本文记录使用PaddleNLP进行文本分类的全流程
文章目录
-
- [1. 数据准备](#1. 数据准备)
- [2. 模型训练](#2. 模型训练)
-
- [2.1 准备关键库](#2.1 准备关键库)
- [2.2 模型训练&验证](#2.2 模型训练&验证)
- [2.3 模型测试](#2.3 模型测试)
- [2.4 结果分析](#2.4 结果分析)
- [3. 模型部署](#3. 模型部署)
-
- [3.1 编写预测脚本](#3.1 编写预测脚本)
- [3.2 Flask搭建服务](#3.2 Flask搭建服务)
- [3.3 Docker包装环境](#3.3 Docker包装环境)
- [4. 小结](#4. 小结)
1. 数据准备
【STEP1】:拿到用来训练的数据 train.xlsx 和用来测试的数据 test.xlsx,确定训练集测试集数据来源一致。
【STEP2】:PaddleNLP要求训练过程中有三个文件:train.txt,val.txt,class.txt
-
准备train.txt和val.txt: 将用来训练的数据划分训练集和验证集,PaddleNLP要求训练和验证集采用'.txt'文件格式,并且每一行数据为:content + '\t' + label 的形式
-
准备class.txt: 将类别标签那一列去重后保存,每一行是一个类别
python
def prepare_txt(data_fp,tar_fp,rate):
"""
准备训练、验证数据集以及标签文件
:param data_fp:训练数据路径
:param tar_fp:保存处理好的数据文件夹路径
:param rate:训练集比率
:return:
"""
data = pd.read_excel(data_fp, rate)
# 保存类别标签数据class.txt
data['label'].drop_duplicates().to_csv(os.path.join(tar_fp, 'class.txt'),index=False,header=None)
data_shuffle = data.sample(frac=1).reset_index(drop=True)
print(f"处理后:{data.shape[0]}")
length = data.shape[0]
train_num = int(length * rate)
test_num = length - train_num
train_data = data_shuffle.iloc[: train_num, :]
test_data = data_shuffle.iloc[train_num:, :]
train_data_txt = train_data[['content', 'label']]
test_data_txt = test_data[['content', 'label']]
# 保存训练集和验证集
with open(os.path.join(tar_fp,'train_data.txt'),'w',encoding='utf-8') as f:
for i in tqdm(range(len(train_data_txt))):
f.write(str(train_data_txt.iloc[i,0]) + '\t' + str(train_data_txt.iloc[i,1]) + '\n')
with open(os.path.join(tar_fp,'test_data.txt'),'w',encoding='utf-8') as f:
for i in tqdm(range(len(test_data_txt))):
f.write(str(test_data_txt.iloc[i,0]) + '\t' + str(test_data_txt.iloc[i,1]) + '\n')设置好路径运行后得到三个文件:
2. 模型训练
2.1 准备关键库
安装关键库:paddlepaddle-gpu建议根据官网安装教程安装,选择适配的版本(安装教程:https://www.paddlepaddle.org.cn/install/old?docurl=/documentation/docs/zh/install/pip/windows-pip.html)
plaintext
python==3.9.19
paddlenlp==2.5.2
paddlepaddle-gpu==2.5.2.post120
pandas==1.5.2
sklearn==1.0.2
numpy==1.23.5把PaddleNLP目录下的train.py和utils.py粘贴到本地项目中:(PaddleNLP版本为2.5.2好像把evaluate.py合并到train.py中,设置参数do_eval就可以完成验证)

2.2 模型训练&验证
主要调整:(各个参数含义在参考网站下有说明)
- batch_size:越大越好占满显存
- model_name_or_path:选择需要使用的模型,综合考虑运行时间和精度
- early_stopping和early_stopping_patience:早停策略:n个epoch没提升就停止训练,节省时间,同时可以把num_train_epochs设大一点
- train_path / dev_path / label_path:替换训练集和验证集路径
bash
python ./train.py \
--do_train \
--do_eval \
--do_export \
--dataloader_num_workers 8 \
--model_name_or_path ernie-3.0-medium-zh \
--output_dir ./dispose_model_2024712 \
--overwrite_output_dir True \
--load_best_model_at_end True \
--early_stopping True \
--early_stopping_patience 3 \
--device gpu \
--num_train_epochs 100 \
--logging_steps 5 \
--evaluation_strategy epoch \
--save_strategy epoch \
--per_device_train_batch_size 128 \
--per_device_eval_batch_size 128 \
--max_length 128 \
--save_total_limit 1 \
--train_path ./train_data.txt \ # 替换准备好的训练数据集路径
--dev_path ./test_data.txt \ # 替换准备好的验证数据集路径
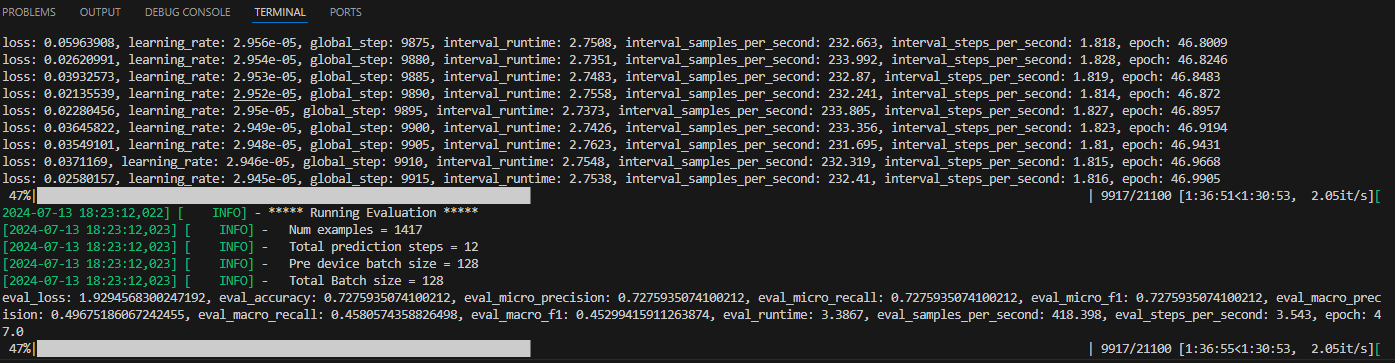
--label_path ./class.txt # 替换准备好的标签集合路径终端有训练日志输出即为开启训练,loss有下降说明正常训练,根据设置的参数每个epoch结束会在验证集上验证结果:
2.3 模型测试
【注】老版本可以用evaluate.py来预测测试集得到模型预测结果,新版本需要将模型导出为pdmodel格式后采用Taskflow进行预测,流程如下:
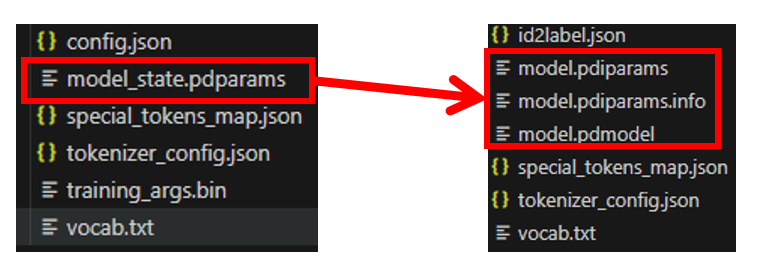
【Step1】模型导出:训练保存的模型(以及相关文件) VS 导出的模型(以及相关文件)差别对比:(主要多了一个.pdmodel文件)
模仿train.py中的模型导出写法,编写模型导出脚本,修改export_model_dir、model_name_or_path、class_txt路径
python
from paddlenlp.transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
export_model,
)
import paddle
import json
import os
from paddlenlp.utils.log import logger
export_model_dir = './export' # 模型导出路径
model_name_or_path = './model_fp' # 训练好的模型路径
class_txt = './model_fp/class.txt' # 类别标签txt
cls_list = []
with open(class_txt,'r',encoding='utf-8') as f:
for line in f.readlines():
cls_list.append(line.strip())
id2label = {}
label2id = {}
with open(class_txt, 'r', encoding='utf-8') as f:
for i,line in enumerate(f.readlines()):
id2label[f"{i}"] = line.strip()
label2id[line.strip()] = i
input_spec = [paddle.static.InputSpec(shape=[None, None], dtype="int64", name="input_ids")]
# input_spec = [
# paddle.static.InputSpec(shape=[None, None], dtype="int64", name="input_ids"),
# paddle.static.InputSpec(shape=[None, None], dtype="int64", name="token_type_ids"),
# ]
model = AutoModelForSequenceClassification.from_pretrained(
model_name_or_path, label2id=label2id, id2label=id2label
)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
export_model(model=model, input_spec=input_spec, path=export_model_dir)
tokenizer.save_pretrained(export_model_dir)
id2label_file = os.path.join(export_model_dir, "id2label.json")
with open(id2label_file, "w", encoding="utf-8") as f:
json.dump(id2label, f, ensure_ascii=False)
logger.info(f"id2label file saved in {id2label_file}")【Step2】模型预测:基于Taskflow编写预测脚本
python
from paddlenlp import Taskflow
import pandas as pd
from tqdm import tqdm
import os
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score,classification_report
import json
import numpy as np
def predict(model_fp, content_fp, save_fp):
"""预测结果
Args:
model_fp (str): 导出的模型路径
content_fp (str): 待预测的测试集路径(写的read_table读取txt)
save_fp (str): 保存路径
"""
# 模型预测
model = Taskflow("text_classification", task_path=model_fp, is_static_model=True)
content = pd.read_table(content_fp, header=None, encoding='utf_8_sig')
content.columns = ['data', 'label']
# 初始化 predict 和 score
content['predict'] = content['label']
content['score'] = content['label']
for i in tqdm(range(content.shape[0])):
tmp = content.loc[i, 'data']
pred = model([content.loc[i, 'data']])[0] # list
content.loc[i, 'predict'] = pred['predictions'][0]['label']
content.loc[i, 'score'] = pred['predictions'][0]['score']
content.to_excel(os.path.join(save_fp, 'test_data_predict.xlsx'))
if __name__ == '__main__':
# 预测
model_fp = './dispose_model_2024712/model_2024712/export'
content_fp = './dispose_data_2024712/data_2024712/test_data.txt'
save_fp = './dispose_data_2024712/report_valid'
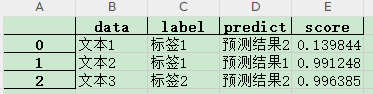
predict(model_fp, content_fp, save_fp)预测完成后打开test_data_predict.xlsx查看结果:存放了输入文本、标签、预测结果、置信度得分
2.4 结果分析
计算各个类别的指标,思路:
- 编写Metric类,存放数据读取、预处理和指标计算的方法
- preprocess():测试数据预处理:例如清洗没有标签的测试数据等,根据不同的数据和业务需求来定义
- cal_metrics_class()和cal_metrics_all():分别用来计算各个类的指标和总体指标并保存
- compute():预处理 => 计算指标 => 保存
python
import pandas as pd
import os
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score,classification_report
import json
import numpy as np
id2label = None
with open('./id2label.json', 'r', encoding='utf-8') as file:
id2label = json.load(file)
label2id = {value: int(key) for key, value in id2label.items()}
class Metric:
def __init__(self, pred_fp, true_label_col, pred_label_col, save_fp, score_thresh=0.9):
self.pred_fp = pred_fp
self.true_label_col = true_label_col
self.pred_label_col = pred_label_col
self.save_fp = save_fp
self.score_thresh = score_thresh
self.df = pd.read_excel(pred_fp)
# 确保输入的列名存在
assert self.true_label_col in self.df.columns, f"{self.true_label_col} not in DataFrame columns"
assert self.pred_label_col in self.df.columns, f"{self.pred_label_col} not in DataFrame columns"
self.label2id = label2id
self.id2label = id2label
print(f"测试集数量:{self.df.shape[0]}")
def compute(self):
self.preprocess()
# self.cal_metrics_all()
self.cal_metrics_class()
def preprocess(self):
print(f"所有测试数据条数为:{self.df.shape[0]}")
# 删除没有预测的项(label中包含测试的项目)
self.df['label'] = self.df['label'].replace(['',' '], np.nan)
self.df.dropna(axis=0, subset = ["label"], how='any', inplace=True)
print(f"删除未测试项后数据条数为:{self.df.shape[0]}")
# 根据 score_thresh 筛选数据
if self.score_thresh is not None:
self.df = self.df[self.df['score'] > self.score_thresh]
print(f"筛选score>{self.score_thresh}的数据有: {self.df.shape[0]}")
def cal_metrics_class(self):
# 生成分类报告
report = classification_report(
self.df[self.true_label_col],
self.df[self.pred_label_col],
output_dict=True
)
report_df = pd.DataFrame(report).T
cls_id = list(report.keys())
cls_name = [self.id2label[id.split('.')[0]] for id in cls_id[:-3]] # 去掉'accuracy', 'macro avg', 'weighted avg'这三个
report_df['category'] = cls_name + cls_id[-3:] # 加上'accuracy', 'macro avg', 'weighted avg'这三个
report_df = report_df[['category','precision','recall','f1-score','support']] # 调整一下顺序,把类别放第一个
# 重命名列以更清晰地表示指标
if self.save_fp is not None:
report_df.to_excel(os.path.join(self.save_fp, f'metrics_class_{self.score_thresh}.xlsx'), index=False)
def cal_metrics_all(self):
# 计算各项指标
accuracy = accuracy_score(self.df[self.true_label_col], self.df[self.pred_label_col])
precision = precision_score(self.df[self.true_label_col], self.df[self.pred_label_col], average='weighted')
recall = recall_score(self.df[self.true_label_col], self.df[self.pred_label_col], average='weighted')
f1 = f1_score(self.df[self.true_label_col], self.df[self.pred_label_col], average='weighted')
report_dict = {
'Accuracy': accuracy,
'Precision': precision,
'Recall': recall,
'F1 Score': f1
}
report_list = [value for value in report_dict.values()]
# 然后,创建DataFrame
report_df = pd.DataFrame(report_list, index=list(report_dict.keys())).T
report_df.columns = list(report_dict.keys())
if self.save_fp is not None:
report_df.to_excel(os.path.join(self.save_fp, f'metrics_all_{self.score_thresh}.xlsx'), index=False)
# 返回指标字典
return report_df【注】分析过程中出现的问题:
- 模型精度过低排除参数设置的问题外,基本都是数据问题,例如:测试集和训练集标签差别很大、
- 一般加载ERNIE模型后训练10-20个epoch左右基本就可以稳定
- 数据增强的作用在项目中微乎其微,不如清洗脏数据
3. 模型部署
模型部署主要分为以下步骤:
- 编写预测脚本:调用上一步中训练好的模型,通过接收'POST'请求的方式封装成预测函数
- Flask搭建服务:使用Flask给预测函数搭建搭建一个微服务
- Docker包装环境:编写Dockerfile构建镜像(如果服务器有gpu可以构建gpu镜像)
- 编写dockerfile:选择基础镜像构建环境(docker build)
- 运行镜像形成容器:docker run
- 镜像确认无误后移植到服务器上运行,将服务器端口号与容器端口号对应上
3.1 编写预测脚本
- 将模型和相关文件保存到对应文件夹
- 编写调用训练好的模型进行预测的函数predict(),根据业务需求设定判断条件
- 保存日志并以json的形式返回结果
python
def predict():
if request.method == 'POST':
start_time = time.time()
s1 = request.json
if "content" not in s1:
return jsonify({"success":False, "data":[], "message":"missing content"})
if "streetName" not in s1:
return jsonify({"success":False, "data":[], "message":"missing streetName"})
if "topK" not in s1:
return jsonify({"success":False, "data":[], "message":"missing topK"})
data = s1['content'].replace(' ', '').replace('\n', '').replace('\t', '').replace('\r', '')
street_name=s1['streetName']
topn=int(s1['topK'])
itext_all=data.replace('\n', '').replace('\r', '').replace('\t', '').replace(' ', '')+street_name
result = predict_dispose(itext_all, topn)
logger.info(f"{result} ----time cost: {(time.time() - start_time):.4f}")
return jsonify({
"success":True,
"data":result
})3.2 Flask搭建服务
基于Flask搭建微服务
- 给函数加上修饰器,指定路由
- 在主函数中启动服务
python
from flask import Flask, request, jsonify
import time
from config.utils import get_logger, get_config
from predict.load_model import init_model
from predict.load_model import predict_dispose
@app.route('/predict/dispose', methods=['GET', 'POST'])
def predict():
pass
if __name__ == '__main__':
config = get_config()
logger = get_logger("dispose")
init_model("dispose", config) # 加载模型参数
app.run(host='0.0.0.0', port=config.getint("service", "dispose_port")) # 根据配置文件获取端口号3.3 Docker包装环境
将环境打包成requirements.txt(或者自己写一下requirements)
python
conda list -e > requirements.txt下载并安装docker,编写Dockerfile:
docker
FROM python:3.9.19 # 基础镜像
RUN mkdir -p /app/${MODEL_PATH} # 新建app文件夹
# 把代码和模型COPY至镜像中
COPY config /app/config
COPY ./models/dispose/pingshan app/models/dispose/pingshan/
COPY ./predict app/predict
COPY dispose_api.py ./app/dispose_api.py
COPY utils.py ./app/utils.py
COPY requirements.txt ./app
# 设置工作路径
WORKDIR /app
# 根据requirements.txt安装库
RUN pip install -r requirements.txt -i https://mirrors.ustc.edu.cn/pypi/web/simple
# 启动服务
ENTRYPOINT ["python", "dispose_api.py"]使用docker build创建镜像:用-ip进行端口映射
dockerfile
docker build -t hs_classification_service . 创建成功后通过命令行输入 docker images 可以看到

本地启动服务,使用postman请求该服务确保没问题:docker run IMAGE ID
dockerfile
docker run -it --gpus all -ip <服务器端口>:<容器端口> 5c # -it显示终端结果 --gpus all:调用gpu,能在容器内用nvidia-smi
把镜像保存到本地.tar文件
plaintext
docker save -o D:\work\codes\proj\dockerfiles\docker_images\image1.tar 5ce023c786f6
把镜像文件传到服务器上(可以通过MobaXterm传输),通过docker load -i .tar来加载镜像,加载成功后用docker images查看
plaintext
docker load -i .tar在服务器上用docker run启动服务,并在本地电脑上使用postman向服务发送请求,正确返回预测结果即部署成功(cpu版本)
gpu版本
如果服务器有显卡则需要用docker部署gpu版本的paddle:
docker中配置cuda的环境变量:
plaintext
echo "export LD_LIBRARY_PATH=/dmdbms_x86/bin:/usr/local/cuda-11.0/lib64:\$LD_LIBRARY_PATH" >> /root/.bashrc 4. 小结
应用过程中一般使用现有模型就能满足大多数需求,如果精度差距很远多半是数据原因
模型部署需要知道的框架:flask\docker\nginx\
- flask:轻量级python服务框架
- docker:容器、镜像服务,模型部署必备
- nginx:网络服务,在对方服务器只能访问我方唯一端口时需要
部署流程:
- 本地编写Dockerfile成功build一个镜像
- 在flask run处指定host=0.0.0.0,端口号=指定端口号,并将docker中的端口号暴露出来
- 将该镜像传到服务器上,使用docker run