前言 Encoder-decoder 模型在序列到序列的自然语言处理任务(如语言翻译等)中提供了最先进的结果。多步时间序列预测也可以被视为一个 seq2seq 任务,可以使用 encoder-decoder 模型来处理。本文提供了一个用于解决 Kaggle 时间序列预测任务的 encoder-decoder 模型,并介绍了获得前 10% 结果所涉及的步骤。
数据集
所使用的数据集来自过去的 Kaggle 竞赛 ------ Store Item demand forecasting challenge,给定过去 5 年的销售数据(从 2013 年到 2017 年)的 50 个商品来自 10 家不同的商店,预测接下来 3 个月(2018 年 1 月 1 日至 2018 年 3 月 31 日)每个商品的销售情况。这是一个多步多元的时间序列预测问题。

特征也非常的少
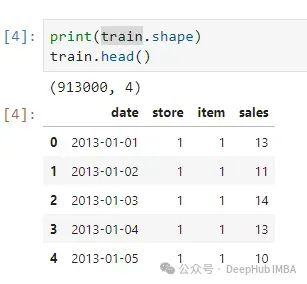
有500个商店组合,这意味着要预测500个时间序列。

数据预处理
深度学习模型擅长自行发现特征,因此可以将特征工程简化到最少。
从图表中可以看出,我们的数据具有每周和每月的季节性以及每年的趋势,为了捕捉这些特性,可以向模型提供DateTime 特征。为了更好地捕捉每个商品销售的年度趋势,还提供了年度自相关性。

时间的特征是有周期性的,为了将这些信息提供给模型,对 DateTime 特征应用了正弦和余弦变换。

最终的特征如下所示。

神经网络期望所有特征的值都在相同的尺度上,因此数据缩放变得必不可少。每个时间序列的值都是独立归一化的。年度自相关和年份也进行了归一化。
Encoder-decoder 模型接受一个序列作为输入并返回一个序列作为输出,所以需要将数据转为序列
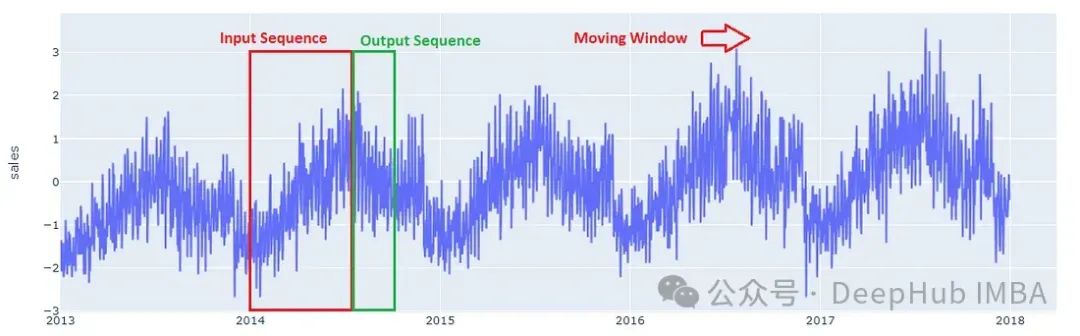
输出序列的长度固定为 90 天,而输入序列的长度必须根据问题的复杂性和可用的计算资源来选择。对于这个问题,可以选择 180 天(6 个月)的输入序列长度。通过在数据集中的每个时间序列上应用滑动窗口来构建序列数据。
数据集和数据加载器
Pytorch 提供了方便的抽象 ------ Dataset 和 Dataloader ------ 用于将数据输入模型。Dataset 接受序列数据作为输入,并负责构建每个数据点以输入到模型中。Dataloader 则可以读取Dataset 生成批量的数据
python
class StoreItemDataset(Dataset):
def \_\_init\_\_(self, cat\_columns=\[\], num\_columns=\[\], embed\_vector\_size=None, decoder\_input=True, ohe\_cat\_columns=False):
super().\_\_init\_\_()
self.sequence\_data = None
self.cat\_columns = cat\_columns
self.num\_columns = num\_columns
self.cat\_classes = {}
self.cat\_embed\_shape = \[\]
self.cat\_embed\_vector\_size = embed\_vector\_size if embed\_vector\_size is not None else {}
self.pass\_decoder\_input=decoder\_input
self.ohe\_cat\_columns = ohe\_cat\_columns
self.cat\_columns\_to\_decoder = False
def get\_embedding\_shape(self):
return self.cat\_embed\_shape
def load\_sequence\_data(self, processed\_data):
self.sequence\_data = processed\_data
def process\_cat\_columns(self, column\_map=None):
column\_map = column\_map if column\_map is not None else {}
for col in self.cat\_columns:
self.sequence\_data\[col\] = self.sequence\_data\[col\].astype('category')
if col in column\_map:
self.sequence\_data\[col\] = self.sequence\_data\[col\].cat.set\_categories(column\_map\[col\]).fillna('#NA#')
else:
self.sequence\_data\[col\].cat.add\_categories('#NA#', inplace=True)
self.cat\_embed\_shape.append((len(self.sequence\_data\[col\].cat.categories), self.cat\_embed\_vector\_size.get(col, 50)))
def \_\_len\_\_(self):
return len(self.sequence\_data)
def \_\_getitem\_\_(self, idx):
row = self.sequence\_data.iloc\[\[idx\]\]
x\_inputs = \[torch.tensor(row\['x\_sequence'\].values\[0\], dtype=torch.float32)\]
y = torch.tensor(row\['y\_sequence'\].values\[0\], dtype=torch.float32)
if self.pass\_decoder\_input:
decoder\_input = torch.tensor(row\['y\_sequence'\].values\[0\]\[:, 1:\], dtype=torch.float32)
if len(self.num\_columns) > 0:
for col in self.num\_columns:
num\_tensor = torch.tensor(\[row\[col\].values\[0\]\], dtype=torch.float32)
x\_inputs\[0\] = torch.cat((x\_inputs\[0\], num\_tensor.repeat(x\_inputs\[0\].size(0)).unsqueeze(1)), axis=1)
decoder\_input = torch.cat((decoder\_input, num\_tensor.repeat(decoder\_input.size(0)).unsqueeze(1)), axis=1)
if len(self.cat\_columns) > 0:
if self.ohe\_cat\_columns:
for ci, (num\_classes, \_) in enumerate(self.cat\_embed\_shape):
col\_tensor = torch.zeros(num\_classes, dtype=torch.float32)
col\_tensor\[row\[self.cat\_columns\[ci\]\].cat.codes.values\[0\]\] = 1.0
col\_tensor\_x = col\_tensor.repeat(x\_inputs\[0\].size(0), 1)
x\_inputs\[0\] = torch.cat((x\_inputs\[0\], col\_tensor\_x), axis=1)
if self.pass\_decoder\_input and self.cat\_columns\_to\_decoder:
col\_tensor\_y = col\_tensor.repeat(decoder\_input.size(0), 1)
decoder\_input = torch.cat((decoder\_input, col\_tensor\_y), axis=1)
else:
cat\_tensor = torch.tensor(
\[row\[col\].cat.codes.values\[0\] for col in self.cat\_columns\],
dtype=torch.long
)
x\_inputs.append(cat\_tensor)
if self.pass\_decoder\_input:
x\_inputs.append(decoder\_input)
y = torch.tensor(row\['y\_sequence'\].values\[0\]\[:, 0\], dtype=torch.float32)
if len(x\_inputs) > 1:
return tuple(x\_inputs), y
return x\_inputs\[0\], y模型架构
Encoder-decoder 模型是一种用于解决序列到序列问题的循环神经网络(RNN)。
Encoder-decoder 模型由两个网络组成------编码器(Encoder)和解码器(Decoder)。编码器网络学习(编码)输入序列的表示,捕捉其特征或上下文,并输出一个向量。这个向量被称为上下文向量。解码器网络接收上下文向量,并学习读取并提取(解码)输出序列。
在编码器和解码器中,编码和解码序列的任务由一系列循环单元处理。。
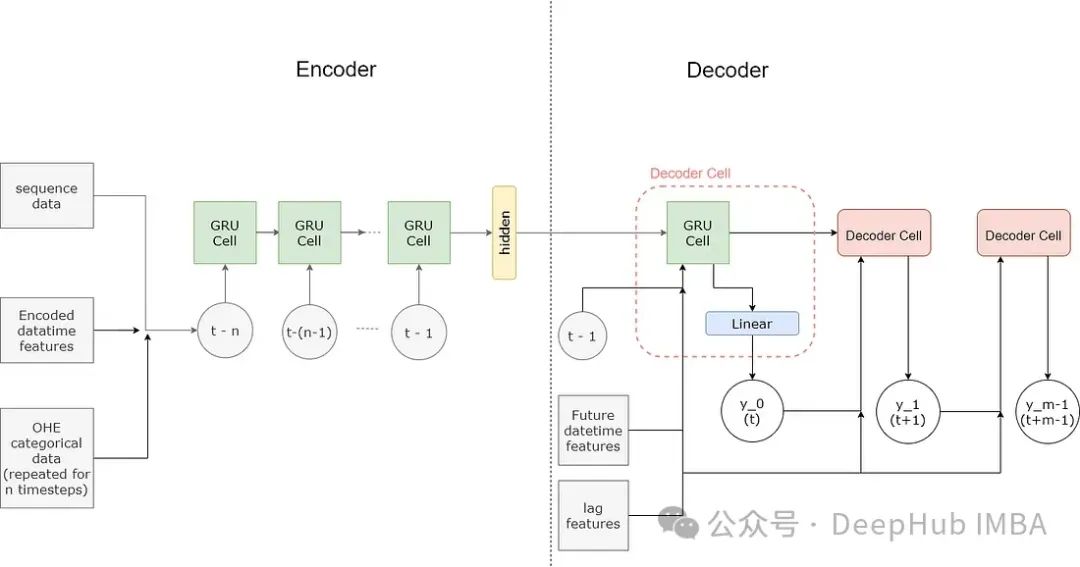
编码器
编码器网络的输入形状为(序列长度,特征维度),因此序列中的每个项目由 n 个值组成。在构建这些值时,不同类型的特征被不同对待。
时间依赖特征 --- 这些是随时间变化的特征,如销售和 DateTime 特征。在编码器中,每个连续的时间依赖值被输入到一个 RNN 单元中。
数值特征 --- 不随时间变化的静态特征,如序列的年度自相关。这些特征在序列的长度中重复,并被输入到 RNN 中。重复和合并值的过程在 Dataset 中处理。
分类特征 --- 如商店 ID 和商品 ID 等特征,可以通过多种方式处理,每种方法的实现可以在 encoders.py 中找到。对于最终模型,分类变量进行了独热编码,跨序列重复,并被输入到 RNN 中,这也在 Dataset 中处理。
带有这些特征的输入序列被输入到循环网络 --- GRU 中。下面给出了使用的编码器网络的代码。
python
class RNNEncoder(nn.Module):
def \_\_init\_\_(self, rnn\_num\_layers=1, input\_feature\_len=1, sequence\_len=168, hidden\_size=100, bidirectional=False, device='cpu', rnn\_dropout=0.2):
super().\_\_init\_\_()
self.sequence\_len = sequence\_len
self.hidden\_size = hidden\_size
self.input\_feature\_len = input\_feature\_len
self.num\_layers = rnn\_num\_layers
self.rnn\_directions = 2 if bidirectional else 1
self.gru = nn.GRU(
num\_layers=rnn\_num\_layers,
input\_size=input\_feature\_len,
hidden\_size=hidden\_size,
batch\_first=True,
bidirectional=bidirectional,
dropout=rnn\_dropout
)
self.device = device
def forward(self, input\_seq):
ht = torch.zeros(self.num\_layers \* self.rnn\_directions, input\_seq.size(0), self.hidden\_size, device=self.device)
if input\_seq.ndim < 3:
input\_seq.unsqueeze\_(2)
gru\_out, hidden = self.gru(input\_seq, ht)
print(gru\_out.shape)
print(hidden.shape)
if self.rnn\_directions \* self.num\_layers > 1:
num\_layers = self.rnn\_directions \* self.num\_layers
if self.rnn\_directions > 1:
gru\_out = gru\_out.view(input\_seq.size(0), self.sequence\_len, self.rnn\_directions, self.hidden\_size)
gru\_out = torch.sum(gru\_out, axis=2)
hidden = hidden.view(self.num\_layers, self.rnn\_directions, input\_seq.size(0), self.hidden\_size)
if self.num\_layers > 0:
hidden = hidden\[-1\]
else:
hidden = hidden.squeeze(0)
hidden = hidden.sum(axis=0)
else:
hidden.squeeze\_(0)
return gru\_out, hidden解码器
解码器接收来自编码器的上下文向量,解码器的输入还包括未来的 DateTime 特征和滞后特征。模型中使用的滞后特征是前一年的值。使用滞后特征的原因是,鉴于输入序列仅限于 180 天,提供超出此时间的重要数据点将有助于模型。
不同于直接使用循环网络(GRU)的编码器,解码器是通过循环一个解码器单元来构建的。这是因为从每个解码器单元获得的预测作为输入传递给下一个解码器单元。每个解码器单元由一个 GRUCell 组成,其输出被输入到一个全连接层,该层提供预测。每个解码器单元的预测被组合形成输出序列。
python
class DecoderCell(nn.Module):
def \_\_init\_\_(self, input\_feature\_len, hidden\_size, dropout=0.2):
super().\_\_init\_\_()
self.decoder\_rnn\_cell = nn.GRUCell(
input\_size=input\_feature\_len,
hidden\_size=hidden\_size,
)
self.out = nn.Linear(hidden\_size, 1)
self.attention = False
self.dropout = nn.Dropout(dropout)
def forward(self, prev\_hidden, y):
rnn\_hidden = self.decoder\_rnn\_cell(y, prev\_hidden)
output = self.out(rnn\_hidden)
return output, self.dropout(rnn\_hidden)Encoder-Decoder模型
下面代码将上面2个模型整合完成完整的seq2seq模型
python
class EncoderDecoderWrapper(nn.Module):
def \_\_init\_\_(self, encoder, decoder\_cell, output\_size=3, teacher\_forcing=0.3, sequence\_len=336, decoder\_input=True, device='cpu'):
super().\_\_init\_\_()
self.encoder = encoder
self.decoder\_cell = decoder\_cell
self.output\_size = output\_size
self.teacher\_forcing = teacher\_forcing
self.sequence\_length = sequence\_len
self.decoder\_input = decoder\_input
self.device = device
def forward(self, xb, yb=None):
if self.decoder\_input:
decoder\_input = xb\[-1\]
input\_seq = xb\[0\]
if len(xb) > 2:
encoder\_output, encoder\_hidden = self.encoder(input\_seq, \*xb\[1:-1\])
else:
encoder\_output, encoder\_hidden = self.encoder(input\_seq)
else:
if type(xb) is list and len(xb) > 1:
input\_seq = xb\[0\]
encoder\_output, encoder\_hidden = self.encoder(\*xb)
else:
input\_seq = xb
encoder\_output, encoder\_hidden = self.encoder(input\_seq)
prev\_hidden = encoder\_hidden
outputs = torch.zeros(input\_seq.size(0), self.output\_size, device=self.device)
y\_prev = input\_seq\[:, -1, 0\].unsqueeze(1)
for i in range(self.output\_size):
step\_decoder\_input = torch.cat((y\_prev, decoder\_input\[:, i\]), axis=1)
if (yb is not None) and (i > 0) and (torch.rand(1) < self.teacher\_forcing):
step\_decoder\_input = torch.cat((yb\[:, i\].unsqueeze(1), decoder\_input\[:, i\]), axis=1)
rnn\_output, prev\_hidden = self.decoder\_cell(prev\_hidden, step\_decoder\_input)
y\_prev = rnn\_output
outputs\[:, i\] = rnn\_output.squeeze(1)
return outputs训练
模型的性能高度依赖于优化、学习率等超参数和策略
-
验证策略 ------ 由于我们的数据是时间依赖的,交叉的训练-验证-测试分割不适用。时间依赖的训练-验证-测试分割存在一个问题,即模型没有在最近的验证数据上进行训练,这影响了模型在测试数据上的表现。为了解决这个问题,模型在过去 3 年的数据(2014 到 2016 年)上进行训练,并预测 2017 年的前 3 个月,这用于验证和实验。最终模型在 2014 到 2017 年的数据上进行训练,并预测 2018 年的前 3 个月。最终模型基于验证模型训练的学习成果,以盲模式(无验证)进行训练。
-
优化器 ------ 使用的优化器是 AdamW,它在许多学习任务中提供了最佳结果。另一个探索的优化器是 COCOBOptimizer,它不显式设置学习率。在使用 COCOBOptimizer 训练时,我观察到它比 AdamW 尤其是在初始迭代时收敛更快。但使用 AdamW 和单周期学习得到了最佳结果。
-
学习率调度 ------ 使用了 1cycle 学习率调度器。通过使用循环学习的学习率查找器确定了周期中的最大学习率。
-
损失函数 ------ 使用的损失函数是均方误差损失(MSE),这与最终测试的损失 ------ SMAPE 不同。MSE 损失提供了更稳定的收敛性,优于使用 SMAPE。
-
为编码器和解码器网络使用了不同的优化器和调度器,这带来了结果的改进。
-
除了权重衰减外,还在编码器和解码器中使用了 dropout 来对抗过拟合。
结果
下图显示了该模型对2018年前3个月某家商店单品的预测。
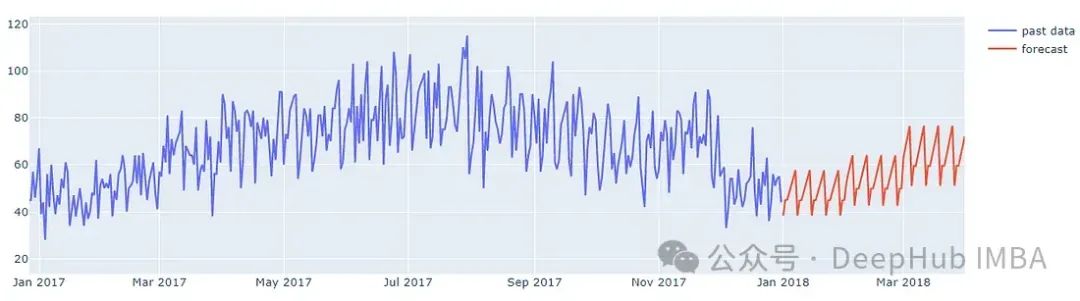
通过绘制所有商品的平均销售额,以及均值预测来去除噪声,可以更好地评估模型。下图来自验证模型对特定日期的预测,可以与实际销售数据进行比较。

这个结果在竞赛排行榜中提供前10%的排名。

总结
本文演示了使用Encoder-Decoder 模型创建多步时间序列预测的完整步骤,但是为了达到这个结果(10%),作者还做了超参数调优。并且这个模型还没有增加注意力机制,所以还可以通过探索注意机制来进一步改进模型,进一步提高模型的记忆能力,应该能获得更好的分数。
如何学习AI大模型?
?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 "AI会取代那些行业?""谁的饭碗又将不保了?"等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码 领取🆓↓↓↓
👉CSDN大礼包🎁:[全网最全《LLM大模型入门+进阶学习资源包》免费分享](https://hnxx.oss-cn-shanghai.aliyuncs.com/official/1725500307561.jpg?t=0.4405313375184585)**(安全链接,放心点击)**()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
