的解析执行的chain。
python
from langchain.agents import create_tool_calling_agent
from langchain.agents import AgentExecutor
from tongyi.chat_model import CustomChatTongyi
model = CustomChatTongyi(model='qwen-plus')
agent = create_tool_calling_agent(model, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)最后,便可以直接使用LangChain的LCEL调用。
AgentExecutor的invoke仅支持stream模式,因此需要LLM支持流式模式的function call,不然便需要在_stream方法中进行改造,比如通义千问就不支持流式的function call,改造详见本仓库代码。
python
agent_executor.invoke({'input': '杭州和北京天气怎么样?现在几点了?'})
"""
> Entering new AgentExecutor chain...
Invoking: `get_current_weather` with `{'location': '杭州市'}`
杭州市今天是雨天。
Invoking: `get_current_weather` with `{'location': '北京市'}`
北京市今天是雨天。
Invoking: `get_current_time` with `{}`
当前时间:2024-07-30 15:35:17。目前杭州市和北京市的天气都是雨天。现在的时间是2024年7月30日15点35分17秒。记得带伞出门哦!
> Finished chain.
{'input': '杭州和北京天气怎么样?现在几点了?',
'output': '目前杭州市和北京市的天气都是雨天。现在的时间是2024年7月30日15点35分17秒。记得带伞出门哦!'}
"""结构化Agent
前面提到,Agents的整个迭代过程如下:
其中关键的一步便是LLM来决定是否调用工具 ,一般来说,包括前面出现的全部使用方法,都是基于使用的LLM支持function call ,即将工具列表信息传递给LLM的tools参数。
但是,LangChain还另外支持了结构化的Agents实现方式,则不依赖于LLM的function call,可以通过对Prompt的设计来达到同样的效果,这能够让不支持function call的LLM实现Agents的效果。
不过目前主流大模型都支持function call,因此下面便简单介绍一下即可。
XML Agent
我们以XML Agent为例来介绍结构化Agent(其他还包括:JSON Chat Agent、Structured chat、Self-ask with search)
这些结构化Agent与上面使用的Agent的区别在于下图红框部分:如何从LLM回复中提取tool call信息,再将tool执行结果进行整理,拼接到原来的Prompt中,继续传到LLM。
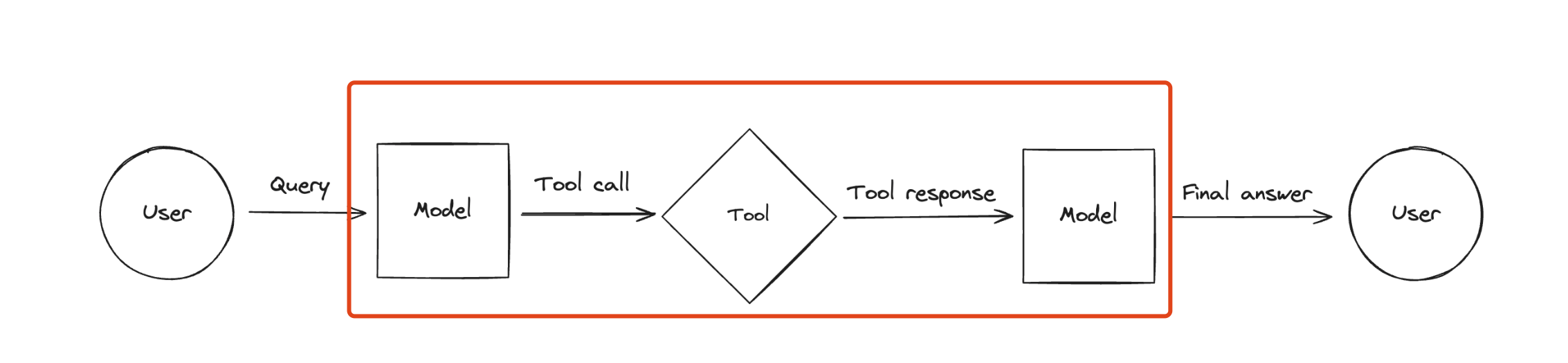
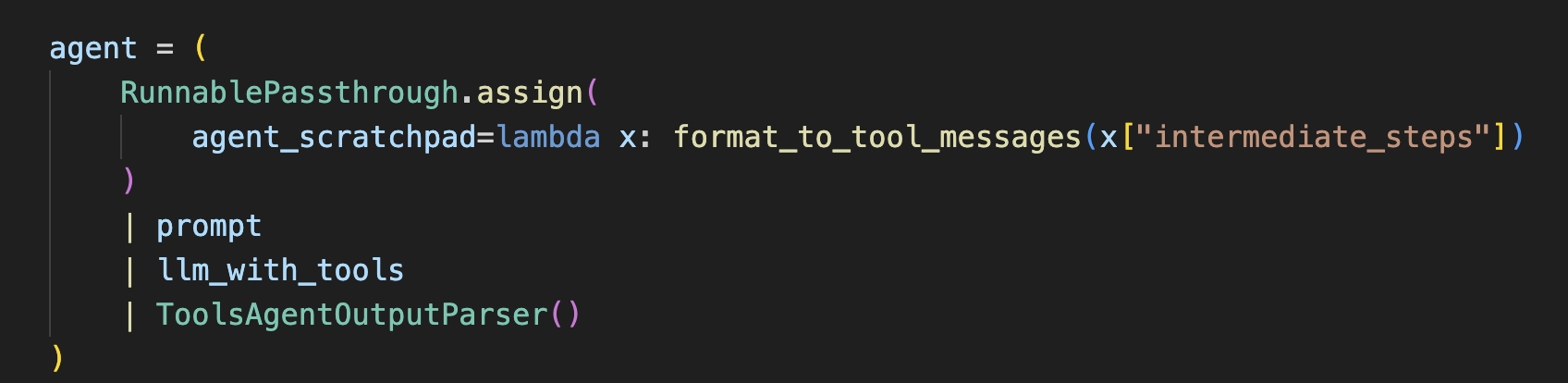
在LangChain代码中,Agent仍然被设计成Chain的形式(开头已经提及Agent和Chain的区别),包括四部分,如下图所示:
- prompt:提示词模板
- llm_with_tools:与tools绑定后的LLM
- ToolsAgentOutputParser:对LLM的回复内容进行解析
- RunnablePassthrough:将ToolsAgentOutputParser解析之后的内容进行整理拼接到Prompt中
而整个迭代过程是在AgentExecutor._call中。
因此,XML Agent需要调整的部分是在创建Chain形式的Agent,即create_xml_agent,而不是AgentExecutor,如下图所示:
python
# Construct the XML agent
agent = create_xml_agent(llm, tools, prompt)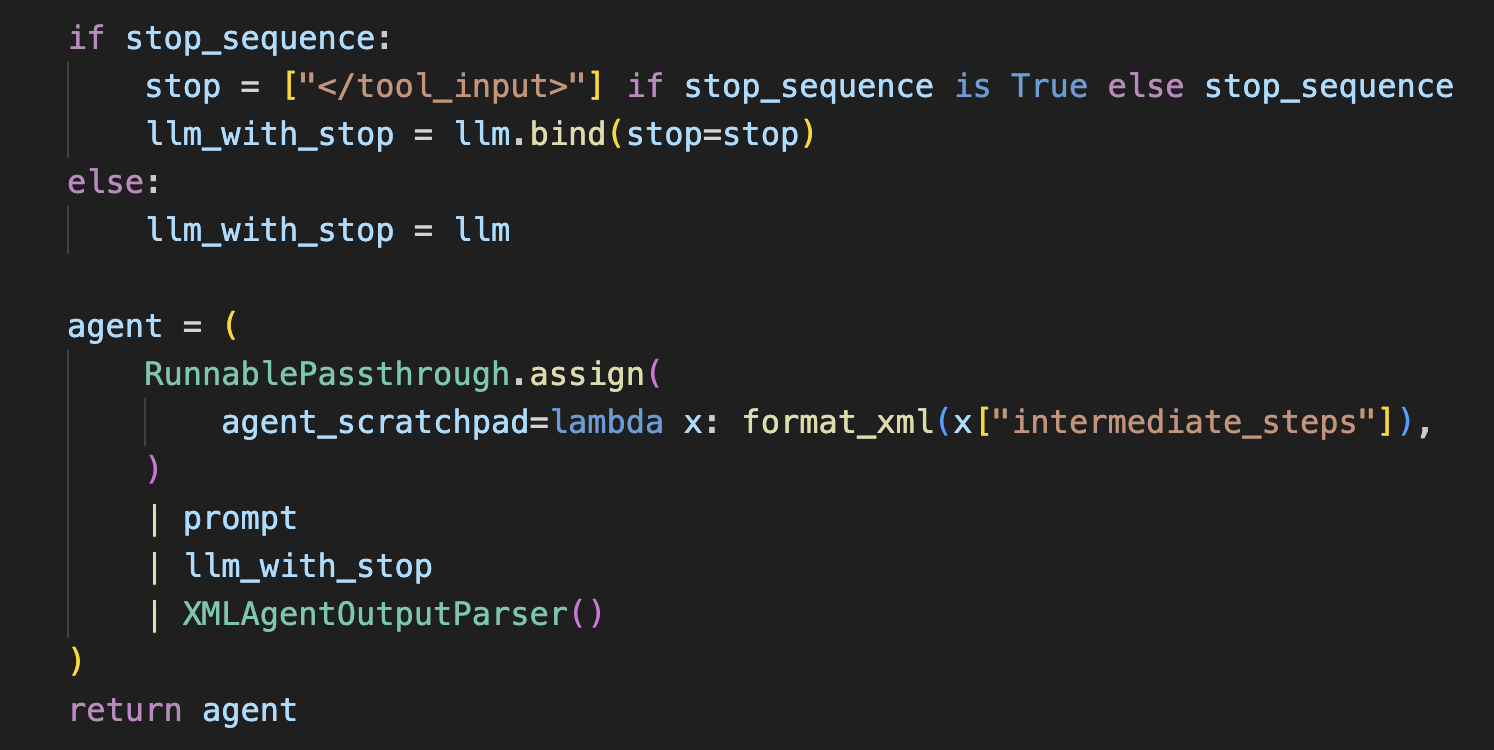
第一部分,Prompt的设计,下面是LangChain官方提供的一个提示词:
xml
You are a helpful assistant. Help the user answer any questions.
You have access to the following tools:
{tools}
In order to use a tool, you can use <tool></tool> and <tool_input></tool_input> tags. You will then get back a response in the form <observation></observation>
For example, if you have a tool called 'search' that could run a google search, in order to search for the weather in SF you would respond:
<tool>search</tool><tool_input>weather in SF</tool_input>
<observation>64 degrees</observation>
When you are done, respond with a final answer between <final_answer></final_answer>. For example:
<final_answer>The weather in SF is 64 degrees</final_answer>
Begin!
Previous Conversation:
{chat_history}
Question: {input}
{agent_scratchpad}第二部分,LLM绑定的则不再是tools,而是上图-create_xml_agent中的bing方式 ,会以</tool_input>作为结果进行截断,因为根据Prompt可以看出LLM会以</tool_input>标签来存储工具的参数;
第三部分,则是LLM的回复内容解析 XMLAgentOutputParser。 其实主要就是对选择工具</tool>、工具参数</tool_input>,还是最终回复</final_answer>这几个标签的提取;
第四部分,便是LLM选择的工具的函数调用 ,这个中间结果(包括工具执行结果)会存放在intermediate_steps中;
最后,则是RunnablePassthrough中使用format_xml函数来对工具调用的中间结果即intermediate_steps进行解析和提取,拼接到Prompt中 (写入到agent_scratchpad占位变量),接着去继续请求LLM,进行Agent的迭代。
python
model = CustomChatTongyi(model='qwen-plus')
agent = create_xml_agent(model, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, return_intermediate_steps=True)
agent_executor.invoke({'input': '杭州和北京天气怎么样?现在几点了?'})
"""
{'input': '杭州和北京天气怎么样?现在几点了?',
'output': '杭州和北京今天的天气都是雨天。现在的时间是2024年7月31日16点59分52秒。',
'intermediate_steps': [(AgentAction(tool='get_current_weather', tool_input='杭州', log='<tool>get_current_weather</tool><tool_input>杭州'),
'杭州今天是雨天。'),
(AgentAction(tool='get_current_weather', tool_input='北京', log='<tool>get_current_weather</tool><tool_input>北京'),
'北京今天是雨天。'),
(AgentAction(tool='get_current_time', tool_input='', log='<tool>get_current_time</tool><tool_input>'),
'当前时间:2024-07-31 16:59:52。')]}
"""PS:LangChain对无参数的函数工具支持并不好,会抛出异常,并且在LangChain2.x仍未修复,我已经提了PR,看官方要不要merge了。或者你可以直接使用本仓库的代码,对tools的基类StructuredTool进行改正。
Agent迭代器
上面的例子,Agent的调用都是直接输出最终结果(虽然包含了中间调用的日志)。但其实是可以使用Agent迭代器来循环整个过程的,这样的话,可控性更高,可以对一些中间步骤进行校验或者校正,减少出现重复调用或者调用链路错误等异常情况。
如下代码,上面也提到了LLM选择tools和其执行结果都是存放在intermediate_step中,我们可以根据实际情况对其进行校验。而最终结果则存放在output。
python
for i, step in enumerate(agent_executor.iter({'input': '杭州和北京天气怎么样?现在几点了?'})):
print(f'Agent的第 {i+1} 步输出:')
if output := step.get("intermediate_step"):
action, value = output[0]
print(f'\taction: {action}')
print(f'\tvalue: {value}')
else:
print(step['output'])
"""
Agent的第 1 步输出:
action: tool='get_current_weather' tool_input={'location': '杭州市'} log="\nInvoking: `get_current_weather` with `{'location': '杭州市'}`\n\n\n"......'
value: 杭州市今天是雨天。
Agent的第 2 步输出:
action: tool='get_current_weather' tool_input={'location': '北京市'} log="\nInvoking: `get_current_weather` with `{'location': '北京市'}`\n\n\n"......'
value: 北京市今天是雨天。
Agent的第 3 步输出:
action: tool='get_current_time' tool_input={'properties': {}} log="\nInvoking: `get_current_time` with `{'properties': {}}`\n\n\n"......'
value: 当前时间:2024-08-01 08:04:33。
Agent的第 4 步输出:
目前杭州市和北京市的天气都是雨天。现在的时间是2024年8月1日8点04分33秒。请记得带伞出门哦!
"""结构化输出
截止到这里,Agent的最终输出都是一个字符串,那么我们是否也可以像前面的文章提到的Output Parsers那样,对Agent的输出也进行结构化转化,比如存储在一个数据对象中?
答案,当然是肯定的,这无疑对下流任务的开发对接提供了极大的便捷。
下面,我们继续以询问天气和时间为例子,前面没有进行特殊处理,Agent最终返回了目前杭州市和北京市的天气都是雨天。现在的时间是2024年8月1日8点04分33秒。请记得带伞出门哦!,接下来,我们便让它以json的格式返回。
(这里可能有人会有疑问,为什么不直接在Prompt加入让LLM返回json格式的提示词呢?其实如果每次都是询问天气和时间,那么是可以这么做的,当我们是使用Agent,即并不是每一次都是询问天气和时间,可能是其他的问题或者聊天)
第一步,仍然是定义天气和时间的tools,如上面的例子无异,不再重复。
第二步,定义触发结构化返回天气和时间的工具 。这一步是核心思想,可以看出,我们仍然是以工具的形式来实现这个做法:
- 即如果LLM调用了
Response这个工具,那么意味着用户的输入是关于天气和时间的,我们便退出Agent的迭代过程,并且天气和时间的字段提取是完全交给LLM,而不需要我们自己去处理。 - 而如果是调用其他工具或者无需调用工具,便交由正常的逻辑
parse_ai_message_to_tool_action去处理,这个是我们最普通的Agent创建,即create_tool_calling_agent中ToolsAgentOutputParser的处理方法。
python
from typing import List, Dict
from langchain_core.agents import AgentActionMessageLog, AgentFinish, AgentAction
from langchain.agents.output_parsers.tools import parse_ai_message_to_tool_action
from langchain_core.pydantic_v1 import BaseModel, Field
class Response(BaseModel):
"""最终的回答如果包含天气、时间等信息,则需要调用该工具"""
weather: Dict[str, str] = Field(
description='最终的回答中不同城市对应的天气,比如北京的天气为阴天,则返回`{"北京": "阴天"}`。如果不存在天气信息则忽略', default={})
current_time: str = Field(
description="最终的回答中的当前时间,如果不存在则忽略", default="")
def parse(output):
name = None
# 判断调用的工具是否为 Response
if output.tool_calls:
tool_calls = output.tool_calls[0]
name = tool_calls["name"]
inputs = tool_calls["args"]
elif output.additional_kwargs.get("tool_calls"):
tool_calls = output.additional_kwargs["tool_calls"][0]
name = tool_calls["name"]
inputs = tool_calls["args"]
if name == "Response":
return AgentFinish(return_values=inputs, log=str(tool_calls))
return parse_ai_message_to_tool_action(output)第三步,定义Agent的Chain,前面也提到了,在LangChain代码中,Agent是以Chain的形式来实现的。这在上面结构化Agent小节中也重点介绍了这个Chain。
重要的一步,是要把Response工具也绑定到LLM,即model.bind_tools(tools + [Response])。
python
# prompt & tools的定义在上面[Agents-Quickstart]小节
from langchain.agents.format_scratchpad import format_to_tool_messages
from langchain.agents import AgentExecutor
from tongyi.chat_model import CustomChatTongyi
model = CustomChatTongyi(model='qwen-plus')
llm_with_tools = model.bind_tools(tools + [Response])
agent = (
{
"input": lambda x: x["input"],
# Format agent scratchpad from intermediate steps
"agent_scratchpad": lambda x: format_to_tool_messages(
x["intermediate_steps"]
),
}
| prompt
| llm_with_tools
| parse
)最后,便是AgentExecutor即Agent迭代过程的创建和调用了 。这里可以看到,因为我们自定义了Response工具的特殊逻辑,因此我们不需要再把Response工具加入Agent的迭代过程。
结果也符合预期,以json的形式返回时间和天气。
python
agent_executor = AgentExecutor(tools=tools, agent=agent, verbose=True)
agent_executor.invoke(
{"input": "杭州和北京天气怎么样?现在几点了?"},
return_only_outputs=True,
)
"""
{'current_time': '2024-08-01 22:19:30', 'weather': {'杭州市': '雨天', '北京市': '雨天'}}
"""总结
- 这篇文章我们介绍了Agent这个热门的概念,以及它是如何依托LLM的function call来实现的
- 接着,再展示了借助LangChain的封装来简化这个开发过程,
- 并且还介绍了另外一种不依赖function call的Agent实现。