推荐算法工程师面试题
- 二分类的分类损失函数?
二分类的分类损失函数一般采用交叉熵(Cross Entropy)损失函数,即CE损失函数。二分类问题的CE损失函数可以写成: 其中,y是真实标签,p是预测标签,取值为0或1。
其中,y是真实标签,p是预测标签,取值为0或1。
- 多分类的分类损失函数(Softmax)?
多分类的分类损失函数采用Softmax交叉熵(Softmax Cross Entropy)损失函数。Softmax函数可以将输出值归一化为概率分布,用于多分类问题的输出层。Softmax交叉熵损失函数可以写成: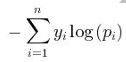 ,其中,n是类别数,yi是第i类的真实标签,pi是第i类的预测概率。
,其中,n是类别数,yi是第i类的真实标签,pi是第i类的预测概率。
- 关于梯度下降的sgdm,adagrad,介绍一下。
- SGD(Stochastic Gradient Descent)是最基础的梯度下降算法,每次迭代随机选取一个样本计算梯度并更新模型参数
- SGDM(Stochastic Gradient Descent withMomentum)在SGD的基础上增加了动量项,可以加速收敛
- Adagrad(AdaptiveGradient)是一种自适应学习率的梯度下降算法,它根据每个参数的梯度历史信息调整学习率,可以更好地适应不同参数的变化范围。
- 为什么不用MSE分类用交叉熵?
MSE(Mean Squared Error)损失函数对离群点敏感,而交叉嫡(CrossEntropy)损失函数在分类问题中表现更好,因为它能更好地刻画分类任务中标签概率分布与模型输出概率分布之间的差异。
- yolov5相比于之前增加的特性有哪些?
YOLOv5相比于之前版本增加了一些特性,包括:使用CSP(Cross StagePartial)架构加速模型训练和推理;采用Swish激活函数代替ReLU;引入多尺度训l练和测试,以提高目标检测的精度和召回率;引入AutoML技术,自动调整超参数以优化模型性能。
- 可以介绍一下attention机制吗?
Attention机制是一种用于序列建模的技术,它可以自适应地对序列中的不同部分赋予不同的权重,以实现更好的特征表示。在Attention机制中,通过计算查询向量与一组键值对之间的相似度,来确定每个键值对的权重,最终通过加权平均的方式得到Attention向量.
- 关于attention机制,三个矩阵KQ,KV,K.的作用是什么?
在Attention机制中,KQV是一组与序列中每个元素对应的三个矩阵,其中K和V分别代表键和值,用于计算对应元素的权重,Q代表查询向量,用于确定权重分配的方式。三个矩阵K、Q、V在Attention机制中的具体作用如下:
- K(Key)矩阵:K矩阵用于计算每个元素的权重,是一个与输入序列相同大小的矩阵。通过计算查询向量Q与每个元素的相似度,确定每个元素在加权平均中所占的5比例。
- Q(Query)向量:Q向量是用来确定权重分配方式的向量,与输入序列中的每个元素都有一个对应的相似度,可以看作是一个加权的向量。
- V(Value)矩阵:V矩阵是与输入序列相同大小的矩阵,用于给每个元素赋予一个对应的特征向量。在Attention机制中,加权平均后的向量就是V矩阵的加权平均向量。
通过K、Q、V三个矩阵的计算,Attention机制可以自适应地为输入序列中的每个元素分配一个权重,以实现更好的特征表示。
- 介绍一下文本检测EAST。
EAST(Efficient and Accurate Scene Text)是一种用于文本检测的神经网络模型。EAST通过以文本行为单位直接预测文本的位置、方向和尺度,避免了传统方法中需要多次检测和合并的过程,从而提高了文本检测的速度和精度。EAST采用了一种新的训练方式,即以真实文本行作为训练样本,以减少模型对背景噪声的干扰,并在测试阶段通过非极大值抑制(NMS)算法进行文本框的合并。
- 编程题(讲思路):给定两个字符串s,在$字符串中找到包含t字符串的最小字串。
给定两个字符串s、t,可以采用滑动窗口的方式在s中找到包含t的最小子串。具体做法如下:
- 定义两个指针left和right,分别指向滑动窗口的左右边界。
- 先移动ight指针,扩展滑动窗口,直到包含了t中的所有字符。
- 移动left指针,缩小滑动窗口,直到无法再包含t中的所有字符。
- 记录当前滑动窗口的长度,如果小于之前记录的长度,则更新最小长度和最小子串。
- 重复(2)到(4)步骤,直到ight指针到达s的末尾为止。
算法工程师暑期实习面试题
- 如何理解交叉熵的物理意义
交叉熵是一种用于比较两个概率分布之间的差异的指标。在机器学习中,它通常用于比较真实标签分布与模型预测分布之间的差异。
- 过拟合如何去解决?
L1正则为什么能够使得参数稀疏,从求导的角度阐述。过拟合的解决方法有很多:数据的角度:获取和使用更多的数据(数据集增强)模型角度:降低模型复杂度、L1L2 Dropout正则化、Early stopping(提前终止)
模型融合的角度:使用bagging等模型融合方法。L1正则化在损失函数中加入参数的绝对值之和,可以使得一些参数变得非常小或者为零,从而使得模型更加稀疏,减少过拟合的风险。从求导的角度来看:L1正则化添加了个与模型参数绝对值成正比的项到损失函数中,即λ|w|,λ是正则化系数,w是模型参数。进行求导,可以得到: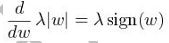 其中sign()是符号函数。这个导数是常数,不像L2正则化的导数那样与参数的大小成正比。
其中sign()是符号函数。这个导数是常数,不像L2正则化的导数那样与参数的大小成正比。
当使用梯度下降进行优化时,L1正则化会持续地从权重中减去一个恒定的值(取决于其符号),导致许多权重减少到零。而L2正则化会持续地从权重中减去一个与权重大小成正比的值,这不太可能导致权重完全达到零。因此,L1正则化倾向于产生稀疏的权重向量,其中大多数权重为零,而L2正则化则更可能使所有权重都接近于零但不完全为零。
- 类别不平衡是如何去处理的?如果进行采样,策略是什么?
类别不平衡可以通过对数据进行采样来处理。一种常用的采样策略是欠采样,即随机从多数类中选择一部分样本使得样本平衡。另一种常用的采样策略是过采样,即从少数类中复制一些样本使得样本平衡。还有一种策略是生成新的少数类样本,比如SMOTE算法,其中通过对少数类样本进行随机插值来生成新的样本。
- 介绍一下attention,做过哪些尝试和改进。
Attention是一种机器学习中的技术,主要用于提取输入序列中的关键信息。在自然语言处理和图像处理中,Attention机制已经成为了重要的技术。对于Attention的一些实现方法和改进,一种常见的Attention实现方法是Soft Attention,它可以用于提取序列数据中的重要信息。另外,还有些改进方法,比如Muti-Head Attention和Self-Attention等,可以进一步提高Attention的性能。
- 对于一个时间顺序的推荐数据,如何划分训练集和验证集,能不能随机?
对于时间顺序的推荐数据,通常可以使用时间轴来划分训练集和验证集。具体地,可以选取一段时间作为训练集,另一段时间作为验证集。如果数据量足够大,也可以将数据随机划分为训练集和验证集。但是,需要注意的是,在时间序列数据中,训练集和验证集应该按照时间顺序进行划分,以保证模型的泛化能力。
- 欠拟合如何去解决,训练过程不收敛如何去解决?
欠拟合的解决方法有很多,其中一个是增加模型的复杂度。可以增加模型的参数数量、增加网络层数、使用更复杂的模型结构等来提高模型的拟合能力。另外,还可以尝试调整学习率、修改损失函数、增加训练数据等方法。如果训练过程不收敛,可能是学习率过大或者网络结构不合理导致的。可以尝试减小学习率、使用不同的优化器、增加网络层数等方法来解决这个问题。
- 正则化和最大似然的关系。
正则化和最大似然有一定的关系。最大似然是一种用于估计模型参数的方法,其目标是找到使得观测数据出现的概率最大的模型参数。正则化是一种对模型参数进行限制的方法,可以使得模型参数更加稳定和泛化能力更强。在最大似然估计中,通过添加正则化项可以达到类似的目的,即防止模型过拟合。常见的正则化方法包括L1正则化和L2正则化。
- Leetcode:数组中第K大的元素。
难度:【中等】三种思路:一种是直接使用sorted函数进行排序,一种是使用小顶堆,一种是使用快排(双指针+分治)。
- 方法一:直接使用sorted函数进行排序代码如下:
csharp
class Solution:
def findKthLargest(self,nums:List[int],k:int)->int:
return sorted(nums,reverse =True)[k-1]- 方法二:使用堆XX维护一个size为k的小顶堆,把每个数丢进去,如果堆的size>k,就把堆顶pop掉(因为它是最小的),这样可以保证堆顶元素一定是第k大的数。代码如下:
csharp
class Solution:
def findKthLargest(self,nums:List[int],k:int)->int:
heap = []
for num in nums:
heappush(heap,num)
if len(heap)>k:
heappop(heap)
return heap[0]时间复杂度:O(nlogk)空间复杂度:O(k)
- 方法三:双指针+分治partition部分定义两个指针left和right,还要指定一个中心pivot(这里直接取最左边的元素为中心,即numsi)不断将两个指针向中间移动,使得大于pivot的元素都在pivot的右边,小于pivot的元素都在pivot的左边,注意最后满足时,left是和right相等的,因此需要将pivot赋给此时的let或right。.然后再将中心点的索引和k-1进行比较,通过不断更新let和right找到最终的第k个位置。代码如下:
csharp
class Solution:
def findKthLargest(self,nums:List[int],k:int)->int:
left,right,target =0,len(nums)-1,k-1
while True:
pos=self.partition(nums,left,right)
if pos ==target:
return nums[pos]
elif pos>target:
right=pos-1
else:
left = pos + 1
def partition(self,nums,left,right):
pivot=nums[left]
while left right:
while nums[right]<=pivot and left<right:
right-=1
nums[left]=nums[right]
while nums[left]>pivot and left<right:
left += 1
nums[right]nums[left]
nums[left] = pivot
return left视觉算法工程师面试题
- C++编译的过程,从源码到二进制:
C++源码经过以下几个步骤进行编译,从源码转换为可执行的二进制文件:
- 预处理(Preprocessing):预处理器根据源码中的预处理指令,如# include、define等,对源码进行文本替换、宏展开等处理。
- 编译(Compilation):编译器将预处理后的源码转换为汇编语言代码,也称为汇编源码。
- 汇编(Assembly):汇编器将汇编语言代码转换为机器语言指令,生成目标文件(通常为二进制文件)。
- 链接(Linking):链接器将目标文件与系统库、用户自定义的库进行链接,生成可执行文件。链接器将目标文件中的符号(如函数、变量等)与其对应的定义进行匹配,解析符号的引用关系,生成最终的可执行文件。
- 加载(Loading):操作系统将可执行文件加载到内存中,并将程序的控制权转交给程序的入口点,从而开始执行程序。
- C++最小的编译单元:
C++中最小的编译单元是函数。函数在编译时被编译器独立地编译成目标文件,然后通过链接器将目标文件与其他目标文件或库文件链接成最终的可执行文件。
- C+静态库和动态库的区别:
静态库(Static Library)在链接时会被完整地复制到可执行文件中,程序运行时不需要外部的库文件支持。而动态库(Dynamic Library)在链接时并不会被复制到可执行文件中,而是在程序运行时由操作系统动态加载到内存中并共享使用。因此,静态库会增加可执行文件的大小,而动态库可以在多个可执行文件之间共享,减小了可执行文件的大小。
- 说一下C+中的share_ptr
share_ptr是C++11引入的智能指针,用于管理动态分配的对象的所有权。它使用引用计数的方式来自动释放资源,避免了内存泄漏。share_ptr允许多个share_ptr对象共享同一个对象,当最后一个指向对象的share_ptr被销毁时,它会自动释放资源。
- C++中new和make_shared创建出来的差异点
- new和make_shared都用于在堆上分配动态内存并创建对象。其中,new是C++中的关键字,返回的是裸指针,需要手动管理内存释放:而make_shared是C++11引入的函数模板,返回的是一个shared_ptr对象,使用引用计数管理内存,无需手动释放
差异点:
- make_shared通常比new效率更高,因为它在一次内存分配中同时分配了对象和控制块(用于管理引用计数),减少了内存分配的次数,提高了性能。
- make_shared可以避免潜在的内存泄漏,因为它将对象和引用计数块一同存储在连续的内存块中,确保了对象和引用计数块的一致性,避免了因为异常导致的资源泄漏。
- 使用shared_ptr时,建议优先使用make_shared,因为它更加安全和高效,能够减少内存分配次数,提高性能。
- C++中左值和右值的概念:
- 左值(Lvalue)是指具有持久性、可以被命名的表达式或对象,它们具有内存地址。左值可以出现在赋值、取址、函数调用等操作中,并且可以被修改。
- 右值(Rvalue)是指临时的、没有持久性的表达式或对象,它们不能被命名,通常用于初始化或者临时计算。右值不能出现在赋值的左侧,但可以出现在赋值的右侧,并且可以被移动或者转移所有权。
- C++11引入了右值引用(Rvalue reference),通过&&表示,用于标识对右值的引用,右值引用可以用于实现移动语义和完美转发(perfect forwarding),提高了性能和灵活性。
- C++中的STL(Standard Template Library)里面有以下常用的容器:
- vector:动态数组,支持随机访问.
- list:双向链表,支持快速插入和删除。
- deque:双端队列,支持随机访问。
- queue:队列,先进先出(FIFO)。
- stack:栈,后进先出(LIFO)。
- set:集合,自动排序且元素唯一。
- map:映射,键值对容器,自动排序且键唯一。
- unordered_set:无序集合,哈希实现,元素唯一。
- unordered_map:无序映射,键值对容器,哈希实现。
8、C++中map和unordered_map的区别:
- 排序:map中的键值对默认按照键的大小进行排序,而unordered_map没有固定的排序,是无序的。
- 实现:map通常使用红黑树(平衡二叉搜索树)实现,而unordered_map使用哈希表实现。
- 性能:unordered_map在插入删除和查找操作上通常具有更好的平均性能,因为哈希表具有较快的查找和插入速度,而map则对键进行排序可能会导致性能略低。
- 内存占用:unordered_map通常占用更多的内存,因为哈希表需要额外的存储空间来存储哈希函数和桶(bucket)的信息,而map使用红黑树存储,不需要额外的存储空间。
- 查找效率:在大数据量的情况下,unordered_map通常比map更快,因为哈希表具有O(1)的平均查找复杂度,而红黑树具有OogN)的平均查找复杂度。
- 迭代顺序:mp中的元素按照键的大小进行排序,可以通过迭代器按照顺序访问,而unordered_map中的元素没有固定的顺序。
- 适用场景:map适用于需要按照键的大小进行排序或者需要有序访问的场景,而unordered_map适用于不需要排序或者对访问顺序无要求的场景,且在性能要求较高的情况下可以考虑使用unordered_map