一、介绍一下强化学习的Q_learning
Q-Learning 是一种无模型(model-free)强化学习算法,用于学习智能体在环境中的最优策略,使其获得最大的累计奖励。
1.1. Q-Learning 的核心思想
学习一个 Q函数 :
Q ( s , a ) = 在状态 s 下采取动作 a 后的期望总奖励 Q(s, a) = \text{在状态 } s \text{ 下采取动作 } a \text{ 后的期望总奖励} Q(s,a)=在状态 s 下采取动作 a 后的期望总奖励
通过不断与环境交互,更新 Q 值,最终得到最优策略:
π ∗ ( s ) = arg max a Q ( s , a ) \pi^*(s) = \arg\max_a Q(s, a) π∗(s)=argamaxQ(s,a)
1.2. Q-Learning 算法公式
✅ 核心更新公式:
Q ( s t , a t ) ← Q ( s t , a t ) + α r t + γ max a ′ Q ( s t + 1 , a ′ ) − Q ( s t , a t ) Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left r_t + \\gamma \\max_{a'} Q(s_{t+1}, a') - Q(s_t, a_t) \\right Q(st,at)←Q(st,at)+αrt+γa′maxQ(st+1,a′)−Q(st,at)
各部分含义:
- Q ( s t , a t ) Q(s_t, a_t) Q(st,at):当前的 Q 值估计
- r t r_t rt:当前获得的即时奖励
- s t + 1 s_{t+1} st+1:下一个状态
- max a ′ Q ( s t + 1 , a ′ ) \max_{a'} Q(s_{t+1}, a') maxa′Q(st+1,a′):下一个状态下的最大预期价值(贪婪估计)
- α \alpha α:学习率
- γ \gamma γ:折扣因子(衡量未来奖励的重要性)
二、介绍强化学习的DQN(Deep Q-Network)算法
DQN 是 DeepMind 在 2015 年提出的深度强化学习算法,通过使用神经网络来逼近 Q-learning 中的 Q 函数,解决了传统 Q-learning 无法应对高维状态空间的问题。
2.1. DQN 的核心思想
传统 Q-Learning 需要维护一个 Q 表: Q ( s , a ) Q(s,a) Q(s,a),但当状态空间巨大(如图像输入)时无法表示。
DQN 用神经网络 Q ^ ( s , a ; θ ) \hat{Q}(s,a; \theta) Q^(s,a;θ) 来逼近 Q 函数,使得在高维状态空间中也能进行强化学习。
2.2. DQN 的关键公式
核心是使用均方误差损失函数 训练神经网络:
L ( θ ) = E ( s , a , r , s ′ ) ( y − Q ( s , a ; θ ) ) 2 L(\theta) = \mathbb{E}_{(s,a,r,s')} \left \\left( y - Q(s,a;\\theta) \\right)\^2 \\right L(θ)=E(s,a,r,s′)(y−Q(s,a;θ))2
其中目标值:
y = r + γ max a ′ Q ( s ′ , a ′ ; θ − ) y = r + \gamma \max_{a'} Q(s', a'; \theta^-) y=r+γa′maxQ(s′,a′;θ−)
- θ \theta θ 是当前 Q 网络的参数
- θ − \theta^- θ− 是目标网络 参数(定期复制 θ \theta θ)
- r r r 是即时奖励, γ \gamma γ 是折扣因子
2.3. DQN 的结构改进(相比 Q-Learning)
| 关键机制 | 作用 |
|---|---|
| ✅ Deep Neural Network | 逼近 Q 函数 |
| ✅ 经验回放(Replay Buffer) | 打破样本相关性,提高训练稳定性 |
| ✅ 目标网络(Target Network) | 减少更新震荡,提高收敛性 |
| ✅ ε-greedy 策略 | 平衡探索与利用 |
三、DIN 注意力机制的理解
DIN注意力的本质也还是将行为序列的embeding 和 物品的embeding 做显式交叉后,输入全连接层得到注意力权重。
3.1. DIN 注意力(行为兴趣建模)
-
对每个历史行为 k i k_i ki,构造特征交叉,输入到MLP
Attention ( q , k i ) = MLP ( q , k i , q − k i , q ⋅ k i ) \text{Attention}(q, k_i) = \text{MLP}(q, k_i, q - k_i, q \\cdot k_i) Attention(q,ki)=MLP(q,ki,q−ki,q⋅ki)- q q q:目标物品 embedding
- k i k_i ki:第 i i i 个历史行为 embedding
-
经过softmax归一化,得到注意力权重
α i = exp ( a i ) ∑ j exp ( a j ) \alpha_i = \frac{\exp(a_i)}{\sum_j \exp(a_j)} αi=∑jexp(aj)exp(ai) -
加权求和作为兴趣表示:
v = ∑ i α i ⋅ k i v = \sum_i \alpha_i \cdot k_i v=i∑αi⋅ki
3.2.Transformer 注意力(自注意力机制)
Attention ( Q , K , V ) = softmax ( Q K T d ) V \text{Attention}(Q, K, V) = \text{softmax} \left( \frac{QK^T}{\sqrt{d}} \right) V Attention(Q,K,V)=softmax(d QKT)V
- Q , K , V Q, K, V Q,K,V 通常由同一个输入序列通过线性变换得到
- 使用点积衡量 token 间相关性
四、92. 反转链表 II(中等)
这题虽然不是hot100的题,但是做的逻辑还是很清楚的。先看看hot100的反转链表
4.1. 206. 反转链表(力扣hot100_链表_简单)
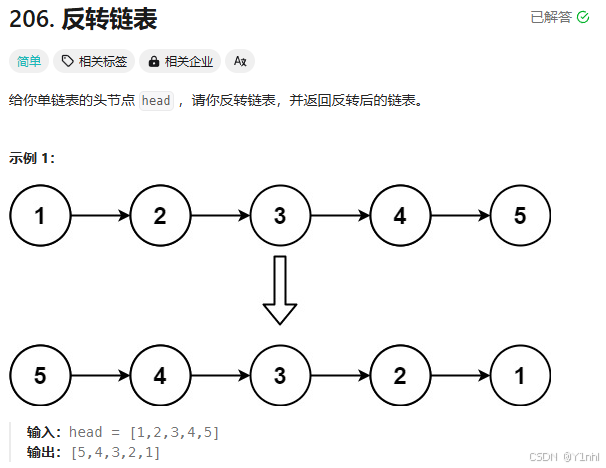
- 代码:
python
class Solution:
def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
pre = None
cur = head
while cur:
nxt = cur.next
cur.next = pre
pre = cur
cur = nxt
return pre- 上述代码的核心就是 cur.next = pre,最终遍历完,pre指向新的头节点,cur指向尾节点的下一个。
4.2. 再看原题
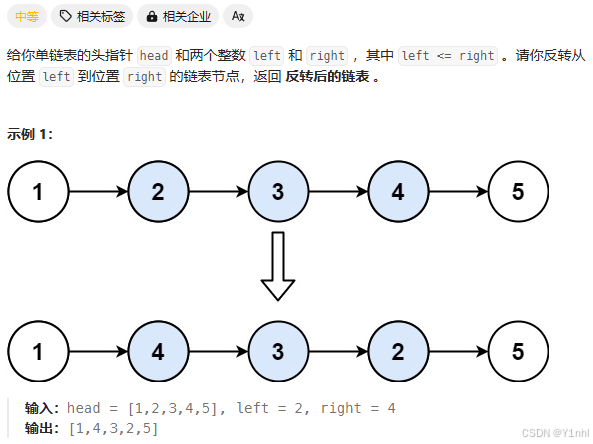
- 思路:如果我们要反转中间部分,根据反转链表的方法。反转完后,pre指向的是反转后的头节点,也就是反转段的最后一个节点;cur指向的是反转段的下一个节点。我们只需要将
- 1. 反转段的前一个节点和pre连接起来,
- 2. 反转段的尾节点和cur连接起来便可。
python
class Solution:
def reverseBetween(self, head: Optional[ListNode], left: int, right: int) -> Optional[ListNode]:
p0 = dummy = ListNode(next=head)
for _ in range(left - 1):
p0 = p0.next
pre = None
cur = p0.next
for _ in range(right - left + 1):
nxt = cur.next
cur.next = pre # 每次循环只修改一个 next,方便大家理解
pre = cur
cur = nxt
p0.next.next = cur # 上面2
p0.next = pre # 上面1
return dummy.next