现在网上的服务越来越多了,推荐系统在很多应用里都特别重要,像是在线购物或者电影推荐什么的。这些系统就是帮我们从一大堆信息里挑出我们可能感兴趣的,然后给我们推荐。它们会用各种信息来预测我们喜欢啥,比如我们以前的行为,还有我们和商品之间的互动。这些互动特别关键,因为它们能帮系统了解我们的喜好。

推荐系统会根据我们表现出来的喜好,显式的或者隐式的,来调整推荐的内容。显式的就是咱们直接告诉系统的,比如打分或者评论,但这种信息一般不多。所以,系统更多的是通过我们过去的行为,比如浏览历史和搜索习惯,来推测我们的兴趣。这招也被用在了别的信息检索领域,比如在线广告或者网络搜索。
接下来,咱们得搞清楚几个词,这样才好理解用户行为的各种类型:
-
行为对象就是用户互动的东西,比如商品或者服务。可能是一个商品,也可能是好几个。
-
行为类型 就是用户怎么和商品互动,比如搜索、点击、加购物车、购买、分享等等。这些互动方式也叫做"渠道",就是通过这些渠道,系统能收集到我们的反馈。
-
行为就是行为类型和行为对象加在一起,比如用户通过点击这个行为类型,和商品这个行为对象互动。
-
行为序列,或者说行为会话,就是一连串的用户行为。
下面这张图展示了用户行为建模大概是怎么一回事。
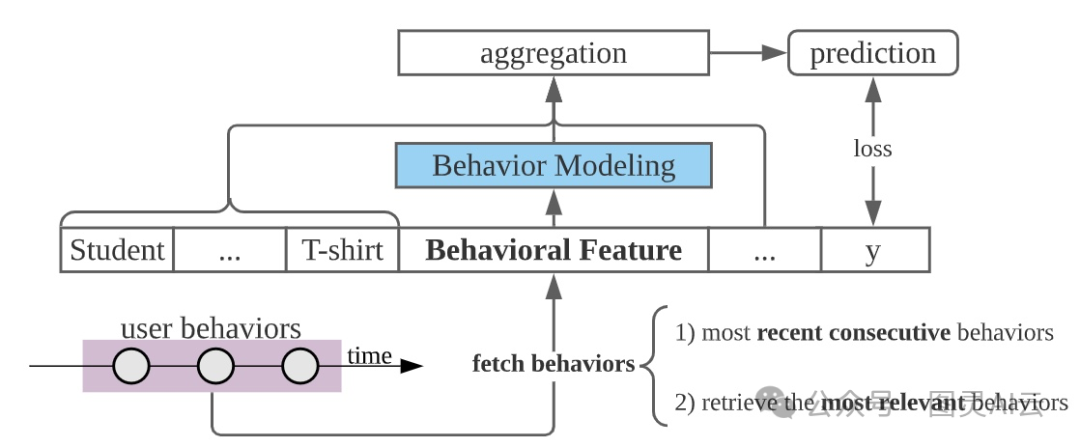
用户行为建模的一般框架
用户的行为里头藏着他们兴趣的线索。这篇文章要说的,就是怎么根据这些线索来分类用户的行为,然后看看每种类型的行为该怎么建模。
在用户行为建模的应用里,我们记录的数据通常是静态的,比如用户给电影打分的表格,或者是一连串的购买历史。老式的推荐系统会用一些方法,像是协同过滤或者基于内容的过滤,来建立模型。这些方法都是静态的,只能捕捉到用户的一般喜好。
但是,顺序推荐系统就不一样了,它会考虑用户和商品互动的顺序,把这种互动看作是一个动态的序列。所以,跟老方法不一样,顺序推荐系统会把行为信息看作是会变化的数据,就像时间序列那样。
在静态用户行为建模这一块,我们基本上是从一些固定不变的数据里头,像是用户和商品之间的互动,或者用户对广告的反应,来挖掘出一些潜在的用户特征。但是,这些方法都不考虑时间因素的。
浅层学习模型
那些传统的浅层学习模型,大多数都是基于一些统计假设,从一大堆复杂的数据里提取出一些简单、关键的信息。矩阵分解,尤其是协同过滤中用到的,就是这种方法的典型代表。它通过把用户反馈的矩阵拆解成几个潜在因子的矩阵来实现。虽然这招挺管用,但碰到新用户或者新商品的时候就有点尴尬了,因为缺乏历史数据。为了解决这个问题,一些更先进的分解技术就登场了,比如贝叶斯矩阵分解、跨域三元分解、分解机和上下文协同过滤。这些算法都挺简单直接的,也好实现,但处理复杂的用户行为数据时,它们的能耐就有限了。
深度学习模型
深度学习方法就不同了,它们用神经网络来从数据中提取深层次的信息。在用户行为建模这块,这些方法主要关注从用户的行为数据中学习到用户的潜在特征。比如基于受限玻尔兹曼机的序数RBM、深度信念网络、基于自动编码器的深度协同过滤、概率矩阵分解、边缘去噪自动编码器,以及前馈神经网络的神经协同过滤和神经分解机。比起浅层学习,这些方法更擅长处理复杂的特征交互,但它们在解释性和处理类别特征方面还有挑战。
重要的是,用户的行为和偏好是会随时间变化的,而传统的推荐系统,比如基于内容的推荐或者协同过滤,它们抓不住这种变化。它们通常假设用户和商品之间的所有互动都一样重要。但实际上,用户的下一步行动受到长期偏好和短期意图的影响,尤其是最近的一些互动。
与此相反,动态表示学习的方法,比如顺序推荐系统(SRSs),就考虑到了用户行为的这种动态性。SRSs通过分析用户和商品互动的顺序,来学习用户偏好和商品流行度随时间的变化。这样,就能更准确地把握用户的意图和商品的消费趋势,从而提供更准确、更灵活的推荐。
在现实世界里,用户的购物行为通常都不是孤立的,它们之间往往存在一些先后顺序的关系。
通过把用户和商品的互动看作是一个动态的序列,SRSs能够更灵活地捕捉到用户的当前和近期偏好。基于会话的推荐就是顺序推荐的一部分,它同时考虑了用户在单个会话中的短期兴趣和不同会话之间的行为模式的关系。
接下来,这篇文章会继续探讨动态用户行为建模。虽然一些非深度学习方法,比如频繁模式挖掘、基于项目的KNN、马尔可夫链、动态矩阵分解和张量分解,都曾经被用过,但基于深度学习的方法在鲁棒性和性能上都明显更胜一筹。所以,这篇文章会重点讨论最新的基于深度学习的方法。
咱们现在来聊聊顺序推荐系统(SRSs)里的两个典型任务,它们都是以用户的行为轨迹为基础的:
-
下一个项目推荐:这个任务里,咱们只关注单一的对象或项目,比如一个产品、一首歌、一部电影或者一个地点。
-
下一个购物篮推荐:这个任务更复杂一点,因为它关注的是一堆东西,比如你一次购物车里的多个商品。
虽然这两种任务的输入不一样,但目标都是一样的:预测用户接下来可能会对什么感兴趣。最常见的输出形式就是列出最可能吸引用户的前N个项目。这些项目的排名可以通过概率、绝对值或者相对排名来确定。假设ViV_i是第i个项目,下面的图就展示了这两种任务。
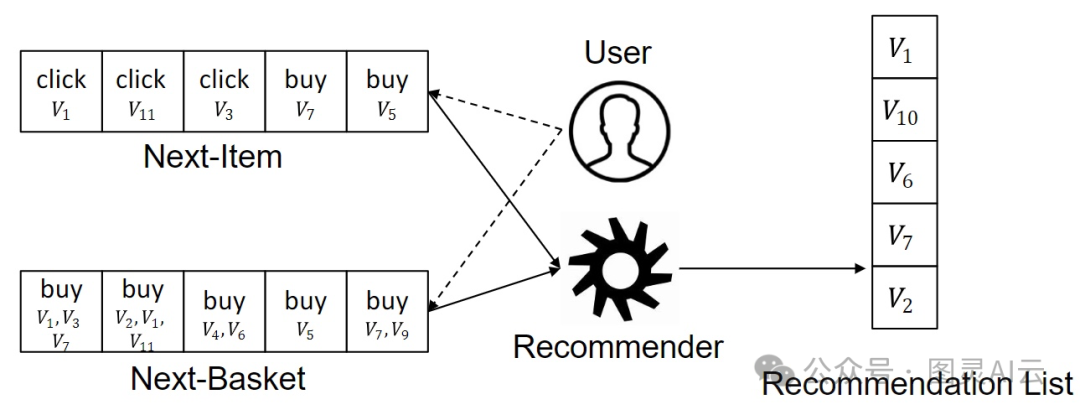
下一个项目和下一个购物篮推荐
我们把顺序推荐任务定义得更正式一点:给定用户的行为序列,生成一个个性化的项目列表。也就是说,我们要找出一个函数f,使得 (p1,p2,p3,...,pI)=f(a1,a2,a3,...,at,u)。这里,a1到at是用户的行为序列,u是用户,I是候选项目的数量,而pi是项目i在下一个时间点被用户u喜欢的概率。我们的目标就是学会这个函数f,来准确预测出这些概率。
在真实世界里,用户的行为多种多样,也很复杂。我们接下来会根据一般的分类法,探讨一下建模用户行为时面临的一些常见挑战:
-
长序列:长的行为序列可能包含了很多复杂的互动,这种复杂的顺序关系很难用老方法,比如马尔可夫链或者矩阵分解来捕捉。虽然深度学习模型,比如RNN,可以处理中等长度的序列,但这些模型通常假设序列中每个元素都严格按照顺序来。
-
灵活的顺序:在现实世界的数据中,并不是所有相邻的互动都有严格的顺序关系。比如你购物时,买"牛奶"和"黄油"的顺序并不重要,但如果你买了这俩,接下来买"面粉"的可能性就大了。像CNN这样的模型可以通过跳跃连接来避免严格的顺序假设。
-
嘈杂的项目 :很多行为序列里可能包含一些噪声或者不相关的互动,这会影响我们预测下一个项目的质量。比如在序列{ bacon, rose, eggs, bread}中,"rose"可能是个噪声项,而"eggs"和"bread"更可能是预测下一个项目"milk"的有效线索。注意力模型和基于检索的模型可以通过选择性地利用序列中的信息来解决这个问题。
-
异构关系:行为序列可能包含不同类型的关系,这些关系包含不同的信息,需要用不同的方式建模。这是一个相对较少被探索的问题,目前提出的解决方案是混合模型。
-
层次关系:用户-项目互动或者其子序列中可能存在层次依赖性。为此设计的模型,比如层次RNN、层次注意力网络、层次嵌入模型和基于会话的推荐器,可以帮助我们学习这些层次依赖性。
咱们从用户过去的行为里提取一定长度的序列,比如最近7天的记录。这些行为序列里头包括了商品的ID、一些上下文信息,还有商品的特征啥的。就像下面这张图展示的,这些行为特征一般都是按照时间顺序排列的。
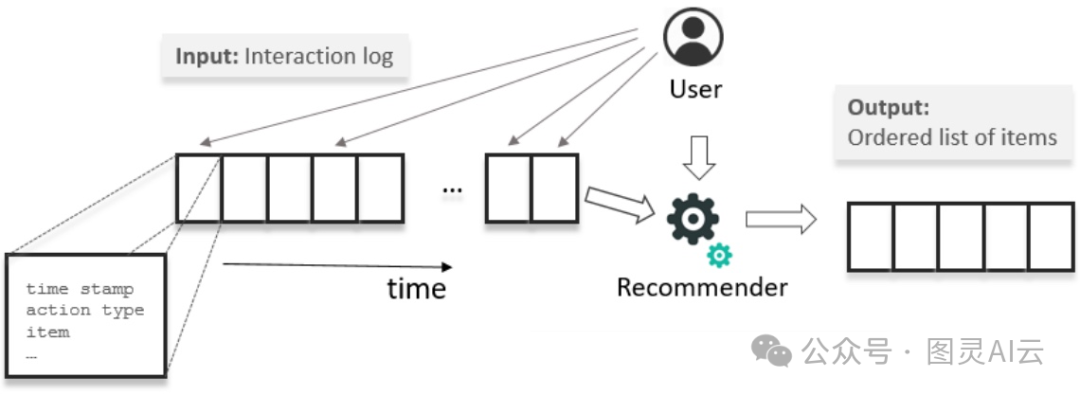
序列感知推荐器的高级概述
用户行为的隐式建模是个很广泛的话题,可以从各种不同的角度来理解。接下来,我们根据三种行为序列的类型来给现有的算法分分类。
在基于经验的行为序列里,用户可能通过不同的方式多次和同一个商品互动。比如,a1, a2, ..., an就是一串行为序列,其中每个行为ai由行为类型和行为对象组成。
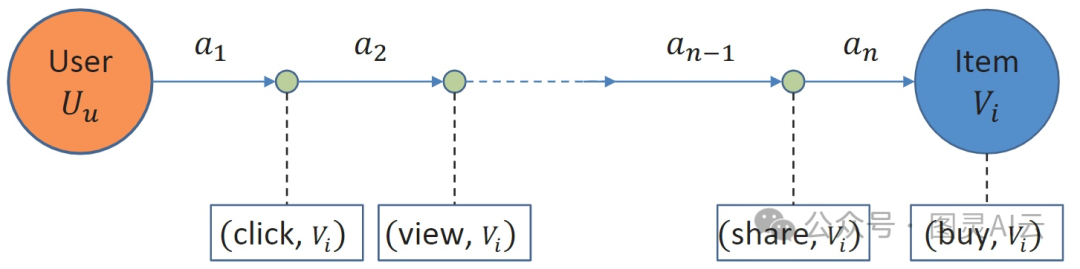
基于经验的行为序列("单个项目,多种行为类型")
举个例子,用户可能先搜索一个商品,然后在搜索结果里点进去看,接着详细查看商品信息。用户可能还会把商品分享给朋友,加到购物车里,最后购买。所有这些行为类型和它们的顺序可能都暗示了用户不同的意图。如果一个行为序列里只有点击和查看,那可能表示用户对商品的兴趣不大。如果用户在购买前分享商品,可能表示他很想要这个东西;如果是购买后分享,可能就表示他对商品很满意。在这种情况下,推荐系统(有时候也叫做多行为推荐模型)需要能识别出用户的潜在意图,并预测出用户对特定商品的下一个行为类型。
建模这种基于经验的行为序列的传统方法包括集体矩阵分解(CMF)、Google+用的那种行为分解、多反馈贝叶斯个性化排名(MF-BPR)、异构隐式反馈的贝叶斯个性化排名(BPRH)、逐元素交替最小二乘法(eALS)。这些方法都是利用来自不同渠道的用户反馈。
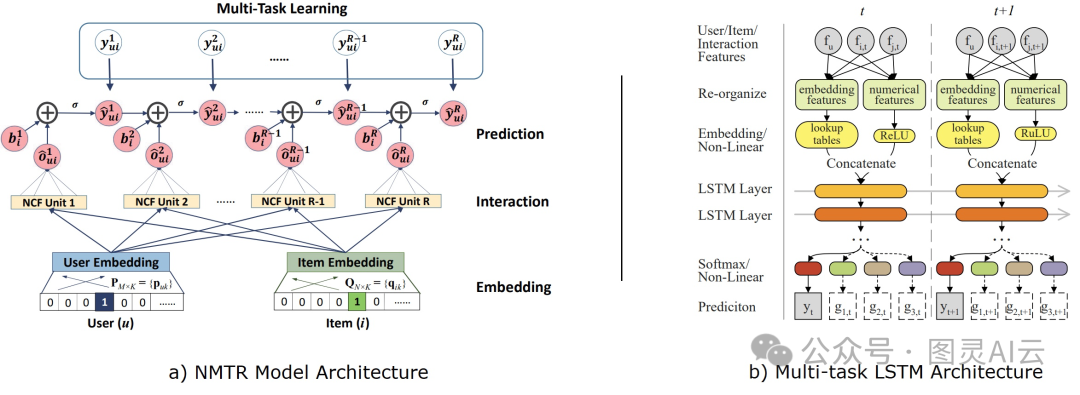
基于DL的多行为推荐系统
深度学习技术也被用来搞多行为推荐。比如,神经多任务推荐(NMTR)就是基于多任务学习(MTL)框架,把每种行为的优化当作一个任务来联合优化。NMTR结合了神经协同过滤(NCF)和MTL的优点,设计中用户和商品在多种行为类型中都有共享的嵌入。类似地,Xia等人提出了一个MTL模型,用LSTM明确建模用户的购买决策过程,通过预测用户在特定时间的阶段和决策。
基于交易的行为序列包括了用户互动的不同对象,但行为类型是相同的。在电子商务领域,最常见的行为类型就是购买商品了。所以,这种推荐模型的目标就是根据用户的历史交易记录,推荐用户可能要购买的下一个商品。这代表了传统的用户行为建模任务。
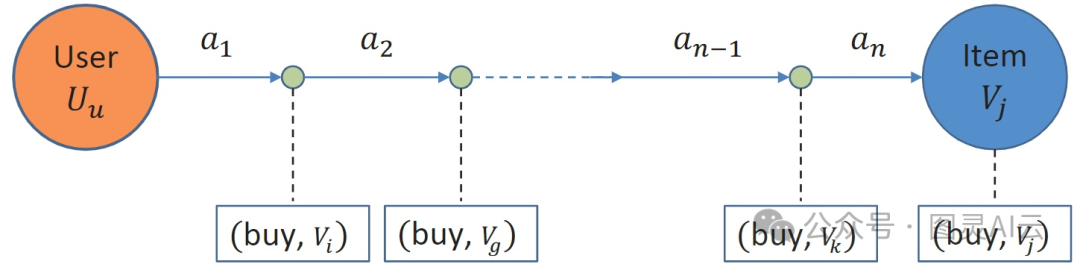
基于交易的行为序列("多个项目,单一行为类型")
在基于交易的行为建模这一块,我们的目标是理解商品之间的顺序关系和用户的喜好。这个领域里,深度学习已经被大量研究了。
-
基于RNN的模型:RNN这种模型天生就擅长抓住序列里的短期和长期联系。GRU4Rec就是最早用RNN处理用户会话中商品序列的模型之一。后来,很多研究都在这个模型的基础上做了改进,比如用数据增强技术,或者改进排名损失函数来提高效果。
-
基于CNN的模型:CNN模型在一定程度上能弥补RNN模型的一些不足,比如计算成本太高,或者处理不了太长的序列。3D-CNNs在电子商务领域就挺火的,它能预测用户接下来可能往购物车里添加的商品。Caser、CNN-Rec和NextItNet这些基于CNN的模型也用来识别商品之间的短期和长期依赖关系。
-
基于注意力的模型:这种模型特别擅长从用户的历史行为中找出他们可能感兴趣的商品。NARM、DIN、DIEN和ATEM都是这一类别的代表。自注意力模型在处理交易行为序列方面也引起了很多研究兴趣,比如SDM、SASRec、TiSASRec、SANSR、DSIN、BST和BERT4Rec。
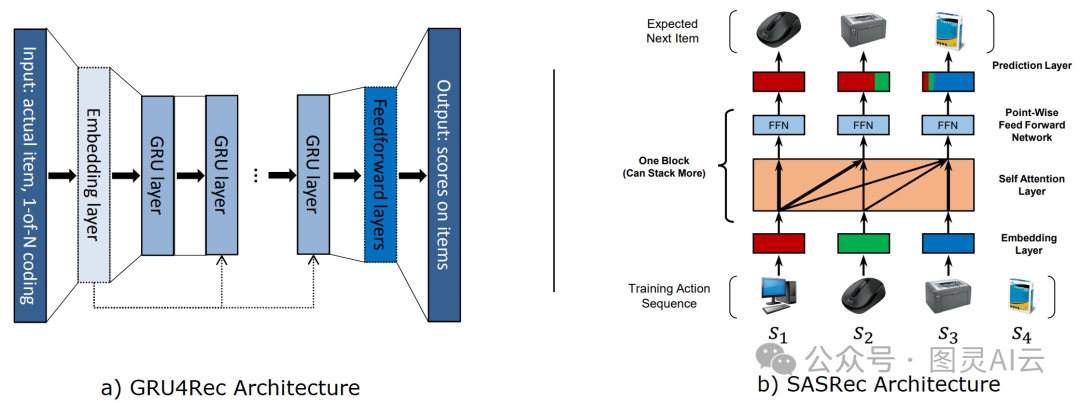
基于交易的行为序列的推荐系统
还有一种是基于交互的行为序列,这种模型结合了基于经验和基于交易的行为序列的特点,也就是说,它同时考虑了不同的行为对象和不同的行为类型。
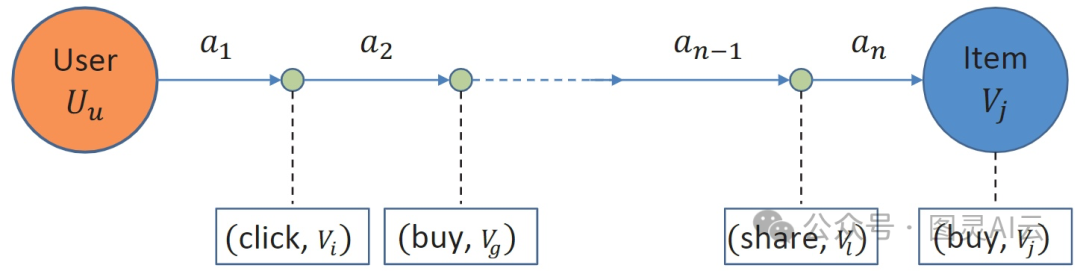
基于交互的行为序列("多个项目,多种行为类型")
这种模型更符合现实世界的情况。它需要学习不同用户对不同行为类型的兴趣,以及对不同商品的偏好。目标就是要预测出用户接下来可能会互动的商品。
基于交互序列的推荐系统得能够理解不同行为之间的那种先后关系,还有不同商品以及它们的行为本身之间的区别。这些方法特别注重清晰地表现出行为类型之间的细微差别。这很重要,比如在电子商务中,要是用户买了某个商品,那这可比他们只是点击了一下更能说明他们对这商品感兴趣。再比如,在商品评论里,好评和差评传达的是完全相反的意思。现有的研究可以根据怎样融合跨行为和行为内的关系来分类。
-
后期融合模型:后期融合模型分两步走,先分别建模跨行为和行为内的关系。这类模型的代表有神经多任务推荐(NMTR)、深度多面变换器(DMT)、多个场景排名模型的动物园(ZEUS)和图异构协同过滤(GHCF)。这些方法的缺点是,它们没有考虑到商品级别的跨行为关系。
-
早期融合模型:早期融合模型就不同了,它们一块儿学习跨行为和行为内的关系。这一类别的一些工作包括从微观行为视角的推荐框架(RIB)、多行为序列变换器推荐器(MB-STR)、并行信息共享网络(π\pi-Net)和图学习方法,比如多行为图卷积网络(MBGCN)和多行为图元网络(MB-GMN)。这些模型因为探索了商品级别的跨和内部级别依赖性,所以表现不错。但是,它们也因为模型的复杂性导致计算成本较高。
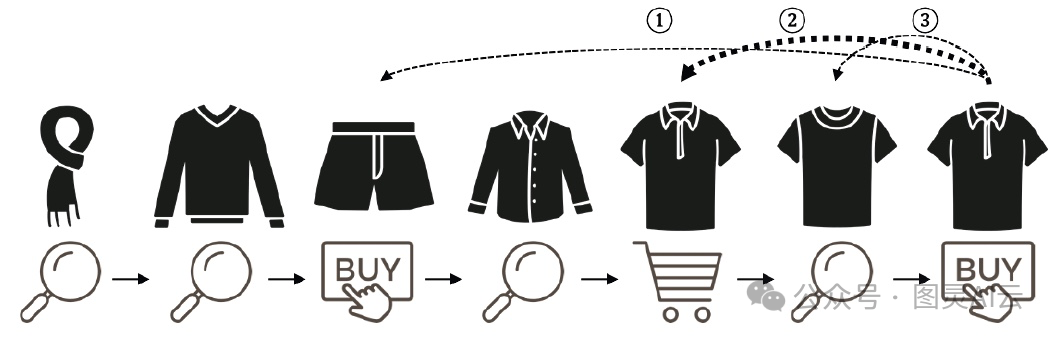
多项目多行为序列的一个例子,箭头指示最终购买决策的可能解释
建模基于交互的行为序列的一个独特挑战是要在同一个模型中预测多种行为类型。这种联合预测挺难的,因为不同行为的标签可能不在同一个空间里,甚至可能是互相排斥的。像GHCF、深度意图预测网络(DIPN)和领域感知GCN(DACGN)这样的方法为不同行为类型构建了单独的预测模块。但是,因为忽略了任务之间的关系,这种策略的表现可能就不是很好。而像多门控混合专家(MMoE)和渐进式层提取(PLE)这样的方法通过促进任务相关性和抑制任务冲突来解决这个问题。这类解决方案的例子包括DMT、ZEUS和MB-STR。
在线平台,比如电子商务网站,通常会积累大量的用户行为数据。所以,对于很多应用来说,挖掘用户历史中更久远的行为模式是有好处的。这些行为通常都很长(至少成千上万),所以建模过程在计算要求和延迟方面可能变得很昂贵。而且,长序列往往包含更多的噪声。为了解决这些挑战,提出的解决方案可以分为两类。
- 记忆增强模型:受NLP中记忆增强网络的启发,一些推荐模型使用外部记忆来存储用户表示,这些表示由定制的神经网络读取和更新。比如,神经记忆推荐网络(NMRN)提出了一个基于GAN的推荐器,使用外部记忆来捕获和存储流数据场景中的长期兴趣和短期动态兴趣。推荐系统与外部用户记忆网络(RUM)使用基于FIFO的记忆来明确存储用户历史,并应用注意力机制在矩阵上计算下一个项目推荐。这类模型的其他例子包括知识增强顺序推荐器(KSR)、层次周期记忆网络(HPMN)、记忆增强变换器网络(MATN)和用户兴趣中心(UIC)。
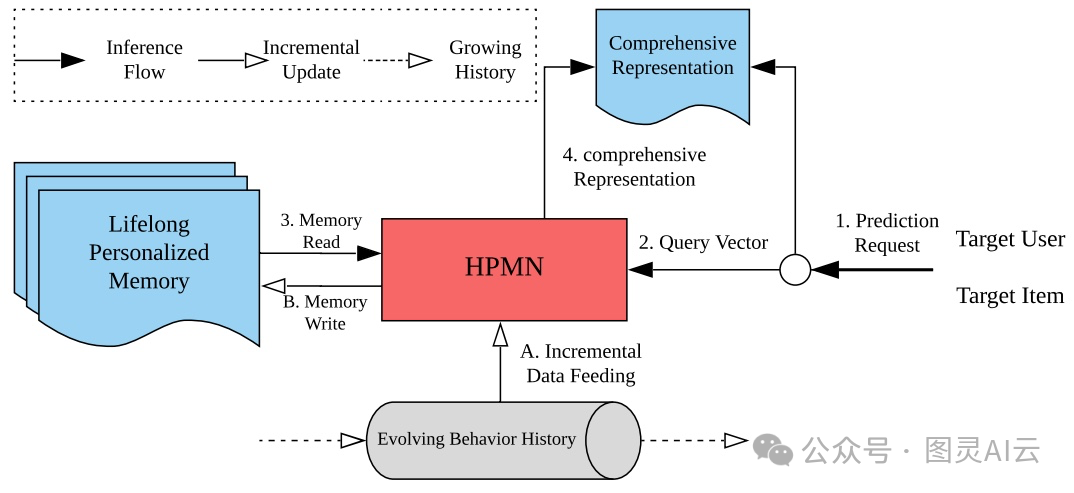
HPMN提出的终身顺序建模框架
基于检索的模型为推荐系统提供了一种替代记忆增强模型的方法,这种方法效率更高,也更容易扩展和部署。与传统的使用一长串连续的行为序列不同,基于检索的技术只关注最相关的那些行为。这样的方法可以减少处理长序列时的时间复杂性,还能减少长序列中噪声的影响。比如CTR预测的用户行为检索(UBR4CTR),它就用了搜索引擎技术来找出最相关的k个历史行为。它通过一个参数化的过程来生成基于目标的查询,然后用这个查询来执行检索。这个类别里的其他代表性模型还包括基于搜索的兴趣模型(SIM)、端到端目标注意力(ETA)、基于抽样的深度兴趣建模(SDIM)和对抗性过滤模型(ADFM)。
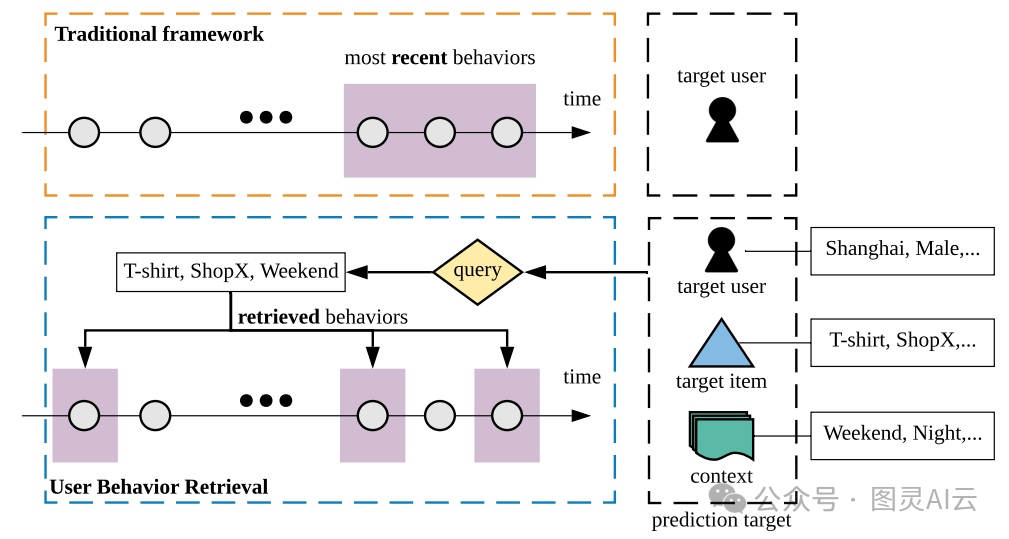
用户的行为序列通常包含了丰富的边信息,比如商品的类别、图片、描述、评论,还有行为的信息,比如停留时间,或者别的上下文信息。我们可以根据边信息的类型来分类建模方法。
-
时间信息:在SASRec和BERT4Rec这些方法里,时间信息用来排序行为记录,这会影响到序列建模之前的位置编码。TiSSA和TiSASRec就用商品对之间的时间间隔来做注意力权重的计算。还有一些方法会用停留时间来衡量行为对象的重要性。
-
商品属性:像FDSA和Trans2D这样的模型就提出了一种方法,可以同时建模商品ID和商品属性,比如类别、品牌、价格和描述文本,用于顺序推荐。
-
多模态信息:处理多模态边信息就复杂一些。比如p-RNN模型,它先从视频缩略图中提取图像特征,再从产品描述中提取文本特征,然后用NLP和CV的方法分别学习这些特征。Sequential Multi-modal Information Transfer Network(SEMI)也是类似的,它通过预训练的NLP和CV模型来获取视频和文本的表示。
像p-RNN这样的模型会把商品ID和边信息的学习向量直接连接起来。但是,如果简单地用加法或者连接来融合边信息,可能会因为边信息的异构性而破坏原始的商品ID表示。为了解决这个问题,NOVA-BERT和DIF-SR这样的方法就利用边信息来学习更好的注意力分布。此外,还提出了一些自监督学习框架来更有效地利用边信息。
推荐系统已经成为新闻、娱乐、电子商务等在线服务中不可或缺的一部分。这些推荐器帮助定制和适应用户的特定需求。为了实现这种个性化,深度学习模型从行为日志中学习用户意图和偏好。用户行为或用户-商品互动的建模过程也已经扩展到了CTR预测和目标广告等其他领域。这篇文章全面介绍了用户行为的分类法、建模策略、代表性工作、开放问题和最新进展。
