这是一个大模型训练的系列文章,将从零开始手把手带大家构建大模型训练全流程。话不多说,开始发车~什么是大语言模型
1. LLMs是什么?
大型语言模型(LLMs)是基于Transformer架构的深度学习模型,旨在理解、生成和响应类似人类文本的神经网络,具备数十亿参数,专门用于处理和生成自然语言文本。这些模型通过海量数据训练,利用其复杂的网络结构来捕捉语言的序列依赖性和上下文关系。LLMs的核心优势在于其无需手动特征工程,能够自动从数据中学习表示,从而在多种自然语言处理任务中展现出强大的性能和适应性。
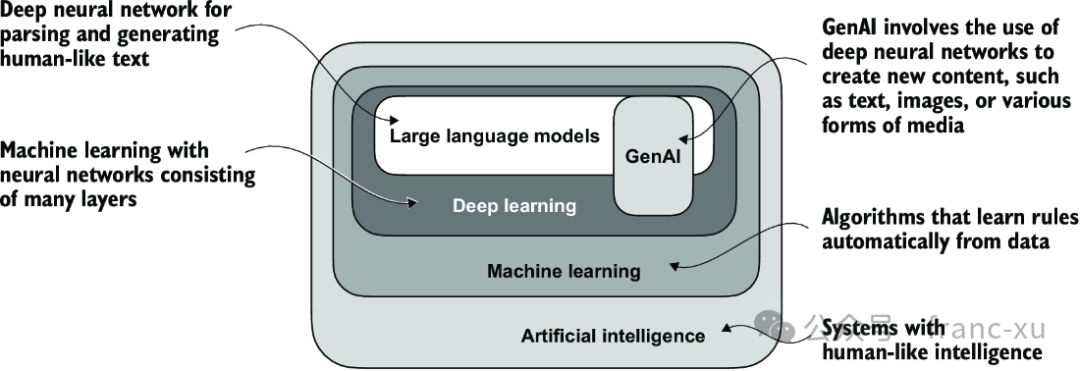
图1.1 如此层次化的不同领域关系图表明,LLM(大语言模型)代表了深度学习技术的一种具体应用,利用其处理和生成类人文本的能力。深度学习是机器学习的一个专门分支,专注于使用多层神经网络。机器学习和深度学习是旨在实现能让计算机从数据中学习并执行通常需要人类智能才能完成的任务的算法的领域。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:

2. LLMs的应用场景
LLM被用于机器翻译、生成新文本、情感分析、文本摘要、内容创作等众多任务。此外,大型语言模型可以用于从医学或法律等专业领域的大量文本中有效检索知识。这包括筛选文档、总结长篇文章以及回答技术性问题。总之,大型语言模型对于涉及解析和生成文本的几乎所有任务来说都是不可或缺的。它们的应用几乎是无穷无尽的,随着我们不断创新发展使用这些模型的新方法,很明显,大型语言模型有潜力重新定义我们与技术的关系,使其更加对话化、直观并且易于访问。
 图1.2 大型语言模型接口使得用户与AI系统之间能够进行自然语言交流。
图1.2 大型语言模型接口使得用户与AI系统之间能够进行自然语言交流。
3. 为什么要构建和使用自己的LLMs
从头开始编码一个LLM是理解其机制和局限性的极佳练习。同时还需要了解对现有的开源LLM架构进行预训练或微调,以适应我们自己特定领域的数据集或任务。使用自定义构建的LLMs有几个优点:
-
保护数据隐私;
-
方便在客户设备上直接部署,减少延迟和降低服务器成本;
-
能够按需控制对模型的更新和修改。
创建一个LLM的一般过程包括预训练和微调。"预"在"预训练"中的含义是指初始阶段,此时像LLM这样的模型在一个大的、多样的数据集上进行训练,以发展出对语言的广泛理解。这个预训练的模型随后作为一个基础资源,可以通过微调进一步精炼,即在特定任务或领域相关的更窄的数据集上对模型进行具体训练。
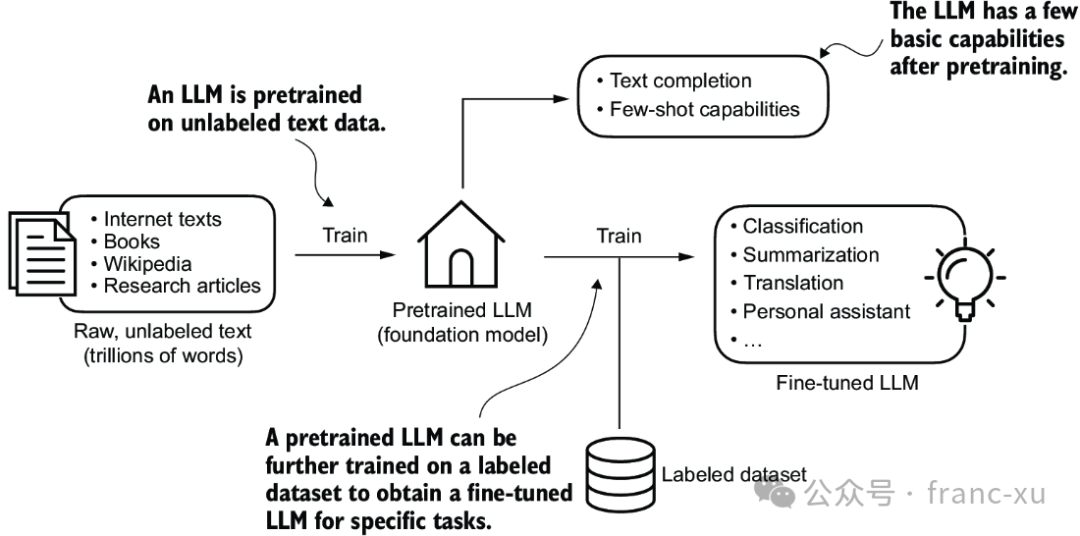
图1.3 预训练LLM(大型语言模型)涉及在大量文本数据集上进行下一个词的预测。然后可以使用较小的标注数据集对预训练的LLM进行微调。
4. 介绍Transformer架构
大多数现代的大语言模型依赖于 Transformer 架构,首次出现在2017年的论文《Attention Is All You Need》。Transfromer 架构由两个子模块组成:编码器和解码器。编码器模块处理输入文本,并将其编码成一系列的数值表示或向量,这些向量捕捉了输入内容的上下文信息。然后,解码器模块接收这些编码的向量并生成输出文本。例如,在一个翻译任务中,编码器会将源语言的文本编码成向量,而解码器则会解码这些向量来生成目标语言的文本。Transformer 的关键组件是自注意力机制,它允许模型衡量序列中不同单词或标记的重要性。这种机制使模型能够捕捉输入数据中的长距离依赖关系和上下文关系,增强其生成连贯且上下文相关的输出的能力。
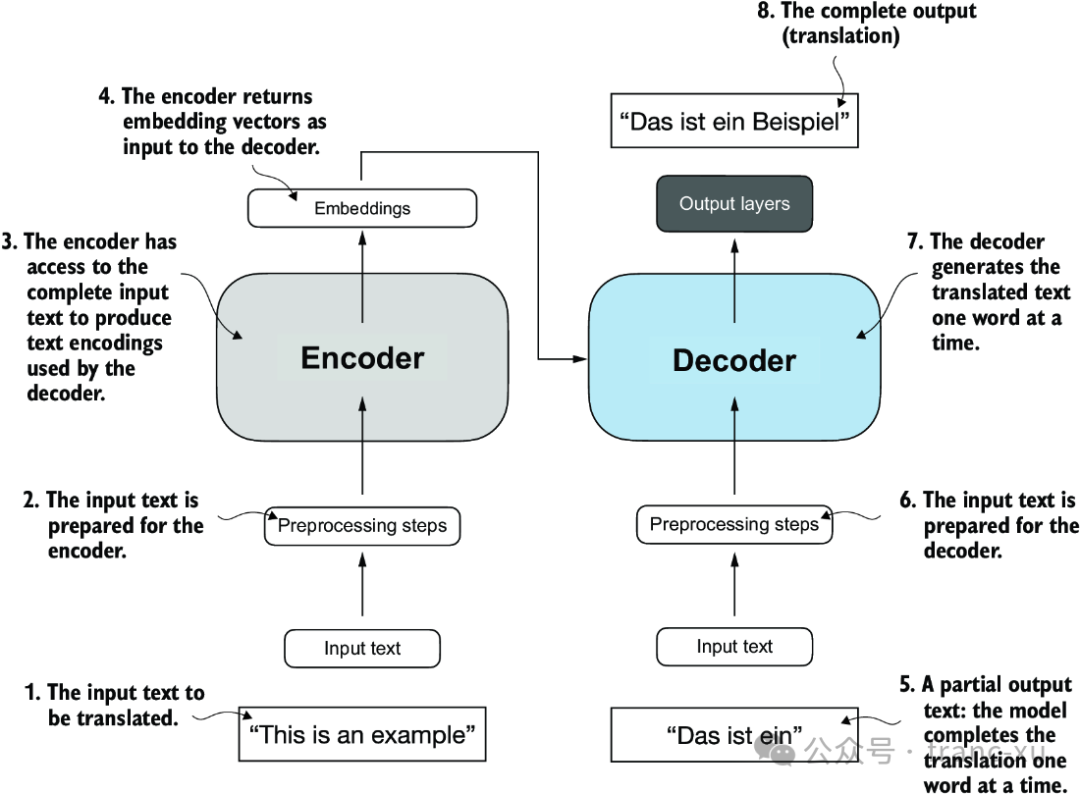
图1.4 对原始 Transformer 架构的简化描绘,这是一种用于语言翻译的深度学习模型。Transformer 由两部分组成:(a) 处理输入文本并生成文本的嵌入表示(一种数值表示,在不同维度上捕捉许多不同因素)的编码器,以及 (b) 可以用来逐词生成翻译文本的解码器。此图显示了翻译过程的最后阶段,其中解码器只需要生成最后一个词("Beispiel"),给定原始输入文本("This is an example")和部分翻译的句子("Das ist ein"),以完成翻译。
后来的 Transformer 架构变体,例如BERT(即来自变压器的双向编码器表示的简称)和各种GPT模型(即生成预训练变压器的简称),在此概念的基础上发展,以适应不同的任务。BERT基于原始变压器的编码器子模块构建,在训练方法上与GPT不同。虽然GPT是为了生成任务设计的,但BERT及其变体专门用于掩码词预测,在给定的句子中,模型预测被掩码或隐藏的词。
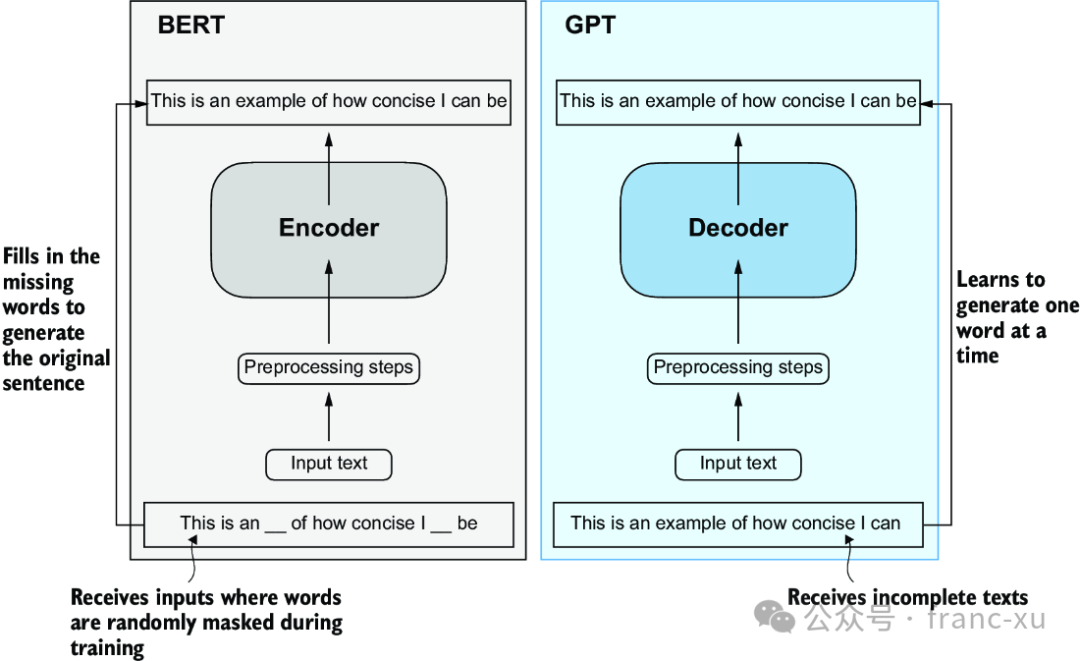
图1.5 Transformer 的编码器和解码器子模块的可视化表示。左边,编码器部分体现了类似BERT的LLM(大型语言模型),它们专注于掩码词预测,主要用于文本分类等任务。右边,解码器部分展示了类似GPT的LLM,它们设计用于生成任务,生成连贯的文本序列。
5. 数据集
大量训练数据集用于流行的类似GPT和BERT的模型,代表了多样且全面的文本语料库,涵盖了数十亿的文字,其中包括大量的主题和自然及计算机语言。总之,就是数据量大,一个CommonCrawl 数据集大约需要570GB的存储空间。
|------------------------|----------------------------|-----------------|-----------|
| 数据名称 | 描述 | 数据量(tokens) | 训练中占比 |
| CommonCrawl (filtered) | Web crawl data | 410 billion | 60% |
| WebText2 | Web crawl data | 19 billion | 22% |
| Books1 | Internet-based book corpus | 12 billion | 8% |
| Books2 | Internet-based book corpus | 55 billion | 8% |
| Wikipedia | High-quality text | 3 billion | 3% |
表1.1 主流的GPT-3大语言模型的预训练数据集(tokens数相当于文本中的单词和标点符合的数量)
6. 细品GPT架构
GPT 最初是由 OpenAI 的 Radford 等人在论文《通过生成预训练改进语言理解》中引入的。GPT-3 是该模型的放大版本,具有更多的参数,并在更大的数据集上进行了训练。这些模型是强大的文本补全模型,并且可以执行其他任务,例如拼写纠正、分类或语言翻译。相比原始 Transformer 架构,通用的 GPT 架构相对简单。基本上,它只有解码器部分而没有编码器。由于像 GPT 这样的解码器风格的模型通过一次预测一个词来生成文本,因此它们被视为一种自回归模型。

图1.6 GPT 架构仅使用了原始变压器的解码器部分。它是为了单向、从左到右的处理而设计的,使其非常适合以迭代的方式生成文本,一次预测一个词。
7. 构建大语言模型
构建大模型语言模型分为一下几个阶段:
-
基本的数据预处理步骤;
-
编码每个大型语言模型(LLMs)核心的注意力机制;
-
编码并预训练一个类似GPT的大型语言模型,使其能够生成新的文本;
-
采用一个预训练的大型语言模型,并对其进行微调。