0.概述
论文地址:https://arxiv.org/abs/2404.06571
本研究探讨了制造系统集成商如何构建知识图谱来识别新的制造合作伙伴,并通过供应链多样化来降低风险。它提出了一种使用制造服务知识图谱(MSKG)提高 ChatGPT 响应准确性和完整性的方法。该研究整合了来自北美小型制造商数字足迹的结构化和非结构化数据,以开发制造服务知识图谱。知识图谱和学习图谱嵌入向量用于解决数字供应链网络中的复杂查询,以提高可靠性和可解释性。这种方法可扩展地形成全球制造服务知识网络图,将跨行业、跨地域和跨业务领域的知识图谱整合在一起。已发布的数据集包含 13000 多个制造商网络链接、制造服务、认证和位置实体类型。
1. 介绍
随着数字化程度的不断提高,制造业正越来越多地采用数据驱动的方法。特别是,制造系统集成商正在寻找有效的方法来识别新的制造合作伙伴,并通过供应链多样化来降低风险。制造服务知识图谱(MSKG)是为满足这些需求而开发的工具,可为复杂查询提供可靠性和可解释性。
1.1 制造服务知识图谱 (MSKG) 概览
MSKG 是通过整合北美小型制造商数字足迹中的结构化和非结构化数据而建立的。该知识图谱包括制造商的网络链接、制造服务、认证和地点等数据,并将这些数据联系在一起,为供应链优化和风险管理提供支持。

|---------------------------------------|
| 图 1. ChatGPT 与 MSKG 增强型 ChatGPT 响应的比较 |
1.2 研究的背景和目标
本研究旨在利用 MSKG 提高 ChatGPT 响应的准确性和完整性。具体来说,它旨在解决制造系统集成商面临的以下挑战
- 确定新的生产合作伙伴。
- 供应链多样化
- 降低风险
为了应对这些挑战,我们使用了知识图谱和学习图谱嵌入向量。这允许在数字供应链网络中进行复杂查询,并提高了可靠性和可解释性。
1.2 方法的可扩展性
本研究提出的方法具有可扩展性,可形成一个全球制造服务知识网络图,将多个行业、地理边界和业务领域的知识图谱整合在一起。这种可扩展性使其适用于其他地区和行业,并有望作为更广泛的数字生态系统的一部分发挥作用。
2. 相关研究
知识图谱(KG)用于连接医学、社交网络和化学等领域的概念;知识图谱嵌入模型将实体和关系转化为低维向量,并保留知识图谱结构。这些模型适用于聚类和链接预测等机器学习任务;Mohamed 等人探索了知识图谱嵌入在药物目标预测和聚类中的应用,Wang 等人则将其用于药物推荐。
虽然从结构化数据中构建 KG 的方法已经成熟,但由于提取不可靠和缺乏数据集,从文本和多媒体等非结构化数据中构建 KG 仍然具有挑战性。最近的尝试包括 COVID-KG(来自科学文献)和来自中国汽车行业文本的行业 KG。由于噪音和旧的 HTML 结构,从网站中提取准确信息非常困难;自然语言处理(NLP)和主题标签生成(TLP)技术,如 BERT 和 GPT-4 对于处理大型非结构化文本非常重要。
工业领域的知识映射对于知识、数据和关系的可视化非常重要;LangChain 和 LlamaIndex 等方法使用 LLM 进行数据处理,并辅以工业本体基金会和工业 4.0制造本体,并辅以本体驱动的方法。这些构成了制造服务发现和设备查询等服务的基础,以支持工业问题的解决和决策。此外,Siddharth 等人还致力于从专利中提取工程知识。然而,关于实时制造数据的映射、整合和分析还缺乏文献。造成这一空白的原因是,当前基于 LLM 的方法在行业知识映射以实现不断发展的制造数据集成方面存在局限性。
问答(QA)系统结合了信息检索和基于知识的方法来提供准确的答案。基于知识的问答系统使用知识库检索答案,而图嵌入则将知识库数据转换为向量,以帮助人工智能和神经网络进行推理。基于知识的问答提供了结构化的上下文,从而提高了 LLM 生成和解释更准确、更符合上下文的答案的能力。
最近的一些研究强调了如何将 KG 和 LLM 结合起来以改进质量保证系统;Daull 等人探讨了 KG 如何帮助改进 LLM 和减少错误;Truong 和 Coleen 强调了结合 KG 以生成准确的答案;Linyao 等人探讨了如何将 KG 和 LLM 结合起来以改进质量保证系统。这些发展表明,改进质量保证系统是大有可为的。虽然这些发展显示了改进质量保证系统和准确性的前景,但应用这些方法的研究还很有限,尤其是在制造业的供应采购方面。将这些集成方法专门用于制造业,可以大大改善服务发现和供应链流程优化。
3.算法架构
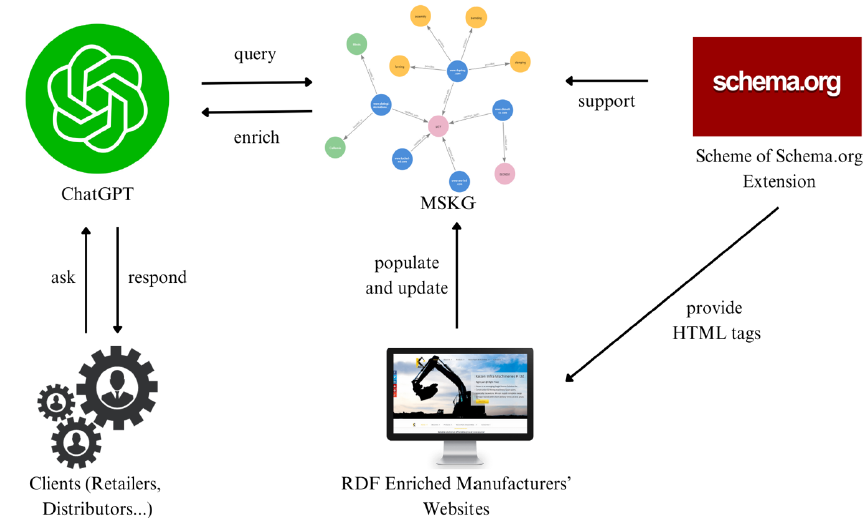
本节描述了制造服务知识图谱(MSKG)和 ChatGPT 的集成架构,旨在增强制造服务发现功能。制造业客户与 ChatGPT 之间的交互是通过 QA 进行的。在收到客户输入的问题后,应用程序会将问题转发给 OpenAI GPT-4 端点,并请求将其转换为可在图数据库中使用的查询语句。中检索相关的制造能力,并用查询语句做出响应。检索到的数据有助于建立一个全面的答案,以解决客户的初始问题。
图 2 显示了使用 MSKG 增强 ChatGPT 的架构。
|---------------------------|
| 图 2:用 MSKG 丰富 ChatGPT 的架构 |
此外,MSKG 还由众多制造商网站进行近乎实时的更新。在制造领域采用 Schema.org 词汇扩展后,制造商可以使用 HTML 标签将特定的制造服务标签附加到其网站上。当制造商在其网站上添加这些标签时,这些标签就会与 MSKG 本体相关联,从而使查询搜索结果更及时、更准确。
4. 工作流程
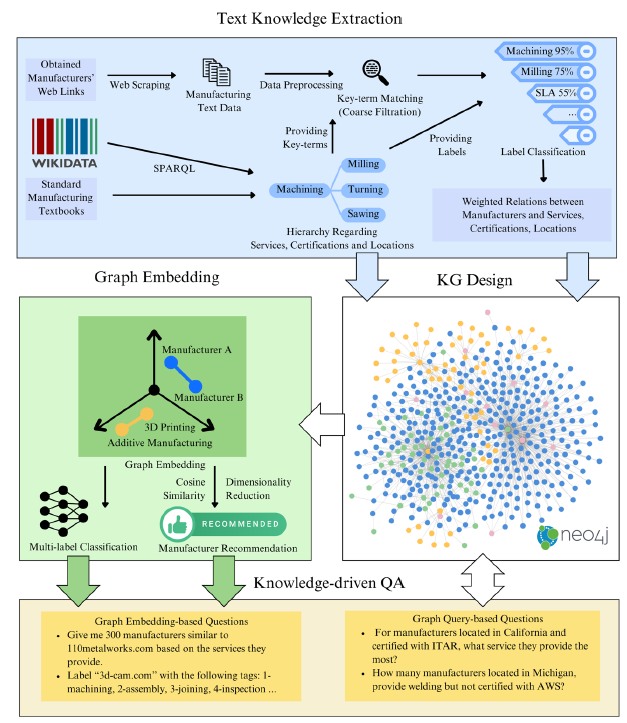
本节介绍了在 ChatGPT 中建立 MSKG 和加强 QA 的整体程序。该流程由四个主要部分组成。文本知识提取、KG 设计、图表嵌入和知识驱动的质量保证。
图 3 显示了通过根据互联网信息设计的知识图谱(KG)来增强问答(QA)系统的工作流程。
|---------------------------------------|
| 图 3:从互联网信息到知识图谱 (KG),旨在增强问题解答 (QA) 系统 |
- 文本知识提取:从制造商网站和其他数据源中进行信息提取,以获得要导入 MSKG 的数据;在批量导入后,以从 Wikidata 中提取的实体为指导构建 MSKG;从 MSKG 中进行学习。根据图嵌入向量,进行降维和多标签分类。
- KG 设计:包括四种节点标签和四种关系标签的 KG。给出了节点和关系类型的示例。
- 图嵌入:使用图嵌入技术(Node2Vec 和 GraphSAGE)从 MSKG 子图中学习嵌入向量。嵌入向量用于下游的制造商推荐和多标签分类任务。
- 知识驱动的质量保证:建立基于 MSKG 的质量保证系统,以解决制造服务发现方面的复杂问题;通过 P@N 和 MRR 指标对质量保证系统进行评估,以便向制造商提出建议。
5. 数据整合与丰富
该流程旨在对收集到的数据进行标准化和整合,以建立知识图谱。这一过程包括以下步骤:
-
数据标准化:
- 将从不同来源收集的数据转换成一致的格式。这可确保数据的一致性。数据标准化包括统一数据格式、转换单位和整合数据字段。例如,统一日期格式和转换数字数据单位。
-
实体匹配:
- 它可以匹配和合并同一实体上不同来源的数据。这样可以消除重复数据,提高数据完整性。实体匹配使用名称相似性、地址匹配性和产品 ID 共通性等标准进行。例如,将从不同来源收集的同一制造商的数据合并为单一实体。
-
丰富生活:
- 从外部数据源获取更多信息来丰富数据。这就扩展了知识图谱节点和边中包含的信息。丰富数据可增加公司财务信息、行业报告、专利数据等。这使得知识图谱更加详细和全面。
表 1 显示了提取的实体类型。
|-------------|
| 表 1 提取的实体类型 |
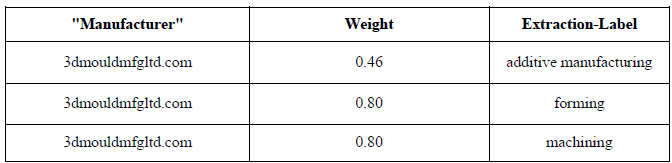
 表 2 显示了服务提取的样本。
表 2 显示了服务提取的样本。
|------------|
| 表 2:服务提取样本 |
6. 知识图谱构建
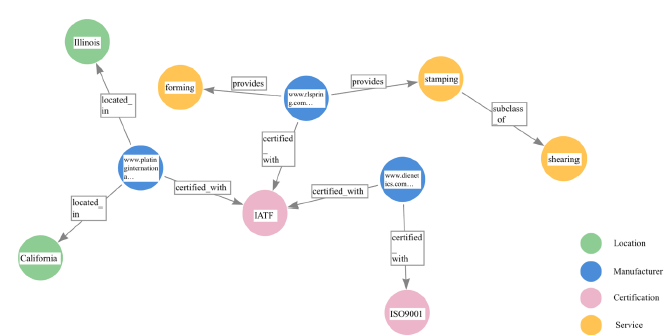
综合数据用于构建知识图谱。知识图谱由节点(实体)和边(关系)组成,包含制造商、产品、服务、认证和地理位置等信息。
-
生成节点:
- 制造商、产品、服务、认证和地理位置等实体作为节点生成。这样可以单独识别每个实体,并明确它们之间的相互关系。节点生成根据数据属性识别实体,并将每个实体定义为单独的节点。
-
边缘生成:
- 实体之间的关系用边来表示。例如,制造商与其提供的服务之间的关系。边的生成基于实体间的交互和依赖关系来定义关系。例如,如果制造商 A 提供服务 X,那么 A 和 X 之间就形成了一条边。
图 4 显示了 MSKG 的总体结构。
|------------------|
| 图 4. 典型 MSKG 的结构 |
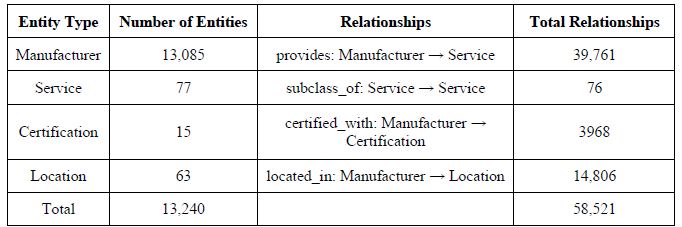
表3 显示了 KG 实体和关系的总数。
|----------------|
| 表 3:KG 实体和关系总数 |
7. 嵌入式图形
图嵌入模块可学习节点之间的关系,并将节点嵌入高维向量空间。这有助于计算节点的相似性,并提高对复杂查询的响应精度。
-
使用 node2vec:
- 基于 Grover 和 Leskovec(2016 年)的方法,node2vec 可捕捉随机行走中节点的邻近信息,并生成嵌入向量。这样就能高效地学习节点特征。
-
使用图卷积网络(GCN):
- 基于 Kipf 和 Welling(2017 年)的方法,GCN 通过整合节点特征及其邻近节点信息来提高预测精度。GCN 是一种针对图结构数据的深度学习方法,它将节点属性和邻近节点信息结合在一起。这提高了节点分类和链接预测的准确性。
8.知识驱动的质量保证
8.1 背景
要建立一个发现制造服务的质量保证系统,就必须解决制造业复杂多变的问题。主要挑战是将详细的行业特定数据整合到 KG 中,并不断更新以反映新的发展和市场趋势。此外,还需要对制造供应链中的复杂关系进行精确建模。制造业对准确性和可靠性的要求很高,再加上获得专有数据的途径有限,因此建立有效的质量保证系统具有挑战性。
8.2评估方法
评估质量保证系统有多种方法,包括平均互易等级 (MRR)、N 倍精度 (P@N)、召回率 (Recall)、F1 分数和人工评估。P@N 衡量推荐系统返回的前 N 个回复中正确回复的比例。精度在 N (P@N) 的指标(N=10,100,300)用于评估制造商推荐器的性能和评价系统的能力。P@N 表示为:推荐器系统返回的前 N 个回复中正确回复的百分比;制造商返回的前 N 个回复中正确回复的百分比;以及制造商返回的前 N 个回复中正确回复的百分比:
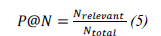
其中,NrelevantN_{relevant}Nrelevant是前 N 个结果中与目标制造商相关的服务数量,NtopN_{top}Ntop是前 N 个结果所提供的服务数量。MRR 表示为
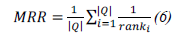
其中,rank_i 是第 i 个查询的第一个相关制造商的排名。
之所以选择这些指标,是因为它们要求在发现制造商时提供准确且排名靠前的答案;P@N 评估的是顶级推荐的准确性,而 MRR 评估的是系统首先识别最相关制造商的有效性。
8.3 建立质量保证系统
本研究采用索引方法对从制造商网站检索到的文本进行分类和组织,该方法基于 KG 构建过程中使用的一些技术。主要贡献如下
-
我们提出了一种从小型制造商的独立网站中提取和组织特定领域文本的机制。这将使他们能够与特定技术领域的文本进行自然交互。
-
将不断发展的 KG 集成到 LLM 中提供了一种新的解决方案,可改变制造能力识别和制造商建议的格局。
-
本文介绍了一种自下而上的本体构建与先进机器学习模型的新整合方法,可从结构化和非结构化数据源中高效构建 MSKG。这种方法简化了各种数据的整合,提高了KG的准确性和相关性。
-
这是一个基于图形的高级质量保证系统,旨在解决与数字供应链网络相关的复杂问题,它结合了 KG 和图形嵌入技术,可提供深入分析和定制的、高度准确的、基于相似性的建议。
8.4 系统性能
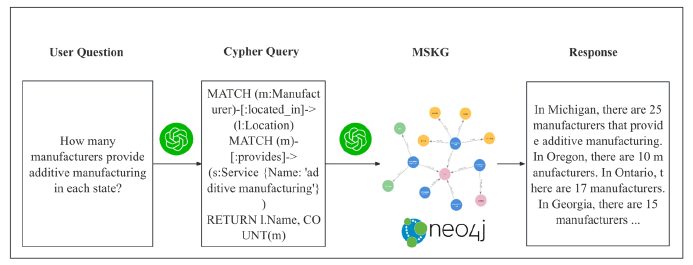
图 5 显示了结合 MSKG 和 ChatGPT 解决一个简单问题的示例。
|---------------------------------|
| 图 5. 结合使用 MSKG 和 ChatGPT 解决易级问题 |
图 6 举例说明了如何将 MSKG 和 ChatGPT 结合起来解决疑难问题。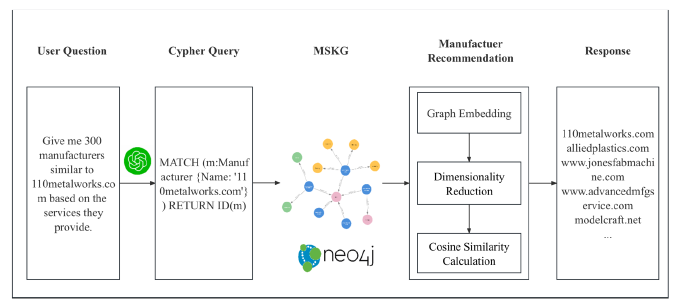
|------------------------------|
| 图 6:结合 MSKG 和 ChatGPT 解决难级问题 |
9.总结
9.1 验证文本提取结果
文本提取结果表明,由于制造商网站主页上缺乏文本信息,负面类别的数量可能高于正面类别的数量。 计算 ROC 曲线和 PR 曲线以显示模型的可靠性。性能。其中,认证提取模型的 AUC-ROC 分数最高,而位置提取模型的性能最低。
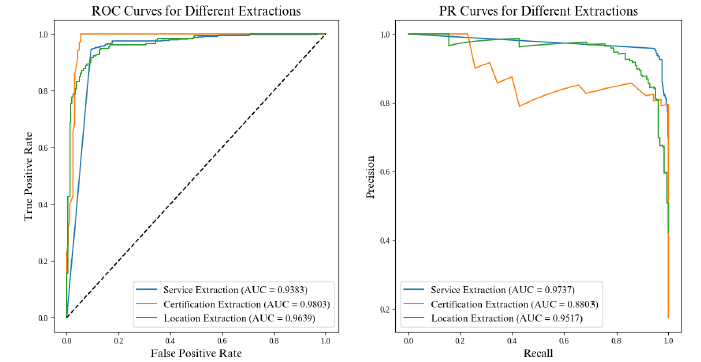
|------------------|
| 图 7:ROC 和 PR 曲线。 |
针对每种数据类型,对特定数据提取模型的准确性、可重复性和计算 F1 分数的临界值进行了优化。这种方法提高了数据提取的整体性能,增加了用于建立 MSKG 的数据的可靠性。
9.2 图形嵌入及其下游任务成果
根据 Node2Vec 和 GraphSAGE 的嵌入结果得到 100 维向量空间,并使用 T-SNE 进行降维。图 8 和图 9 比较了具有服务相关属性的制造商的聚类性能;GraphSAGE 显示出比 Node2Vec 更好的聚类定义,能够更清晰地区分服务特征。
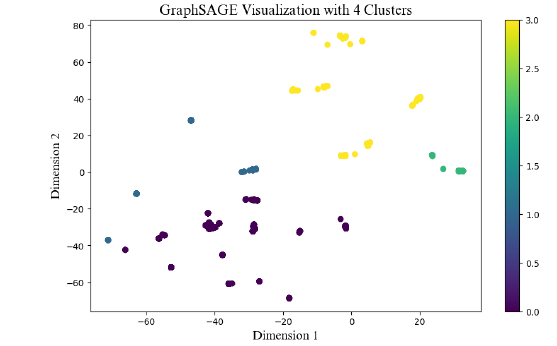
|---------------------------------------------|
| 图 8. 使用 GraphSAGE 对制造商的服务相关属性进行 T-SNE 可视化分析 |

|------------------------------------------|
| 图 9. 使用节点 2Vec 对制造商的服务相关属性进行 T-SNE 可视化分析 |
Node2Vec 生成的嵌入向量被用于多标签分类任务。使用 MLP 模型对这些向量进行了训练和评估。训练准确率为 98.90%,而多标签预测准确率、F1 分数、召回率和精确率分别为 98.72%、94.62%、99.93% 和 89.85%。
9.3 评估基于 MSKG 的质量保证
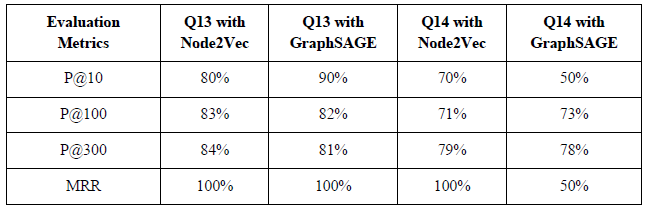
附录详细分析了与制造服务发现相关的问题及其相应的 MSKG 回答与 GPT-4 回答的比较。对于简单的问题,GPT-4 或 MSKG 都可以回答,但对于 Q13 和 Q14 等更复杂的问题,MSKG 和 GPT-4 的整合至关重要。
表 5 显示了制造商推荐的评估结果,GraphSAGE 在第 13 季度略微领先于 Node2Vec,而 Node2Vec 则在第 14 季度更胜一筹。这表明,推荐功能的性能因制造商提供的服务数量而异。
|---------------|
| 表 5:制造商建议的额定值 |
9.4 结论
研究采用了自下而上的方法,从制造商网站收集原始数据,并构建了包含四种实体类型及其相应关系的知识图谱(KG)。然而,由于一些网站缺乏基本的搜索引擎优化代码,只能从 17,000 家公司中提取 13,000 多家公司的信息。未来的挑战包括扩展 MSKG 和整合其他相关数据。
该报告指出,未来的研究将扩展当前的框架,旨在通过法律硕士培训和培训前战略来提高对幼稚园背景的了解。
本文介绍了一个利用近乎实时更新的知识图谱(KG)来识别制造服务和加强制造商推荐的框架。构建的 MSKG 有四种实体类型和相应的关系类型,其中包括制造服务,共有 13,240 个实体和 58,521 个关系,包括来自北美一些制造商的文本内容。
知识图谱和训练有素的图嵌入向量支持 ChatGPT 中的质量保证,并利用人类自然语言和图查询语言之间的转换来回答制造业客户的问题。评估结果表明,所提出的基于 MSKG 的质量保证能有效解决制造业服务发现中的复杂问题。
MSKG 的规模可以扩大到包括与制造供应链和特定工业供应链相邻的领域。未来的框架将致力于整合 LLM 和知识模型,以实现更丰富的搜索。