一、系统概述
在法律行业,纸质文件的数字化需求日益迫切,合同、判决书、协议等文件的管理成为法律部门的一大难题。传统手动输入不仅耗时,且易出错。思通数科的OCR识别平台应运而生,以其开源、免费的特性为法律文档管理提供了智能化、自动化的解决方案。平台支持JPG、PNG、PDF等多种格式的文件输入,生成TXT、DOCX、PDF等可编辑文本,具有高于90%的识别精度,并支持多国语言的识别,特别适用于法律事务所、企业法务部和司法机关。

二、应用场景
- 法律事务所的文件存档管理:在日常工作中,律师事务所需要处理大量合同与协议文件。这些文件往往需转化为电子档案,方便后续查阅。通过思通数科OCR系统,律师事务所能够批量将合同扫描件转化为电子文件,并自动修正识别结果中的错字,避免重复检查。OCR识别算法采用深度学习模型,精度高达90%以上,减少了人工录入的时间和成本,保证了文档的安全性和可追溯性。
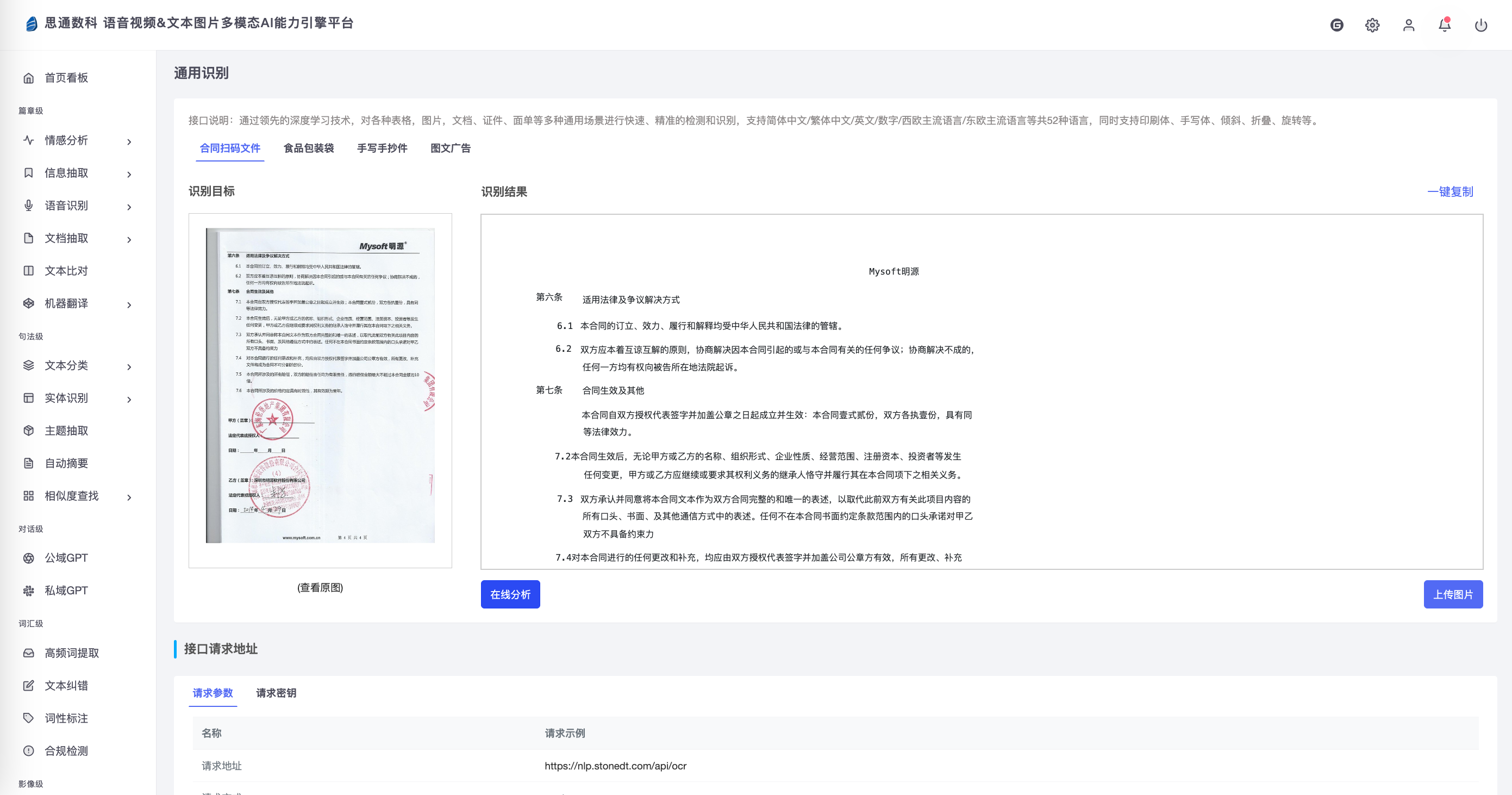
- 企业法务部门的合同管理:对于企业法务部门而言,合同管理是核心工作之一。每份合同都涉及关键条款和法律风险,处理不当可能带来严重的法律后果。使用思通数科OCR平台,法务人员可将合同扫描件直接转化为文本,提升合同存储和查找的便捷性,并在后续审阅时通过全文检索快速定位内容。同时,该系统支持将识别结果以多种格式导出,可轻松集成到现有的合同管理系统中,进一步提升法务团队的工作效率。
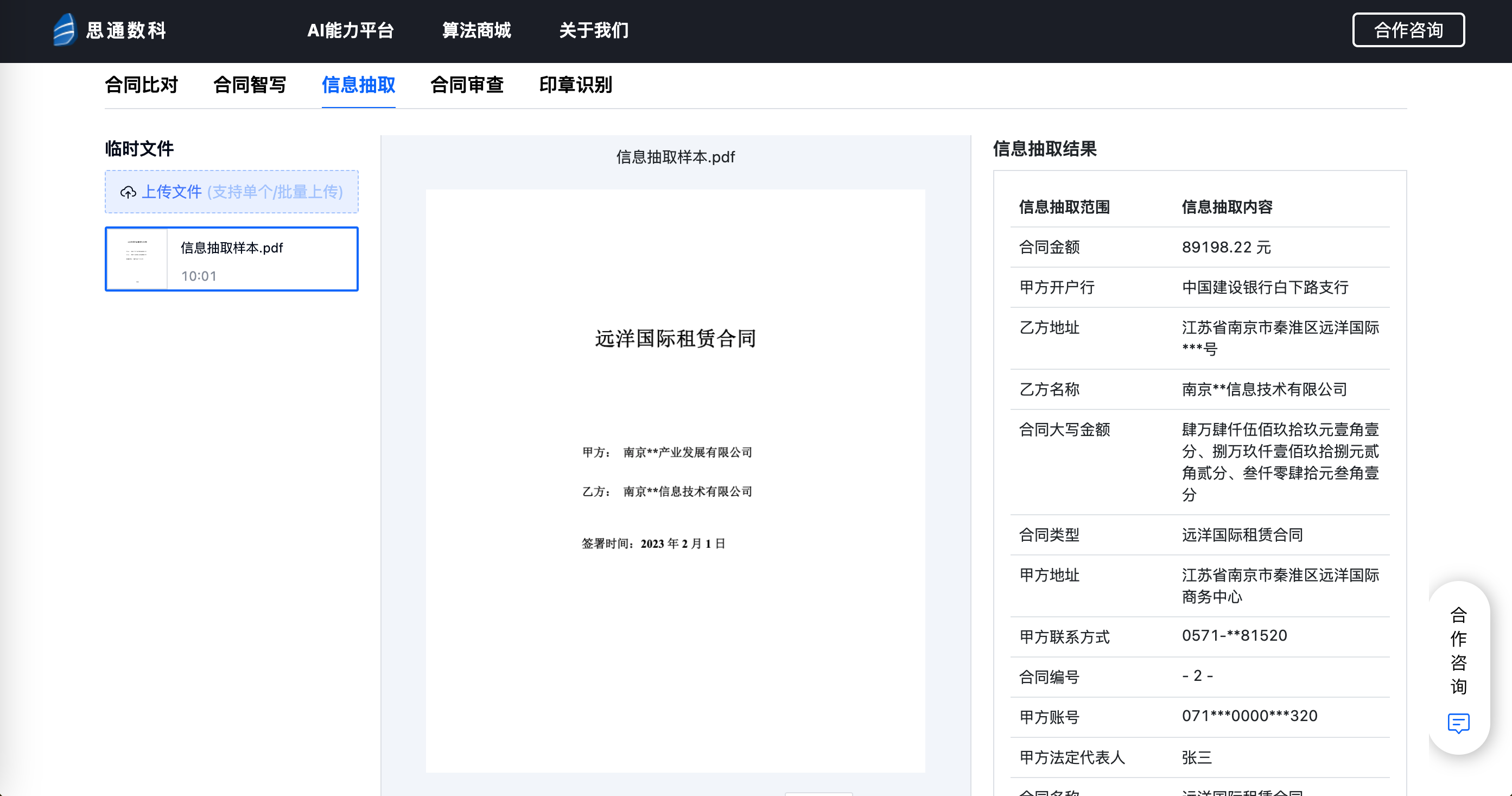
- 司法机关的判决书数字化管理:在司法机关的案件管理过程中,判决书及其相关文件的数字化需求非常高。通过思通数科OCR技术,法院工作人员可以快速将判决书转换为电子文本,并导入到内部系统进行存储和检索。该OCR平台支持对扫描图像的自动优化和手动校正,使识别更加精准,同时提供多语言识别功能,以适应不同类型的案件需求。这一流程有效提升了文档管理的便捷性和检索效率。
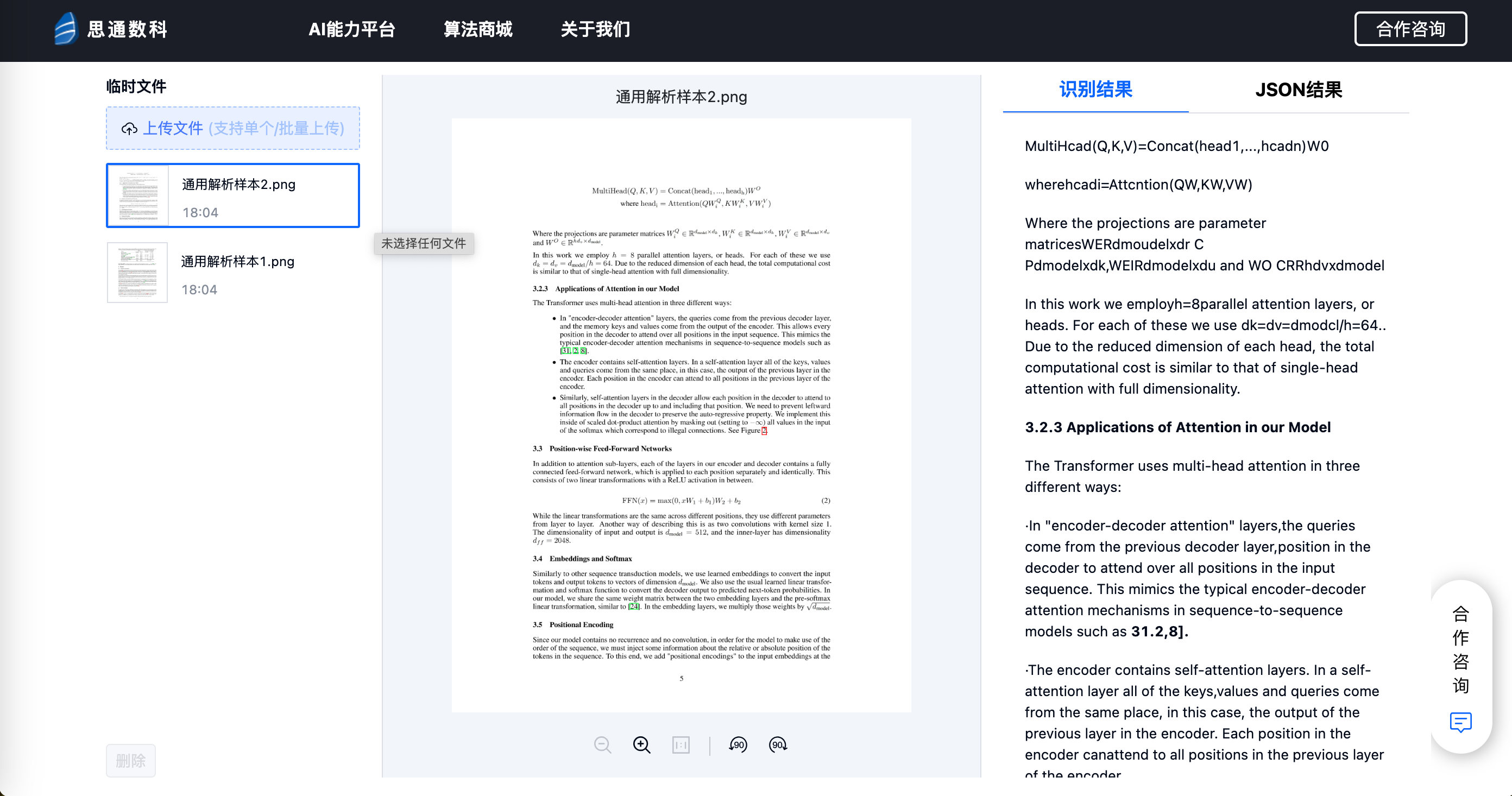
三、技术架构与兼容性
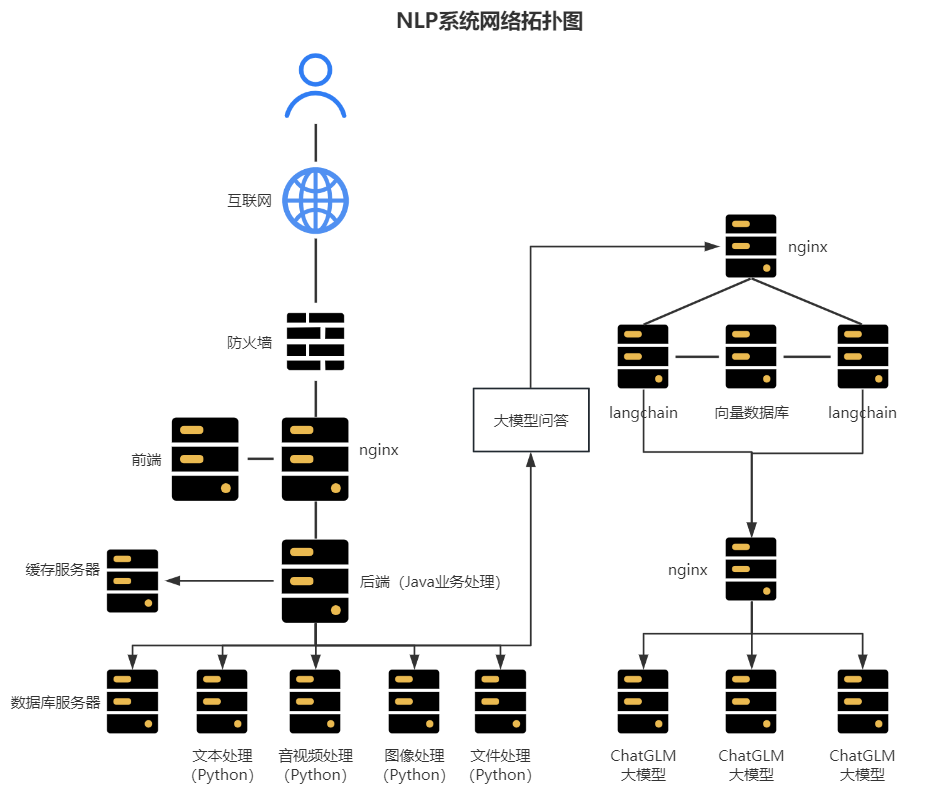
思通数科OCR平台支持与常见的企业系统集成,如ERP、CRM系统等,兼容多种格式和语言,包括Docker和Kubernetes等环境,方便企业进行二次开发和模块扩展。该平台提供开放的API接口,以便用户根据自身需求灵活扩展,确保其兼容性和稳定性。
体验地址:++https://nlp.stonedt.com++
或通过网络搜索"思通数科AI多模态能力平台"
更多咨询:
