AI Agent(智能体)的记忆(Memory)被认为是一项必备的基础能力,它用来提取、存储会话中的重要信息并用于后续的检索与使用。可以把记忆简单地分成短期记忆与长期记忆两种,用来"记住"不同类型的信息:

短期记忆通常用来缓存一次会话过程的上下文与推理过程;而长期记忆则为AI 智能体提供了持久的重要信息存储与快速检索能力。
目前无论是LangChain/LlamaIndex这样的底层LLM框架,还是一些低代码平台,在短期记忆能力上都有相对完善的解决方案;但在长期记忆能力的实现上则相对不足,特别是更智能的个性化记忆能力。
本文介绍一种广受欢迎的AI记忆开源解决方案:Mem0(Mem0背后公司的一款基于Mem0的AI聊天应用获得了OpenAI的投资):
-
AI应用需要怎样的长期记忆
-
Mem0是怎么工作的
-
用LangGraph+Mem0实现个性化Agent体验
01
AI应用需要怎样的长期记忆
很多时候,我们希望AI应用能够提供一种更个性化的人工智能体验:随着时间的推移,AI能够记住每个使用者的一些独特信息,比如个人资料、专业细节、偏好、个人计划、习惯等,并能够在未来的交互中轻松地检索到这些信息,用来实现更针对性与个性化的AI体验。比如:
-
个性化的AI学习。记住不同学员的特点与习惯以提供针对性的教学过程。
-
个性化的AI客户服务。 根据客户的历史交互与信息提供更智能的服务体验。
-
个性化的AI个人助理。 根据个人偏好与习惯提供更有吸引力的推荐与帮助。
-
个性化的AI医疗咨询。根据咨询者的信息、病史、用药等做更精准的诊断。
注意这些信息需要在跨越多用户、多次会话、甚至多个AI应用时保留与检索。
除此之外,参考人类的记忆习惯,我们还希望AI的长期记忆能够:
-
智能记忆: 并非简单对话历史的存储,而是智能的理解、提取与记住重要信息与相关事实。
比如:从一次旅游规划对话中识别客户偏好的酒店类型、出行习惯。
-
自适应学习: 随着用户的不断使用与交互,能够持续提高个性化信息的丰富性与准确性。
比如:在多次对话中不断完善对客户信息与画像的了解。
-
动态更新: 根据新的交互信息动态更新记忆内容。
比如:在对话中识别出使用者的工作发生了变化,需要更新之前的记忆。
-
更准确的检索与响应: 优先考虑最近最相关的记忆信息,及时忘记过时信息,以提供更准确的个性化上下文。
比如:回忆最近一段时间的客户用餐爱好,并做针对性推荐。
以上这些能力要求,也正是Mem0已经具备的核心特性。
02
Mem0是怎么工作的?
简单地说,Mem0就是为基于LLM的AI应用而设计的独立记忆层 。通过它可以帮助AI应用实现跨应用持久、智能、自适应与动态的长期记忆与回忆能力,以用来实现真正的个性化AI体验。
Mem0的主要构成与工作方式用下图表示:

-
Mem0提供了简单的记忆管理API用来集成到你自己的AI应用
-
Mem0借助LLM与嵌入模型来智能的生成与更新记忆,并实现语义检索
-
Mem0的后端需借助向量数据库或者图数据库来组织、存储与检索记忆
以Mem0简单的增加记忆(add方法)为例,其核心处理过程大致为:
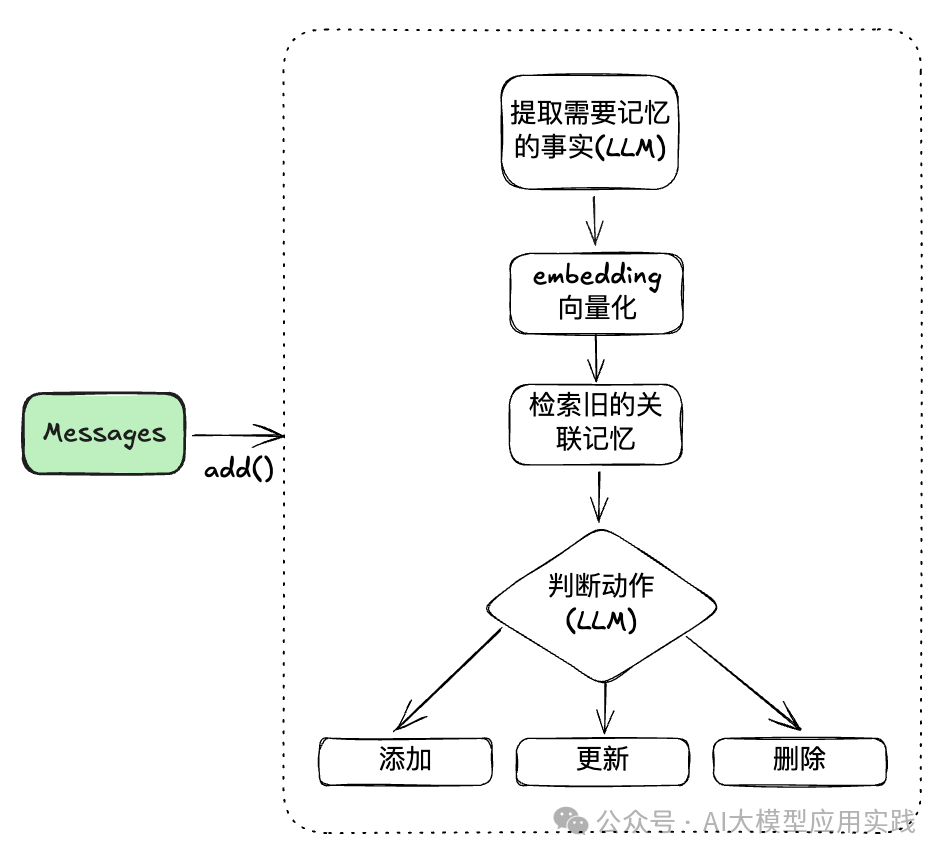
可以看到,Mem0借助了LLM来实现对记忆事实的提取,并能够根据新的交互信息来动态更新历史记忆,以保留最新的个性化记忆,并遗忘无用的记忆。由于借助了LLM,因此提示词就显得非常重要。如果你需要定制自己的记忆提取的提示词,可以在创建Memory对象时,设置custom_prompt参数。
03
用LangGraph+Mem0创建个性化体验的AI Agent
现在,让我们来创建一个具有个性化记忆能力的AI Agent,相对LangChain框架中的记忆组件,Mem0提供了更强大与智能的另外一种选项。
这里仍然用之前我们演示使用的智能体:**一个带有网络搜索功能的简单对话机器人。****但这次我们增加了长期记忆选项,用来实现跨多次会话、多用户甚至多Agent的个性化交互能力。**工作流程如下:
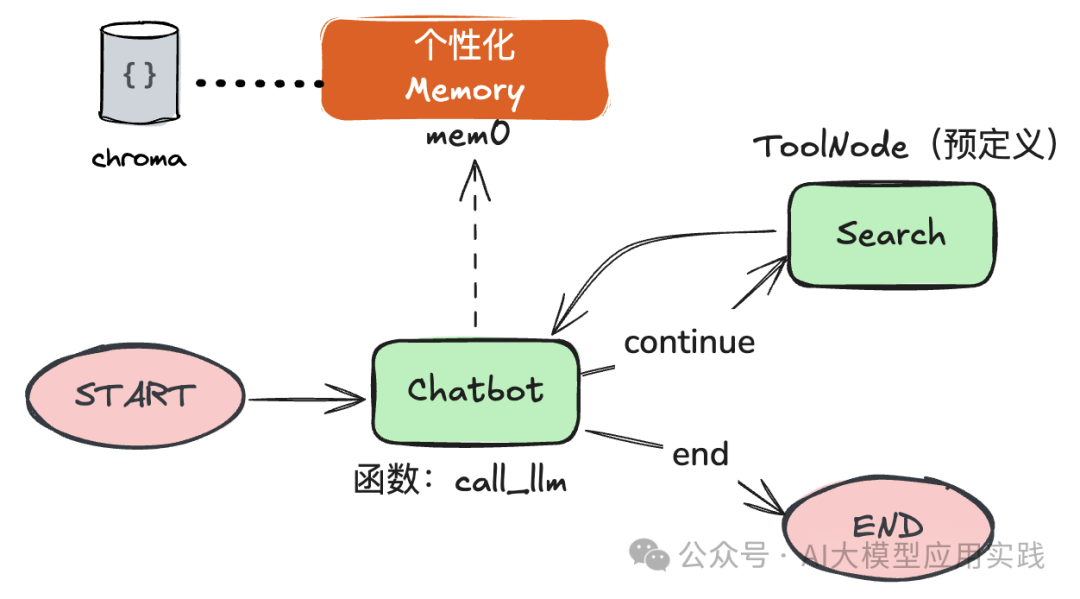
【创建记忆】
创建一个Mem0的Memory对象,向量数据库使用嵌入式的Chroma,LLM使用OpenAI的gpt-4o-mini模型(OpenAI的Key在环境变量配置):
from mem0 import Memory
from typing import Annotated, TypedDict, List
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langchain_community.tools.tavily_search import TavilySearchResults
from langgraph.prebuilt import ToolNode
#个性化长期记忆,采用chrona向量库存储
mem0 = Memory.from_config({
"version":"v1.1",
"llm": {
"provider": "openai",
"config": {
"model": "gpt-4o-mini"
} },
"vector_store": {
"provider": "chroma",
"config": {
"collection_name": "chat_memory",
"path": "./db",
}
}
})【创建LangGraph工作流与Agent】
定义LangGraph中的节点行为,最后创建工作流,并添加节点与边。这里针对Mem0的主要修改集中在chatbot这个节点方法中。简单解释如下:
-
为了区分不同用户的记忆,会在state中保留一个mem0_user_id。在添加记忆或者检索记忆时都需要携带这个user_id。(在实际应用中,这个id很可能是你的某个客户ID)
-
在chatbot回复之前,先根据输入消息内容检索关联的个性化记忆(search),并把检索到的记忆组装成System Message。(这是一个常见的优化点,即如何检索出更相关的记忆,可以参考RAG优化中的一些方法)
-
将System Message与用户消息一起作为上下文输入给LLM,从而在生成响应时,大模型能够根据个性化的记忆作出响应。
-
在本轮交互结束后,调用add接口将该用户的本次对话信息添加到记忆中。Mem0会自动识别和合并,以用于下次检索。
#定义LangGraph的State
class State(TypedDict):
messages: Annotated[List[HumanMessage | AIMessage], add_messages]
mem0_user_id: str调用搜索引擎的工具节点,利用ToolNode构建
tools = [TavilySearchResults(max_results=1)]
tool_node = ToolNode(tools)#定义chatbot节点
def chatbot(state: State):
messages = state["messages"]
user_id = state["mem0_user_id"]# 取出关联的个性化记忆,并组装成context,放在system message中 memories = mem0.search(messages[-1].content, user_id = user_id)["results"] context = "历史对话中的相关信息有:\n" for memory in memories: context += f"- {memory['memory']}\n" system_message = SystemMessage(content=f"你是一个乐于助人的客户支持助手。利用所提供的上下文来个性化你的回复,并会记住用户的偏好和过去的交互。\n{context}") # 组装消息,并调用LLM(注意绑定tools) full_messages = [system_message] + messages llm = ChatOpenAI(model="gpt-4o-mini") .bind_tools(tools) response = llm.invoke(full_messages) # 记住本地对话的信息 mem0.add(f"User: {messages[-1].content}\nAssistant: {response.content}", user_id=user_id) return {"messages": [response]}一个辅助方法:判断是否需要调用工具
def should_continue(state):
messages = state["messages"]
last_message = messages[-1]#根据大模型的反馈来决定是结束,还是调用工具 if not last_message.tool_calls: return "end" else: return "continue"定义一个graph
workflow = StateGraph(State)
workflow.add_node("llm", chatbot)
workflow.add_node("search", tool_node)
workflow.set_entry_point("llm")一个条件边,即从agent出来的两个分支及条件
workflow.add_conditional_edges(
"llm",
should_continue,
{
"continue": "search",
"end": END,
},
)action调用后返回agent
workflow.add_edge("search", "llm")
graph = workflow.compile()
【测试Agent的记忆能力】
准备如下的简单测试代码:
if __name__ == "__main__":
print("AI: 你好!有什么可以帮助你?")
mem0_user_id = "testuser" # You can generate or retrieve this based on your user management system
while True:
user_input = input("输入: ")
if user_input.lower() in ['quit', 'exit', 'bye']:
break
config = {"configurable": {"thread_id": mem0_user_id}}
state = {"messages": [HumanMessage(content=user_input)], "mem0_user_id": mem0_user_id}
response = graph.invoke(state,config)
print("AI: ",response["messages"][-1].content)我们首先做一些简单的交互对话,试图让Agent产生一些"记忆":

这里的会话中传递了一些个性化的信息:最近爱看足球、不喜欢坐飞机、对历史文化名城感兴趣等。
现在让我们退出,然后重新启动应用,并开始新的对话:

可以看到,AI知道你最近对足球比赛感兴趣,并进行了推荐。继续上面的对话:

没错,AI也了解你对历史文化名城感兴趣,所以做了更贴心更针对性的规划。
注意,这里Agent的记忆是和user_id相关的(测试代码中为testuser),如果你更换这个user_id,那么将不会获得之前testuser的记忆信息,而会重新开始创建新的用户记忆。
04
小结
借助Mem0你可以快速地给自己的AI应用与智能体添加额外的持久记忆体,以记住用户偏好、曾经的互动、任务的进度等,从而构建自适应的学习与记忆能力,实现完全个性化的AI应用体验。这在个人助理、客户服务、智能咨询、企业生产力应用等领域都可以有广泛的应用。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。