概述
源码地址:https://github.com/neuhai/Mental-LLM.git
论文地址:https://arxiv.org/abs/2307.14385
在一项关于哪些法律硕士适合精神健康护理的研究中,对以下五种法律硕士进行了比较
- 羊驼-7b。
- 羊驼-LoRA。
- FLAN-T5-XXL
- GPT-3.5
- GPT-4.
作为本研究的背景,心理健康护理领域是近年来备受商业和组织管理研究关注的一个领域。然而,关于 LLM 在心理健康护理领域的表现及其准确性如何,还没有进行过全面的研究,因此本文将对 LLM 在综合心理健康护理领域的潜力进行调查。
与以往研究的区别
本文介绍了几项相关研究,并不是说根本没有与心理保健有关的法律硕士调查和研究。不过,论文指出,大多数研究都不如本研究全面,而且大多数研究都是使用简单的提示工程进行的零点研究。
本研究与现有研究的不同之处还在于,本研究全面研究和评估了各种技术,以提高 LLM 在心理健康领域的能力,如模型性能随提示的变化、微调时应注意的数据量或项目,以及用户对文本推理的评估。本研究的目的是
研究结果
这项研究的结果可大致归纳如下
(i) 在心理健康护理领域,我们证明 GPT-3 和 GPT-4 在其知识空间中存储了足够的知识。
(ii) 微调结果表明,LLMs 的能力可以在不同数据集上同时针对多个心理健康特定任务得到显著提高。
(iii) 我们为心理健康预测任务提供了开放的微调 LLM。
(iv) 提供了一个框架,包括数量和质量,以便为 LLMs 创建数据集,用于未来心理保健领域的研究。
关于(i)和(ii)
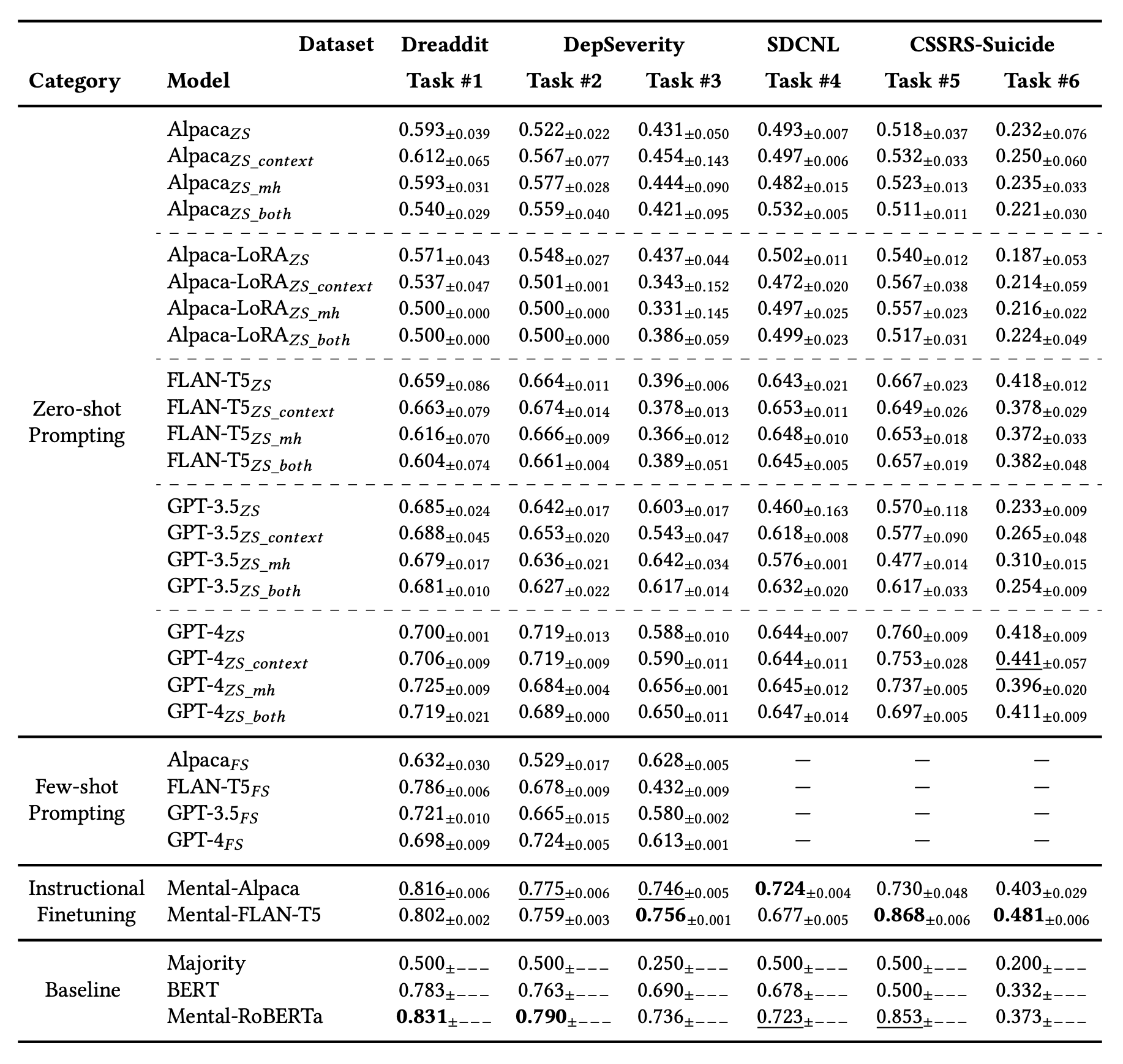
下表显示了每个模型的结果,从最上面一行开始依次为:零镜头学习、零镜头学习 + 添加比问题更多的上下文、零镜头学习 + 赋予 LLM 角色、零镜头学习 + 添加比问题更多的上下文 + 赋予 LLM 角色。
下面是 "Few-Shot Learning",其中介绍并回答了一些问题。
从这些结果来看,TASK#1 中表现最好的竟然是现有的 BERT 模型 Mental-RoBERTa。微调模型在其他任务中的表现也优于现有的 GPT,而在 GPT 内部的比较显示,"零镜头 "和 "少镜头 "之间没有显著差异,这表明 GPT 系列所掌握的知识空间包含了足够的心理健康知识。这表明,在 GPT 系列所掌握的知识空间中,有足够的心理健康知识。
Alpaca 和 FLAN-T5 在微调前后的其他比较结果表明,微调前,Alpaca 和 FLAN-T5 的性能压倒性地优于 FLAN-T5。然而,微调后的结果显示,Alpaca 的性能已赶上 FLAN-T5。这一结果表明,与基于 LLM 的网络相比,FLAN-T5 等早期网络对自然语言的理解能力较差。因此,本研究认为,在微调过程中,Alpaca 可能从微调数据中吸收了更多信息,并接近了 FLAN-T5 的结果。
(iv) 关于
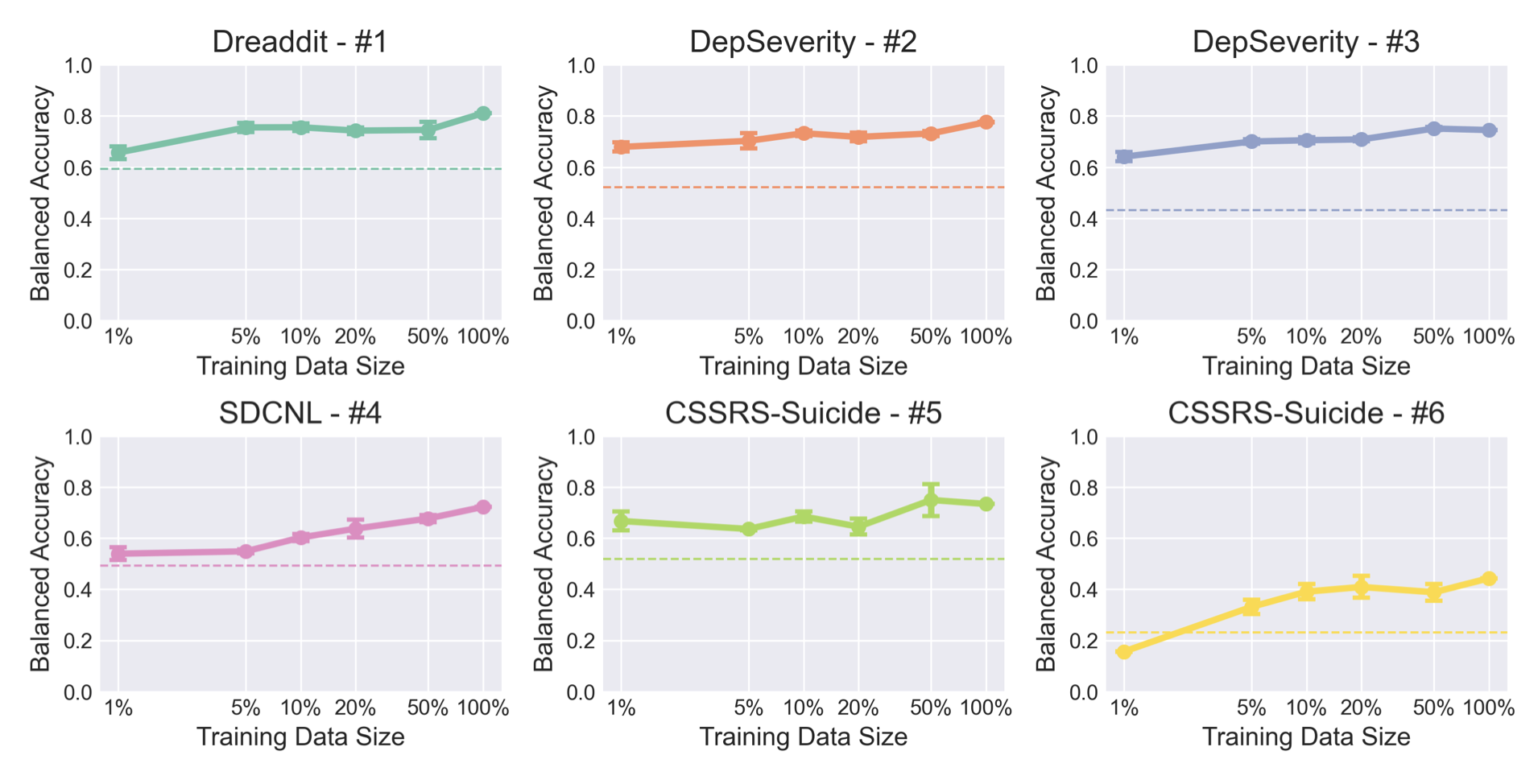
下图(论文中的图 1)显示了第(iii)点所述的已发布的 Mental-Alpaca 模型在改变训练集时的准确度变化。结果表明,经过微调后,准确率与基础模型相比基本有所提高。此外,可以看出数据集的大小与系统并不一定有直接关系。这表明,在 LLM 中微调数据集时,质量和多样性比数量问题更重要。
实验细节
至于提示语,我们尝试了三种模式--无语境、在语境中包含相似信息和让模型扮演专家角色--以及后两种模式的组合,以解决从句子中预测心理状态标签的任务,并比较绩效。
结果表明,如前所述,无论提示中是否存在信息,GPT 系列的表现都很好,而且我们判断有关精神护理的知识已作为基本信息嵌入知识空间。
下图分别为 "零镜头 "和 "少镜头 "的提示设计。
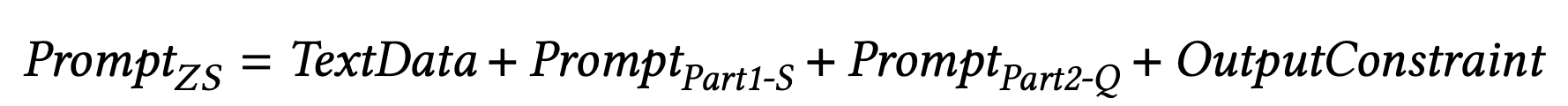
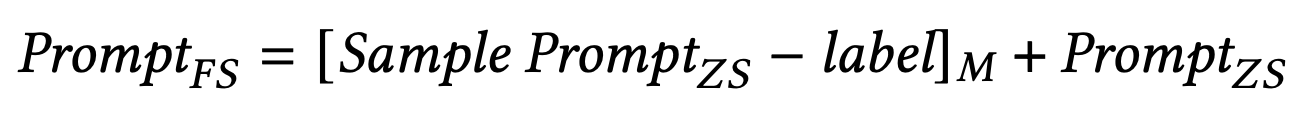
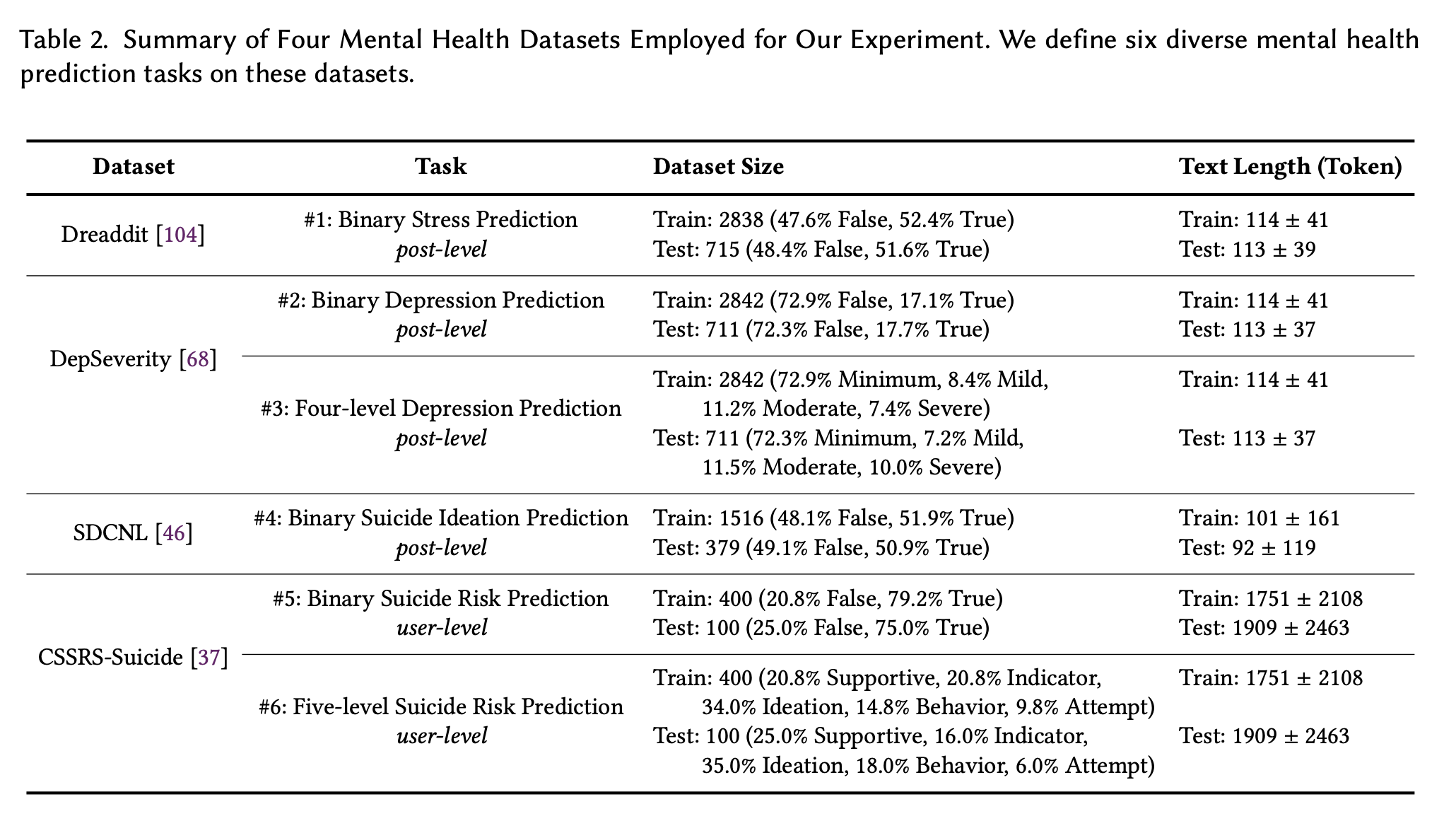
接下来,实验中使用的数据集是 Dreaddit、DepSeverity、SDCNL 和 CSSRS-Suicide。下面将简要介绍每个数据集。
**Dreaddit
**Dreaddit 数据集是 Reddit(美国一个流行的社交网站)上的帖子集合,包含五个领域(虐待、社交、焦虑、创伤后应激障碍和金融)的 10 个子数据集。多名人类注释者对海报中的某段文字是否表示压力进行了评估,并将注释汇总生成最终标签。该数据集用于后级二元压力预测(任务 1)。
**DepSeverity
**DepSeverity 数据集采用了与 Dreaddit 上收集的相同的提交内容,但不同之处在于它侧重于抑郁症:两名人类注释员根据 DSM-5 将提交内容分为四个抑郁症等级:极轻度、轻度、中度和重度。数据集以任务集的形式提供。该数据集用于两个贡献级任务。(i) 二元抑郁预测(即一篇帖子是否表明至少有轻度抑郁,任务 2)和 (ii) 四级抑郁预测(任务 3)。
**SDCNL
**SDCNL 数据集也是 Reddit 上帖子的集合,包括 r/SuicideWatch 和 r/Depression。通过人工标注,每篇帖子都被标记为表明有自杀意念或没有自杀意念。我们利用该数据集进行帖子级二元自杀意念预测(任务 4)。
**CSSRS-Suicide
**CSSRS-Suicide 数据集包含来自 15 个心理健康相关子论坛的贡献,四名活跃的精神病学家按照哥伦比亚自杀严重程度评定量表(C-SSRS)的指导原则对 500 名用户进行了注释。我们从五个层面对用户进行了人工标注:支持、指标、意念、行为和自杀未遂风险。我们利用该数据集完成了两项用户级任务:二元自杀风险预测(即用户是否至少表现出一个自杀指标,任务 5)和五级自杀风险预测(任务 6)。
训练数据和测试数据的分割比例以及数据数量如下图所示。
这些结果已在前面介绍过。
总结
当没有用于微调的数据和计算资源时,使用注重任务解决的 LLM 可能会产生更好的结果。在有足够数据和计算资源的情况下,对基于对话的模型进行微调已被证明是更好的选择。
另一方面,我们也注意到,像 Alpaca 这样具有交互式对话功能的模型可能更适合下游应用,例如为最终用户提供心理健康支持。
未来的挑战有两个
- 需要进行更多的案例研究,使其更接近实际应用。
- 多个数据集,需要使用更多 LLM 进行验证