DataLoader 的使用
- dataset:告诉程序中数据集的位置,数据集中索引,数据集中有多少数据(想象成一叠扑克牌)
- dataloader:加载器,将数据加载到神经网络中,每次从dataset中取数据,通过dataloader中的参数可以设置如何取数据(想象成抓的一组牌)
参数介绍
参数如下(大部分有默认值,实际中只需要设置少量的参数即可):
- dataset:只有dataset没有默认值,只需要将之前自定义的dataset实例化,再放到dataloader中即可
- batch_size:每次抓牌抓几张
- shuffle:打乱与否,值为True的话两次打牌时牌的顺序是不一样。默认为False,但一般用True
- num_workers:加载数据时采用单个进程还是多个进程,多进程的话速度相对较快,默认为0(主进程加载)。Windows系统下该值>0会有问题(报错提示:BrokenPipeError)
- drop_last:100张牌每次取3张,最后会余下1张,这时剩下的这张牌是舍去还是不舍去。值为True代表舍去这张牌、不取出,False代表要取出该张牌
示例
import torchvision
from torch.utils.data import DataLoader
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
#加载测试数据集,batch_size=4即每次取4个数据集打包
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)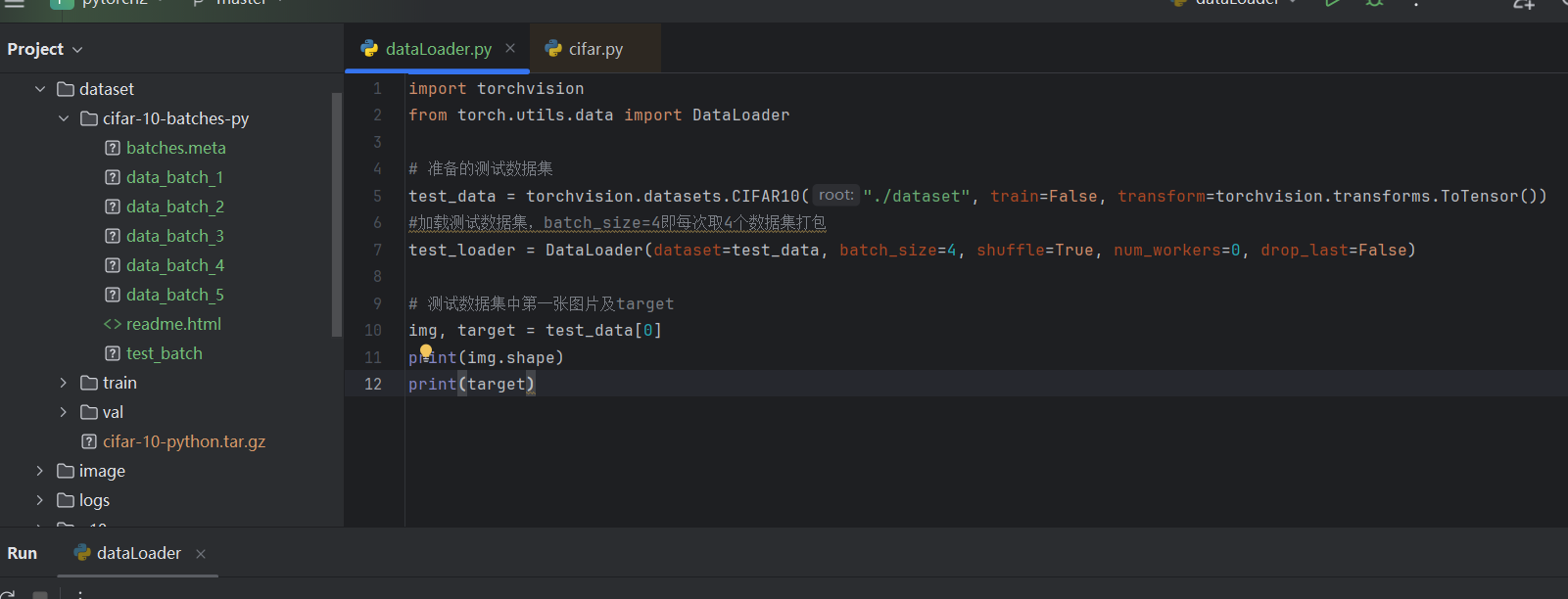
输出结果:
torch.Size([3, 32, 32]) #三通道,32×32大小
3 #类别为3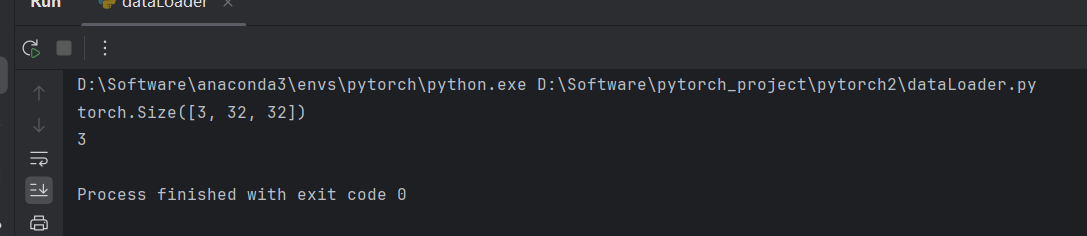
测试数据集CIFAR10中getitem返回的数据类型为img,target
dataset
__getitem()__:return img,targetdataloader(batch_size=4):从dataset中取4个数据
img0,target0 = dataset[0]
img1,target1 = dataset[1]
img2,target2 = dataset[2]
img3,target3 = dataset[3]把 img 0-3 进行打包,记为imgs;target 0-3 进行打包,记为targets;作为dataloader中的返回
for data in test_loader:
imgs,targets = data
print(imgs.shape)
print(targets)
输出:
torch.Size([4, 3, 32, 32]) #4张图片,三通道,32×32
tensor([1, 1, 7, 3]) #4个target进行一个打包
数据是随机取的(断点debug一下,可以看到采样器sampler是随机采样的),所以两次的 target 0 并不一样
batch_size
# 用上节课torchvision提供的自定义的数据集
# CIFAR10原本是PIL Image,需要转换成tensor
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# 加载测试集
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
#batch_size=4,意味着每次从test_data中取4个数据进行打包
writer = SummaryWriter("dataloader")
step=0
for data in test_loader:
imgs,targets = data #imgs是tensor数据类型
writer.add_images("test_data",imgs,step)
step=step+1
writer.close()
运行后在 terminal 里输入:
tensorboard --logdir="dataloader"运行结果如图,滑动滑块即是每一次取数据时的batch_size张图片:
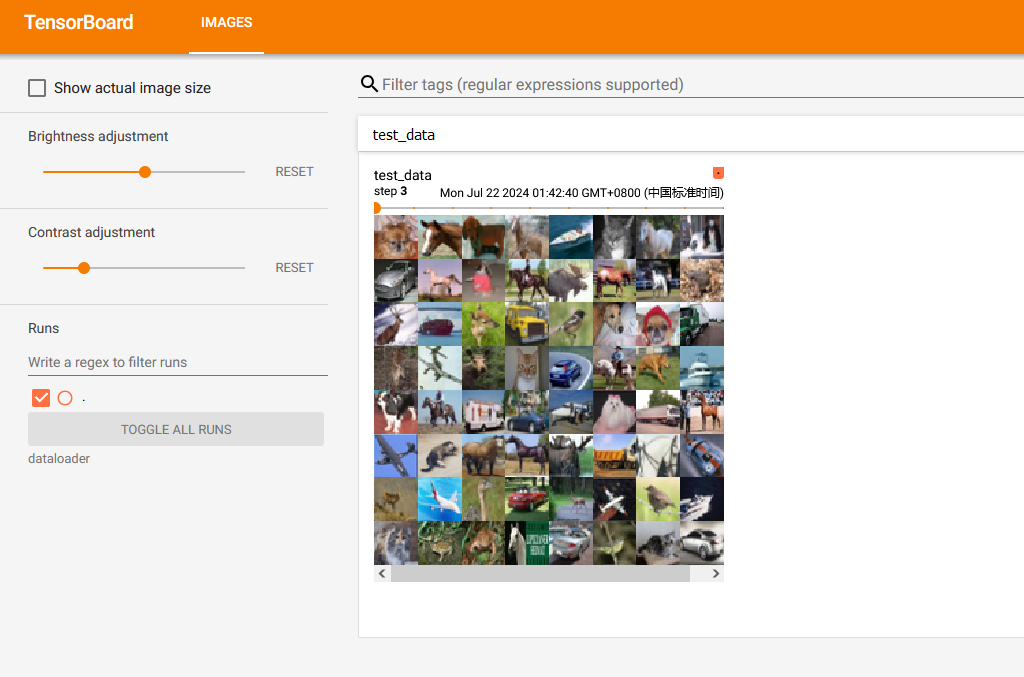
由于 drop_last 设置为 False,所以最后16张图片(没有凑齐64张)显示如下:
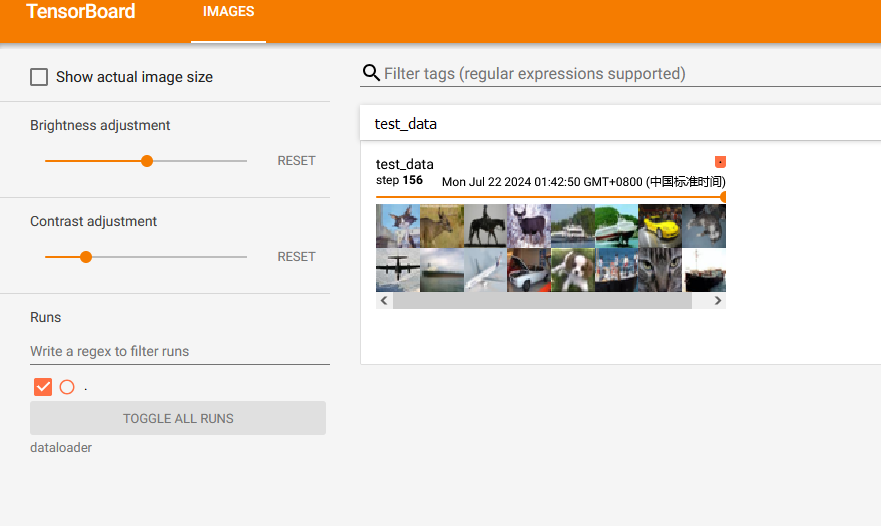
drop_last
若将 drop_last 设置为 True,最后16张图片(step 156)会被舍去,结果如图:
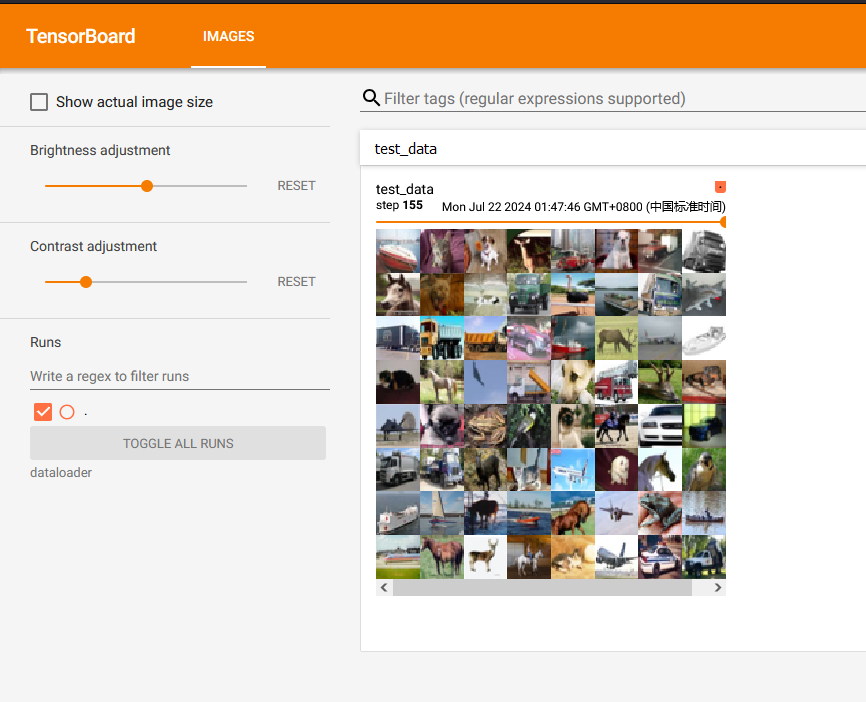
shuffle
shuffle的作用:一个 for data in test_loader 循环,就意味着打完一轮牌(抓完一轮数据),在下一轮再进行抓取时,第二次数据是否与第一次数据一样。值为True的话,会重新洗牌(一般都设置为True)shuffle为False的话两轮取的图片是一样的
在外面再套一层 for epoch in range(2) 的循环来验证一下
# shuffle为True
for epoch in range(2):
step=0
for data in test_loader:
imgs,targets = data #imgs是tensor数据类型
writer.add_images("Epoch:{}".format(epoch),imgs,step)
step=step+1
shuffle为False结果如下:
可以看出两次 step 155 的图片一样
shuffle为True结果如下:
可以看出即使是同样的 step 155,两轮抓取的图片不一样
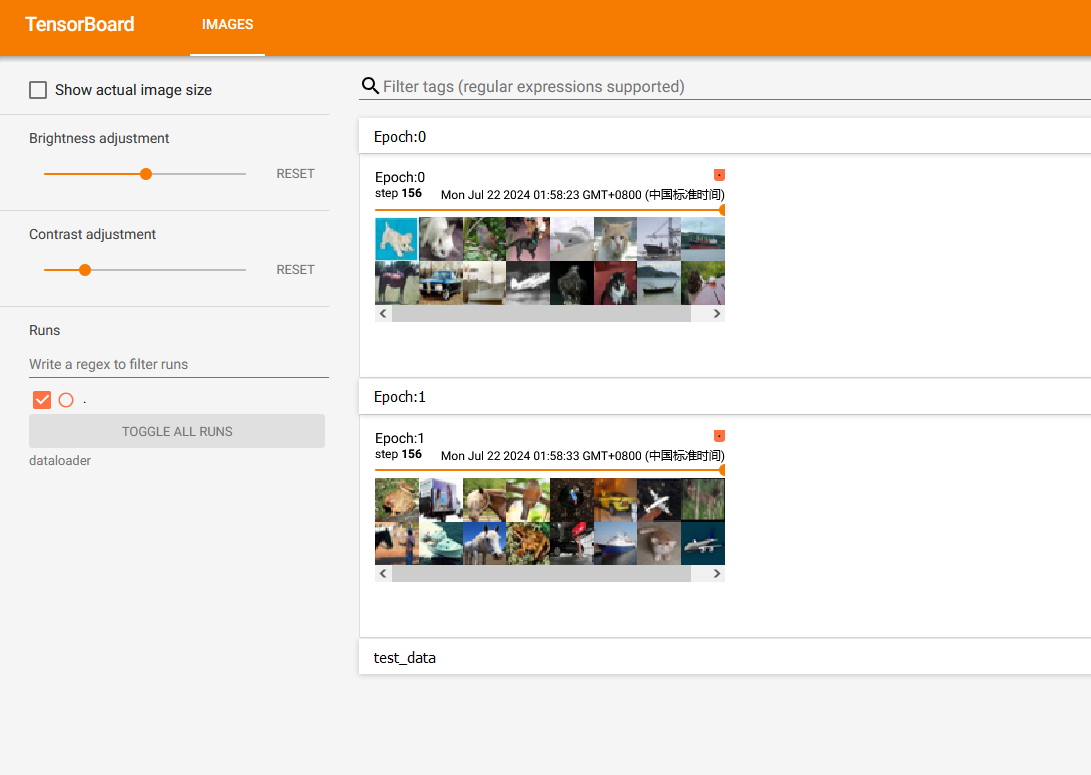
出两次 step 155 的图片一样
外链图片转存中...(img-F8G96Zxa-1724861448845)
shuffle为True结果如下:
可以看出即使是同样的 step 155,两轮抓取的图片不一样
外链图片转存中...(img-Aru5xvXY-1724861448846)