目录
[1. 前言](#1. 前言)
[2. GRU的基本原理](#2. GRU的基本原理)
[2.1 重置门(Reset Gate)](#2.1 重置门(Reset Gate))
[2.2 更新门(Update Gate)](#2.2 更新门(Update Gate))
[2.3 候选隐藏状态](#2.3 候选隐藏状态)
[2.4 最终隐藏状态](#2.4 最终隐藏状态)
[2.5 图结构](#2.5 图结构)
[3. 关于GRU的实例:电影评论情感分类](#3. 关于GRU的实例:电影评论情感分类)
[3.1 导入必要的库](#3.1 导入必要的库)
[3.2 加载和预处理数据](#3.2 加载和预处理数据)
[3.3 构建GRU模型](#3.3 构建GRU模型)
[3.4 训练模型](#3.4 训练模型)
[5. 评估模型](#5. 评估模型)
[4. 总结](#4. 总结)
1. 前言
循环神经网络(RNN)在处理序列数据方面有着广泛的应用,但传统RNN在处理长序列时容易出现梯度消失或梯度爆炸的问题。为了解决这个问题,门控循环单元(Gated Recurrent Unit, GRU)应运而生。GRU通过引入门控机制,能够更有效地捕获序列中的长期依赖关系,同时减少了计算复杂度。本文将详细介绍GRU的工作原理,并通过一个完整的Python实例来展示如何使用GRU处理序列数据。
RNN基础参考以下博客:
《循环神经网络(RNN)基础入门与实践学习:电影评论情感分类任务》
2. GRU的基本原理
GRU是RNN的一种变体,它通过引入两个门(重置门和更新门)来控制信息的流动。GRU的结构比LSTM简单,但效果相近,且计算效率更高。
2.1 重置门(Reset Gate)
重置门决定了如何结合新输入和之前的隐藏状态。其计算公式为:
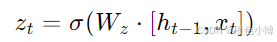
其中,zt 是重置门的输出,Wz 是权重矩阵,σ 是sigmoid激活函数。
2.2 更新门(Update Gate)
更新门决定了保留多少之前的隐藏状态。其计算公式为:
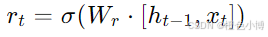
其中,rt 是更新门的输出,Wr 是权重矩阵。
2.3 候选隐藏状态
候选隐藏状态结合了当前输入和重置门的输出。其计算公式为:
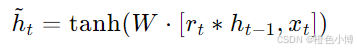
其中,h~t 是候选隐藏状态,W 是权重矩阵,∗ 表示逐元素乘法。
2.4 最终隐藏状态
最终隐藏状态由更新门和候选隐藏状态共同决定。其计算公式为:
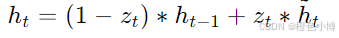
2.5 图结构

3. 关于GRU的实例:电影评论情感分类
我们将使用Keras库来实现一个简单的GRU模型,用于IMDB电影评论的情感分类。
3.1 导入必要的库
python
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, GRU, Dense
from tensorflow.keras.preprocessing.sequence import pad_sequences3.2 加载和预处理数据
python
# 设置参数
vocab_size = 10000 # 词汇表大小
maxlen = 200 # 每条评论的最大长度
batch_size = 64 # 批量大小
# 加载IMDB数据集
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=vocab_size)
# 填充序列,使其长度相同
X_train = pad_sequences(X_train, maxlen=maxlen)
X_test = pad_sequences(X_test, maxlen=maxlen)3.3 构建GRU模型
python
# 创建模型
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=128, input_length=maxlen))
model.add(GRU(128, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 打印模型摘要
model.summary()3.4 训练模型
python
# 训练模型
history = model.fit(X_train, y_train,
batch_size=batch_size,
epochs=5,
validation_data=(X_test, y_test))5. 评估模型
python
# 评估模型
score, acc = model.evaluate(X_test, y_test, batch_size=batch_size)
print(f'Test score: {score}')
print(f'Test accuracy: {acc}')4. 总结
GRU通过引入重置门和更新门,有效地解决了传统RNN在处理长序列时的梯度消失问题。它在保持较高计算效率的同时,能够更好地捕获序列中的长期依赖关系。在本文中,我们通过一个简单的IMDB电影评论情感分类任务,展示了如何使用Keras实现GRU模型。GRU在许多序列建模任务中表现出色,特别是在计算资源有限的情况下,是一个非常实用的选择。未来,我们可以进一步探索GRU在更复杂任务中的应用,如机器翻译、语音识别等。我是橙色小博,关注我,一起在人工智能领域学习进步。