每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

Google推出的DataGemma模型填补了大型语言模型(Large Language Models, LLMs)与现实世界数据之间的鸿沟,通过利用Data Commons知识图谱来提升LLM回应的真实性与可信度。
虽然LLM革新了人们与信息互动的方式,但确保它们的回应基于可验证的事实仍是一个重大挑战。现实世界中的知识往往分散在多个来源中,每个来源都有不同的数据格式、模式和API,这使得访问和整合变得困难。缺乏这种事实基础会导致模型"幻觉"------即生成错误或误导性信息。打造负责任且值得信赖的AI系统是Google研究的核心目标,解决LLM中的幻觉问题对于实现这一目标至关重要。
Google今天发布了DataGemma,这是一组实验性的开源模型,旨在通过将LLM与Google Data Commons庞大的现实世界统计数据结合来应对幻觉问题。Data Commons已具备自然语言界面,DataGemma正是利用这一现有接口,以自然语言作为"API",让用户可以直接问诸如"加州的就业行业有哪些?"或"有哪些国家的森林面积在增加?"这样的问题,而无需编写传统的数据库查询语句。借助Data Commons,Google克服了不同数据模式和API带来的复杂性,实际上提供了一个统一的"外部数据源API"。
Data Commons:事实性AI的基础
Data Commons是Google公开的知识图谱,包含全球超过2500亿个数据点,涵盖数十万个统计变量。这些数据来自联合国、世界卫生组织、卫生部、统计局等可信机构,涉及经济、气候变化、健康和人口等多个领域。这一庞大的数据仓库不断扩展其全球覆盖范围,为构建更加可靠和有依据的AI提供了坚实的基础。
DataGemma将LLM与现实世界数据相连接
Gemma系列是轻量级的开源模型家族,基于与Google Gemini模型相同的研究和技术构建。DataGemma通过利用Data Commons中的知识扩展了Gemma家族的能力,从而增强了LLM的事实性与推理能力。通过创新的数据检索技术,DataGemma帮助LLM从可信机构获取数据(包括政府、国际组织和非政府组织),减少幻觉的风险,提升模型输出的可信度。
与传统方法不同,使用DataGemma不需要掌握底层数据集的具体模式或API。它通过Data Commons的自然语言接口直接发出问题,而关键在于训练LLM知道何时提问。为此,Google使用了两种不同的方法:检索交错生成(RIG)和检索增强生成(RAG)。
检索交错生成(RIG)
这种方法对Gemma 2模型进行微调,使其在生成回应时能识别出其中的统计数据,并通过调用Data Commons进行验证。相当于模型对自己的回答进行"复查"。
RIG的工作流程如下:
- 用户查询:用户向LLM提交查询。
- 初始响应与Data Commons查询:DataGemma模型基于微调后的Gemma 2模型生成回应,同时生成自然语言查询,调用Data Commons获取相关数据。例如,模型不会直接回答"加州人口为3900万",而是回答"加州人口为DC(加州人口是多少?) → 3900万",允许外部验证以提高准确性。
- 数据检索与修正:查询Data Commons并检索数据,这些数据与来源信息及链接一起被自动用于修正初始响应中的潜在错误。
- 最终响应与来源链接:最终的响应包括数据来源和Data Commons的元数据,以便透明度和验证。
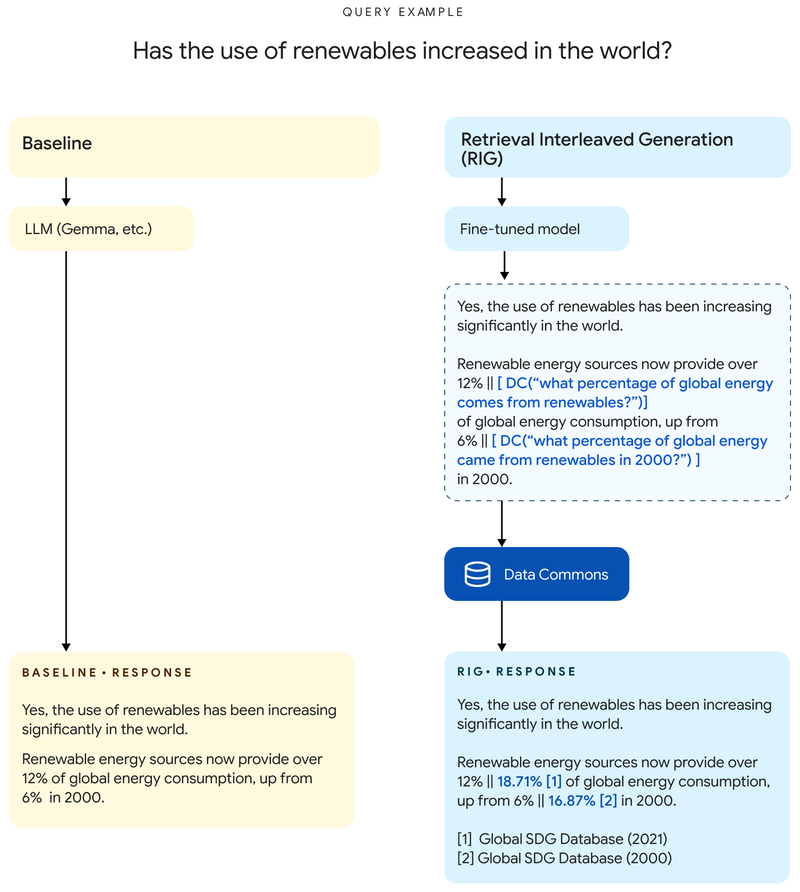
RIG方法的优势在于不改变用户的查询,能在各种情境下有效运作,但LLM并不会保留来自Data Commons的更新数据,导致后续的推理或查询无法反映新信息。
检索增强生成(RAG)
RAG方法在LLM生成文本之前,首先从Data Commons检索相关信息,为其回应提供事实基础。然而,由于广泛查询返回的数据可能包含大量跨多个年份的数据表,因此RAG需要利用Gemini 1.5 Pro模型的长上下文窗口,来处理如此大量的数据输入。
RAG的工作流程如下:
- 用户查询:用户向LLM提交查询。
- 查询分析与Data Commons查询生成:DataGemma模型分析用户查询,生成相应的自然语言查询,向Data Commons接口提问。
- 从Data Commons检索数据:利用该查询,Data Commons检索到相关的数据表、来源信息和链接。
- 增强提示词:检索到的信息与用户查询结合,生成增强后的提示词。
- 最终响应生成:通过Gemini 1.5 Pro模型使用这个增强后的提示词,生成更具事实依据的完整回应。
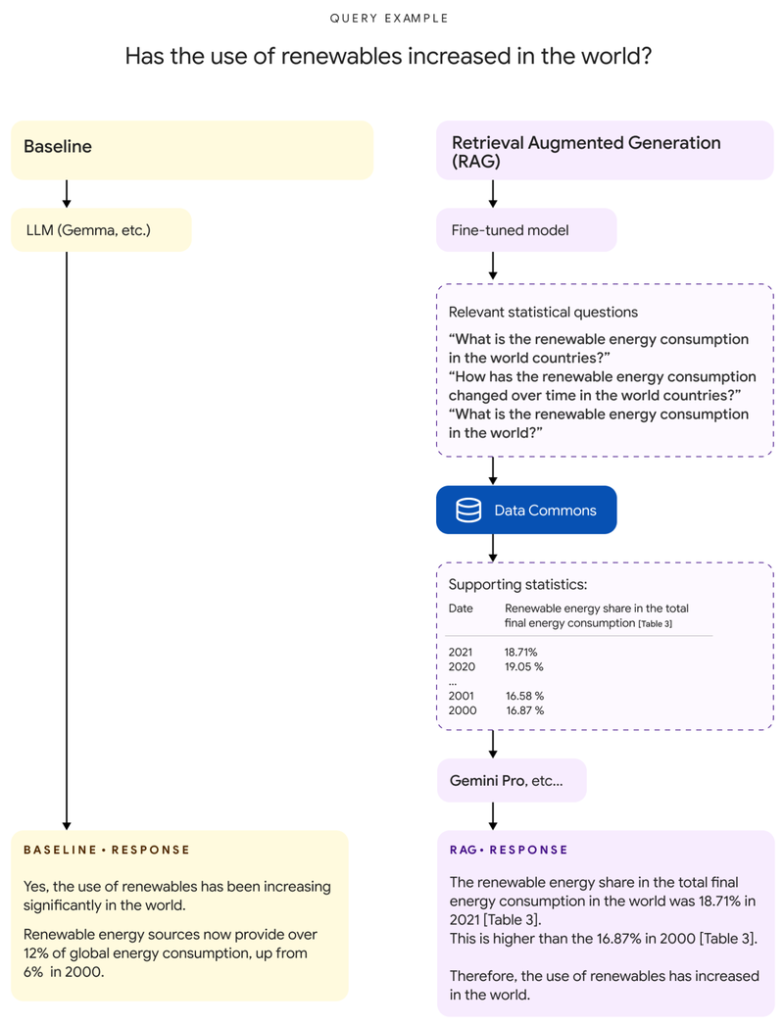
RAG的优点在于随着LLM模型的进化,其生成的响应也会更加准确。缺点是修改用户的提示词可能会导致使用体验不够直观,且效果取决于查询Data Commons的质量。
参与构建有据可依的AI未来
虽然DataGemma是向前迈出的重要一步,Google认识到这一领域仍处于早期阶段。Google邀请研究人员、开发者以及对负责任AI感兴趣的各方一起探索DataGemma,共同推动这项技术的发展。通过将LLM与Data Commons中的现实世界数据结合,未来的AI不仅会更加智能,还会建立在事实和证据的基础之上。
对于想要深入了解DataGemma研究背景的人员,可以参考Google的研究论文。此外,Google希望研究人员能够超越Data Commons的具体实现,扩展这项技术至其他知识图谱格式。
准备好开始了吗?可以从Hugging Face或Kaggle下载DataGemma模型(RIG、RAG),并通过Google提供的快速入门笔记本探索它的功能。https://huggingface.co/collections/google/datagemma-release-66df7636084d2b150a4e6643