
当您考虑对象存储工作负载和存储类型时,数据库正日益成为核心工作负载。这些变化是由两股力量驱动的:高性能对象存储的可用性以及数据(特别是其相关元数据)的爆炸式增长。由于这两大力量,几乎每个主要数据库供应商现在都包含与 S3 兼容的终端节点。此外,对于许多组织和大多数工作负载来说,这成为默认架构,无论是在云中还是在本地。让我们简要地探讨一下这些概念。
性能
在过去几年中,与数据库相关的存储性能要求发生了逆转。数据库以前需要高 IOPS。这是需要在整个网络中进行大量小更改的功能。这非常适合 SAN 和 NAS 架构,因此数据库成为他们的生计。问题在于 IOPS 的可扩展性不是特别强 - 至少在经济上是这样。数据库不再将网络上的数据更改为 4KB 块。相反,它们将 MB 大小的扩展数据块中的对象(特别是表段)流式传输到客户端内存,并在本地更改它们。本地内存 IOPS 与 100GBe 相结合,使这成为吞吐量问题,而不是 IOPS 问题。对象存储是吞吐量驱动的,而不是 IOPS 或延迟驱动的。即使在高性能对象存储和 NVMe 驱动器的今天也是如此。新的数据库模型非常适合对象存储,因为盘区本质上是不可变的。由于每项更改都会自动进行版本控制,因此对象存储可以提供持续的数据保护,而无需快照。就 MinIO 而言,我们不仅在吞吐量方面是世界上最快的对象存储,而且 MinIO 在表段范围为 256K 到 2MB 的小对象性能方面也表现出色。这样做的原因很重要。MinIO 不使用元数据数据库,因为它采用确定性哈希来查找对象。当您将这些表段存储为小对象时,其他对象存储实现很快就会不堪重负。
对于托管数据库的对象存储,它需要提供卓越的吞吐量以及可接受的延迟。它在这些指标上做得越好,迁移到对象的工作负载百分比就越大。这应该是有道理的。如果对象存储可以提供硬件阻塞吞吐量和可接受的延迟,则它可以运行 80% 或更多的数据库要求。如果不能,则它仅适用于 20-30% 的工作负载 - 有效的备份。MinIO 满足了这些新要求,因此,它是这种日益流行的架构的领先对象存储。如果这听起来很熟悉,那应该是。这是解耦的叙述。数据库供应商实际上已经选择将存储和计算分开,将计算端据为己有,并将存储卸载到高性能对象存储。它们专注于分布式、高性能的查询处理。通过这样做,他们专注于特性和功能,并将繁重的存储工作留给了 MinIO 等公司。结果是,由于对象存储的可扩展性属性,他们现在可以拥有越来越大的数据范围。让我们暂时将注意力转向那里。
可扩展性
大多数文件和块系统都不是为扩展而设计的。因此,当您超过 100TB 时,就开始做出权衡。当您达到 1PB 时 - 对于这些系统来说,您就处于稀薄的空气中。另一方面,对象存储刚刚开始达到 1PB 的最佳位置。从那里开始,天空就是极限。这使得对象存储成为数据库的理想补充,这些数据库旨在应对涵盖组织数据大型组件的巨型应用程序工作负载。考虑到快速对象存储的吞吐量能力,该模型很简单。一小部分数据保存在"内存中"以实现超快速处理,而绝大多数数据位于非常非常温暖的层中 - 使用定义现代应用程序生态系统的标准 S3 调用提供。当支持 S3 Select 时,这种效果更加有效。只有少数供应商支持这种谓词下推功能,而且没有一个供应商能够提供高性能。MinIO 是 - 因此,您可以从 PB 级数据中提取您需要的数据。这就是 MinIO 在数据库供应商社区中如此受欢迎的原因。
Altinity/Clickhouse
我们与 Altinity 的合作就是一个很好的例子,Altinity 专注于速度极快、功能丰富、功能丰富的 Clickhouse 数据仓库。Altinity 在此处提供了有关将两者集成的出色教程。然而,更有趣的是他们在 OnTime 和 NYC Taxi 数据集上比较 MinIO 和 AWS 的工作。OnTime 数据集包含近 2 亿行航空公司航班数据。Altinity 选择此数据集进行性能基准测试,因为该数据集包含 109 列。
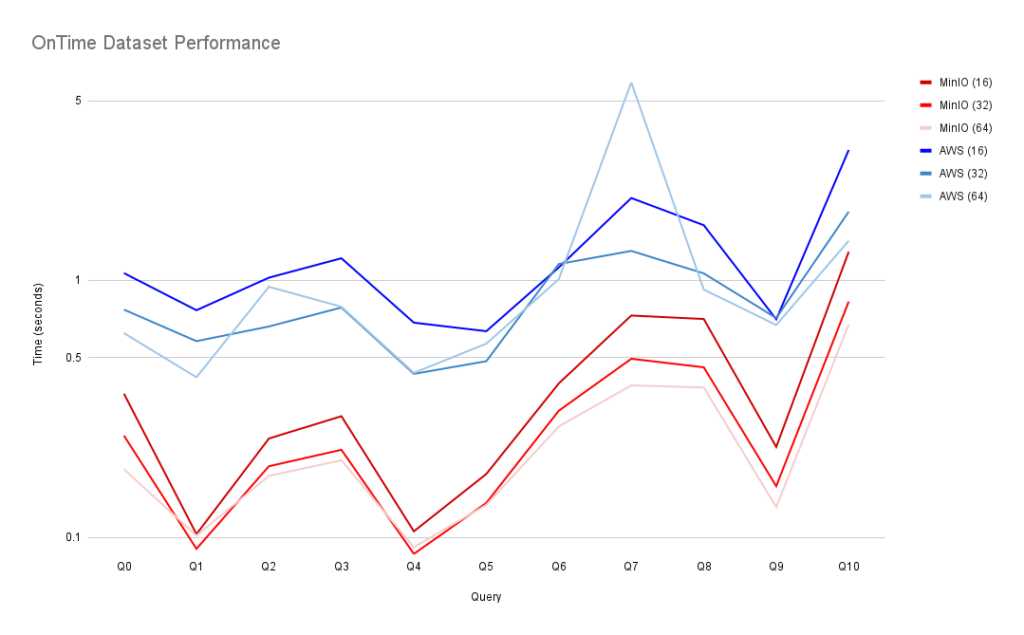
基准测试利用 S3 Select 来优化数据摄取,从而加快查询速度。Altinity 还对 NYC Taxi Dataset 进行了基准测试,这可能是使用最广泛的基准测试数据集。数据集有 11 亿条记录,51 列,未压缩的 CSV 格式大小为 500 GB。同样,对于 "对象存储" 来说,速度简直是惊人的:
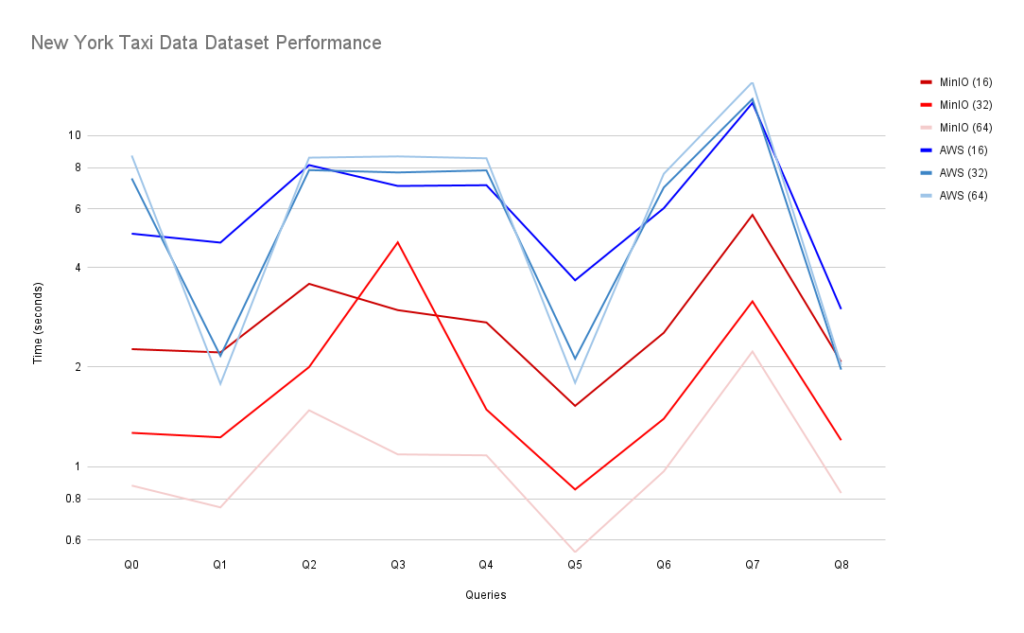
这些速度将使 Clickhouse/MinIO 在 Mark Litwintschik 的快速数据库列表(公平地说,也是快速硬件)中排名前 15 位。同样 - 我们鼓励您完整地阅读这些帖子。
Snowflake
Snowflake 是 Amazon S3 中最大的工作负载之一,也是增长最快的工作负载之一。它建立在对象存储之上 - 就像所有其他现代系统一样。他们当然可以选择在 EFS 或 EBS 上构建,但他们没有。这不仅仅是经济问题。而是规模。
Microsoft SQL Server
SQL Server 是最早支持对象存储的服务器之一,而 MinIO 是其实现的典型代表。我们有很多内容,但你可以从这里开始。
InfluxDB
Influx 是另一个例子。这个基于 Go 的出色时间序列数据库使对象存储成为一等公民,并继续加倍下注。
其他示例
不要只相信我们的话。以您最喜欢的数据库为例。就像 MongoDB。或 MariaDB。或 CockroachDB。或 Teradata。或者 DuckDB。或者 列表很长而且很出色,Google 可以快速带您到达那里...
结论
S3 API 是当今存储的事实标准,将 POSIX 降级为"不可逆的下降"状态。因此,现在几乎每个数据库都支持 S3 API,但只有极少数"与 S3 兼容的对象存储"能够提供性能和规模的组合,更重要的是,能够提供支持现代企业所需的使用案例范围所需的大规模性能。使用 MinIO,您可以获得这三者,这就是为什么我们是现代数据库和数据仓库的首选对象存储 - 无论是在本地还是在公共云中,MinIO 随处可见。结果是存储和计算的有效分离,并为这两个元素提供了最佳品种。我们鼓励您亲自尝试一下。您可以在此处下载 MinIO 或在您最喜欢的数据库博客上查找教程。只需输入他们的名字和 MinIO - 某人可能在某个地方已经完成了这项工作。