文章目录
-
-
- [A 论文出处](#A 论文出处)
- [B 背景](#B 背景)
-
- [B.1 背景介绍](#B.1 背景介绍)
- [B.2 问题提出](#B.2 问题提出)
- [B.3 创新点](#B.3 创新点)
- [C 模型结构](#C 模型结构)
- [D 实验设计](#D 实验设计)
- [E 个人总结](#E 个人总结)
-
A 论文出处
- 论文题目:FreeAL: Towards Human-Free Active Learning in the Era of Large Language Models
- 发表情况:2023-EMNLP
- 作者单位:浙江大学、网易
B 背景
B.1 背景介绍
传统的主动学习,降低了第一步的标注成本,通过迭代标注小部分数据,然后通过模型的Uncertainty(或Feature-based Diversity)进行校验,筛选剩余有价值的样本进行再标注。但仍存在两个问题,首先是少量标注其实很难训练很好的模型,影响后续筛选的步骤,其次传统AL还是需要大量的人力成本,目前的AL论文大部分都需要标注10%~50%以上的数据才能达到较好的性能。
B.2 问题提出
(1)大模型:可以用Zero/few-shot ICL解决下游任务,人力标注几乎为0,但光靠大模型部署成本较高,效果不总是尽如人意;
(2)小模型:直接用小模型需要收集很多标注数据,人力成本更高。但可以使用半监督、主动学习缓解一下标注成本,但总是需要一定的人力成本。
B.3 创新点
(1)在没有任何人为监督的情况下,提高大模型的泛化能力;
(2)大模型+小模型的协同学习方法FreeAL,大模型用来主动标注,小模型用来过滤和反馈。
C 模型结构
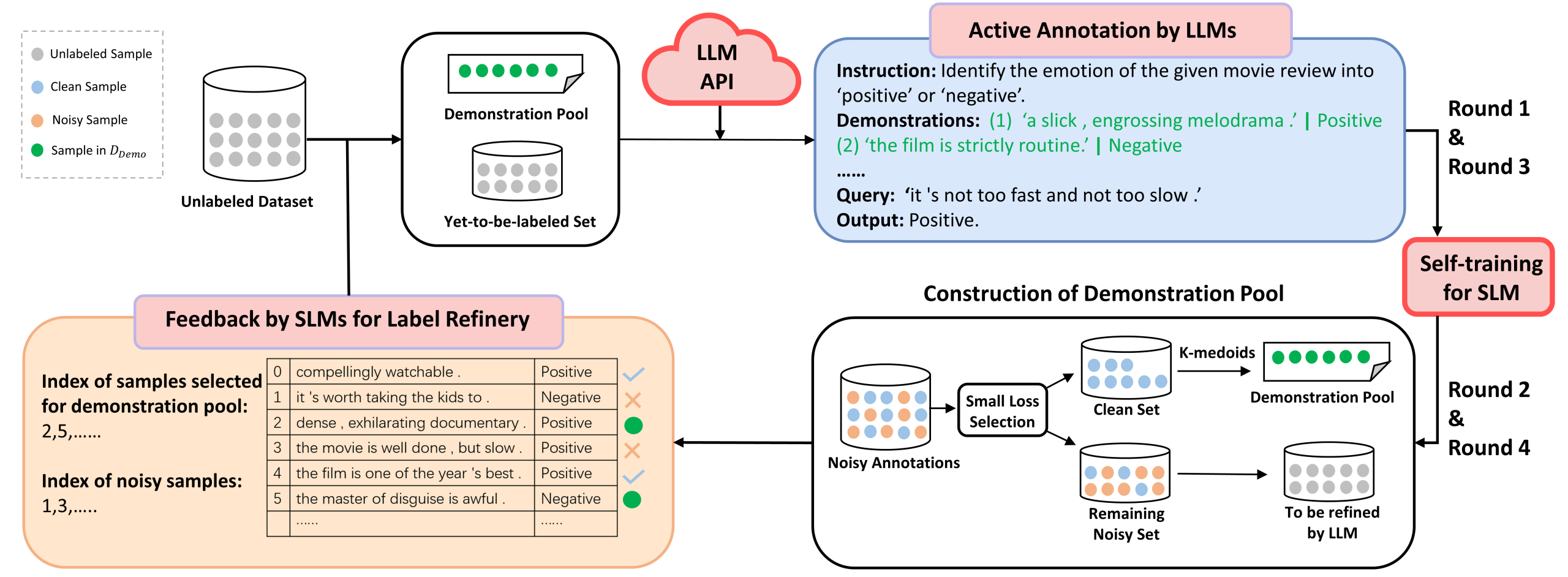
(1)LLM通过自生成的虚拟样本对未标注的数据进行打标,形成初始的标注数据集;
(2)SLM对于LLM的标注结果进行筛选过滤,得到clean set用于LLM进行ICL;
- 训练预热(Warm-up Training)
SLM使用LLM生成的初始伪标签进行少量周期的标准训练(如交叉熵损失),目的是让模型初步学习数据中的简单模式,避免过早陷入噪声样本的过拟合。 - 损失计算与排序(Loss Calculation and Ranking)
对每个训练样本计算交叉熵损失值 l i l_i li,并按类别对损失值进行升序排序。损失值较低的样本表明SLM对其预测置信度较高,可能对应LLM生成的更准确的伪标签。 - 类别内筛选(Class-wise Selection)
对每个类别 j j j 的样本集合 D t r a i n j \mathcal{D}{train}^j Dtrainj,选择损失值最小的前 R % R\% R%(如论文中设 R = 20 R=20 R=20 )的样本,构成初步的干净子集 D c l e a n j \mathcal{D}{clean}^j Dcleanj,确保每个类别都有一定比例的"高置信度"样本被保留。 - 聚类去冗余(Clustering for Diversity)
使用k-medoids算法 对 D c l e a n j \mathcal{D}{clean}^j Dcleanj 中样本的嵌入表示(如SLM的隐藏层输出)进行聚类,选择每个簇的中心样本(medoids)作为最终演示池 D d e m o j \mathcal{D}{{demo}}^j Ddemoj 。这保证了演示样本的多样性和代表性,避免冗余。 - 合并与反馈(Aggregation and Feedback)
将所有类别的演示池合并为 D d e m o = ∪ D d e m o j \mathcal{D}{{demo}}=\cup\mathcal{D}{{demo}}^j Ddemo=∪Ddemoj ,并反馈给LLM用于后续的标签优化。未被选中的样本则交由 D n o i s y \mathcal{D}_{{noisy}} Dnoisy LLM通过上下文学习重新标注。
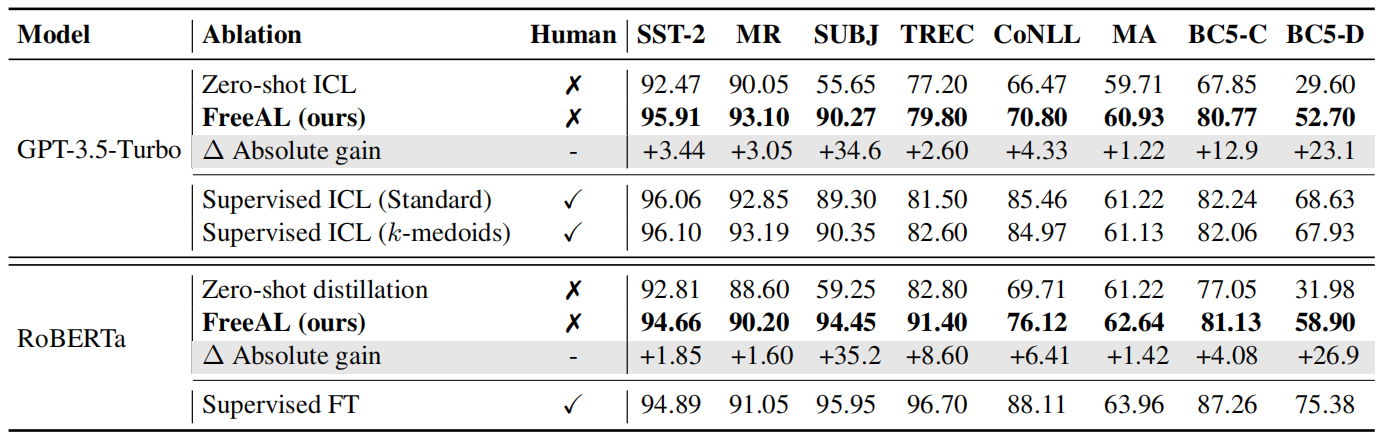
D 实验设计
(1)多次迭代性能提升

(2)相较于ICL的性能提升
E 个人总结
(1)数据标注依然重要,完全监督、弱监督的小模型在很多场景下比(未精调)大模型强;
(2)利用LLM进行标注是完全可行的,小模型可以协同进行过滤、精炼大模型的标签;
(3) 该方法的核心在于用LLM完全替代人类进行样本选择,但LLM固有的不确定性、偏见和"幻觉"问题可能导致其选择的样本质量不稳定,甚至引入错误或次优的标注,反而损害最终模型性能;
(4)论文中展示的有效性可能高度依赖于特定的数据集、任务或使用的LLM,其提出的"完全无人"流程在更复杂、动态或领域外(OOD)的真实世界场景中的鲁棒性和泛化能力尚未得到充分验证。