在 PyTorch 中,Dataset 和 DataLoader 是两个非常重要的类,用于高效地加载和处理数据。它们通常一起使用,以便在训练深度学习模型时更好地管理数据。
详细介绍:Pytorch中的数据加载
1、 DataLoader 类
DataLoader 是一个迭代器,用于从 Dataset 中高效地加载数据。它提供了以下功能:
- 批量加载数据: 可以将数据分成多个小批量(mini-batches)进行加载。
- 多线程加载: 可以使用多个线程并行加载数据,减少 I/O 瓶颈。
- 数据打乱: 可以在每次迭代时打乱数据顺序,以避免模型过拟合。
- 自定义采样策略: 可以通过 Sampler 和 BatchSampler 自定义数据加载的顺序。
DataLoader类官方文档:DataLoader文档
使用 DataLoader 示例
python
from torch.utils.data import DataLoader
# 创建DataLoader
dataloader = DataLoader(dataset, batch_size=4, shuffle=True, num_workers=2)
# 遍历DataLoader
for batch_idx, (samples, labels) in enumerate(dataloader):
print(f"Batch {batch_idx}:")
print(f"Samples: {samples}, Labels: {labels}")参数说明
- dataset: 需要加载的数据集,通常是 Dataset 类的实例。
- batch_size: 每个批次的样本数量。
- shuffle: 是否在每个 epoch 打乱数据顺序。
- num_workers: 用于数据加载的子进程数量。如果设置为 0,则数据加载在主进程中进行。
总结
- Dataset 类用于定义数据集的结构和如何访问数据。
- DataLoader 类用于高效地加载数据,支持批量加载、多线程加载和数据打乱等功能。
结合使用 Dataset 和 DataLoader 可以让你在训练深度学习模型时更加高效地处理数据。
2、DataLoader实例
2.1 准备数据集并预处理数据集
torchvision及其内置数据集(CIFAR10)介绍见:torchvision中数据集的使用
transforms的使用见:Pytorch中的Transforms学习
python
import torchvision
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",
train=False,
transform=torchvision.transforms.ToTensor())
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(img)
print(target)程序将CIFAR10中的测试集PIL图像数据转换为tensor形式(transform=torchvision.transforms.ToTensor()),得到张量形式的img和对应的target,打印img的形状以及img和其taeget。
运行结果:
img是一个3X32X32的张量图像
python
torch.Size([3, 32, 32])
tensor([[[0.6196, 0.6235, 0.6471, ..., 0.5373, 0.4941, 0.4549],
[0.5961, 0.5922, 0.6235, ..., 0.5333, 0.4902, 0.4667],
[0.5922, 0.5922, 0.6196, ..., 0.5451, 0.5098, 0.4706],
...,
[0.2667, 0.1647, 0.1216, ..., 0.1490, 0.0510, 0.1569],
[0.2392, 0.1922, 0.1373, ..., 0.1020, 0.1137, 0.0784],
[0.2118, 0.2196, 0.1765, ..., 0.0941, 0.1333, 0.0824]],
[[0.4392, 0.4353, 0.4549, ..., 0.3725, 0.3569, 0.3333],
[0.4392, 0.4314, 0.4471, ..., 0.3725, 0.3569, 0.3451],
[0.4314, 0.4275, 0.4353, ..., 0.3843, 0.3725, 0.3490],
...,
[0.4863, 0.3922, 0.3451, ..., 0.3804, 0.2510, 0.3333],
[0.4549, 0.4000, 0.3333, ..., 0.3216, 0.3216, 0.2510],
[0.4196, 0.4118, 0.3490, ..., 0.3020, 0.3294, 0.2627]],
[[0.1922, 0.1843, 0.2000, ..., 0.1412, 0.1412, 0.1294],
[0.2000, 0.1569, 0.1765, ..., 0.1216, 0.1255, 0.1333],
[0.1843, 0.1294, 0.1412, ..., 0.1333, 0.1333, 0.1294],
...,
[0.6941, 0.5804, 0.5373, ..., 0.5725, 0.4235, 0.4980],
[0.6588, 0.5804, 0.5176, ..., 0.5098, 0.4941, 0.4196],
[0.6275, 0.5843, 0.5176, ..., 0.4863, 0.5059, 0.4314]]])
32.2 使用DataLoader加载数据集
使用上述预处理过的CIFAR10数据集,并设置批次大小为4:
python
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=True)
for data in test_loader:
imgs, targets = data
print(imgs.shape)
print(targets)运行结果:
python
torch.Size([4, 3, 32, 32])
tensor([1, 1, 0, 8])
torch.Size([4, 3, 32, 32])
tensor([6, 0, 7, 9])
torch.Size([4, 3, 32, 32])
tensor([6, 0, 8, 5])
...因为设置的批次大小为4,所以每个批次取4个张量图像和4个对应target打包为一个data。
2.3 使用tensorboard查看数据集
python
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=True)
#记录日志
writer = SummaryWriter("runs")
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("tensor_test_data", imgs, step)
step = step + 1
writer.close()在终端执行命令:
python
tensorboard --logdir=E:\my_pycharm_projects\project1\runs
python
TensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
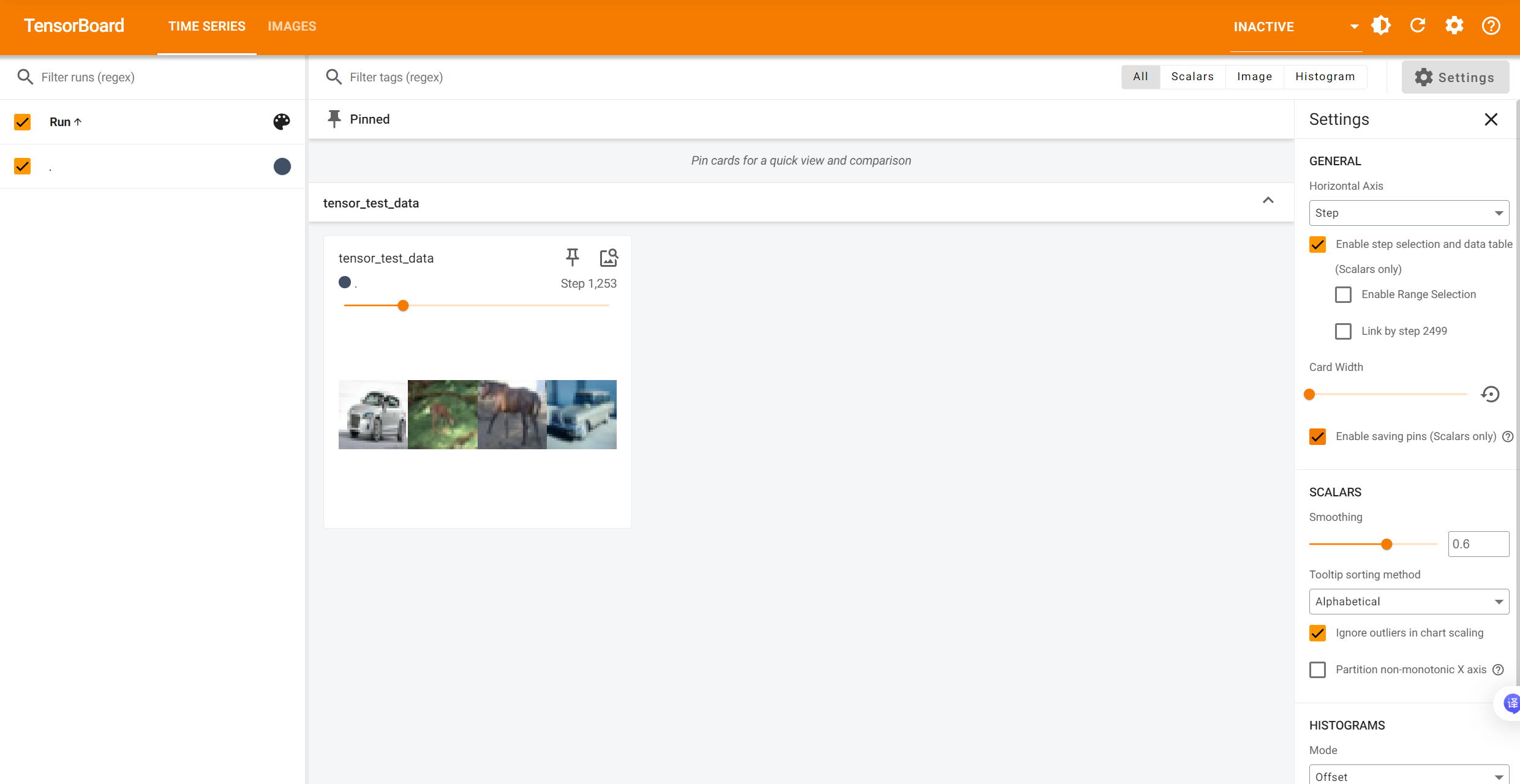
TensorBoard 2.19.0 at http://localhost:6006/ (Press CTRL+C to quit)打开网址:
step表示第几个批次(epoch),在每个批次中都取了4张图片:
2.4 shuffle参数的作用
- 设置shuffle=True
设置两次记录:
python
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=True)
#记录日志
writer = SummaryWriter("runs")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()结果:

可以看到,同样是step=2499批次取4张图片,两次取的图片不一样。
- 设置shuffle=False
同样记录两次:
python
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=False, num_workers=0, drop_last=True)
#记录日志
writer = SummaryWriter("runs")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()结果:
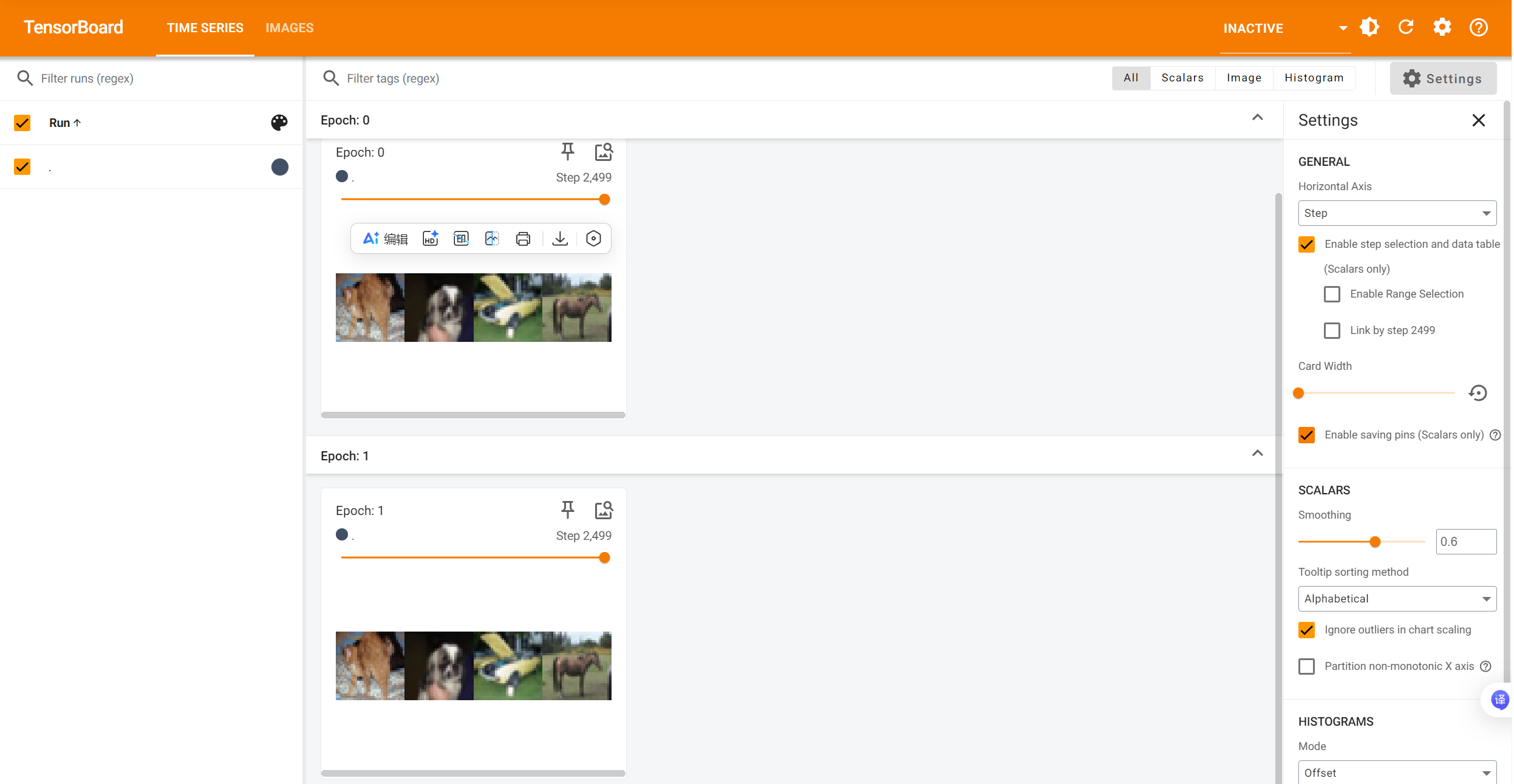

可以看出,在每个step批次取4张图片,两次取的结果都是一样的。
因此,在实际中一般设置shuffle=True。