在分布式系统中,生成全局唯一且高效的 ID 是一个不可忽视的问题。如何在多个节点上同时生成唯一的 ID,同时保证系统的高并发性能,是设计分布式系统时的一个关键考量。本文将详细介绍常见的分布式 ID 生成方式,包括数据库自增 ID、数据库集群模式、UUID、Redis、雪花算法、号段模式以及美团 Leaf,并对每种方法进行深入分析,帮助开发者根据业务需求选择合适的方案。
一、分布式ID说明
1. 什么是分布式ID?
分布式ID是在分布式系统中用于全局唯一标识数据或实体的ID。在单机系统中,数据库自增ID即可满足需求,但在分布式场景(如分库分表、多节点部署)下,单节点生成的自增ID可能重复,无法保证全局唯一性。例如,分库分表后,不同数据库节点的自增主键可能冲突,因此需要一种跨节点、跨服务的唯一ID生成机制,即分布式ID
2. 为什么要用分布式ID?
核心原因
- 解决数据唯一性问题:在分布式系统中,数据可能分散在不同节点、数据库甚至地理位置,传统单机ID生成方式无法保证全局唯一性,导致数据冲突
- 支持系统扩展性:随着数据量增长,分库分表、多活部署等架构优化成为必要,分布式ID是这些场景下数据管理和查询的基础
典型应用场景
- 分库分表:同一业务表拆分到多个物理库表时,需全局唯一ID标识数据
- 多活部署:跨区域部署的系统需要ID包含区域属性,以支持数据路由和聚合
- 链路跟踪:微服务架构中,需全局唯一的TraceID关联全链路调用日志
- 高并发业务:如订单、支付单等高频业务需高效生成唯一ID,避免性能瓶颈
3. 分布式ID需要满足的条件
基本要求
- 全局唯一性:必须确保不同节点、时间生成的ID绝不重复(核心要求)
- 高可用性:ID生成服务需接近100%可用,支持容灾和动态扩容
- 易用性:开箱即用,接入成本低,无需复杂配置
进阶要求
- 有序性:ID趋势递增(如时间戳排序),便于数据库写入和查询优化
- 安全性:ID不暴露敏感信息(如机器IP、业务量规律)
- 可扩展性:支持动态调整ID规则(如业务前缀、随机尾号)
- 低存储开销:尽量缩短ID长度(如64位Long类型优于128位UUID),减少数据库索引压力
二、数据库自增ID
在分布式系统下,如果数据量不大的情况下,可以使用一个单独的MySQL实例来生成ID,通过自增主键生成唯一 ID。例如,使用 MySQL 或 PostgreSQL 的自增字段,系统自动为每一行数据生成一个唯一的主键。
优点:
-
简单易用:无需额外的配置和复杂的算法。
-
可靠性强:由于数据库本身具备事务和并发控制,因此生成 ID 具有很高的可靠性。
缺点:
-
性能瓶颈:数据库每次需要获取新的自增 ID 时,会产生一次数据库操作,这对于高并发系统可能成为瓶颈。
-
跨节点问题:在分布式数据库或多个节点的情况下,如何保证 ID 唯一性变得复杂。
三、数据库集群模式
为了避免单数据库节点的性能瓶颈,可以搭建数据库集群模式或者分库分表,但也会带来一些问题,比如,多个数据库实例生成重复的id怎么解决?解决方案就是设置不同的初始值和步长。
例如双主集群中,主库1生成奇数ID(1/3/5...),主库2生成偶数ID(2/4/6...)。
// 第一个MySQL实例设置
set @@auto_increment_offset = 1; -- 起始值
set @@auto_increment_increment = 2; -- 步长
// 第二个MySQL实例设置
set @@auto_increment_offset = 2; -- 起始值
set @@auto_increment_increment = 2; -- 步长但如果项目发展迅速,两个实例也扛不住这数据量,需要水平拓展数据库节点,那就需要人工修改前面的数据库实例的步长和初始值,将第三台的ID初始值设定在比现有的ID大的位置上,设置不一样的步长,必要时需要停机修改。
// 第一个MySQL实例设置
set @@auto_increment_offset = 10001; -- 起始值
set @@auto_increment_increment = 3; -- 步长
// 第二个MySQL实例设置
set @@auto_increment_offset = 20002; -- 起始值
set @@auto_increment_increment = 3; -- 步长
// 第三个MySQL实例设置
set @@auto_increment_offset = 21003; -- 起始值
set @@auto_increment_increment = 3; -- 步长优点:
-
高并发支持: 每个节点都拥有独立的 ID 号段,可以在多个节点并行生成 ID,充分利用数据库集群的分布式特性。
-
灵活的扩展性: 系统可以通过增加数据库节点来水平扩展 ID 生成能力。当负载增大时,可以动态地添加新的节点并分配新的 ID 范围。
-
容错性强: 通过冗余备份机制,数据库集群可以保证在某些节点故障时,其他节点仍然可以继续生成 ID,保证系统的高可用性。
缺点:
-
管理复杂: 在分布式环境下,如何有效地管理各节点的 ID 范围,避免冲突和浪费,增加了管理的复杂性。
-
数据库负载: 每次生成 ID 时都需要访问数据库,尤其是在数据库集群规模较大时,频繁的访问可能会增加数据库的负担。
-
号段分配不均: 如果 ID 范围的分配不均,可能导致某些节点的号段被耗尽,而其他节点还有大量的未用 ID,从而造成资源浪费。
四、UUID
1.简介
UUID(Universally Unique Identifier,通用唯一标识符)是一种标准化的标识符,旨在提供全局唯一的 ID。UUID 是基于时间戳、随机数和机器信息(如 MAC 地址)等生成的 128 位数字,通常表示为 32 位字符,格式为 8-4-4-4-12(例如:550e8400-e29b-41d4-a716-446655440000)。UUID 的关键特性是 全局唯一性,它可以在分布式系统中生成不同节点、不同时间、不同机器的唯一标识符,适用于高并发、高可用的分布式环境。
UUID 的生成方式有多个版本,最常用的是 UUIDv4(基于随机数生成),它生成的 ID 随机且唯一性强。UUID 的生成不依赖于中央服务器或数据库,能够在去中心化的环境中进行并行生成,因此适用于分布式系统。
2.实现
UUID 的生成可以通过大多数编程语言的标准库或第三方库来完成。例如,在 Java 中使用 UUID.randomUUID() 来生成一个 UUID。
Java 示例:
import java.util.UUID;
public class UUIDGenerator {
public static void main(String[] args) {
// 生成一个随机UUID(UUIDv4)
UUID uuid = UUID.randomUUID();
System.out.println("Generated UUID: " + uuid.toString());
}
}输出示例:
9e107d9d-372b-4f16-b5d0-b9cbf51b8bb3
3.优缺点
优点
-
全球唯一性: UUID 的生成方式保证了它的全球唯一性,即使是不同的机器、不同的时间、不同的进程生成的 UUID 也不会重复,避免了分布式系统中的 ID 冲突问题。
-
去中心化: UUID 的生成过程是完全去中心化的,生成 UUID 不依赖于任何中心化的服务或数据库,所有节点都可以独立生成 ID,适用于大规模的分布式系统。
-
生成速度快: UUID 通过简单的算法(例如基于随机数)生成,不依赖外部系统(如数据库),因此它的生成速度非常快。
-
简单易用: 大部分编程语言都提供了生成 UUID 的标准库或工具类,使用起来非常简单,几乎不需要任何额外的配置。
缺点
-
长度较长: UUID 是 128 位长(32个字符),比传统的整型 ID 长,存储和传输时需要更多的空间。这可能导致在存储大量数据时增加存储成本,并且在数据库索引中占用更多的空间。
-
不可排序: UUID 的生成过程是随机的,因此无法保证生成的 UUID 有顺序性。如果需要按时间顺序生成 ID,UUID 的随机特性会导致索引的性能下降,并增加查询延迟。
-
不适合有顺序要求的场景: 如果业务场景中对 ID 的顺序性有要求(例如按时间顺序生成 ID),则 UUID 的随机性可能会影响性能和使用体验。
-
存储开销较大: UUID 占用的存储空间较大,在使用数据库存储大量 UUID 时,可能会增加存储和网络传输的负担,特别是与数字型 ID(如自增 ID)相比,UUID 的存储效率较低。
五、Redis
1.简介
在分布式 ID 生成中,Redis 的 原子自增 操作被广泛用于生成唯一且递增的 ID。
通过 Redis 提供的 INCR(自增)命令,可以在 Redis 中创建一个全局唯一的计数器,利用这个计数器生成分布式系统中的 ID。因为 Redis 是单线程处理命令的,这保证了自增操作的原子性,从而能够有效避免多个客户端生成相同 ID 的问题。
2.实现
Redis 实现分布式 ID 的基本思路是使用 Redis 的 INCR 命令来生成自增 ID。每次请求一个新的 ID 时,应用通过 Redis 服务器调用 INCR 命令,Redis 会返回递增后的 ID 值。
实现步骤:
-
在 Redis 中维护一个计数器,使用
INCR命令生成唯一的自增 ID。 -
如果系统要求全局唯一 ID,可以使用 Redis 集群中的计数器,确保每次生成的 ID 都不重复。
Java 示例:
import redis.clients.jedis.Jedis;
public class RedisIDGenerator {
private Jedis jedis;
public RedisIDGenerator(Jedis jedis) {
this.jedis = jedis;
}
// 生成分布式 ID
public String generateID() {
// 使用 Redis 的 INCR 命令生成自增 ID
long id = jedis.incr("global_id");
return String.valueOf(id);
}
public static void main(String[] args) {
// 连接 Redis
Jedis jedis = new Jedis("localhost", 6379);
RedisIDGenerator idGenerator = new RedisIDGenerator(jedis);
String id = idGenerator.generateID();
System.out.println("Generated ID: " + id);
}
}Redis 关键操作:
INCR key:将指定键的值加 1,并返回加 1 后的值。如果键不存在,会创建该键并初始化为 0。
Redis 内部实现:
INCR命令是原子操作,Redis 保证在高并发环境下,多个客户端调用时每次自增的值都是唯一的。
3.优缺点
优点
-
高性能: Redis 是内存数据库,提供了极高的吞吐量和低延迟,能够高效生成 ID。使用 Redis 的
INCR操作生成 ID 是原子操作,能保证高并发时的准确性。 -
去中心化: Redis 支持多节点部署,在分布式环境下,多个节点都可以独立地生成 ID,且保证全局唯一性,无需集中式协调。
-
支持高并发: Redis 是单线程处理请求,但由于采用内存存储和高效的操作,它能够处理大量的并发请求,非常适合分布式环境。
-
自增 ID 顺序性: Redis 生成的 ID 是递增的,通常是自增序列号,能够提供顺序性的 ID,这在很多场景下是非常有用的。
-
简单实现: 使用 Redis 生成 ID 相对简单,几乎不需要复杂的配置,直接通过 Redis 的原子操作即可完成。
缺点
-
Redis 单点故障: 如果 Redis 服务出现故障,生成 ID 的功能会受到影响,造成整个系统的 ID 生成中断。为此,通常需要部署 Redis 集群来提高可用性,但这也带来了额外的运维成本。
-
依赖性: 依赖外部 Redis 服务,意味着每次生成 ID 时都需要与 Redis 进行通信。如果 Redis 服务不可用,可能会导致 ID 生成失败,从而影响系统的正常运行。
-
性能瓶颈: 如果系统需要生成大量 ID,并且 Redis 服务器的性能有限时,可能会出现性能瓶颈,导致响应时间变慢。在极高并发的环境下,可能需要水平扩展 Redis 集群以应对负载。
-
ID 的长度: Redis 自增生成的 ID 纯粹是数字类型的 ID,对于需要更复杂或包含更多信息(如时间戳、机器 ID)的场景,可能需要结合其他方式生成更复杂的 ID。
-
ID 唯一性保证问题: 如果系统要求生成跨 Redis 实例的全局唯一 ID,则需要考虑 Redis 集群的分布式锁机制等方案,确保 ID 在多个 Redis 实例之间不会重复。
六、雪花算法(SnowFlake)
1.简介
雪花算法(Snowflake ID)是由 Twitter 开源的一种分布式 ID 生成算法,能够在高并发的分布式环境下生成全局唯一且有序的 ID。它的设计思想是在多台机器上生成 ID 时,保证 ID 的唯一性、递增性以及可拓展性。
雪花算法的核心是将 64 位的数字划分为多个字段,其中每个字段存储不同的信息,这样可以确保在分布式环境下,ID 是唯一的。它将时间戳、机器 ID、数据中心 ID、序列号等信息编码在 ID 中,使得生成的 ID 既能保证全局唯一,又能保持一定的时间顺序。
2.实现
雪花算法的基本构成:
64 位 ID 结构 :
1 位符号位:始终为 0,因为生成的 ID 都是正数。
41 位时间戳:表示当前时间的毫秒数,从某个固定的时间起开始计数,能够支持 69 年(2^41 毫秒)。
10 位机器 ID:用于区分不同的机器,最多支持 1024 个节点(2^10)。
12 位序列号:在同一毫秒内生成多个 ID 时,确保 ID 唯一,最多支持每毫秒生成 4096 个 ID(2^12)。
代码实现(Java)
public class SnowflakeIDGenerator {
private final long twepoch = 1288834974657L; // 自定义起始时间戳
private final long machineIdBits = 10L; // 机器ID位数
private final long datacenterIdBits = 5L; // 数据中心ID位数
private final long maxMachineId = -1L ^ (-1L << machineIdBits); // 最大机器ID
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); // 最大数据中心ID
private final long sequenceBits = 12L; // 序列号位数
private final long machineIdShift = sequenceBits; // 机器ID偏移量
private final long datacenterIdShift = sequenceBits + machineIdBits; // 数据中心ID偏移量
private final long timestampLeftShift = sequenceBits + machineIdBits + datacenterIdBits; // 时间戳偏移量
private final long sequenceMask = -1L ^ (-1L << sequenceBits); // 序列号掩码
private long lastTimestamp = -1L; // 上次生成 ID 的时间戳
private long sequence = 0L; // 当前毫秒内的序列号
private long machineId; // 机器 ID
private long datacenterId; // 数据中心 ID
// 构造函数,传入机器 ID 和数据中心 ID
public SnowflakeIDGenerator(long machineId, long datacenterId) {
if (machineId > maxMachineId || machineId < 0) {
throw new IllegalArgumentException("机器ID不能大于 " + maxMachineId + " 或小于 0");
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException("数据中心ID不能大于 " + maxDatacenterId + " 或小于 0");
}
this.machineId = machineId;
this.datacenterId = datacenterId;
}
// 生成唯一的 ID
public synchronized long generateID() {
long timestamp = System.currentTimeMillis(); // 当前时间戳
if (timestamp < lastTimestamp) {
throw new RuntimeException("系统时钟出现倒退!");
}
// 如果是同一毫秒内,生成的 ID 使用序列号递增
if (timestamp == lastTimestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = waitForNextMillis(lastTimestamp); // 序列号用尽,等待下一毫秒
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
// 根据各个部分组合 ID
return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift)
| (machineId << machineIdShift) | sequence;
}
// 等待下一毫秒
private long waitForNextMillis(long lastTimestamp) {
long timestamp = System.currentTimeMillis();
while (timestamp <= lastTimestamp) {
timestamp = System.currentTimeMillis();
}
return timestamp;
}
public static void main(String[] args) {
SnowflakeIDGenerator generator = new SnowflakeIDGenerator(1, 1); // 机器ID=1, 数据中心ID=1
System.out.println(generator.generateID());
}
}3.优缺点
优点:
-
高效: 雪花算法利用了 64 位位运算,生成 ID 的速度非常快,可以在高并发环境下生成大量的唯一 ID。
-
全局唯一性: 通过时间戳、机器 ID、数据中心 ID 和序列号的组合,确保了每个生成的 ID 在分布式系统中是全局唯一的。
-
有序性: 生成的 ID 基本按时间顺序递增,这对于需要顺序性 ID(如订单号、日志编号等)非常有用。
-
可扩展性: 雪花算法支持分布式部署,可以在多个节点上使用不同的机器 ID 和数据中心 ID,能够适应高并发和大规模的分布式应用。
缺点:
-
时钟回退问题: 雪花算法依赖系统时钟,如果系统时间回退(例如通过 NTP 同步),可能会导致生成的 ID 重复或不连续。因此,在生成 ID 时需要保证系统时钟的稳定性。
-
精度问题: 如果每毫秒内的请求数量非常多,ID 的生成会遇到序列号溢出的情况(最大为 4095)。虽然可以通过等待下一毫秒来解决,但这会导致延迟,影响性能。
-
ID 长度: 由于 ID 包含时间戳、机器 ID、数据中心 ID 和序列号等多个字段,生成的 ID 长度较长(64 位),可能会影响存储和传输性能。
-
部署复杂性: 需要为每个节点分配唯一的机器 ID 和数据中心 ID,这在大规模的分布式环境中可能带来一定的管理复杂性。
七、号段模式
1.简介
号段模式 (Segment Mode)是一种通过数据库批量预取ID区间并缓存在本地使用的分布式ID生成方案。其核心思想是减少对数据库的直接访问频率,提升ID生成效率。该模式在高并发场景(如电商订单、支付系统)中被广泛应用,例如滴滴的TinyID和美团Leaf均采用此模式优化
2.实现
(1)数据库表设计 创建全局ID序列表,记录业务类型、当前最大ID、步长(每次预取的ID数量)及版本号(用于并发控制)。示例如下:
CREATE TABLE `sequence_id_generator` (
`id` int(10) NOT NULL,
`current_max_id` bigint(20) NOT NULL COMMENT '当前最大ID',
`step` int(10) NOT NULL COMMENT '号段长度',
`version` int(20) NOT NULL COMMENT '版本号(乐观锁)',
`biz_type` int(20) NOT NULL COMMENT '业务类型',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;current_max_id:已分配的最大ID值。step:每次预取的ID数量(如5000)。version:通过乐观锁(CAS)解决并发更新冲突。
(2)预选号段
- 首次获取 :服务启动时查询数据库,获取当前业务(如
biz_type=101)的current_max_id和step,并更新数据库中的current_max_id为current_max_id + step,同时版本号version+1。 - 后续更新:本地缓存号段(如1, 5000)用完后,再次执行上述操作获取新号段。
(3)本地缓存和分配
- 将预取的号段缓存在JVM内存中,直接分配本地ID,避免每次请求访问数据库。
- 优化策略:
- 双Buffer机制:预加载两个号段,一个使用中,另一个异步预取,避免号段耗尽时的延迟
- 动态调整步长 :根据业务峰值调整
step,平衡数据库压力与号段浪费。
3.优缺点
优点:
- 高性能:通过本地缓存减少数据库访问频率(如步长5000时,数据库压力降低至1/5000)
- 趋势递增:ID按批次递增,适合数据库索引优化(如B+树有序插入)
- 高可用性:即使数据库短暂不可用,本地缓存仍能支撑一段时间
- 扩展性强:支持多服务实例并行申请不同号段,天然适应分布式架构
缺点:
- 号段浪费:服务重启可能导致未使用的缓存ID失效,导致ID不连续(可通过合理设置步长缓解)
- 并发竞争:多服务同时更新同一业务号段需依赖乐观锁(版本号)或数据库行锁,增加复杂度
- 依赖数据库:仍需要数据库作为ID分配中心,存在单点故障风险(可通过数据库集群优化)
八、美团Leaf
1.简介
美团Leaf是美团点评开源的分布式ID生成系统,旨在解决分布式场景下全局唯一ID生成的需求。其核心设计目标是 高性能、高可用、低延迟,支持两种主流模式:
- 号段模式(Segment Mode):通过数据库批量预取ID区间,减少数据库访问压力,适合高并发场景
- Snowflake模式:基于Twitter Snowflake算法改进,生成趋势递增的64位ID,适合无中心化部署的场景
Leaf广泛应用于美团的金融、支付、订单等核心业务,日均生成ID量级达万亿 。其名称源自莱布尼茨的名言"世界上没有两片相同的树叶",寓意生成的ID全局唯一。
官方技术文档:Leaf------美团点评分布式ID生成系统 - 美团技术团队
2.实现原理
号段模式采用的是基于MySQL数据生成id的,它并不是基于MySQL表中的自增长实现的,因为基于MySQL的自增长方案对于数据库的依赖太大了,性能不好,Leaf的号段模式是基于一张表来实现,每次获取一个号段,生成id时从内存中自增长,当号段用完后再去更新数据库表,如下:
CREATE TABLE `leaf_alloc` (
`biz_tag` VARCHAR(128) PRIMARY KEY, // 业务标签,用来区分业务
`max_id` BIGINT NOT NULL, // 目前所被分配的ID号段的最大值
`step` INT NOT NULL, // 每次分配的号段长度
`description` VARCHAR(256), // 描述
`update_time` TIMESTAMP // 更新时间
);Leaf架构图:
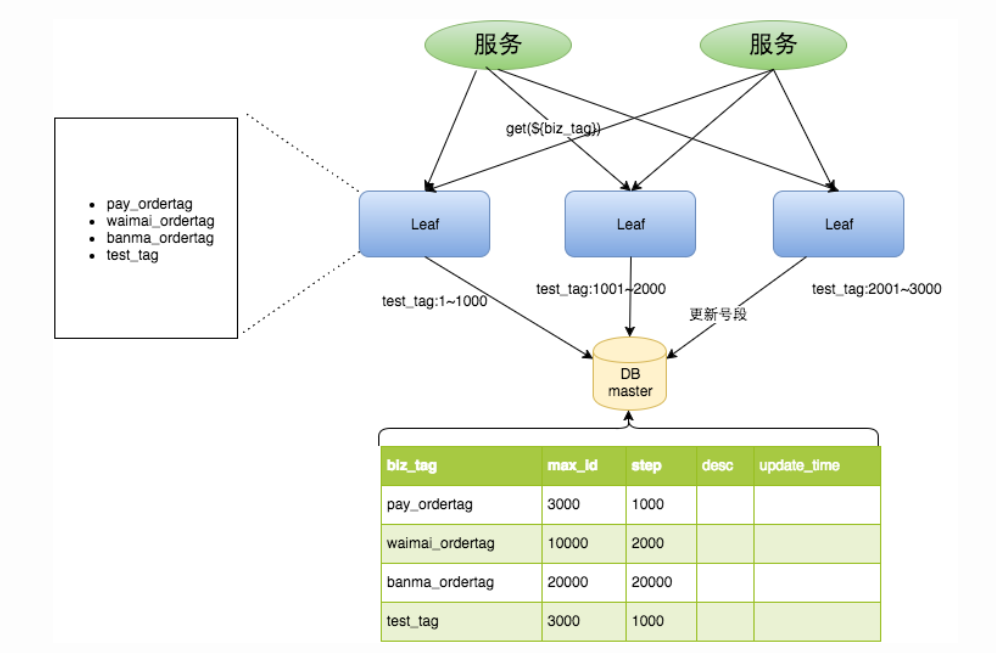 图片来源: Leaf------美团点评分布式ID生成系统 - 美团技术团队
图片来源: Leaf------美团点评分布式ID生成系统 - 美团技术团队
说明:test_tag在第一台Leaf机器上是1~1000的号段,当这个号段用完时,会去加载另一个长度为step=1000的号段,假设另外两台号段都没有更新,这个时候第一台机器新加载的号段就应该是3001~4000。同时数据库对应的biz_tag这条数据的max_id会从3000被更新成4000,更新号段的SQL语句如下:
update order_table set max_id = max_id + step where biz_tag == order
select tag, max_id, step from order_table where biz_tag == orderLeaf 取号段的时机是在号段消耗完的时候进行的,也就意味着号段临界点的ID下发时间取决于下一次从DB取回号段的时间,并且在这期间进来的请求也会因为DB号段没有取回来,导致线程阻塞。如果请求DB的网络和DB的性能稳定,这种情况对系统的影响是不大的,但是假如取DB的时候网络发生抖动,或者DB发生慢查询就会导致整个系统的响应时间变慢。
Leaf为此做了优化,增加了双buffer优化。
 图片来源: Leaf------美团点评分布式ID生成系统 - 美团技术团队
图片来源: Leaf------美团点评分布式ID生成系统 - 美团技术团队
3.代码实现
实体类(映射数据库字段):
public class LeafAlloc {
private String bizTag; // 业务标识(如"order")
private Long maxId; // 当前最大ID
private Integer step; // 号段步长
// 其他字段及getter/setter
}数据库操作DAO层(使用乐观锁更新号段)
public class LeafAllocDAO {
public LeafAlloc updateMaxId(String bizTag) {
// 1. 查询当前号段信息
LeafAlloc current = queryByBizTag(bizTag);
// 2. 乐观锁更新
int rows = jdbcTemplate.update(
"UPDATE leaf_alloc SET max_id = max_id + step, update_time = NOW() " +
"WHERE biz_tag = ? AND max_id = ?",
bizTag, current.getMaxId()
);
if (rows == 0) {
throw new OptimisticLockingFailureException("并发更新冲突");
}
// 3. 返回更新后的号段
return queryByBizTag(bizTag);
}
}SegmentBuffer管理类(线程安全设计)
public class SegmentBuffer {
private volatile Segment current; // 当前使用的号段
private volatile Segment next; // 预加载的备用号段
private final Object switchLock = new Object();
// 获取下一个ID
public synchronized long nextId() {
if (current == null || !current.hasRemaining()) {
synchronized (switchLock) {
if (current == null || !current.hasRemaining()) {
// 切换Buffer并异步加载新号段
current = next;
next = null;
loadNextSegmentAsync();
}
}
}
return current.nextId();
}
// 异步预加载下一个号段
private void loadNextSegmentAsync() {
executor.submit(() -> {
LeafAlloc newSegment = leafAllocDAO.updateMaxId(bizTag);
next = new Segment(newSegment.getMaxId(), newSegment.getStep());
});
}
}根据流量自动调整步长(如QPS翻倍时步长倍增)
public void adjustStep(String bizTag, int currentQps) {
LeafAlloc alloc = leafAllocDAO.queryByBizTag(bizTag);
int newStep = alloc.getStep();
if (currentQps > alloc.getStep() * 0.8) { // 流量达到步长的80%
newStep = alloc.getStep() * 2; // 步长翻倍
}
leafAllocDAO.updateStep(bizTag, newStep);
}完整调用示例
// 初始化服务
LeafAllocDAO dao = new LeafAllocDAO(dataSource);
SegmentBuffer buffer = new SegmentBuffer(dao, "order");
// 获取ID
long id = buffer.nextId(); // 返回如1001、1002...4.优缺点
| 方案 | 性能 | 有序性 | 连续性 | 复杂度 | 适用场景 |
|---|---|---|---|---|---|
| Leaf号段 | 极高 | 趋势递增 | 不连续 | 中 | 高并发订单、支付系统 |
| Leaf雪花 | 高 | 时间有序 | 不连续 | 高 | 日志追踪、分布式链路 |
| UUID | 高 | 无序 | 不连续 | 低 | 临时标识、低并发场景 |
| 数据库自增 | 低 | 严格递增 | 连续 | 低 | 小规模单机系统 |
九、总结
分布式 ID 生成方法各有优缺点,不同的业务场景和系统要求会影响最终的选择。对于高并发和分布式环境,雪花算法和号段模式通常是首选方案,而对于快速生成全局唯一标识符,UUID 和 Redis 自增 ID 则较为适合。美团 Leaf 则提供了一种高可用的分布式 ID 生成服务,适合对 ID 生成有特殊要求的场景。
在实际应用中,开发者应根据系统的规模、性能要求以及可扩展性等因素,选择最合适的分布式 ID 生成方案。