目前为止,我们实现的RAG练习中,答案都是全部来源于检索到的文本内容。而检索过程可能在某些情况下是不需要的。
如何优化这个过程,让我们的RAG程序在必要时才去检索,不必要时,直接使用大模型原有数据来回答呢?本文我们一起来学习下。
本文我们将使用 LangChain 的 Agents 模块来将 Retriever 当作工具,让大模型在有必要时才去使用它。
0. 实现 Retriever
首先我们得现有一个Retrivever,才能在有需要时能够进行查询。搭建Retriever的过程就不展开了,前面我们已经做了非常多的练习,具体可以参考这篇文章:【AI大模型应用开发】【LangChain系列】实战案例4:再战RAG问答,提取在线网页数据,并返回生成答案的来源。
python
python代码解读复制代码import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
1. 实现 Retriever Tool
通过 LangChain 自带的 create_retriever_tool 来将 Retriever 封装成一个可供 Agents 模块调用的 Tool。
create_retriever_tool 在使用过程中,最重要的是第三个参数,这是你这个工具的描述,这个描述相当于一个Prompt,将决定大模型是否会调用这个工具。
python
python代码解读复制代码from langchain.tools.retriever import create_retriever_tool
tool = create_retriever_tool(
retriever,
"search_agents_answer",
"Searches and returns context from LLM Powered Autonomous Agents. Answering questions about the agents.",
)
tools = [tool]关于LangChain中 Agents 模块如何定义Tool,详细教程可参考: 【AI大模型应用开发】【LangChain系列】5. 实战LangChain的智能体Agents模块
2. Prompt模板和模型加载
python
python代码解读复制代码from langchain import hub
prompt = hub.pull("hwchase17/openai-tools-agent")
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0)这块没有特别注意的,就是将需要的元素都创建好,供后面创建 Agent 使用。
看一眼加载的Prompt模板内容:
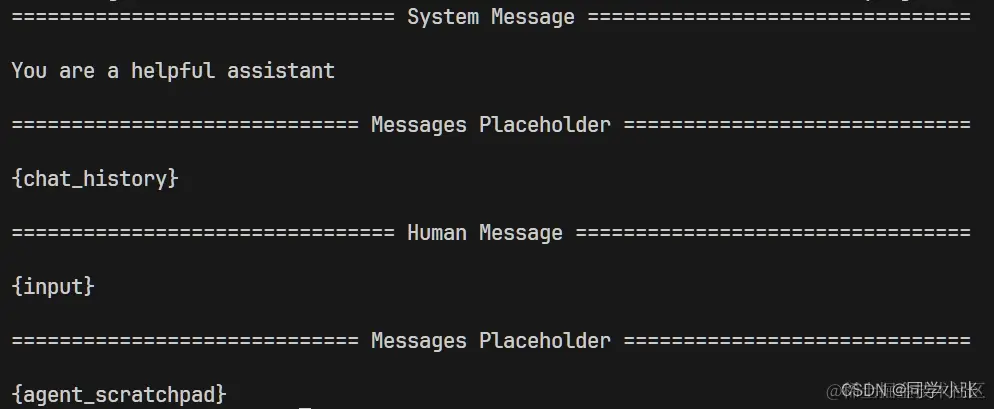
- 小Tips:打印Prompt模板内容,可以使用
prompt.pretty_print()函数,将打印成上图中比较美观的样子。
3. 创建 Agent 和 Agent 执行器
准备好 llm、tools、prompt之后,创建Agent 和 AgentExecutor
python
python代码解读复制代码from langchain.agents import AgentExecutor, create_openai_tools_agent
agent = create_openai_tools_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)其中 create_openai_tools_agent,是 LangChain 对于使用 OpenAI 工具的Agent的封装:
python
python代码解读复制代码def create_openai_tools_agent(
llm: BaseLanguageModel, tools: Sequence[BaseTool], prompt: ChatPromptTemplate
) -> Runnable:
"""Create an agent that uses OpenAI tools.
Args:
llm: LLM to use as the agent.
tools: Tools this agent has access to.
prompt: The prompt to use. See Prompt section below for more on the expected
input variables.其实现原理,就是将 tools 首先转换成OpenAI格式的工具描述,然后与 OpenAI 大模型进行绑定(源码中的这一句:llm_with_tools = llm.bind(tools=[convert_to_openai_tool(tool) for tool in tools]))。这是 Function Calling 部分的知识,不了解的可以补一下:【AI大模型应用开发】2.1 Function Calling连接外部世界 - 入门与实战(1)
4. 完整代码及运行结果
4.1 运行代码
调用 invoke 接口即可运行。
python
python代码解读复制代码result = agent_executor.invoke({"input": "hi, 我是【同学小张】"})
print(result["output"])
result = agent_executor.invoke(
{
"input": "What is Task Decomposition?"
}
)
print("output2: ", result["output"])4.2 完整代码
python
python代码解读复制代码import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
from langchain.tools.retriever import create_retriever_tool
tool = create_retriever_tool(
retriever,
"search_agents_answer",
"Searches and returns context from LLM Powered Autonomous Agents. Answering questions about the agents.",
)
tools = [tool]
from langchain import hub
prompt = hub.pull("hwchase17/openai-tools-agent")
prompt.pretty_print()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0)
from langchain.agents import AgentExecutor, create_openai_tools_agent
agent = create_openai_tools_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
result = agent_executor.invoke({"input": "hi, 我是【同学小张】"})
print(result["output"])
result = agent_executor.invoke(
{
"input": "What is Task Decomposition?"
}
)
print("output2: ", result["output"])4.2 运行结果与解释
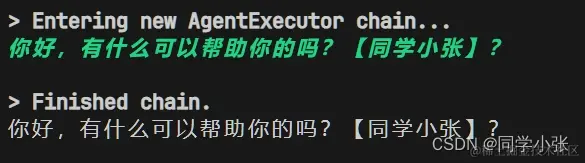
第一个问题,简单打个招呼,这时候不需要也不能去查文本,应该直接使用大模型自身的能力来回复。
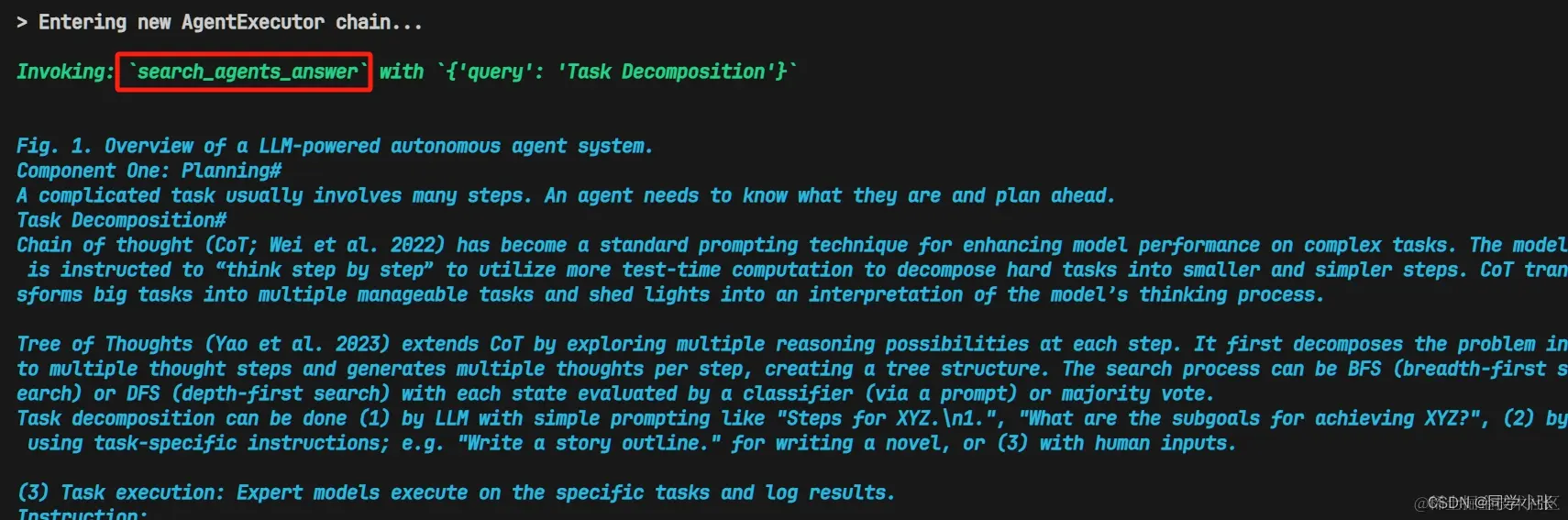
第二个问题,涉及 Agents 相关知识,需要调用 Retriever 去查询相关资料,利用资料去回复。

本文参考教程:python.langchain.com/docs/use_ca...
如果觉得本文对你有帮助,麻烦点个赞和关注呗 ~~~最后如果您也对AI大模型感兴趣想学习却苦于没有方向👀
小编给自己收藏整理好的学习资料分享出来给大家💖
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码关注免费领取【保证100%免费】🆓

一、全套 AGI 大模型学习路线
AI 大模型时代的精彩学习之旅:从根基铸就到前沿探索,牢牢掌握人工智能核心技能!

二、640 套 AI 大模型报告合集
此套涵盖 640 份报告的精彩合集,全面涉及 AI 大模型的理论研究、技术实现以及行业应用等诸多方面。无论你是科研工作者、工程师,还是对 AI 大模型满怀热忱的爱好者,这套报告合集都将为你呈上宝贵的信息与深刻的启示。

三、AI 大模型经典 PDF 书籍
伴随人工智能技术的迅猛发展,AI 大模型已然成为当今科技领域的一大热点。这些大型预训练模型,诸如 GPT-3、BERT、XLNet 等,凭借其强大的语言理解与生成能力,正在重塑我们对人工智能的认知。而以下这些 PDF 书籍无疑是极为出色的学习资源。


阶段 1:AI 大模型时代的基础认知
-
目标:深入洞悉 AI 大模型的基本概念、发展历程以及核心原理。
-
内容
:
- L1.1 人工智能概述与大模型起源探寻。
- L1.2 大模型与通用人工智能的紧密关联。
- L1.3 GPT 模型的辉煌发展历程。
- L1.4 模型工程解析。
- L1.4.1 知识大模型阐释。
- L1.4.2 生产大模型剖析。
- L1.4.3 模型工程方法论阐述。
- L1.4.4 模型工程实践展示。
- L1.5 GPT 应用案例分享。
阶段 2:AI 大模型 API 应用开发工程
-
目标:熟练掌握 AI 大模型 API 的运用与开发,以及相关编程技能。
-
内容
:
- L2.1 API 接口详解。
- L2.1.1 OpenAI API 接口解读。
- L2.1.2 Python 接口接入指南。
- L2.1.3 BOT 工具类框架介绍。
- L2.1.4 代码示例呈现。
- L2.2 Prompt 框架阐释。
- L2.2.1 何为 Prompt。
- L2.2.2 Prompt 框架应用现状分析。
- L2.2.3 基于 GPTAS 的 Prompt 框架剖析。
- L2.2.4 Prompt 框架与 Thought 的关联探讨。
- L2.2.5 Prompt 框架与提示词的深入解读。
- L2.3 流水线工程阐述。
- L2.3.1 流水线工程的概念解析。
- L2.3.2 流水线工程的优势展现。
- L2.3.3 流水线工程的应用场景探索。
- L2.4 总结与展望。
阶段 3:AI 大模型应用架构实践
-
目标:深刻理解 AI 大模型的应用架构,并能够实现私有化部署。
-
内容
:
- L3.1 Agent 模型框架解读。
- L3.1.1 Agent 模型框架的设计理念阐述。
- L3.1.2 Agent 模型框架的核心组件剖析。
- L3.1.3 Agent 模型框架的实现细节展示。
- L3.2 MetaGPT 详解。
- L3.2.1 MetaGPT 的基本概念阐释。
- L3.2.2 MetaGPT 的工作原理剖析。
- L3.2.3 MetaGPT 的应用场景探讨。
- L3.3 ChatGLM 解析。
- L3.3.1 ChatGLM 的特色呈现。
- L3.3.2 ChatGLM 的开发环境介绍。
- L3.3.3 ChatGLM 的使用示例展示。
- L3.4 LLAMA 阐释。
- L3.4.1 LLAMA 的特点剖析。
- L3.4.2 LLAMA 的开发环境说明。
- L3.4.3 LLAMA 的使用示例呈现。
- L3.5 其他大模型介绍。
阶段 4:AI 大模型私有化部署
-
目标:熟练掌握多种 AI 大模型的私有化部署,包括多模态和特定领域模型。
-
内容
:
- L4.1 模型私有化部署概述。
- L4.2 模型私有化部署的关键技术解析。
- L4.3 模型私有化部署的实施步骤详解。
- L4.4 模型私有化部署的应用场景探讨。
学习计划:
- 阶段 1:历时 1 至 2 个月,构建起 AI 大模型的基础知识体系。
- 阶段 2:花费 2 至 3 个月,专注于提升 API 应用开发能力。
- 阶段 3:用 3 至 4 个月,深入实践 AI 大模型的应用架构与私有化部署。
- 阶段 4 :历经 4 至 5 个月,专注于高级模型的应用与部署。
