✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨
🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:传知代码论文复现
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙




目录
本文所有资源均可在该地址处获取。
概述
NeRF (Neural Radiance Fields)是一种神经辐射场,用于将图像转换为3D场景表示。然而,在不同分辨率的训练或测试图像观察场景内容时,NeRF的渲染过程可能会产生过度模糊或伪影的图像。对于传统NeRF来说,使用多条光线对每个像素进行超采样的渲染方案是不实际的,因为渲染每条光线需要对MLP进行数百次查询。
本文提出的mip-NeRF模型,将NeRF扩展到连续值尺度上。通过向像素点投射一个锥形区域(而非光线)进行采样,mip-NeRF减少了伪影的产生,显著提高了NeRF对细节的表示能力,同时比NeRF快7%,仅为NeRF的一半大小。与NeRF相比,mip-NeRF在NeRF呈现的数据集上的平均误差率降低了17%,在多尺度变体数据集上降低了60%。此外,mip-NeRF还拥有与超采样NeRF相当的准确性,而速度快22倍。
原理介绍
传统NeRF的原理
NeRF使用一个连续的5D函数来表示场景,并使用少量的输入视图来优化这个函数以生成复杂场景的新视角。NeRF使用基于MLP的全连接神经网络 来表示场景,输入为一个连续的5D坐标,包括空间位置(x,y,z)和观察视角(θ, φ) ,输出为该空间位置的体密度σ 和与视角相关的RGB颜色。通过沿着相机射线查询MLP并使用经典的体渲染技术将输出颜色和密度投影到图像中来生成新视图。
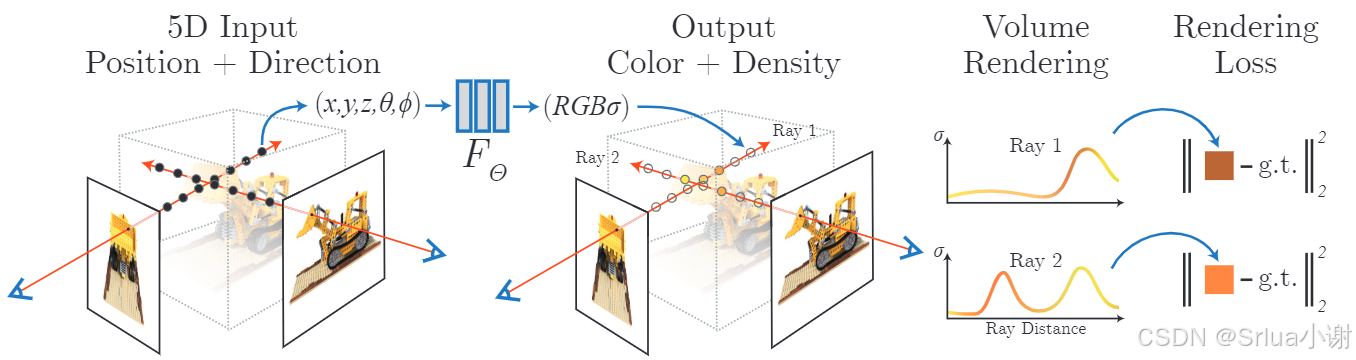
mip-NeRF的改进
- 使用圆锥追踪代替光线追踪,从而显著改善了抗锯齿(伪影)效果。
- 使用集成位置编码 (IPE)特征代替传统的位置编码(PE)特征,实现了更高效的采样和尺度编码。
- 通过单一的多尺度模型(而不是NeRF中的每个尺度单独的模型),使得mip-NeRF的准确性、效率和简单性都得到了提高。
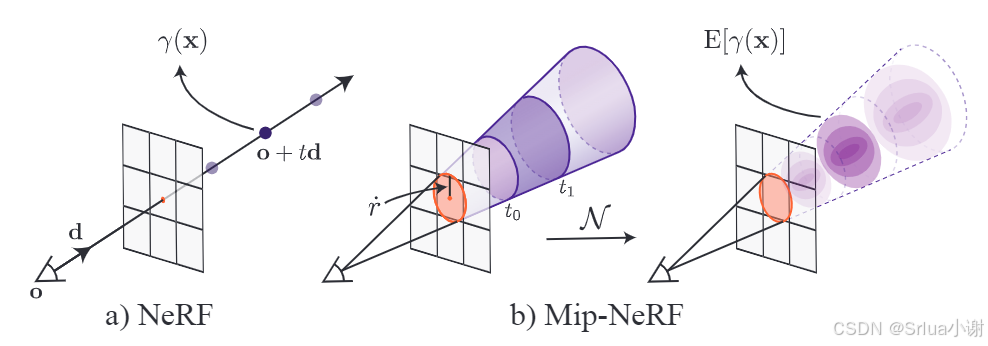
模型介绍
Mip-NeRF是一种用于解决神经辐射场(NeRF)中降采样和抗锯齿问题的改进模型,模型的处理过程如下:
- 对于场景中的每个像素,从相机的中心沿着像素中心的方向投射一个圆锥。
- 计算每个采样间隔的集成位置编码(IPE)特征,作为多层感知机(MLP)的输入。
- MLP输出密度和颜色,用于渲染场景。
复现过程
笔者使用的硬件和系统环境如下:
- 显卡使用RTX4090 24G(实际使用15.25G左右)
- CPU:I9-10900X
- 主存:46.8G
- linux系统(ubuntu20.04.1-desktop)
*以上环境非最低要求,但尽量保证显卡显存16G以上 ,尽量使用linux桌面版系统
读者还需确保环境已正确安装nvidia显卡驱动 (使用nvidia-smi命令能正常输出显卡信息)
我们基于pytorch框架的代码实现进行复现,有利于学习和环境搭建。
安装环境
-
克隆项目源码
# 使用git克隆源码(笔者发现该源码由于作者更新过以后出现了些bug, # 笔者已经fork到自己的仓库,并修复了bug,推荐大家直接clone笔者的仓库) # git clone https://github.com/hjxwhy/mipnerf_pl.git #原作者仓库 git clone https://github.com/Ryan2ky/mipnerf_pl.git # 进入项目目录 cd mipnerf_pl用conda创建虚拟环境
# 创建虚拟环境(推荐python版本为3.9.12)
conda create --name mipnerf python=3.9.12
# 激活环境
conda activate mipnerf
# 安装最新版的pip工具
conda install pip
pip install --upgrade pip
# 使用pip安装依赖库
pip install -r requirements.txt注意:如果读者使用的linux环境不支持桌面GUI,请将requirements.txt中的opencv-python==4.5.4.58依赖改为无头版本的opencv-python-headless==4.5.4.58
3. 安装pytorch依赖
可以前往地址根据自己的操作系统环境选择合适的pytorch版本:
注意:pytorch的cuda工具包版本应根据显卡所支持的cuda版本选择(可使用nvidia-smi命令查看)
(一般应满足:pytorch+cuda版本 <= Cuda版本)
执行安装命令:
pip3 install torch torchvision torchaudio准备数据
-
在项目根目录中创建一个
data目录用来存放训练数据 -
我们使用谷歌官方的NeRF数据集(下载链接见附件
README.md中的Dataset 小节)进行实验,将nerf_synthetic.zip下载并解压到data目录下 -
将
nerf_synthetic数据集转换成多尺寸mipmap数据集python datasets/convert_blender_data.py --blender_dir ./data/nerf_synthetic --out_dir ./data/multiscale
至此,我们拥有了2个数据集,结构如下:
- data
- nerf_synthetic(单一尺寸Blender数据集)
- multiscale(多尺寸Blender数据集)
训练(train)
我们以lego这一数据集为例,进行单尺寸和多尺寸的训练:
-
配置
我们可以在
configs文件夹下配置训练的参数,默认使用的是configs/default.yaml,其中已经配置好了lego场景的参数,我们可以复制一份到lego-multiscale.yaml,并修改exp_name为lego_multiscale加以区分。读者还可以根据需求配置一些其他的参数,例如:check_interval:验证并保存模型的频率,该参数表示每经过一定步数,即进行一次验证,并保存模型到ckpt文件夹下。resume_path:从ckpt恢复模型以继续训练,首次训练时应当设为None表示无需从ckpt恢复。
-
训练
# 训练单一尺寸数据集 python train.py --out_dir ./out --data_path ./data/nerf_synthetic/lego --dataset_name blender # 训练多尺寸数据集 python train.py --out_dir ./out --data_path ./data/multiscale/lego --dataset_name multi_blender --config ./config/lego-multiscale.yaml -
中断与恢复
默认配置下,训练会不断进行(不超过
max_steps),当认为差不多时,可以手动ctrl+c终止训练。训练模型保存在./out/{exp_name}/ckpt中。如果因为异常导致终止,我们也可以从之前保存的ckpt中恢复,只需在配置文件中指定
resume_path为具体的ckpt文件即可。
评估(eval)
#单尺寸模型评估
python eval.py --ckpt ./out/lego/ckpt/last.ckpt --data ./data/nerf_synthetic/lego --out_dir ./out --scale 1 --save_image
#多尺寸模型评估
python eval.py --ckpt ./out/lego_multiscale/ckpt/last.ckpt --data ./data/multiscale/lego --out_dir ./out --scale 4 --save_image评估结果存放在./out/{exp_name}/test下。
渲染(render)
# 单尺寸模型渲染
python render_video.py --ckpt ./out/lego/ckpt/last.ckpt --out_dir ./out --scale 1
# 多尺寸模型渲染
python render_video.py --ckpt ./out/lego_multiscale/ckpt/last.ckpt --out_dir ./out --scale 4渲染结果保存在./out/{exp_name}/render_spheric下。
参考资料
