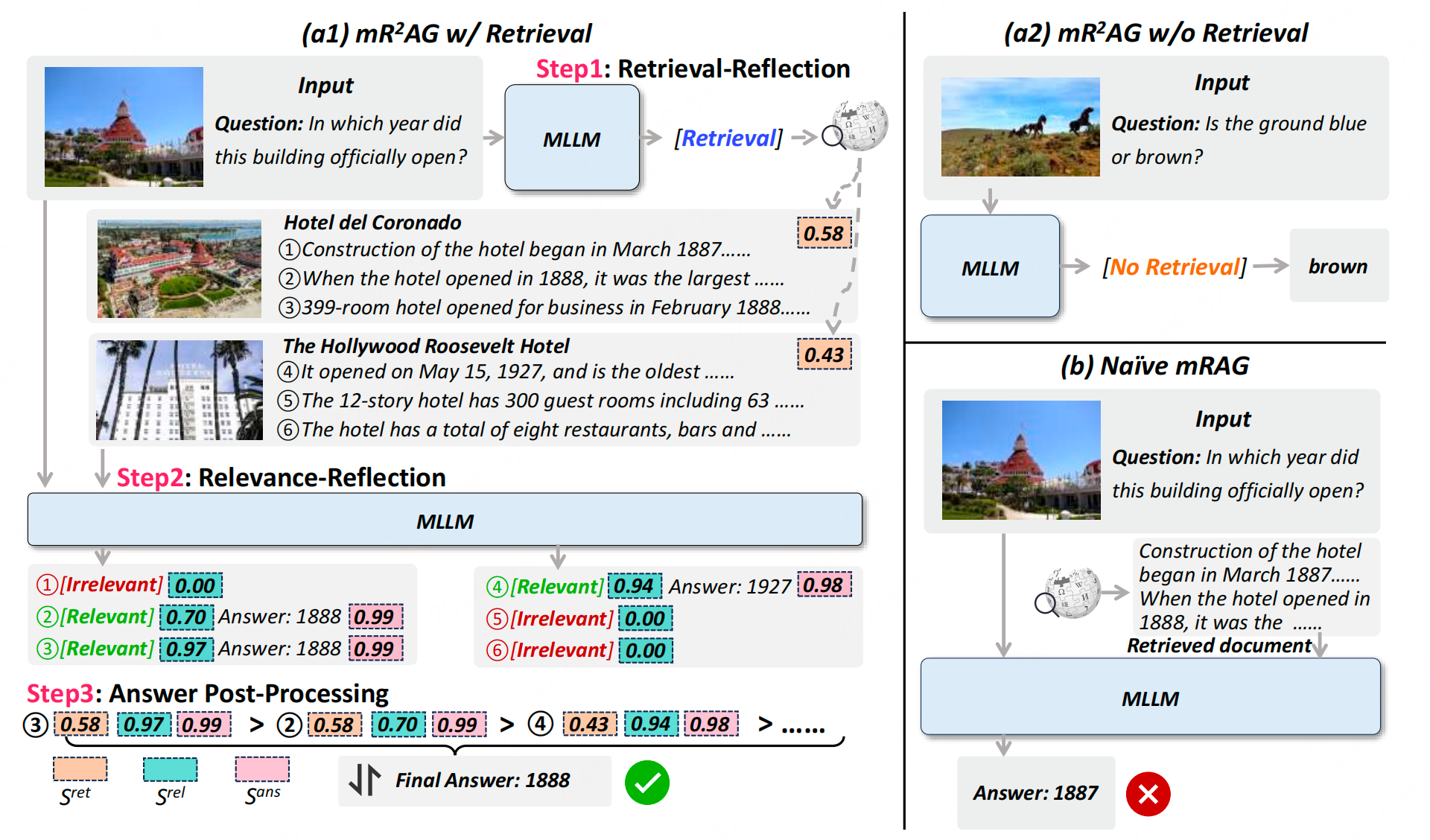
在基于知识的视觉问答(Knowledge-based VQA)任务中,输入通常是一对图像和问题 ( I , Q ) (I, Q) (I,Q),并且依赖于可访问的知识库。文章提出的 m R 2 A G mR^2AG mR2AG框架通过两个新颖的反思操作来解耦生成过程,从而提高答案的质量。 m R 2 A G mR^2AG mR2AG将生成过程分为三个步骤:执行检索反思(Retrieval-Reflection)以确定是否需要检索,执行相关性反思(Relevance-Reflection)以识别证据段落并生成答案,以及后处理多个候选答案。
方法
检索反思
用户查询可以根据输入 ( I , Q ) (I, Q) (I,Q) 分为依赖视觉 的和基于知识的。为了指导模型区分不同类型的查询,定义了两个特殊标记:Retrieval 和 No Retrieval,用于执行检索反思。具体步骤如下:
-
模型基于输入 ( I , Q ) (I, Q) (I,Q) 生成检索反思预测 y r e t y^{ret} yret:
y r e t = M L L M ( I , Q ) y^{ret} = MLLM(I, Q) yret=MLLM(I,Q) -
根据预测结果执行相关操作:
- 如果 y\^{ret} = No Retrieval,模型确定问题可以通过视觉内容回答,不需要外部知识。模型在条件 y\^{ret} = No Retrieval 下,结合 ( I , Q ) (I, Q) (I,Q) 生成答案 y a n s y^{ans} yans:
y a n s = M L L M ( I , Q , y r e t = N o R e t r i e v a l ) y^{ans} = MLLM(I, Q, y^{ret}=No Retrieval) yans=MLLM(I,Q,yret=NoRetrieval) - 如果 y\^{ret} = Retrieval,模型识别到需要外部知识来回答问题,并调用检索器协助进一步的生成过程。
- 如果 y\^{ret} = No Retrieval,模型确定问题可以通过视觉内容回答,不需要外部知识。模型在条件 y\^{ret} = No Retrieval 下,结合 ( I , Q ) (I, Q) (I,Q) 生成答案 y a n s y^{ans} yans:
-
检索过程 :使用英文维基百科条目作为知识库,其中第 k k k 个条目包含候选图像 I ^ k \hat{I}{k} I^k、标题 T ^ k \hat{T}{k} T^k 和文章 P ^ k \hat{P}{k} P^k。 m R 2 A G mR^2AG mR2AG 结合跨模态和单模态检索来选择与查询图像 I I I 最相关的维基百科条目。使用 CLIP 对 I I I、 I ^ k \hat{I}{k} I^k 和 T ^ k \hat{T}{k} T^k 进行编码,并计算 sim ( I , I ^ k ) \operatorname{sim}(I, \hat{I}{k}) sim(I,I^k) 和 sim ( I , T ^ k ) \operatorname{sim}(I, \hat{T}{k}) sim(I,T^k) 的余弦相似度。第 k k k 个条目的整体检索分数 S k r e t S{k}^{ret} Skret 是两个余弦相似度的平均值 :
S k r e t = ( sim ( I , I ^ k ) + sim ( I , T ^ k ) ) / 2 S_{k}^{ret} = \left(\operatorname{sim}(I, \hat{I}{k}) + \operatorname{sim}(I, \hat{T}{k})\right) / 2 Skret=(sim(I,I^k)+sim(I,T^k))/2假设结果 P ^ = { P ^ i } i = 1 N \hat{P} = \{\hat{P}{i}\}{i=1}^{N} P^={P^i}i=1N 对应于检索分数最高的 top-N 的文章。
相关性反思
将每个检索到的文章 P ^ i \hat{P}{i} P^i 分成多个段落。为了使模型能够确定每个分段段落 P ^ i j \hat{P}{ij} P^ij 是否包含与问题 Q Q Q 相关的证据,也引入两个相关性反思标记:Relevant 和 Irrelevant。具体步骤如下:
-
模型在条件 P ^ i j \hat{P}{ij} P^ij 和查询 ( I , Q ) (I, Q) (I,Q) 的组合下生成相关性反思预测 y i j r e l y{ij}^{rel} yijrel:
y i j r e l = M L L M ( I , Q , P ^ i j ) y_{ij}^{rel} = MLLM(I, Q, \hat{P}_{ij}) yijrel=MLLM(I,Q,P^ij) -
根据预测结果执行操作:
- 如果 y_{ij}\^{rel} = Irrelevant,表明模型认为 P ^ i j \hat{P}_{ij} P^ij 与查询无关且缺乏足够的证据,提示模型终止生成过程,避免产生不可靠的答案。
- 如果 y_{ij}\^{rel} = Relevant,模型认为 P ^ i j \hat{P}{ij} P^ij 与查询相关,包含有助于生成答案的证据,因此继续基于 ( I , Q , P ^ i j , y i j r e l = Relevant ) (I, Q, \hat{P}{ij}, y_{ij}^{rel}=\\text{Relevant}) (I,Q,P^ij,yijrel=Relevant) 生成答案 y i j ans y_{ij}^{\text{ans}} yijans:
y i j ans = M L L M ( I , Q , P ^ i j , y i j rel = Relevant ) y_{ij}^{\text{ans}} = MLLM(I, Q, \hat{P}{ij}, y{ij}^{\text{rel}}=\\text{Relevant}) yijans=MLLM(I,Q,P^ij,yijrel=Relevant)
答案后处理
在一个文章中可能存在多个证据段落,导致生成多个候选答案。因此,后处理是必要的,以便得出一个最终的答案。
层级后处理:使用层级后处理来通过整合三个级别的分数对候选答案进行排序:
- 条目级别 :检索分数在方程 (3) 中测量查询图像 I I I 和候选维基百科条目之间的相似性,作为第 i i i 个检索到的条目的检索反思分数 S i r e t S_{i}^{ret} Siret。
- 段落级别 :生成 Relevant 相关性反思标记的概率量化模型判断 P ^ i j \hat{P}{ij} P^ij 为证据的信心,可以定义为相关性反思分数 S i j r e l S{ij}^{rel} Sijrel:
S i j r e l = p θ ( y i j r e l = Relevant ∣ I , Q , P ^ i j ) S_{ij}^{rel} = p_{\theta}(y_{ij}^{rel}=\\text{Relevant} \mid I, Q, \hat{P}_{ij}) Sijrel=pθ(yijrel=Relevant∣I,Q,P^ij)
其中 θ \theta θ 表示 MLLM 的参数。 - 答案级别 :计算生成答案序列中每个标记的概率,并使用几何平均数来规范化序列长度变化的影响,得到答案信心分数 S i j a n s S_{ij}^{ans} Sijans:
S i j a n s = p θ ( y i j a n s ) n S_{ij}^{ans} = \sqrtn{p_{\theta}(y_{ij}^{ans})} Sijans=npθ(yijans)
其中 n n n 表示序列长度。这个分数反映了模型基于检索内容和反思标记生成答案的信心。
最后,三个级别的分数综合考虑了答案生成过程中的每一个步骤,分别在条目、段落和答案级别评估候选答案的可靠性。通过计算这三个分数的乘积来整合它们的效果,作为排序候选答案的最终标准。模型输出基于此标准得分最高的答案。
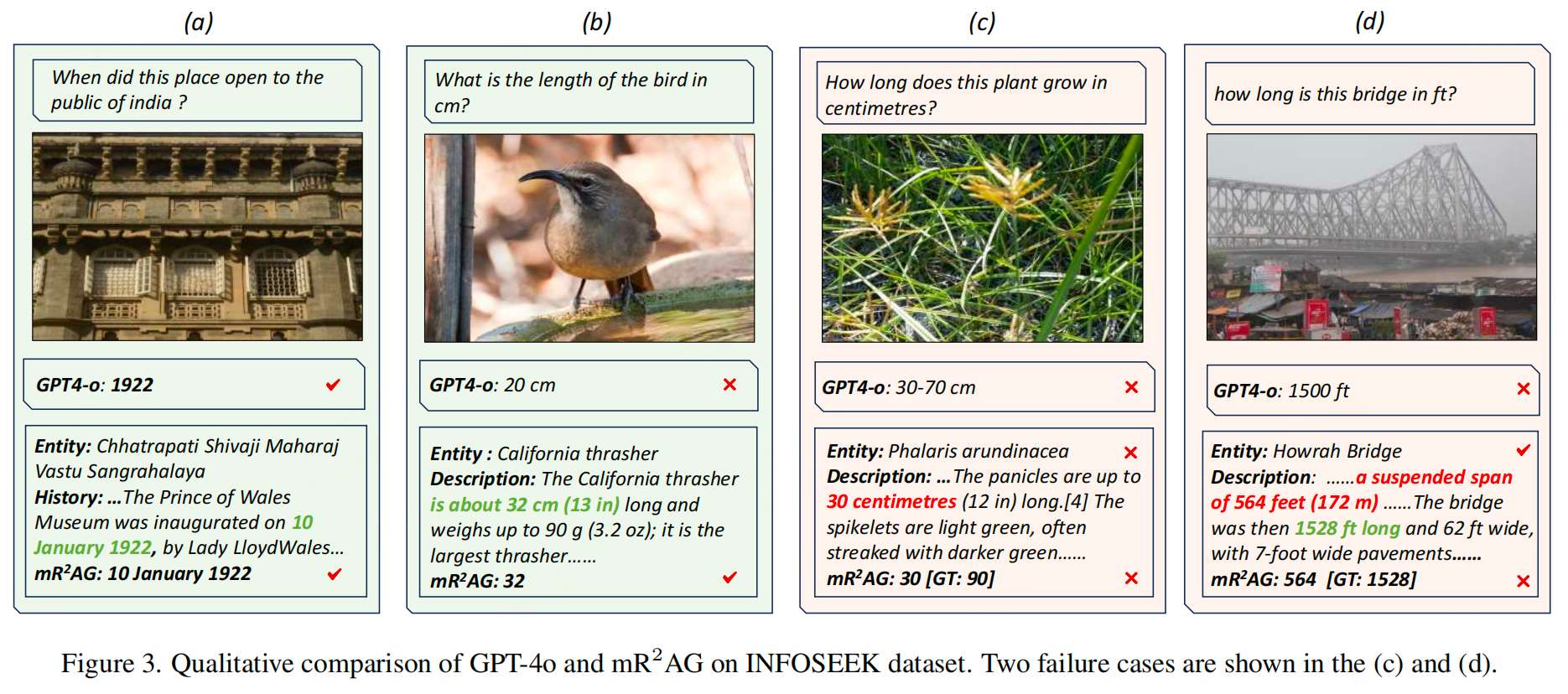
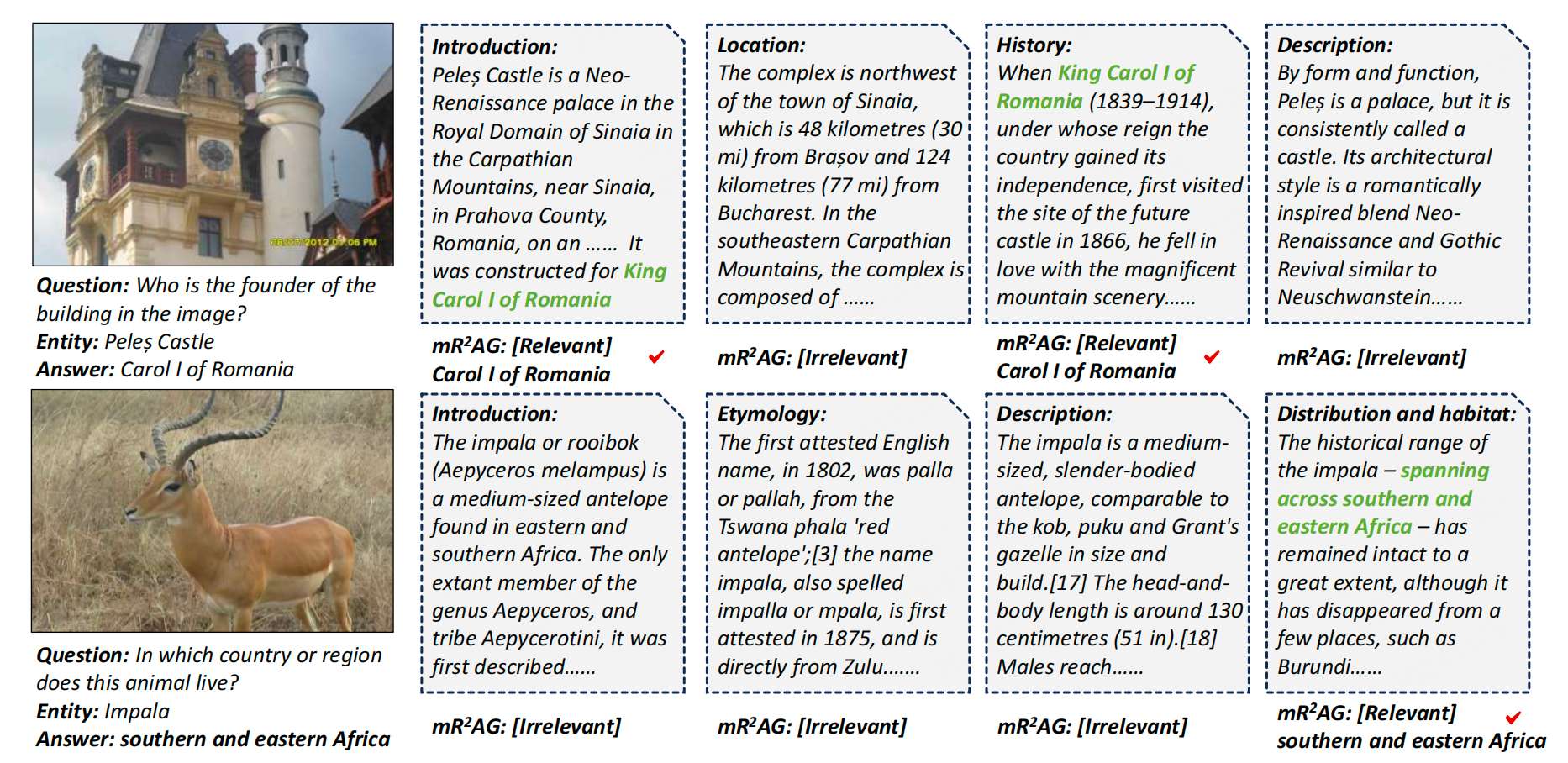
实验


参考文献
mR2AG: Multimodal Retrieval-Reflection-Augmented Generation for Knowledge-Based VQA,https://arxiv.org/pdf/2411.15041