1.self-attention的计算方式?
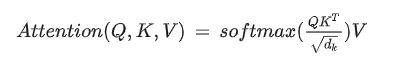
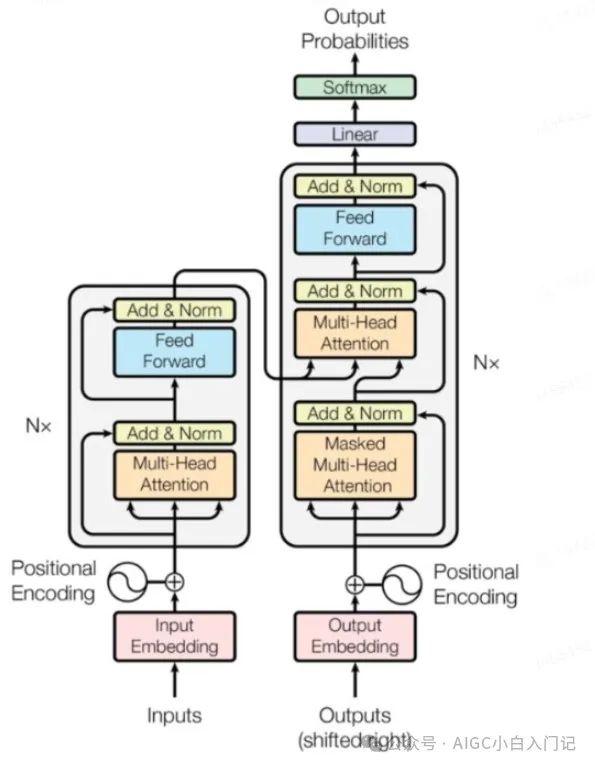
2. 说一下 transformer的模型架构和细节?
3 .说一下大模型高校参数微调方式 p-tuning v2?
P-Tuning V2在P-Tuning V1的基础上进行了下述改进:
- 在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这与Prefix Tuning的做法相同。这样得到了更多可学习的参数,且更深层结构中的Prompt能给模型预测带来更直接的影响。
- 去掉了重参数化的编码器。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现。
- 针对不同任务采用不同的提示长度。提示长度在提示优化方法的超参数搜索中起着核心作用。在实验中,我们发现不同的理解任务通常用不同的提示长度来实现其最佳性能,这与Prefix-Tuning中的发现一致,不同的文本生成任务可能有不同的最佳提示长度。
- 可选的多任务学习。先在多任务的Prompt上进行预训练,然后再适配下游任务。一方面,连续提示的随机惯性给优化带来了困难,这可以通过更多的训练数据或与任务相关的无监督预训练来缓解;另一方面,连续提示是跨任务和数据集的特定任务知识的完美载体。
4. 在 大模型任务中,你用到 LoRA,讲一下 LoRA 实现原理?
LoRA 的思想很简单:
- 在原始 PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的intrinsic rank。
- 训练的时候固定 PLM 的参数,只训练降维矩阵 A 与升维矩阵 B 。而模型的输入输出维度不变,输出时将 BA 与 PLM 的参数叠加。
- 用随机高斯分布初始化 A ,用 0 矩阵初始化 B ,保证训练的开始此旁路矩阵依然是 0 矩阵。
Leetcode 题
具体题意记不清了,但是类似 【两数之和】
- 题目内容
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = 2,7,11,15, target = 9 输出:0,1 解释:因为 nums0 + nums1 == 9 ,返回 0, 1 。
示例 2:
输入:nums = 3,2,4, target = 6 输出:1,2
示例 3:
输入:nums = 3,3, target = 6 输出:0,1
提示:
2 <= nums.length <= 10**4
-109 <= numsi <= 109
-109 <= target <= 109
- 代码实现

如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习还有100套面试题等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。