文章汇总
当前的问题
1.元标记未能捕获分类的关键语义特征
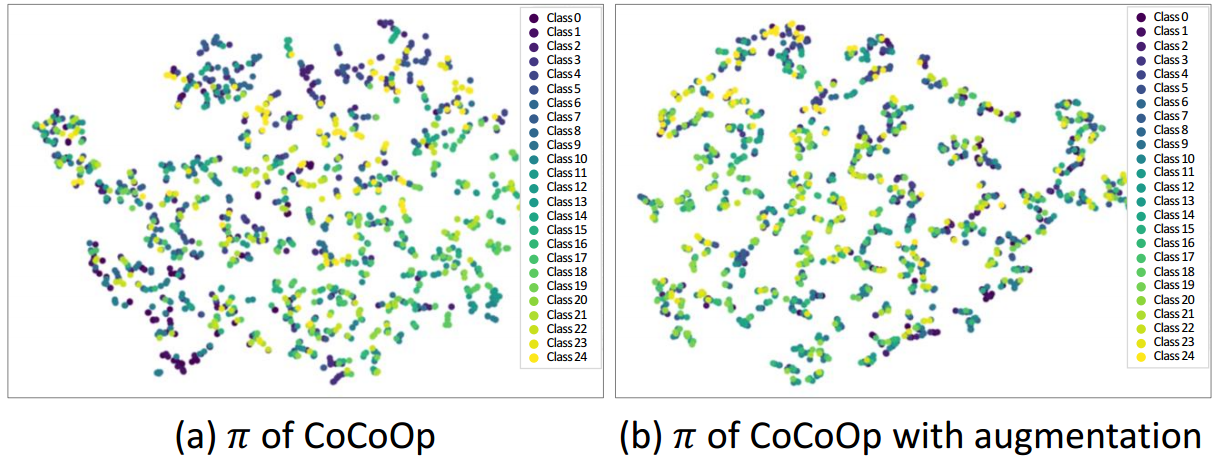
如下图(a)所示, π \pi π在类聚类方面没有显示出很大的差异,这表明元标记 π \pi π未能捕获分类的关键语义特征。我们进行简单的数据增强后,如图(b)所示,效果也是如此
2.简单的增强操作无法提示精度
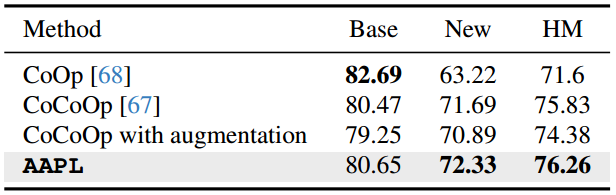
如表1所示,与原始CoCoOp相比,加入增强会导致base-to-new概化精度下降,因为metanet无法从增强图像中提取语义特征;因此,提取任意噪声,而不是特定于属性的语义。
动机
从原始图像特征中减去增强图像特征来有效地提取特定的语义特征和增量元标记。
解决办法
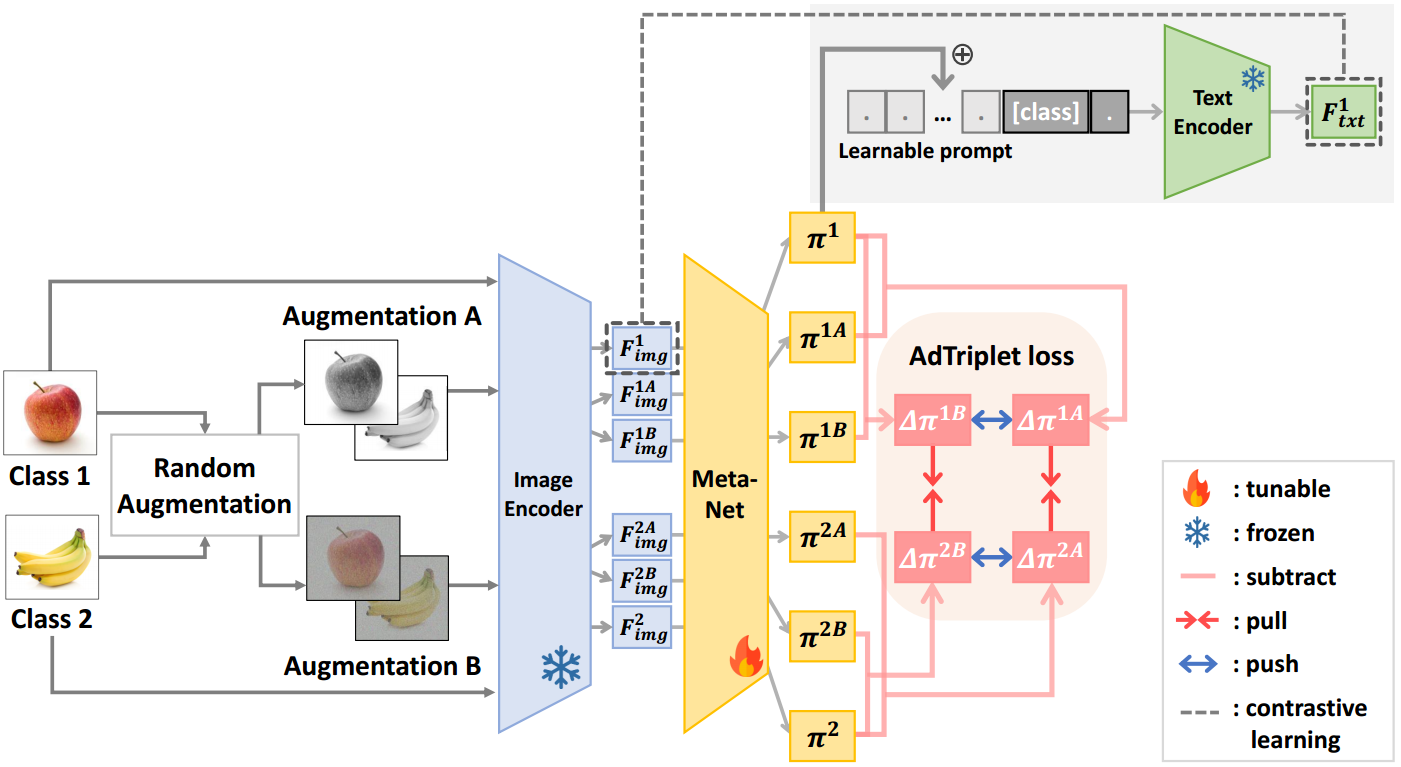
整体流程如上,创新的地方在于做了AdTriplet loss(me:感觉也不算很创新,这种损失应该早就有了)
该损失如下:
弱锚点为 Δ π 1 A \Delta\pi^{1A} Δπ1A,其正对为 Δ π 2 A \Delta\pi^{2A} Δπ2A,其类不同但增广相同。相反, Δ π 1 B \Delta\pi^{1B} Δπ1B被认为是负对,应该被拉远。
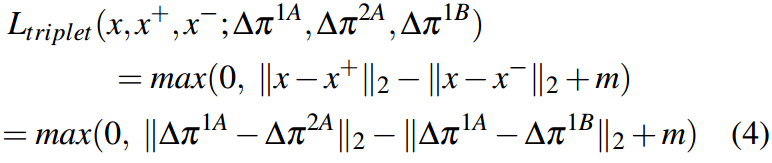
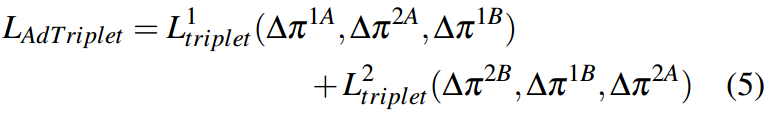
总体损失如下:
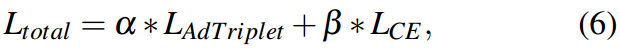
摘要
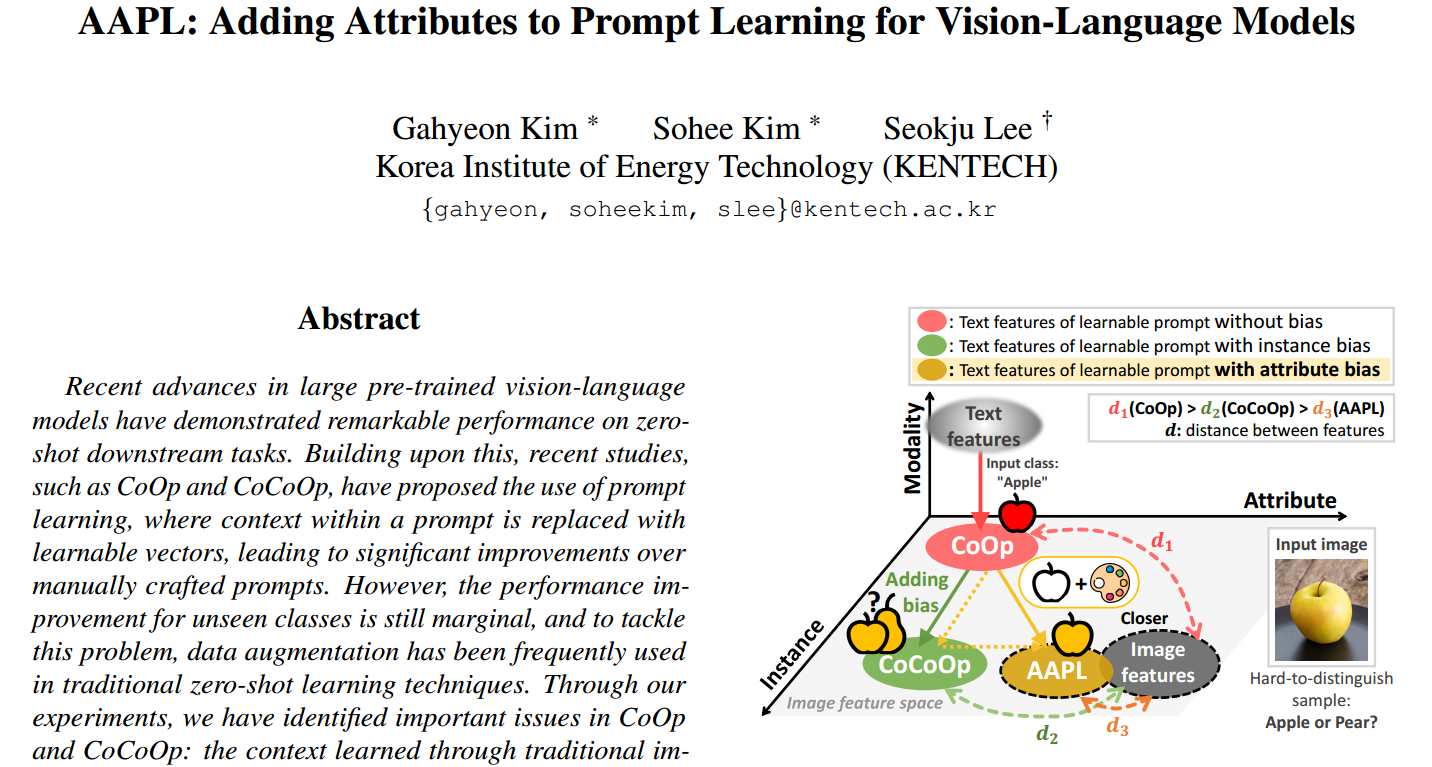
近年来,大型预训练视觉语言模型在零样本下游任务上表现出色。在此基础上,最近的研究,如 CoOp 和CoCoOp,提出了使用提示学习的建议,即提示中的上下文被可学习的向量所取代,从而大大改进了手动制作的提示。然而,对于看不见的类的性能改进仍然是边际的,为了解决这个问题,数据增强在传统的零样本学习技术中经常被使用。通过我们的实验,我们发现了CoOp和CoOp中的重要问题:通过传统图像增强学习的上下文偏向于可见类,对未见类的泛化产生负面影响。为了解决这个问题,我们提出了对抗性令牌嵌入,当在可学习提示中诱导偏差时,将低级视觉增强特征从高级类信息中分离出来。通过我们称为"向提示学习添加属性"(AAPL)的新机制,我们引导可学习的上下文通过关注看不见的类的高级特征来有效地提取文本特征。我们已经在11个数据集上进行了实验,总的来说,与现有方法相比,AAPL在少样本学习、零样本学习、跨数据集和领域泛化任务方面表现出了良好的性能。代码可从https://github.com/Gahyeonkim09/AAPL获得
1. 介绍
最近的研究表明,通过使用大规模视觉语言模型(VLMs),不仅可以显著提高模型泛化性能,而且还可以提高零拍摄图像分类性能46,61,63,64,66。已有研究表明,利用对比语言图像预训练(CLIP)39、ALIGN17、Flamingo1等VLM可以有效地提取图像和文本信息,用于训练分类模型。这些VLMs的优势已被证明在快速学习和有效处理视觉和文本信息方面是有效的31,45,67,68。CoOp68和CoCoOp67通过文本编码器(例如Transformer50)和CLIP有效地为分类权重生成了可学习的上下文向量。具体来说,CoCoOp67通过结合从图像生成的附加上下文信息来创建特定于类的分类权重。此外,视觉提示调谐(visual prompt tuning, VPT)18通过在Transformer的编码器层中引入少量可学习参数以及图像补丁,而无需替换或微调预训练的Transformer,证明了下游任务的性能改进。
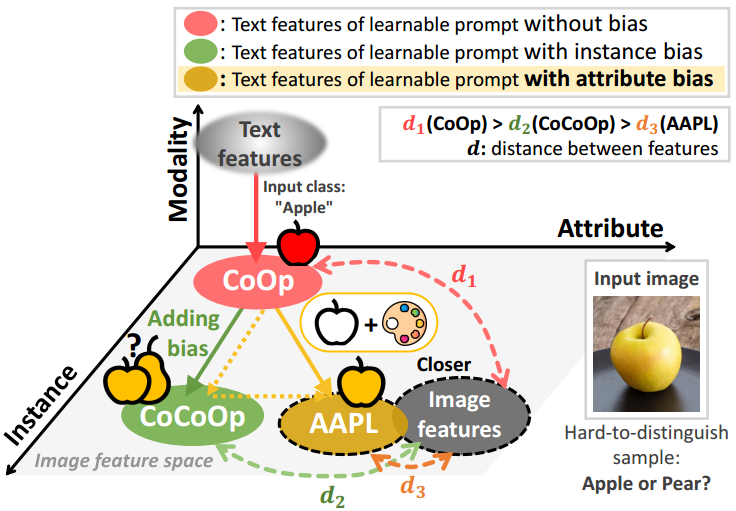
图1所示。苹果的例子。在"apple"类上训练可学习提示,由于训练数据主要由红苹果组成,因此可以将苹果理解为典型的红色。**当输入一个罕见的"黄色苹果"时,实例偏差可能会忽略黄色属性并错误地将其预测为梨。然而,AAPL从图像中提取和分解属性,增强了语义特征中的属性特定偏差。**这使得跨域的泛化性能得到了显著提高。
然而,CoOp68和VPT18都有不可管理的可学习参数,特别是在CoCoOp67的情况下,我们不知道如何根据添加到学习中的图像中的特定信息通过条件偏差来移动可学习上下文向量。缺乏对可学习参数的管理可能会导致在少样本分类任务或领域泛化任务中出现无意的偏差22,30,32。为了解决这个问题,我们提出了一种名为AAPL的新方法,即"为提示学习添加属性",如图1所示。在这种情况下,增强会产生一种可学习的偏见,这种偏见可以被分解,增强的图像作为视觉提示。视觉文本提示的后续学习涉及到可学习上下文向量的使用,它起着对抗作用,减轻了下游任务中意外的过拟合22,30,32。综上所述,我们的贡献如下:
我们建议使用增强图像作为视觉提示,并引入"增量元令牌"的概念,该概念封装了特定属性的信息。
使用delta元令牌,我们进行AdTriplet损失,使条件偏差鲁棒地包括类的语义特征,即使存在通过对抗性三元组损失添加到可学习提示的增强。
我们展示了基本新泛化任务、跨数据集任务和域泛化任务的性能改进。
2. 相关的工作
视觉语言模型
使用图像-文本对的视觉语言模型(VLMs)表现出比仅使用图像的模型更优越的能力,特别是在各种下游分类任务的零射击转移任务中46,61,63,64,66。著名的模型,如CLIP39和ALIGN17,通过大规模的网络数据利用而取得进步,采用自监督学习来增强文本和视觉对齐。在嵌入空间中,对比损失将匹配的图像-文本表示对拉近,而将不匹配的图像-文本表示对拉近。使用这种方法,CLIP展示了卓越的零样本图像识别能力,而无需进一步微调。我们的目标是找到将预训练的视觉语言模型应用于下游应用的有效方法,特别是在CoOp68和CoOp67等提示学习中。
视觉语言模型中的提示学习
提示学习的概念最初是在自然语言处理(NLP)领域提出的27-29。与手动设计提示不同,提示学习研究侧重于在微调阶段自动选择提示。最近,这一概念已经扩展到计算机视觉领域18,21,31,45,52,60,68,69。CoOp68将持续提示学习引入视觉领域,将预先训练好的视觉语言模型应用于各种任务。他们没有使用像"a photo of a"这样的手动提示,而是将上下文词转换为可学习的上下文向量,以优化连续提示。然而,CoOp在泛化方面存在局限性,因为它只对少量数据集进行过拟合。为了解决这个问题,CoCoOp67在可学习提示符中添加了一种条件偏差,称为从图像特征中提取的元标记。它将重点从静态提示转移到动态提示,支持基于每个实例的特征而不是特定类的优化,从而增强CoOp的域泛化性能。然而,从图像样本中获得的元令牌不能声称对过拟合问题具有完全的鲁棒性22,30,32,并且它是不可解释的,因为它是从称为metanet的浅层网络中提取的,该网络由Linear-ReLU-Linear层组成。因此,我们提出了一种新的提示学习方法,使用图像增强来利用添加到可学习提示中的属性特定偏差。
零样本学习
少样本学习是在对新图像进行分类之前,对少量标记样本进行训练的过程。相比之下,零样本学习(zero-shot learning, ZSL)旨在通过只训练见过的类来区分未见过的类5,57。这是通过专门训练一组基类并利用与这些看不见的类共享的侧信息(通常是视觉属性,如颜色、形状和其他特征)来实现的。这些辅助信息帮助机器以人类的方式理解语言或概念,使其能够识别看不见的类。
常用的方法4,20,34,42,55是学习类嵌入与表示该辅助信息的图像特征之间的关系。然而,这些方法往往表现出对不可见类的偏见,称为"可见类偏见"56。其他的研究工作集中在增强视觉语义嵌入3,19,65,或开发更好的图像特征提取器16,59。然而,这些方法通常假设一组固定的辅助信息,由人类标记的属性组成。这个假设带来了挑战,因为标记属性是昂贵的,需要专家注释者,并且很难在大型数据集上扩展。与现有的ZSL方法不同,我们的工作侧重于适应大型视觉语言模型,并采用基于提示的技术。
3. 方法
3.1. Preliminaries
提示学习CLIP
CLIP39使用基于ResNet11或ViT24的图像编码器和基于Transformer50的文本编码器分别从图像和文本中提取特征。这些特征在嵌入空间中使用对比损失进行训练,旨在最大化成对模态特征之间的余弦相似度。当通过图像编码器处理输入图像 x x x时 f ( ⋅ ) f(\cdot) f(⋅),则生成图像特征 f ( x ) f(x) f(x)。使用类似"a photo of a {class}"的提示模板,其中{class}标记被替换为第 i i i个类的名称,对于给定的 K K K个类类别,产生 K K K个具有相应权重向量 { w i } i = 1 K \{w_i\}^K_{i=1} {wi}i=1K的文本特征。CoOp的预测概率如Eq. 1所示,其中 s i m ( ⋅ , ⋅ ) sim(\cdot,\cdot) sim(⋅,⋅)为余弦相似度, τ \tau τ为温度参数。

提示学习中的条件上下文优化
CoOp68引入上下文令牌作为可训练向量, M M M可学习上下文, { v 1 , v 2 , ... , v M } \{v_1,v_2,\ldots,v_M\} {v1,v2,...,vM},脱离固定模板,如"a photo of a"。第 i i i类提示, t i = { v 1 , v 2 , ... , v M , c i } t_i=\{v_1,v_2,\ldots,v_M,c_i\} ti={v1,v2,...,vM,ci},包括这些向量和类名 c i c_i ci的词嵌入。文本特征由CLIP文本编码器 g ( ⋅ ) g(\cdot) g(⋅)从 t i t_i ti生成,在整个训练过程中保持冻结。CoCoOp67提出实例条件上下文来优先考虑单个输入实例,减少CoOp的过拟合。这是通过使用一个元网来完成的,表示为 h θ ( ⋅ ) h_{\theta}(\cdot) hθ(⋅),参数化为 θ \theta θ,为每个输入生成一个条件令牌。式中 π = h θ ( f ( x ) ) , m ∈ { 1 , 2 , ... , M } \pi=h_{\theta}(f(x)),m\in \{1,2,\ldots,M\} π=hθ(f(x)),m∈{1,2,...,M},每个上下文令牌由 v m ( x ) = v m + π v_m(x)=v_m+\pi vm(x)=vm+π获得。第 i i i类的提示以输入的图像特征为条件,即 t i ( x ) = { v 1 ( x ) , v 2 ( x ) , ... , v M ( x ) , c i } t_i(x)=\{v_1(x),v_2(x),\ldots,v_M(x),c_i\} ti(x)={v1(x),v2(x),...,vM(x),ci}。在训练过程中,联合更新上下文向量 { v m ( x ) } m = 1 M \{v_m(x)\}^M_{m=1} {vm(x)}m=1M和元网,保证了泛化性。CoCoOp的预测概率为:
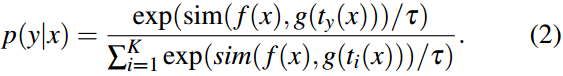
3.2. Delta元令牌
Effect of augmentation in CoCoOp
表1。带增强的AAPL与CoCoOp的基-新泛化精度比较。HM为谐波平均分。
图3。FGVCAircraft数据集CoCoOp元令牌与CoCoOp随机增强元令牌的比较
为了研究图像增强在提示学习中的作用,我们将增强引入CoCoOp进行了对比实验67。我们将增强图像的条件偏差添加到可学习提示中,同时保持其他设置与CoCoOp一致。如表1所示,与原始CoCoOp相比,加入增强会导致base-to-new概化精度下降,因为metanet无法从增强图像中提取语义特征 ;因此,提取任意噪声,而不是特定于属性的语义。此外,如图3所示,它在类聚类方面没有显示出很大的差异,这表明元标记未能捕获分类的关键语义特征。因此,这表明仅仅在提示学习中使用增强可能不会提高鲁棒性或性能。它可能会导致有害的影响,因为元网络无法从增强的图像识别有意义的语义特征,专注于特定于实例的特性,而不是类语义。为了获得最佳结果,需要更小心地应用增强,确保条件偏差适当地捕获类的语义信息。
Delta元令牌:分离属性功能
CoCoOp67通过引入metanet来提高CoOp68的泛化性能,该metanet从图像样本中输出元令牌,然后将其添加到可学习提示符中。它侧重于学习单个实例信息,而不是类信息。然而,目前还不清楚元令牌包含什么信息,因为元网是一个黑盒子,其浅架构导致不确定的特征提取。**如图3所示,无论是通过增强类型还是通过类,都无法展示出清晰的聚类。结果表明,元标记不能有效地捕获类的语义信息或输入图像样本的属性。**为了解决这个问题,并使向可学习提示添加所需信息成为可能,我们提出了增量元令牌的概念,即属性特定偏差。AAPL的概况如图2所示。
图2。AAPL概述我们对输入图像应用两个不同的随机增强,每个图像的类标签分别为1和2。一旦从预训练的CLIP图像编码器39中提取图像特征,它们就会通过元网67来获取元令牌。然后利用它们减去从每个类的增强图像中获得的其他元令牌,从而得到增量元令牌。我们的目标是指导他们使用这些增量元令牌,而不管它们的分类如何。与相同增广相关联的增量元令牌使用AdTriplet损失在嵌入空间内接近,如Eq. 5所示。增量元标记获取特定属性的特征,而元标记学习来自图像特征的语义特征,从而通过分解的特征在可学习提示中使用特定属性的偏差。
为了制作一个delta元标记,需要两个不同类的图像,例如类1和类2,如图2所示。对于每对输入图像,SimCLR6中提出的14种无重复增强方法中随机选择两种不同的增强类型,记为 A u g A ( ⋅ ) Aug_A(\cdot) AugA(⋅)和 A u g B ( ⋅ ) Aug_B(\cdot) AugB(⋅)。TextManiA62演示了使用Word Vector Analogy从文本中提取属性信息9,35,受其启发,我们通过减去同一类中不同增强的图像特征来生成delta元令牌。
元标记表示包含增强信息的图像特征的差向量。它们在每次迭代中生成。类1和 A u g A ( ⋅ ) Aug_A(\cdot) AugA(⋅)的图像 x x x的增量元令牌可以写成如下:
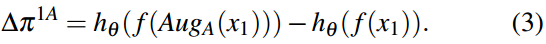
正如TextManiA所展示的,利用包含从类信息派生的语义细节的属性证明了它在分类任务中的有效性。换句话说,虽然元标记包含类和属性信息,但增量元标记保留与增强相关的更具体的图像特征信息。将分解的辅助特性添加到可学习提示中,增量元标记可以学习属性信息。我们使可学习提示符更丰富地融入语义特征,从而使增强更有效。与自然语言处理的对抗性提示学习类似37,54,我们的方法涉及类信息和属性信息之间的对抗性交互,其中元网络学习从增强的图像特征中提取属性相关信息。可学习提示符学习到的类的语义特征信息越多,分类性能越好。

图4。fFGVCAircraft数据集CoCoOp67和AAPL元令牌和delta元令牌的t-SNE可视化。点的颜色表示14个不同的增强,并且使用了验证集中的100个数据点。(a)和©是元标记的可视化,(b)和(d)是增量元标记的可视化。
delta元令牌有精确的增广信息吗 ?在图4中,我们使用t-SNE对CoCoOp67和AAPL的meta验证结果进行了比较。这表明,与AAPL相比,CoCoOp未能区分增强功能。对比图4 ©和(d),元标记不能完美区分14种增强,而增量元标记除了垂直翻转和旋转等少数增强外,几乎表现出完美的区分。聚类结果表明,delta元令牌比元令牌提取了更多关于增强的具体信息。如TextManiA62所示,对于文本情况,特征之间的减法可以保留特定的特征。在图像的情况下,我们展示了delta元令牌在使其包含精确的增强信息方面更有效。据我们所知,我们是第一个通过减法使用视觉特征来提示学习的人。值得注意的是,虽然元标记仍然保留有关类的信息,但增量元标记准确地区分了语义特征和属性特征。
3.3. 对抗性三元组损失
使用三元丢失15,43,47,53,我们可以消除增量元令牌中剩余的特定于类的信息,同时增强与增强相关的信息。在嵌入空间中使用4个delta元令牌 ( Δ π 1 A , Δ π 1 B , Δ π 2 A , Δ π 2 B ) (\Delta\pi^{1A},\Delta\pi^{1B},\Delta\pi^{2A},\Delta\pi^{2B}) (Δπ1A,Δπ1B,Δπ2A,Δπ2B)进行训练,目的是增加同一类向量之间的距离并且对于相同的增广,最小化它。例如,设锚点为 Δ π 1 A \Delta\pi^{1A} Δπ1A,其正对为 Δ π 2 A \Delta\pi^{2A} Δπ2A,其类不同但增广相同。相反, Δ π 1 B \Delta\pi^{1B} Δπ1B被认为是负对,因为它具有相同的类,但增广不同。锚与负极对之间的距离应大于锚与正极对之间的距离。欧几里得距离记为 ∣ ∣ ⋅ ∣ ∣ 2 {||\cdot||}_2 ∣∣⋅∣∣2,三重态损失余量记为式4中的 m m m。
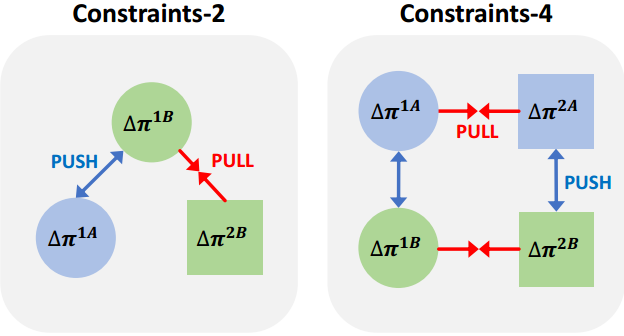
因此,我们引入了Adtriplet loss,它对抗性地训练模型以优先考虑增强信息比对类信息。该损失与分类损失一起更新,特别是交叉熵损失。使用AdTriplet损失作为约束4,如图5所示,使类信息域和增强属性域之间的连接更加平衡23。
图5。比较AdTriplet损失的约束数目。约束条件2的锚点只有一个,例如, Δ π 1 B \Delta\pi^{1B} Δπ1B,约束条件4的锚点有两个,例如, Δ π 1 A \Delta\pi^{1A} Δπ1A和 Δ π 2 B \Delta\pi^{2B} Δπ2B。
交叉熵损失的计算方法与CoCoOp67相同。为了保证训练阶段和测试阶段的公平性,只使用一个输入图像标签进行交叉熵损失计算。最终的训练损失函数为:
其中 α \alpha α和 β \beta β是缩放的超参数。在第4节中,我们将提供有关参数调优的详细信息。
4. 实验
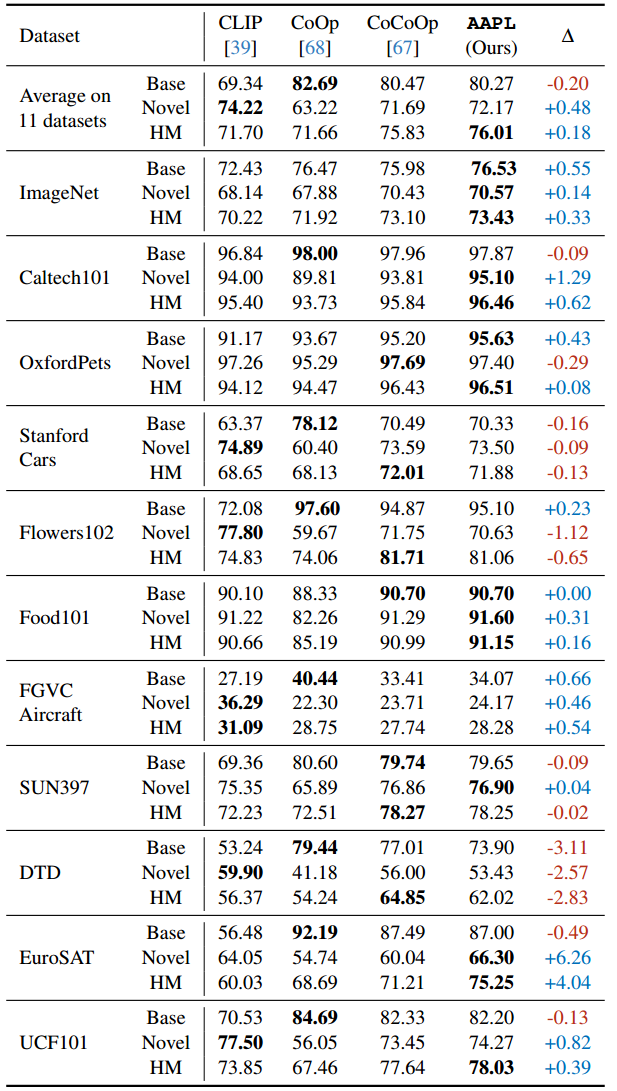
表2。与基线相比,基线到新泛化实验。该模型从基类(16个样本)中训练,并在新类中进行评估。HM为调和平均值。 Δ \Delta Δ为AAPL与coop之差。加粗的部分表示最高的性能分数。
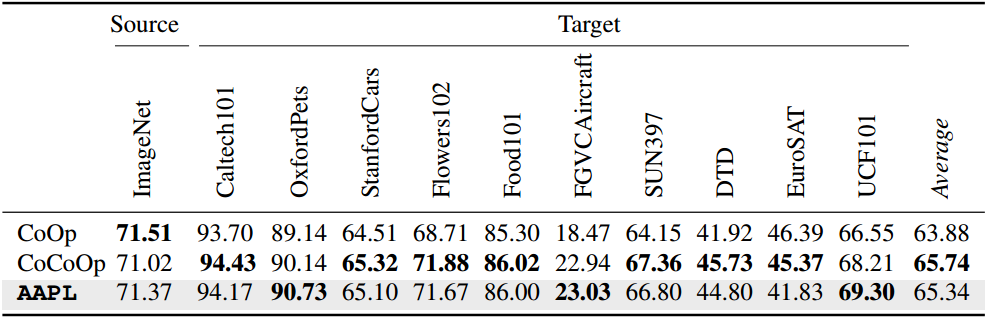
表3。跨数据集传输实验。该模型在整个ImageNet类(16个样本)上进行训练,并在其他10个数据集上进行评估。

表4。领域泛化实验。该模型在整个ImageNet类(16个样本)上进行训练,并在四个不同的基于ImageNet的数据集上进行评估,包括域移位。
哪种增强对促进学习是有效的?
图7 (a)显示了14个增强的delta元标记的t-SNE可视化,以及它们的轮廓分数。事实证明,很难区分旋转和翻转以及颜色抖动,而其他增强则很明显。所有数据集都难以区分这些增广。经过选择性增强训练后,当只训练结果良好的增强时(如图7 (b)所示),聚类得到极大增强,剪影分数也得到提高。此外,从基数到新泛化的平均性能也得到了改善,如表6所示。但是,当只训练相反的情况,即坏兆头时(图7 ©),轮廓分数和视觉效果都没有显著提高在平均基数到新泛化结果。在翻转和旋转之间以及在颜色抖动之间增强的模糊性限制了元神经网络的学习能力。
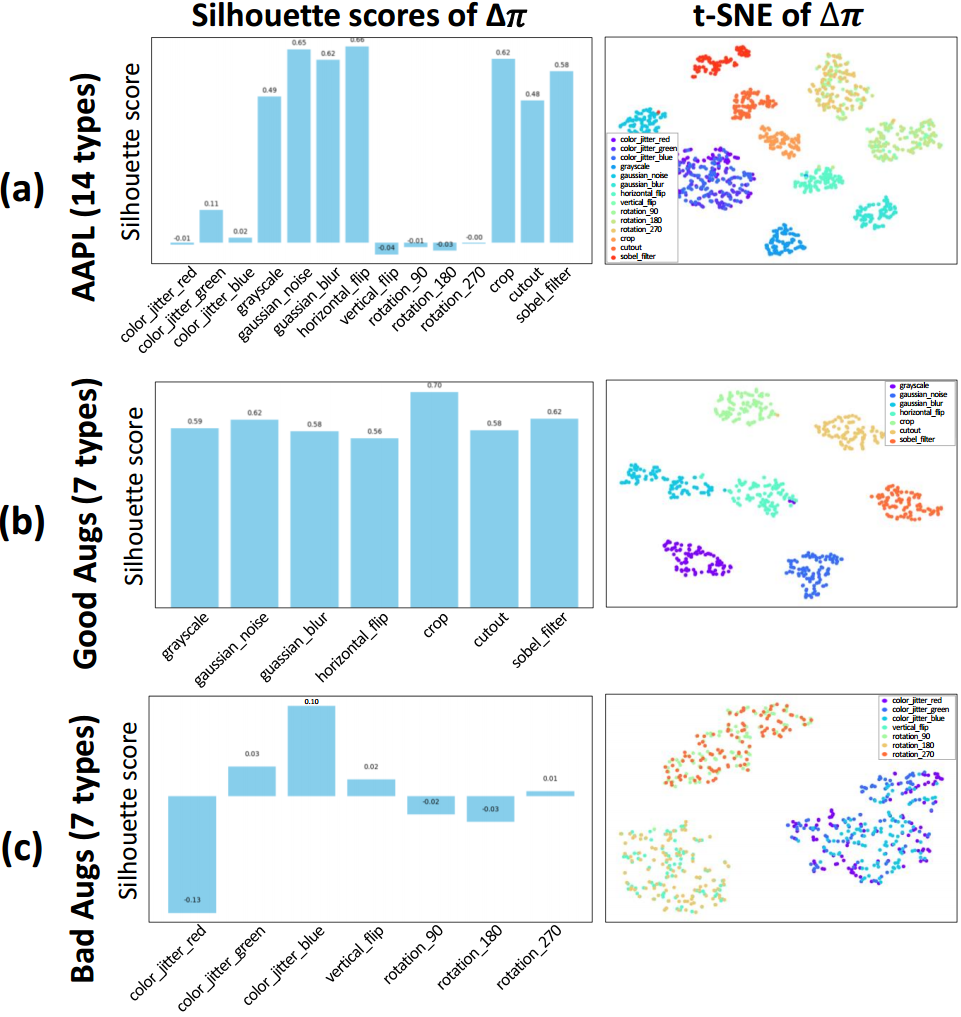
图7。 FGVCAircraf上每一种特定增型的轮廓评分和从基到新概化的t-SNE比较。所有的结果都来自最后一个时期。
5. 结论
我们的新方法通过从原始图像特征中减去增强图像特征来有效地提取特定的语义特征和增量元标记。利用AdTriplet损失对抗地增强分类损失,通过增强实现属性特征的精确识别------这是我们方法的一个基本方面。通过更精确地分解属性和语义特征,我们在提示符中引入了属性特定偏差。此外,我们的研究强调了AAPL在零样本分类任务的增强快速学习中的不可或缺性。总之,我们通过增强分析和对数据集相关性、增强和AAPL性能的分析来强调提示学习中属性分解的重点。
参考资料
论文下载(2024CVPR workshop)
https://arxiv.org/abs/2404.16804