一、CNN 的概述
卷积神经网络(Convolutional Neural Networks,CNN)是深度学习的代表算法之一,在深度学习中占据着重要地位。
CNN 的发展历程可追溯至 20 世纪 80 至 90 年代,时间延迟网络和 LeNet - 5 是最早出现的卷积神经网络。随着深度学习理论的提出和数值计算设备的改进,CNN 在 21 世纪后得到了快速发展,并被广泛应用于计算机视觉、自然语言处理等领域。
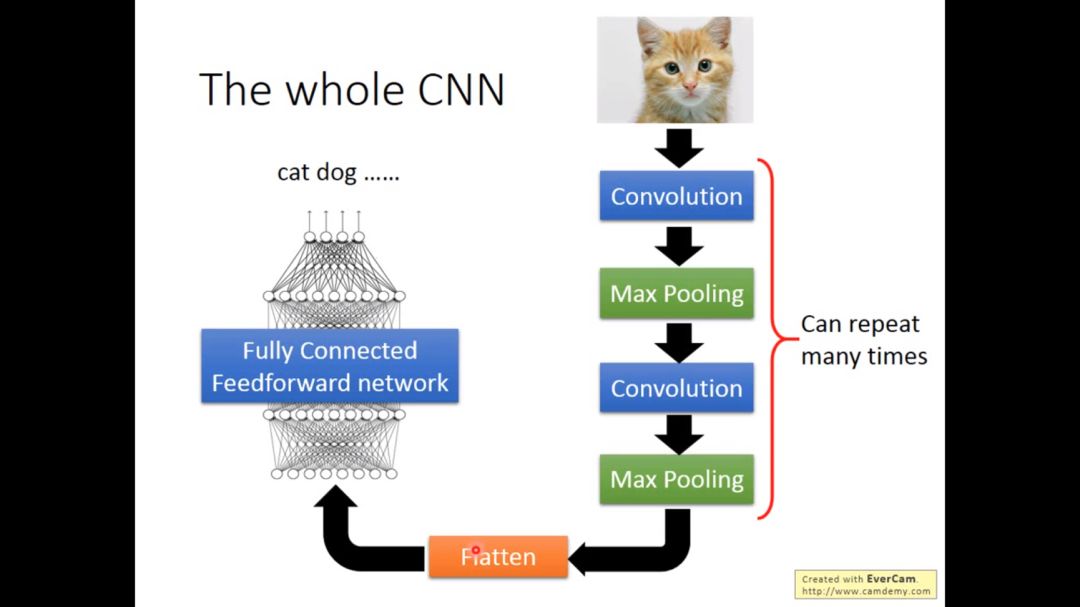
CNN 的结构组成主要包括输入层、卷积层、池化层、全连接层和 Softmax 层等。输入层接收图像等多维数据,并进行标准化处理。卷积层是 CNN 的核心部分,通过卷积操作提取图像的特征,具有局部感知和权值共享的特性。池化层可以缩小矩阵的大小,降低计算量,同时提取主要特征。全连接层将前面提取的特征进行加权和,映射到样本标记空间,完成分类任务。Softmax 层主要用于分类问题,得到当前样例属于不同种类的概率分布情况。
CNN 仿造生物的视知觉机制构建,能够以较小的计算量对格点化特征进行学习,具有稳定的效果且对数据没有额外的特征工程要求。它具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类,因此也被称为 "平移不变人工神经网络"。
二、CNN 在图像处理中的优势
(一)与传统神经网络的比较
传统的神经网络在图像处理方面存在一些局限性。而卷积神经网络(CNN)在图像处理方面相较于传统神经网络具有独特优势。首先,CNN 的输入图像和网络的拓扑结构能很好地吻合。传统神经网络通常需要手动提取特征,难以适应图像的复杂结构,而 CNN 可以直接处理原始图像数据,通过卷积层自动提取图像特征,使得网络结构与图像的空间结构更加匹配。其次,特征提取和模式分类同时进行。在传统神经网络中,特征提取和分类通常是分开的步骤,需要人工设计特征提取器,而 CNN 在卷积层进行特征提取的同时,通过后续的全连接层和分类器进行模式分类,大大提高了图像处理的效率。最后,权重共享可以减少网络的训练参数,使神经网络结构变得更简单,适应性更强。传统神经网络中,每个神经元都有独立的权重参数,而 CNN 中的卷积层通过权值共享,使得同一卷积核在不同位置检测相同的特征,大大减少了参数数量,降低了过拟合的风险。
(二)局部连接性与权值共享
CNN 的局部连接性使得网络能够更好地处理图像数据,减少参数数量和降低过拟合风险。在处理图像这样的高维度输入时,让每个神经元都与前一层中的所有神经元进行全连接是不现实的,因为这会使参数量剧增。而 CNN 让每个神经元只与输入数据的一个局部区域连接,该连接的空间大小叫做神经元的感受野。例如,对于一个 1000 x 1000 的输入图像而言,如果下一个隐藏层的神经元数目为 10^6 个,采用全连接则有 1000 x 1000 x 10^6 = 10^12 个权值参数,而采用局部连接,隐藏层的每个神经元仅与图像中 10 x 10 的局部图像相连接,那么此时的权值参数数量为 10 x 10 x 10^6 = 10^8,将直接减少 4 个数量级。权值共享进一步降低了参数数量和计算复杂度。在卷积层中,每个滤波器与上一层局部连接,同时每个滤波器的所有局部连接都使用同样的参数(卷积核)。假设有 100 个卷积核,假设局部连接中隐藏层的每个神经元连接的都是 10 x 10 的局部图像,则参数也仅有 100 * 100 = 10^4 个。当局部连接和权值共享后,隐层的参数个数就和隐层的神经元个数无关了,而是只和滤波器的大小和种类的多少有关。
(三)平移不变性
CNN 具有平移不变性,这意味着特征检测在平移图像时保持不变性,提升了模型对输入变换的鲁棒性。在 CNN 中,卷积被定义为不同位置的特征检测器,同时存在的池化操作返回局部感受野中最显著的值。两者结合起来提供了 CNN 的局部平移不变性。例如,输入图像的左下角有一个人脸,经过卷积,人脸的特征也位于特征图的左下角。假如人脸特征在图像的左上角,那么卷积后对应的特征也在特征图的左上角。池化操作如最大池化,它返回感受野中的最大值,如果最大值被移动了,但是仍然在这个感受野中,那么池化层也仍然会输出相同的最大值。这就使得 CNN 在处理图像时,无论图像中的目标被平移到哪个位置,都可以检测到同样的特征,输出同样的响应,提高了模型的稳定性和泛化能力。
三、CNN 的基本组件及作用

(一)卷积层
1. 卷积层的定义和组成,包括输入数据、过滤器和特征图。
卷积层是卷积神经网络中的核心组成部分,由输入数据、过滤器(也称为卷积核)和输出的特征图组成。输入数据可以是图像等多维数据,通常具有一定的通道数。过滤器是一个小尺寸的矩阵,其大小通常远小于输入数据的尺寸,比如常见的 3x3、5x5 等尺寸。通过过滤器在输入数据上进行滑动,对局部区域进行卷积操作,从而生成特征图。
2. 卷积操作的过程,通过滑动窗口对输入图像进行加权求和,生成特征图。
卷积操作是通过一个滑动窗口在输入图像上进行移动,每次将窗口覆盖的局部区域与过滤器进行对应元素的乘法,然后将乘积结果进行求和,得到一个输出值。这个输出值作为特征图上对应位置的像素值。例如,对于一个输入图像的局部区域为,过滤器为,则卷积操作的结果为。随着滑动窗口在输入图像上遍历,最终生成完整的特征图。
3. 卷积层的作用,如提取图像中的特征、减少参数、保持特征位置信息等。
卷积层的主要作用之一是提取图像中的特征。通过不同的过滤器,可以提取出图像中的不同特征,如边缘、线条、角等低级特征,随着网络层次的加深,还可以提取更复杂的特征。同时,由于卷积层的参数共享特性,大大减少了参数数量。在传统神经网络中,如果输入图像大小为,下一层神经元数目为个,采用全连接则有个权值参数,而在卷积层中,每个过滤器的参数在整个输入图像上共享,假设过滤器大小为,假设有个过滤器,则参数数量为个,极大地减少了参数。此外,卷积层还能够保持特征位置信息,因为过滤器在输入图像上进行滑动时,相对位置关系保持不变,这对于后续的处理和分类任务至关重要。
(二)池化层
1. 池化层的定义和常见操作,如最大池化和平均池化。
池化层是卷积神经网络中用于减少特征图空间尺寸的一种操作。常见的池化操作有最大池化和平均池化。最大池化是选择局部窗口内的最大值作为输出特征图的值。例如,对于一个的窗口,输入数据为,则最大池化的结果为。平均池化则是计算局部窗口内的平均值作为输出特征图的值,对于同样的输入数据,平均池化的结果为。
2. 池化层的作用,包括降维、防止过拟合、提高计算效率、增强平移不变性等。
首先,池化层可以降低特征图的空间尺寸,从而减少后续网络层的计算量和参数数量。例如,输入特征图大小为,经过一个的池化操作后,输出特征图大小变为,大大降低了计算量。其次,池化操作能够提取区域内的代表性特征,从而减少冗余信息,增强模型的泛化能力,防止过拟合。再者,通过减少特征图的尺寸,池化层提高了网络的计算效率。最后,池化层使得网络对输入数据的微小平移变化具有一定的鲁棒性,增强了平移不变性。例如,对于一个图像中的目标,即使稍微发生了平移,经过池化层后,仍然能够提取到相似的特征。
(三)全连接层
1. 全连接层的定义和结构,与前一层的连接方式。
全连接层,有时也被叫作密集层。全连接层中的每个神经元都与前一层的每个神经元连接在一起,形成了一个全连接的网络结构。例如,如果前一层有个神经元,那么全连接层的每个神经元都与这个神经元相连。
2. 全连接层的作用,如在分类任务中作为输出层、进行维度变换、将学到的分布式特征表示映射到样本标记空间等。
全连接层在整个卷积神经网络中起到 "分类器" 的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的 "分布式特征表示" 映射到样本标记空间的作用。在分类任务中,全连接层通常作为输出层,将前面提取的特征进行加权和,通过激活函数得到不同类别的概率分布。全连接层还可以进行维度变换,将卷积层和池化层提取的特征进行整合和变换,以适应不同的任务需求。同时,全连接层可由卷积操作实现,对前层是全连接的全连接层可以转化为卷积核为的卷积,在一定程度上保留模型的复杂度,特别是在源域与目标域差异较大的情况下,全连接层可保持较大的模型容量从而保证模型表示能力的迁移。
四、CNN 的参数共享和稀疏连接
1. 参数共享的概念和优势
参数共享是卷积神经网络中的一个重要特性。在卷积层中,同一个卷积核在不同位置对输入数据进行卷积操作时,使用的是相同的参数。
减少模型参数数量:以图像识别为例,对于一个大小为的图像,如果采用传统全连接神经网络,每个神经元与上一层的所有神经元相连,那么参数数量将极其庞大。而在卷积神经网络中,由于参数共享,每个卷积核的参数在整个图像上共享,大大减少了参数数量。假设使用个的卷积核,参数数量仅为个,相比全连接网络,参数数量大幅减少。
提高统计效率:参数共享使得卷积神经网络能够从有限的数据中学习到更具有代表性的特征。因为相同的参数在不同位置进行卷积操作,相当于对不同位置的输入数据进行了相同的特征提取,这使得模型能够更有效地利用数据中的统计信息。例如,在识别图像中的边缘特征时,无论边缘出现在图像的哪个位置,都可以使用相同的卷积核进行检测,从而提高了模型对不同位置边缘特征的检测能力。
具有变换等价性:参数共享使得卷积神经网络对输入数据的变换具有一定的等价性。例如,当图像进行平移、旋转等变换时,由于卷积核的参数不变,仍然可以在变换后的图像上检测到相同的特征。这使得卷积神经网络在处理具有变换性质的数据时具有更强的鲁棒性。例如,在识别手写数字时,即使数字的位置、方向发生了变化,卷积神经网络仍然能够准确地识别出数字。
2. 稀疏连接的含义和作用
稀疏连接是指卷积神经网络中每一层的输出只依赖于一小部分输入。在传统全连接神经网络中,每一个神经元都与上一层的所有神经元相连,而在卷积神经网络中,卷积层的神经元只与输入数据的局部区域相连,这种连接方式被称为稀疏连接。
减少计算量:稀疏连接大大减少了计算量。以一个大小为的图像为例,如果下一层的神经元数目为个,采用全连接则有个连接,计算量巨大。而在卷积神经网络中,假设卷积层的神经元只与输入图像中的局部区域相连,那么此时的连接数量为,直接减少了 4 个数量级的计算量。
降低过拟合风险:稀疏连接可以降低过拟合的风险。在全连接神经网络中,由于参数数量众多,容易出现过拟合现象,即模型在训练数据上表现良好,但在测试数据上表现不佳。而在卷积神经网络中,稀疏连接减少了参数数量,使得模型更加简单,不容易出现过拟合。此外,稀疏连接使得模型对输入数据的局部变化更加敏感,能够更好地提取局部特征,从而提高模型的泛化能力。
五、CNN 的未来展望

卷积神经网络(CNN)在图像处理领域展现出了强大的实力,其重要性和优势不言而喻。在图像处理中,CNN 能够自动提取图像特征,减少了人工特征提取的复杂性和主观性,大大提高了图像处理的效率和准确性。同时,CNN 的局部连接性、权值共享和稀疏连接等特性,使得它在处理大规模图像数据时具有高效性和鲁棒性。
展望未来,CNN 在图像处理领域的发展方向和应用前景十分广阔。
技术发展方向:
- 更深的网络结构:随着计算能力的不断提升,研究人员将继续探索更深层次的 CNN 结构。更深的网络可以学习到更复杂的图像特征,提高模型的性能。例如,ResNet 等深度网络已经在图像分类等任务中取得了显著的成果,未来可能会出现更多更深层次的网络结构。
- 多模态融合:图像往往不是孤立存在的,它可以与其他模态的数据(如文本、音频等)相结合,提供更丰富的信息。未来的 CNN 可能会与其他模态的神经网络相结合,实现多模态数据的融合处理,从而更好地理解和处理图像。
- 注意力机制的应用:注意力机制可以让模型更加关注图像中的重要区域,提高特征提取的效率和准确性。目前,注意力机制已经在 CNN 中得到了广泛的应用,未来可能会出现更加复杂和高效的注意力机制,进一步提升 CNN 的性能。
- 模型压缩与轻量化:随着移动设备和嵌入式系统的普及,对轻量化的 CNN 模型的需求越来越大。未来的研究可能会集中在模型压缩和轻量化方面,通过剪枝、量化等技术,减少模型的参数数量和计算量,使得 CNN 能够在资源受限的设备上运行。
应用前景:
- 医疗影像分析:CNN 在医疗影像分析中的应用前景广阔。它可以帮助医生快速准确地诊断疾病,如肿瘤检测、骨折诊断等。未来,随着技术的不断进步,CNN 可能会在医疗影像分析中发挥更加重要的作用,提高医疗诊断的准确性和效率。
- 自动驾驶:在自动驾驶领域,CNN 可以用于识别道路、车辆、行人等物体,为自动驾驶系统提供决策依据。未来,随着自动驾驶技术的不断发展,CNN 的性能将不断提升,为自动驾驶的安全和可靠性提供保障。
- 智能安防:CNN 可以用于智能安防系统中的人脸识别、行为分析等任务,提高安防系统的智能化水平。未来,随着安防需求的不断增加,CNN 将在智能安防领域得到更广泛的应用。
- 虚拟现实和增强现实:在虚拟现实和增强现实领域,CNN 可以用于图像识别、跟踪和渲染等任务,为用户提供更加真实的体验。未来,随着虚拟现实和增强现实技术的不断发展,CNN 将在这些领域发挥重要作用。
总之,卷积神经网络在图像处理领域具有重要的地位和广阔的发展前景。未来,随着技术的不断进步,CNN 将在更多的领域得到应用,为人类的生活和工作带来更多的便利和创新。
六、文章总结和代码案例

代码至少 3 个经典案例
- 手写数字识别:
- 这个经典的案例常常被用来展示卷积神经网络在图像识别方面的强大能力。通过使用 MNIST 数据集,其中包含大量的手写数字图像,构建卷积神经网络模型可以准确地识别不同的手写数字。
- 例如,可以使用 Keras 框架来构建一个简单的卷积神经网络。代码如下:
python
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
# 加载数据
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
input_shape = (28, 28, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
# 转换标签为 one-hot 编码
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
# 构建模型
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
# 编译模型
model.compile(loss=keras.losses.categorical_crossentropy, optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1, validation_data=(x_test, y_test))
# 评估模型
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])- 这个代码通过一系列的卷积层、池化层和全连接层,对手写数字图像进行特征提取和分类,最终能够达到较高的准确率。
- 图像分类:
- 图像分类是卷积神经网络的另一个重要应用领域。使用 CIFAR-10 数据集,其中包含 10 个不同类别的图像,可以构建卷积神经网络进行图像分类任务。
- 以下是使用 PyTorch 实现的图像分类代码示例:
python
import torch
import torchvision
import torchvision.transforms as transforms
# 定义数据转换
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 加载数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
# 定义类别标签
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 定义卷积神经网络模型
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
# 定义损失函数和优化器
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 训练模型
for epoch in range(2): # 多批次循环
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 获取输入数据
inputs, labels = data
# 梯度清零
optimizer.zero_grad()
# 前向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 打印统计信息
running_loss += loss.item()
if i % 2000 == 1999: # 每 2000 个小批次打印一次
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
# 测试模型
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))- 这个代码通过定义卷积神经网络模型,使用 CIFAR-10 数据集进行训练和测试,展示了卷积神经网络在图像分类任务中的应用。
- 目标检测:
- 目标检测是计算机视觉中的一个重要任务,卷积神经网络在目标检测中也发挥了重要作用。使用 Faster R-CNN 算法,可以实现对图像中的目标进行检测和定位。
- 以下是使用 TensorFlow Object Detection API 实现的目标检测代码示例:
python
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
# 下载预训练模型
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# 下载模型文件
opener = urllib.request.URLopener()
opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
# 加载模型
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
# 定义输入和输出节点
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# 加载图像
PATH_TO_TEST_IMAGES_DIR = 'test_images'
TEST_IMAGE_PATHS = [os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 3)]
# 进行目标检测
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# 调整图像大小
image_np = np.array(image)
image_np_expanded = np.expand_dims(image_np, axis=0)
# 进行目标检测
(boxes, scores, classes, num) = sess.run(
[detection_boxes, detection_scores, detection_classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# 打印检测结果
print('Detected {} objects in image {}'.format(len(classes[0]), image_path))
for i in range(len(classes[0])):
print('Object {}: score = {}, class = {}'.format(i, scores[0][i], classes[0][i]))- 这个代码通过下载预训练的 Faster R-CNN 模型,使用 TensorFlow Object Detection API 对测试图像进行目标检测,展示了卷积神经网络在目标检测任务中的应用。
综上所述,卷积神经网络在图像处理中具有广泛的应用和强大的优势。通过这些经典的代码案例,可以更好地理解卷积神经网络的工作原理和应用方法。
七、本文相关学习资料
(一)学习书籍推荐
- 《深度学习》:这本书由 Ian Goodfellow、Yoshua Bengio 和 Aaron Courville 合著,全面系统地介绍了深度学习的各个方面,包括卷积神经网络。书中涵盖了深度学习的基本概念、模型架构、优化算法等内容,对于深入理解卷积神经网络在图像处理中的应用提供了坚实的理论基础。
- 《神经网络与深度学习》:作者邱锡鹏。该书详细介绍了神经网络和深度学习的基础知识,包括卷积神经网络的原理、结构和训练方法。书中通过大量的实例和代码,帮助读者更好地掌握卷积神经网络的实际应用。
(二)在线课程资源
- Coursera 上的《深度学习专项课程》:由 deeplearning.ai 提供,涵盖了深度学习的各个领域,包括卷积神经网络。课程内容丰富,包括视频讲解、编程作业和论坛讨论,适合不同层次的学习者。
- 网易云课堂上的相关课程:有很多关于深度学习和卷积神经网络的课程,这些课程由专业的讲师授课,内容涵盖了理论讲解和实际案例分析,能够帮助学习者快速掌握卷积神经网络的知识和技能。
(三)学术论文推荐
- 《ImageNet Classification with Deep Convolutional Neural Networks》:这是 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey E. Hinton 发表的一篇经典论文,介绍了他们在 ImageNet 图像分类竞赛中使用的深度卷积神经网络架构,该架构在当时取得了巨大的成功,推动了卷积神经网络的发展。
- 《Going Deeper with Convolutions》:由 Google 团队发表,提出了 Inception 网络架构,进一步提高了卷积神经网络在图像分类和检测任务中的性能。
(四)开源项目推荐
- TensorFlow:一个广泛使用的开源深度学习框架,提供了丰富的工具和库,用于构建和训练卷积神经网络。TensorFlow 具有强大的计算能力和灵活的架构,支持多种硬件平台,包括 CPU、GPU 和 TPU。
- PyTorch:另一个流行的深度学习框架,以其简洁的 API 和动态计算图而受到欢迎。PyTorch 也提供了丰富的功能,用于构建和训练卷积神经网络,并且在研究和开发领域得到了广泛的应用。
(五)学习社区和论坛
- 知乎:在知乎上有很多关于深度学习和卷积神经网络的问题和回答,学习者可以在这里与其他专业人士交流和讨论,获取更多的学习资源和经验分享。
- 深度学习论坛:如 CSDN 深度学习论坛、机器之心论坛等,这些论坛聚集了大量的深度学习爱好者和专业人士,提供了丰富的学习资料、技术文章和讨论话题,是学习卷积神经网络的良好平台。
通过利用这些学习资料,学习者可以更加系统地学习深度学习的知识和技术,提高自己的实践能力和创新能力。同时,也可以与其他学习者进行交流和互动,共同推动深度学习领域的发展。
博主还写跟本文相关的文章,邀请大家批评指正: