目录
[1.1 公司背景与发展历程](#1.1 公司背景与发展历程)
[1.2 核心产品DeepSeek-R1的技术特点](#1.2 核心产品DeepSeek-R1的技术特点)
[1.3 行业影响与伦理挑战](#1.3 行业影响与伦理挑战)
[2.1 官方网站与API服务](#2.1 官方网站与API服务)
[2.2 开源代码库资源](#2.2 开源代码库资源)
[2.3 模型部署工具Ollama简介](#2.3 模型部署工具Ollama简介)
[3.1 Ollama环境搭建详解](#3.1 Ollama环境搭建详解)
[3.1.1 获取安装包](#3.1.1 获取安装包)
[3.1.2 安装过程要点](#3.1.2 安装过程要点)
[3.1.3 Ollama的架构与工作原理](#3.1.3 Ollama的架构与工作原理)
[3.2 安装流程图示](#3.2 安装流程图示)
[3.3 安装验证与基础配置](#3.3 安装验证与基础配置)
[3.3.1 图形界面验证](#3.3.1 图形界面验证)
[3.3.2 命令行验证](#3.3.2 命令行验证)
[3.2.3 基础运行测试](#3.2.3 基础运行测试)
[4.1 核心硬件组件详解](#4.1 核心硬件组件详解)
[4.1.1 GPU:LLM部署的核心引擎](#4.1.1 GPU:LLM部署的核心引擎)
[4.1.2 CPU:系统协调与前处理支持](#4.1.2 CPU:系统协调与前处理支持)
[4.1.3 内存:模型工作空间与数据缓冲](#4.1.3 内存:模型工作空间与数据缓冲)
[4.1.4 存储系统:模型加载与数据读写](#4.1.4 存储系统:模型加载与数据读写)
[4.2 辅助硬件与系统稳定性](#4.2 辅助硬件与系统稳定性)
[4.2.1 散热系统:性能稳定的守护者](#4.2.1 散热系统:性能稳定的守护者)
[4.2.2 电磁屏蔽与电源管理](#4.2.2 电磁屏蔽与电源管理)
[4.2.3 网络基础设施](#4.2.3 网络基础设施)
[4.3 不同规模模型的配置要求与应用场景](#4.3 不同规模模型的配置要求与应用场景)
[4.3.1 入门级:DeepSeek-R1-1.5B](#4.3.1 入门级:DeepSeek-R1-1.5B)
[4.3.2 中端方案:DeepSeek-R1-7B/8B](#4.3.2 中端方案:DeepSeek-R1-7B/8B)
[4.3.3 专业级选择:DeepSeek-R1-14B](#4.3.3 专业级选择:DeepSeek-R1-14B)
[4.3.4 高端研究配置:DeepSeek-R1-32B](#4.3.4 高端研究配置:DeepSeek-R1-32B)
[4.3.5 顶级研究平台:DeepSeek-R1-70B](#4.3.5 顶级研究平台:DeepSeek-R1-70B)
[5.1.1 官网查看模型信息](#5.1.1 官网查看模型信息)
[5.1.2 运行命令](#5.1.2 运行命令)
[5.2 Miniconda安装与环境管理](#5.2 Miniconda安装与环境管理)
[5.2.1 为什么选择Miniconda?](#5.2.1 为什么选择Miniconda?)
[5.2.2 安装流程详解](#5.2.2 安装流程详解)
[5.2.3 Windows安装步骤(图示)](#5.2.3 Windows安装步骤(图示))
[5.2.4 环境配置与优化](#5.2.4 环境配置与优化)
[5.2 Open-WebUI界面配置:可视化交互平台](#5.2 Open-WebUI界面配置:可视化交互平台)
[5.2.1 Open-WebUI的价值与功能](#5.2.1 Open-WebUI的价值与功能)
[5.2.2 环境准备与安装流程](#5.2.2 环境准备与安装流程)
[5.2.3 启动与访问配置](#5.2.3 启动与访问配置)
[5.2.4 高级配置与性能优化](#5.2.4 高级配置与性能优化)
[5.2.5 界面功能与使用技巧](#5.2.5 界面功能与使用技巧)
导读:在人工智能加速发展的今天,开源大模型已成为技术民主化的重要力量。本文全面介绍了中国AI新秀DeepSeek(深度求索)及其旗舰产品DeepSeek-R1的本地化部署方案。作为一款训练成本仅为GPT-4的6%却拥有相当性能的开源大模型,DeepSeek-R1为开发者和研究人员提供了极具价值的AI实践平台。
本指南将带您从零开始,详细解析从环境准备到模型部署的完整流程,包括Ollama工具的安装配置、不同规模模型的硬件需求分析(从入门级1.5B到顶级70B)以及Open-WebUI界面的搭建。您是否好奇一款高性能大模型如何在家用硬件上平稳运行?或者如何以最优的硬件配置运行32B以上的大模型?
一、DeepSeek简介:开源领域的新兴力量
1.1 公司背景与发展历程
DeepSeek(深度求索)是中国人工智能领域的一颗新星,总部位于浙江省杭州市。公司成立于2023年7月17日,由前阿里巴巴资深研究员梁文峰创立并担任首席执行官。作为中国AI领域的新兴公司,DeepSeek代表了国内自主研发大语言模型的重要力量,填补了开源大模型领域的部分空白。
在人工智能快速发展的背景下,DeepSeek的出现正值全球对大语言模型的研发与应用进入白热化阶段。公司成立伊始就聚焦于开源大语言模型的研发,希望能够降低AI技术的使用门槛,推动技术的民主化进程。
1.2 核心产品DeepSeek-R1的技术特点
DeepSeek的首个旗舰产品是开源大型语言模型"DeepSeek-R1"。这款模型具有以下几个突出特点:
- 卓越性能:DeepSeek-R1在多项评测中表现出与OpenAI的GPT-4相当的能力,特别是在文本理解、生成和推理等方面。
- 成本突破:最引人注目的是,DeepSeek-R1的训练成本仅约600万美元,相比OpenAI的GPT-4高达1亿美元的训练成本,实现了约94%的成本降低。这一成本优势源自团队在模型架构设计、训练策略优化以及计算资源调度方面的创新。
- 全面开源:不同于许多闭源模型,DeepSeek-R1采用完全开源策略,开发者可以自由使用、查看、修改其代码,并基于其进行二次开发。这种开源策略促进了AI技术的传播与创新。
- 多参数规模系列:DeepSeek-R1提供从1.5B到70B等多种不同参数规模的模型版本,适应不同的应用场景和硬件条件。
- 中英双语能力:相比部分仅专注于英文的开源模型,DeepSeek-R1在中文处理能力上有着明显优势,能更好地服务中文用户群体。
1.3 行业影响与伦理挑战
尽管DeepSeek带来了技术创新和开源价值,但其发展也面临着一系列挑战:
- 隐私安全问题:与所有大语言模型一样,DeepSeek-R1在处理用户数据时涉及到隐私保护问题。尤其是当模型被用于处理敏感信息时,数据安全成为重要考量。
- 信息控制与伦理边界:开源模型可能被用于生成虚假信息或不当内容,如何在开放与控制之间取得平衡是一个难题。
- 监管合规压力:随着全球对AI技术监管的加强,DeepSeek面临着来自多国的监管审查,需要在技术创新与合规要求之间寻找平衡点。
- 技术竞争与持续创新:面对Google、OpenAI等巨头和其他开源项目的竞争,DeepSeek需要持续创新才能保持竞争力。
二、官方资源获取:全面掌握DeepSeek生态
2.1 官方网站与API服务
DeepSeek官方网站(DeepSeek | 深度求索)是获取最新信息和服务的主要渠道。在官网上,用户可以:
- 了解DeepSeek的最新技术进展和产品更新
- 访问在线演示体验DeepSeek模型的能力
- 查询API文档和使用指南
- 获取商业合作与技术支持信息
对于开发者而言,官网提供的API接口是快速集成DeepSeek能力的便捷方式,尤其适合那些不具备本地部署条件的用户。
2.2 开源代码库资源

DeepSeek的GitHub仓库(https://github.com/deepseek-ai/)是开发者最重要的技术资源中心,包含:
- 完整的模型架构代码
- 预训练与微调脚本
- 模型权重下载链接
- 详细的技术文档和部署指南
- 社区贡献的扩展与应用案例
通过这些开源资源,开发者可以深入理解模型内部工作原理,根据自身需求进行定制化开发,甚至参与到模型的改进过程中。
2.3 模型部署工具Ollama简介
Ollama(Ollama)是一款专为大语言模型本地部署设计的工具平台,成为DeepSeek模型本地运行的理想选择。作为本指南推荐的部署工具,Ollama具备以下优势:
- 隐私保护:所有数据处理均在本地完成,不需上传到云端,有效保护用户隐私与数据安全
- 简易操作:提供简洁的命令行和图形界面工具,大幅降低部署难度
- 多模型兼容:除DeepSeek外,还支持Llama、Mistral等多种开源大语言模型,便于横向对比与切换
- 跨平台支持:完全兼容Windows、Linux和macOS等主流操作系统
- 开源免费:Ollama本身也是开源项目,用户可以免费使用并根据需要进行修改
Ollama的出现解决了大语言模型本地部署的技术门槛问题,使个人用户和中小企业也能轻松体验先进的AI技术。
三、部署准备工作:搭建基础环境
3.1 Ollama环境搭建详解

在开始DeepSeek模型的部署前,我们首先需要安装Ollama工具。Ollama的安装过程相对简单,但需要注意一些关键步骤:
3.1.1 获取安装包
从Ollama官方网站(Download Ollama on macOS)下载适合您操作系统的安装包。Ollama提供Windows、macOS和Linux三个主要平台的安装版本。对于中国用户,可能需要考虑使用代理或镜像站点以提高下载速度。
3.1.2 安装过程要点
Windows用户:
- 下载.exe安装文件后双击运行
- 按照安装向导完成安装,建议保留默认安装路径
- 安装完成后会自动启动Ollama服务
macOS用户:
- 下载.dmg文件后双击打开
- 将Ollama拖动到Applications文件夹
- 首次运行时需要授权开发者验证
3.1.3 Ollama的架构与工作原理
了解Ollama的工作原理有助于更好地使用和排障:
- 轻量级服务架构:Ollama采用客户端-服务器架构,安装后会在后台运行一个轻量级服务
- 模型管理机制:使用统一的模型库管理不同的大语言模型,支持按需下载和加载
- 硬件资源调度:智能识别系统可用的CPU和GPU资源,自动进行最优分配
- API接口设计:提供RESTful API,方便与其他应用程序集成
3.2 安装流程图示
安
3.3 安装验证与基础配置
成功安装Ollama后,需要进行一系列验证与配置,确保系统正常运行:
3.3.1 图形界面验证
安装完成后,Ollama会在系统托盘区显示一个"羊驼"图标。这表明Ollama服务已经在后台启动。点击该图标可以查看基本状态和进行简单操作。
3.3.2 命令行验证
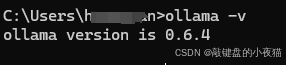
打开命令提示符(Windows)或终端(macOS/Linux),输入以下命令验证Ollama安装是否成功:
ollama -v如果安装正确,将会显示当前Ollama的版本信息,如 ollama version 0.1.14。
3.2.3 基础运行测试
为确保Ollama能够正常加载模型,可以尝试运行一个小型测试模型:
ollama run tinyllama这将下载并运行一个极小的模型,验证Ollama的基本功能是否正常。如果能够成功启动模型并进行简单对话,说明Ollama环境已经准备就绪。
四、硬件配置需求分析:从入门到高端
4.1 核心硬件组件详解
成功运行DeepSeek模型需要合适的硬件支持,不同组件对模型性能的影响各不相同。以下是对各核心硬件的深入解析:
4.1.1 GPU:LLM部署的核心引擎
工作原理:GPU的并行计算架构使其特别适合处理大语言模型中的矩阵运算,能够同时处理成千上万个计算任务。
选择标准:
- 显存容量:运行DeepSeek-R1-32B及更大模型需要至少24GB显存,理想情况下应选择48GB或更高
- 计算性能:Tensor Core支持可大幅提高模型推理速度,NVIDIA的A100/H100或AMD的MI系列是专业选择
- 接口带宽:PCIe 4.0或更高版本提供更快的数据传输速率,减少瓶颈
常见误区:许多用户错误地认为游戏显卡(如RTX系列)足以应对任何AI任务。事实上,虽然RTX 4090等高端游戏显卡可以运行中小规模模型,但对于70B等大型模型,仍需要专业计算卡或多卡并行。
4.1.2 CPU:系统协调与前处理支持
虽然大语言模型的主要计算发生在GPU上,但强大的CPU依然不可或缺:
关键作用:
- 协调系统各组件间的数据流动
- 处理模型的前处理与后处理任务
- 管理GPU资源分配和并行计算
- 执行非神经网络部分的常规计算
推荐配置:
- 多核心处理器(16核以上理想)
- 高缓存容量(36MB以上L3缓存)
- 支持AVX-512等先进指令集
- 英特尔第12代以上或AMD锐龙7000系列处理器
4.1.3 内存:模型工作空间与数据缓冲
容量需求:内存容量直接限制可处理的上下文长度和批处理大小。对于DeepSeek模型:
- 64GB是基本配置(适用于7B-14B模型)
- 128GB推荐配置(适用于32B模型)
- 256GB及以上理想配置(适用于70B及多模型并行)
性能指标:除容量外,内存频率和时序也会影响整体性能:
- DDR5比DDR4提供约25%的带宽提升
- 双通道或四通道配置可显著提高数据传输效率
4.1.4 存储系统:模型加载与数据读写
分层存储策略:
- 高速缓存层:NVMe PCIe 4.0 SSD(读写速度>7000MB/s)用于模型加载和活跃数据存取
- 容量存储层:大容量SATA SSD或HDD用于存储模型文件和训练数据集
最低需求:
- 至少1TB总存储空间
- 系统分区应使用高速SSD
- 单个模型文件最大可达70GB(70B模型版本)
4.2 辅助硬件与系统稳定性
除了核心计算组件,以下辅助系统对于长期稳定运行DeepSeek模型同样重要:
4.2.1 散热系统:性能稳定的守护者
挑战:大语言模型在推理过程中会持续产生大量热量,特别是在高负载状态下。
解决方案:
- 水冷系统:对于高端GPU(如A100/H100或多GPU配置),闭环或定制水冷系统能提供最佳散热效果
- 风冷优化:确保机箱具备良好的空气流动路径,前部进气、后部排气
- 温度监控:实时监控系统温度,设置自动降频或警报机制
专业建议:计算密集型工作负载应考虑数据中心级别的散热设计,包括适当的机架间距和冷通道/热通道分离。
4.2.2 电磁屏蔽与电源管理
电磁干扰影响:高性能计算设备会产生显著的电磁干扰,影响系统稳定性和组件寿命。
解决方案:
- 选择具有良好电磁屏蔽的机箱和组件
- 使用带有EMI过滤器的高质量电源线
- 避免将敏感设备放在计算主机附近
电源规划:
- 为高端GPU配置选择1200W以上高效率电源
- 使用UPS(不间断电源)预防突然断电和电源波动
- 考虑电源线路专业级接地以提高稳定性
4.2.3 网络基础设施
对于需要远程访问或多设备协同工作的部署环境:
- 内部网络:使用万兆以太网实现本地高速数据传输
- 外部连接:稳定可靠的互联网连接用于模型更新和远程管理
- 网络存储:考虑使用NAS(网络附加存储)用于模型文件的集中管理和共享
4.3 不同规模模型的配置要求与应用场景
以下是各种规模DeepSeek模型的具体硬件要求和最适合的应用场景,帮助读者根据自身需求选择合适的配置:
4.3.1 入门级:DeepSeek-R1-1.5B
硬件配置:
- CPU:4核处理器(如Intel Core i5或AMD Ryzen 5)
- 内存:8GB DDR4
- 存储:至少3GB可用空间
- GPU:非必需,可使用CPU推理;若使用GPU,4GB显存足够(如GTX 1650)
适用场景:
- 初学者试验与学习大语言模型基本原理
- 资源受限设备(如树莓派、旧款笔记本)上的轻量级部署
- 简单的文本生成和基础问答系统
- 嵌入式设备和物联网应用中的语言处理组件
性能预期:响应速度适中,适合处理简短对话和基础任务,但在复杂推理和专业领域表现有限。
4.3.2 中端方案:DeepSeek-R1-7B/8B
硬件配置:
- CPU:8核及以上处理器(推荐Intel Core i7或AMD Ryzen 7)
- 内存:16GB DDR4(推荐32GB)
- 存储:至少8GB可用SSD空间
- GPU:推荐8GB显存(如RTX 3070/4060)
适用场景:
- 中小型企业的本地开发和测试环境
- 中等复杂度的自然语言处理任务(文本摘要、内容生成、翻译)
- 多领域知识问答系统
- 需要在普通开发工作站上运行的应用
性能特点:
- 基础创意写作能力较强
- 代码生成和理解功能适合一般开发场景
- 平衡了性能和资源消耗的中间方案
4.3.3 专业级选择:DeepSeek-R1-14B
硬件配置:
- CPU:12核及以上高性能处理器
- 内存:32GB(推荐64GB)
- 存储:至少15GB高速SSD
- GPU:推荐16GB显存(如RTX 3090/4090、NVIDIA A5000)
适用场景:
- 企业级复杂任务(合同分析、报告自动生成)
- 专业领域知识服务(如技术咨询、产品支持)
- 长文本理解与生成(论文写作辅助、内容创作)
- 需要较高质量输出的商业应用
特点分析:
- 相比7B模型,在逻辑推理和上下文理解方面有明显提升
- 能够处理更复杂的语言结构和专业术语
- 推理速度和资源消耗达到较为平衡的状态
4.3.4 高端研究配置:DeepSeek-R1-32B
硬件配置:
- CPU:16核以上服务器级处理器(如AMD EPYC或Intel Xeon)
- 内存:64GB(推荐128GB)
- 存储:至少30GB NVMe SSD
- GPU:推荐48GB及以上显存(如NVIDIA A100、多卡并行)
适用场景:
- 高精度专业领域应用(医疗诊断辅助、法律文档分析)
- 复杂多轮对话系统(如高级虚拟助手)
- 创意内容生成(文学创作、脚本撰写)
- 学术研究和企业研发环境
核心优势:
- 语义理解深度和知识覆盖面接近人类专家水平
- 上下文处理能力强,能维持长对话的一致性
- 在专业领域问题上的回答质量和准确度高
4.3.5 顶级研究平台:DeepSeek-R1-70B
硬件配置:
- CPU:32核以上服务器级处理器
- 内存:128GB起步(推荐256GB)
- 存储:至少70GB高速存储,推荐RAID配置
- GPU:需要至少96GB显存(如多卡并行,2×A100 80GB或4×RTX 4090)
适用场景:
- 科研机构和大型企业的尖端研究
- 金融预测和大规模数据分析
- 需要接近GPT-4水平的任务
- 多模态应用的语言处理组件
五、环境配置流程:构建完整运行平台
5.1模型下载
5.1.1 官网查看模型信息
在ollama官网,选择deepseek-r1
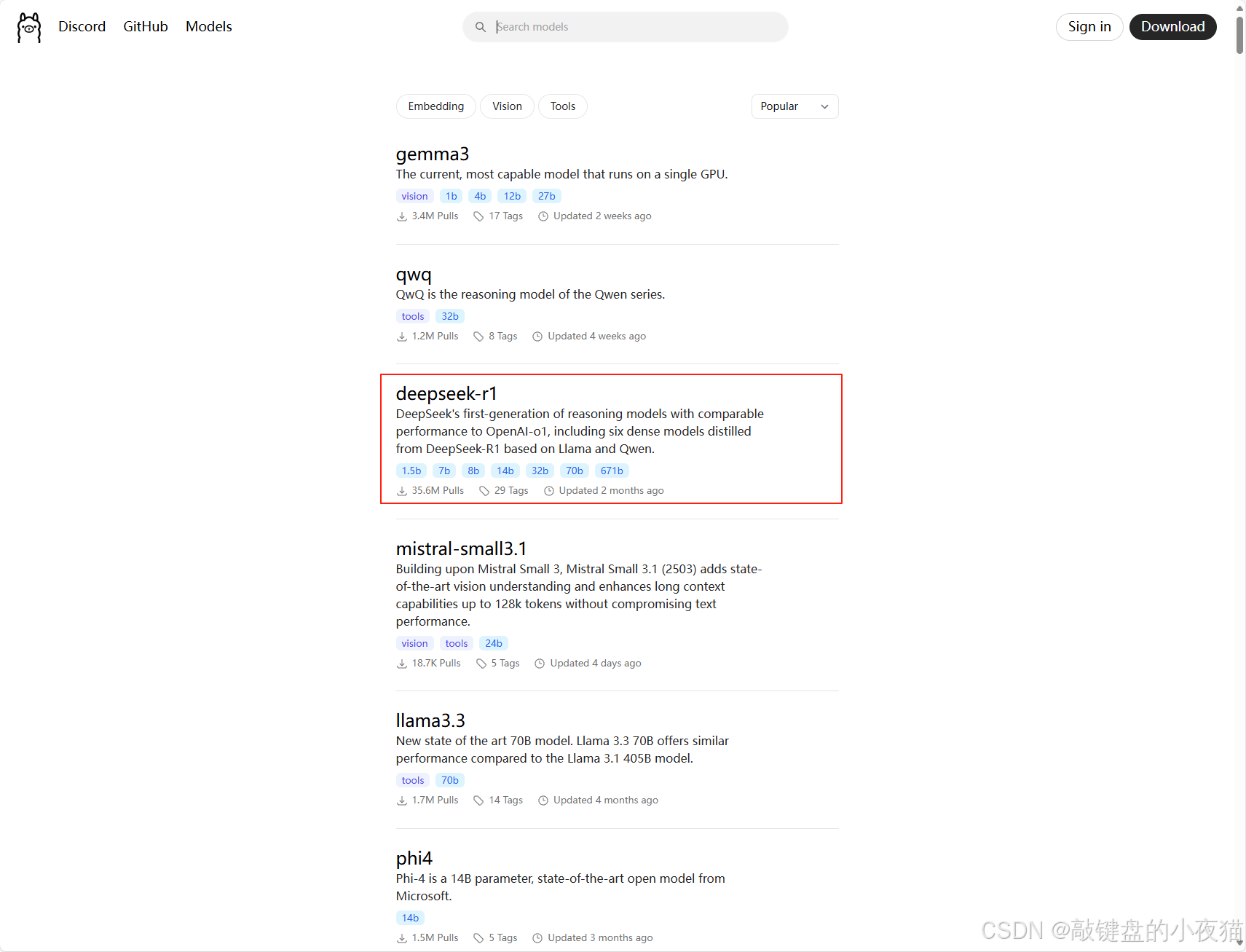
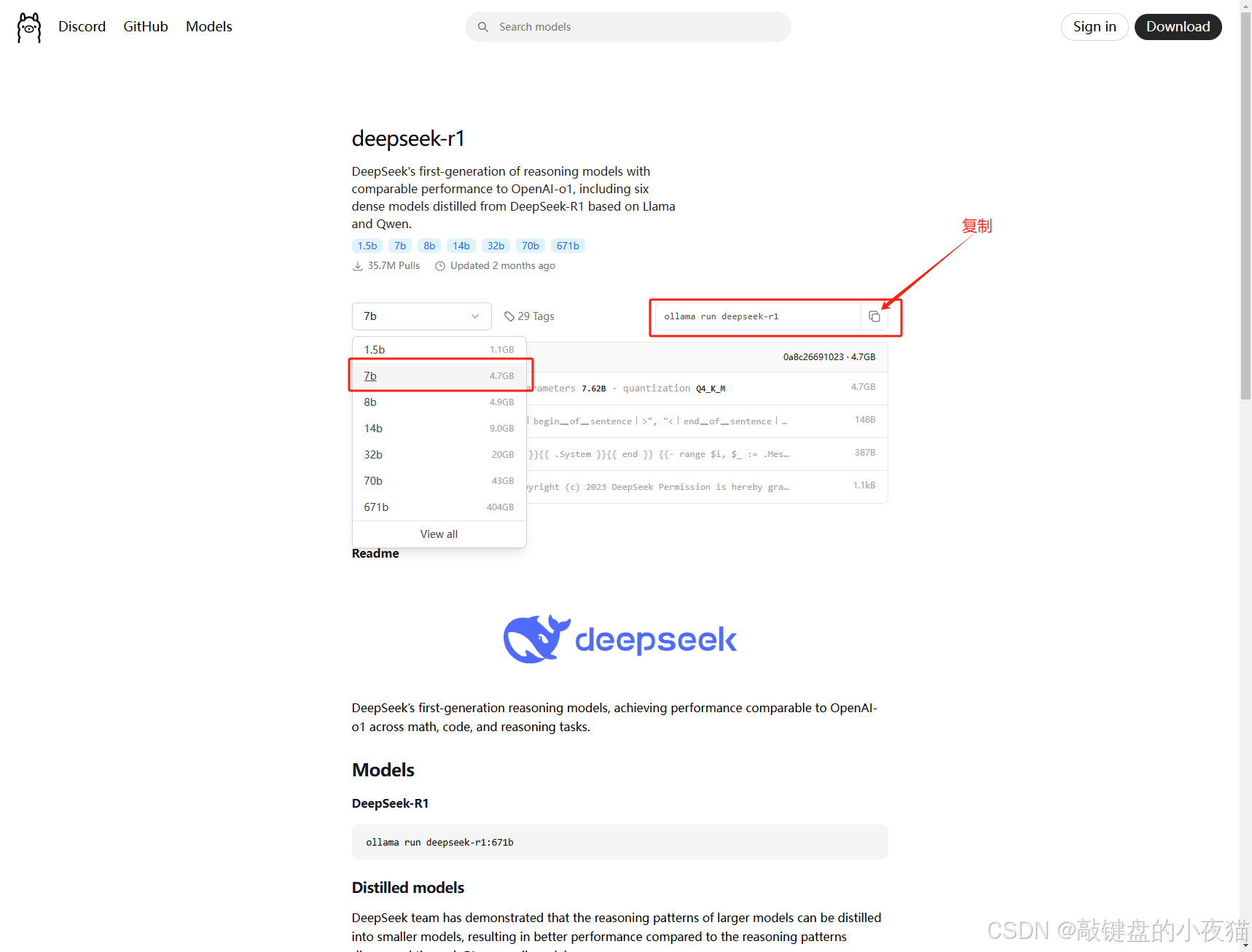
此处可以下载7b的模型文件,模型较小下载快,容易看到效果,各位可以参考4.3章节选择合适的模型文件来体验。
5.1.2 运行命令
14b
ollama run deepseek-r1:14b
32b
ollama run deepseek-r1:32b
查看已安装列表
ollama list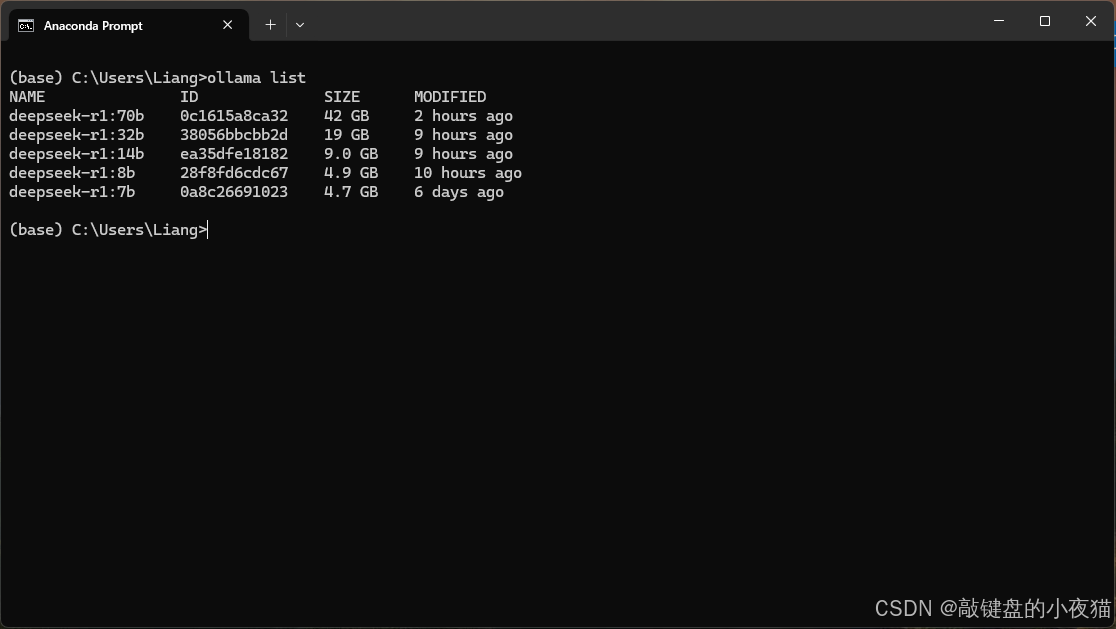
移除大模型
ollama rm deepseek-r1:70b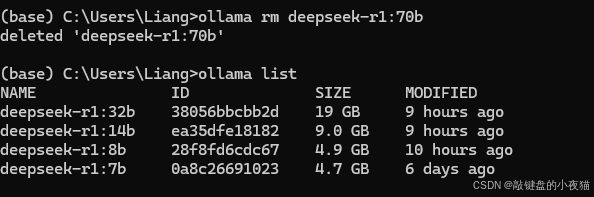
5.2 Miniconda安装与环境管理
Miniconda作为Python环境管理工具,在DeepSeek模型部署中发挥着基础性作用。下面详细解析其安装配置流程和最佳实践:
5.2.1 为什么选择Miniconda?
Miniconda在大语言模型部署中的价值远超过简单的Python包管理工具:
- 依赖隔离:创建独立的Python环境,避免不同项目间的依赖冲突。这一点对于DeepSeek尤为重要,因为它可能依赖特定版本的PyTorch、transformers等库。
- 版本精确控制:能够精确指定每个依赖包的版本,确保模型在不同环境中行为一致。例如,某些特性可能仅在特定版本的CUDA或PyTorch中可用。
- 资源优化:相比完整的Anaconda,Miniconda仅包含必要组件,节省磁盘空间和内存占用,为模型运行保留更多资源。
- 可复制部署:通过environment.yml文件,可以在不同机器上精确复制相同的运行环境,确保部署一致性。
- CUDA工具链整合:简化GPU加速环境配置,自动解决CUDA、cuDNN等与PyTorch的兼容性问题。
5.2.2 安装流程详解

获取安装包 : 从清华大学开源镜像站下载适合您系统的Miniconda安装包: Index of /anaconda/miniconda/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
Windows系统安装步骤:
- 下载.exe安装文件后双击运行
- 阅读并接受许可协议
- 选择"Just Me"(推荐)或"All Users"
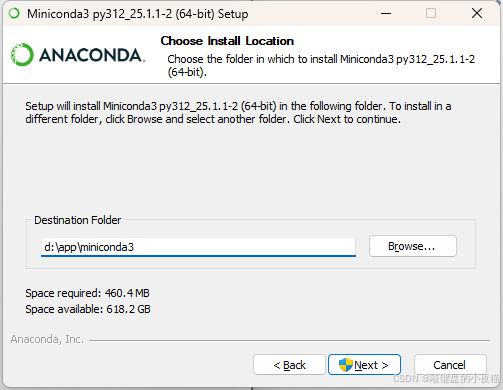
- 选择安装位置(建议默认路径)
- 重要:勾选"Add Miniconda3 to my PATH environment variable",确保可以从命令行直接使用conda命令
- 安装完成后,打开命令提示符,输入
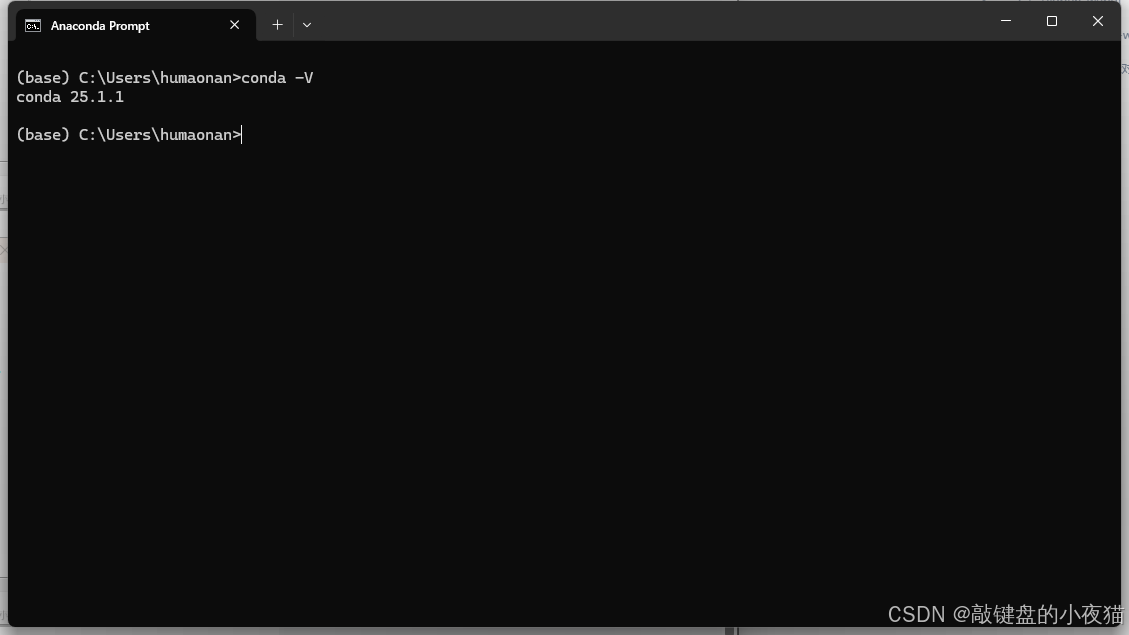
conda --version验证安装
macOS系统安装步骤:
- 下载.pkg安装文件后双击运行
- 按照安装向导完成安装
- 安装完成后,打开终端,输入
conda --version验证安装
Linux系统安装步骤:
- 下载.sh脚本文件
- 打开终端,进入下载目录
- 执行
chmod +x Miniconda3-latest-Linux-x86_64.sh赋予执行权限 - 运行
./Miniconda3-latest-Linux-x86_64.sh开始安装 - 按提示操作,并在询问是否将conda添加到PATH时选择"yes"
- 安装完成后,关闭并重新打开终端,输入
conda --version验证安装
5.2.3 Windows安装步骤(图示)
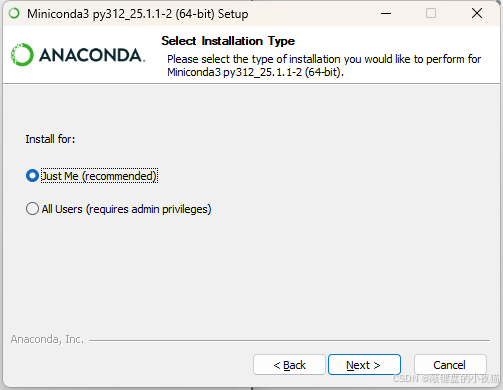
可以全部选项都勾选上,这样可以直接通过cmd命令窗口使用conda
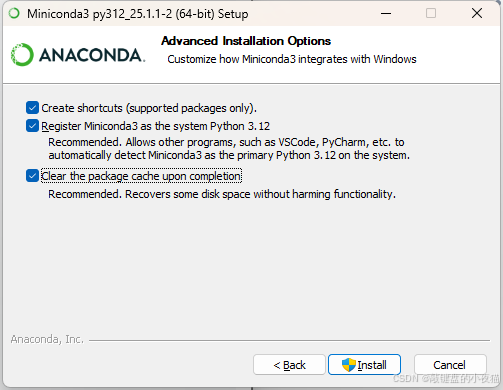
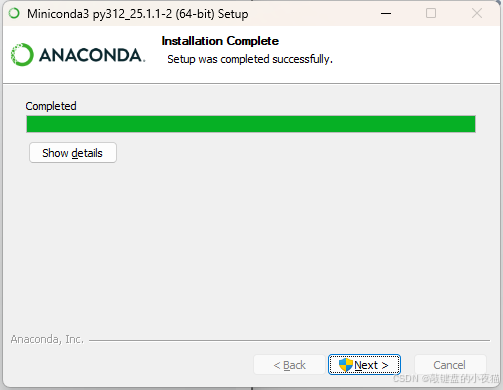

5.2.4 环境配置与优化
配置国内镜像源: 为提高下载速度,建议配置国内镜像源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes创建专用环境: 为DeepSeek创建独立环境,避免与其他项目冲突:
conda create -n deepseek python=3.10激活环境: 使用以下命令激活刚创建的环境:
conda activate deepseek环境管理常用命令:
- 查看已创建的环境:
conda env list - 删除不需要的环境:
conda env remove -n 环境名称 - 导出环境配置:
conda env export > environment.yml - 从配置文件创建环境:
conda env create -f environment.yml
5.2 Open-WebUI界面配置:可视化交互平台
Open-WebUI是一个为大语言模型提供图形化交互界面的开源工具,极大简化了与DeepSeek模型的交互过程。以下是其详细配置流程和使用指南:
5.2.1 Open-WebUI的价值与功能
核心价值:
- 提供直观的图形化界面,无需记忆复杂命令
- 支持多会话管理和历史记录保存
- 提供丰富的提示词模板和参数调整选项
- 支持多模型切换和比较功能
- 内置文件上传和知识库构建能力
技术架构:Open-WebUI采用前后端分离设计,前端使用React框架,后端基于Python的FastAPI,与Ollama通过API进行通信,保证了界面响应迅速和功能扩展的灵活性。
5.2.2 环境准备与安装流程
创建专用工作区:
conda create -n open-webui python=3.11验证创建是否成功
conda info -e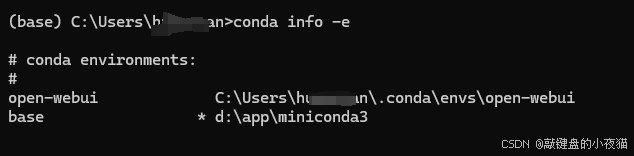
激活工作区:
conda activate open-webui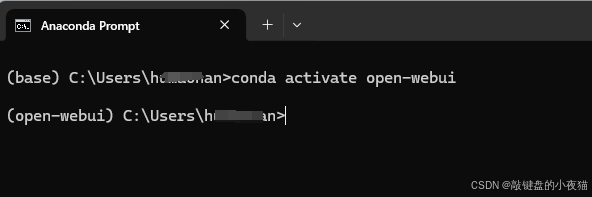
配置PyPI镜像源: 使用国内镜像源加速包下载:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
安装Open-WebUI:
pip install open-webui
安装过程中会自动解决依赖关系,包括必要的Web框架和接口组件。
5.2.3 启动与访问配置
启动服务:
open-webui serve
首次启动时,服务会自动完成初始化配置,包括创建配置文件和数据库。
访问界面: 在浏览器中打开以下地址:
http://localhost:8080/
首次配置:
1.创建管理员账户(设置用户名和密码)


2.连接到本地Ollama服务
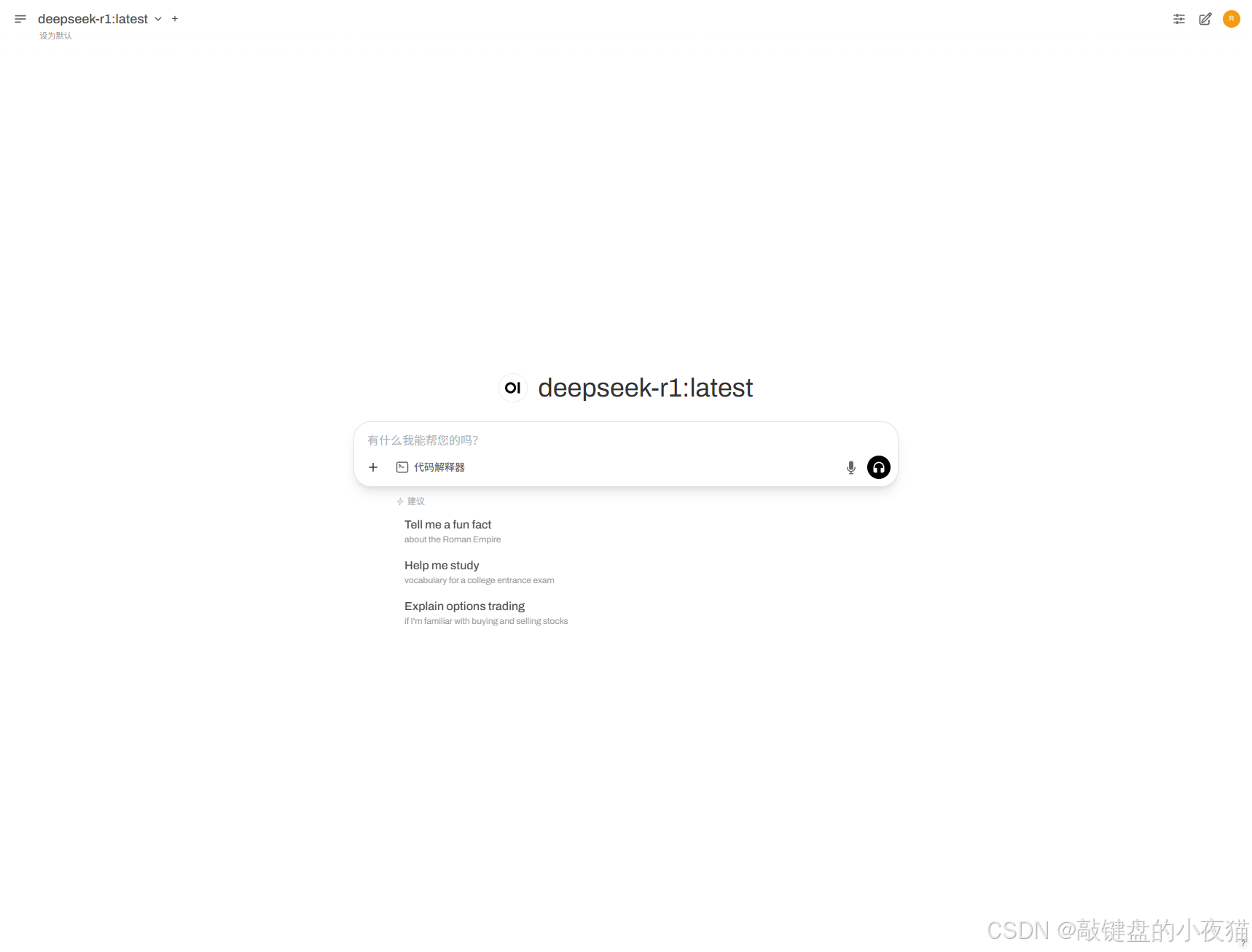
5.2.4 高级配置与性能优化
自定义端口: 如果默认端口被占用,可以指定其他端口:
open-webui serve --port 8088允许远程访问: 默认情况下,Open-WebUI只允许本机访问。要启用远程访问:
open-webui serve --host 0.0.0.0提高并发能力: 对于多用户场景,可以增加工作进程数:
open-webui serve --workers 4持久化运行: 在生产环境中,可以使用nohup或systemd确保服务在后台持续运行:
nohup open-webui serve > webui.log 2>&1 &5.2.5 界面功能与使用技巧
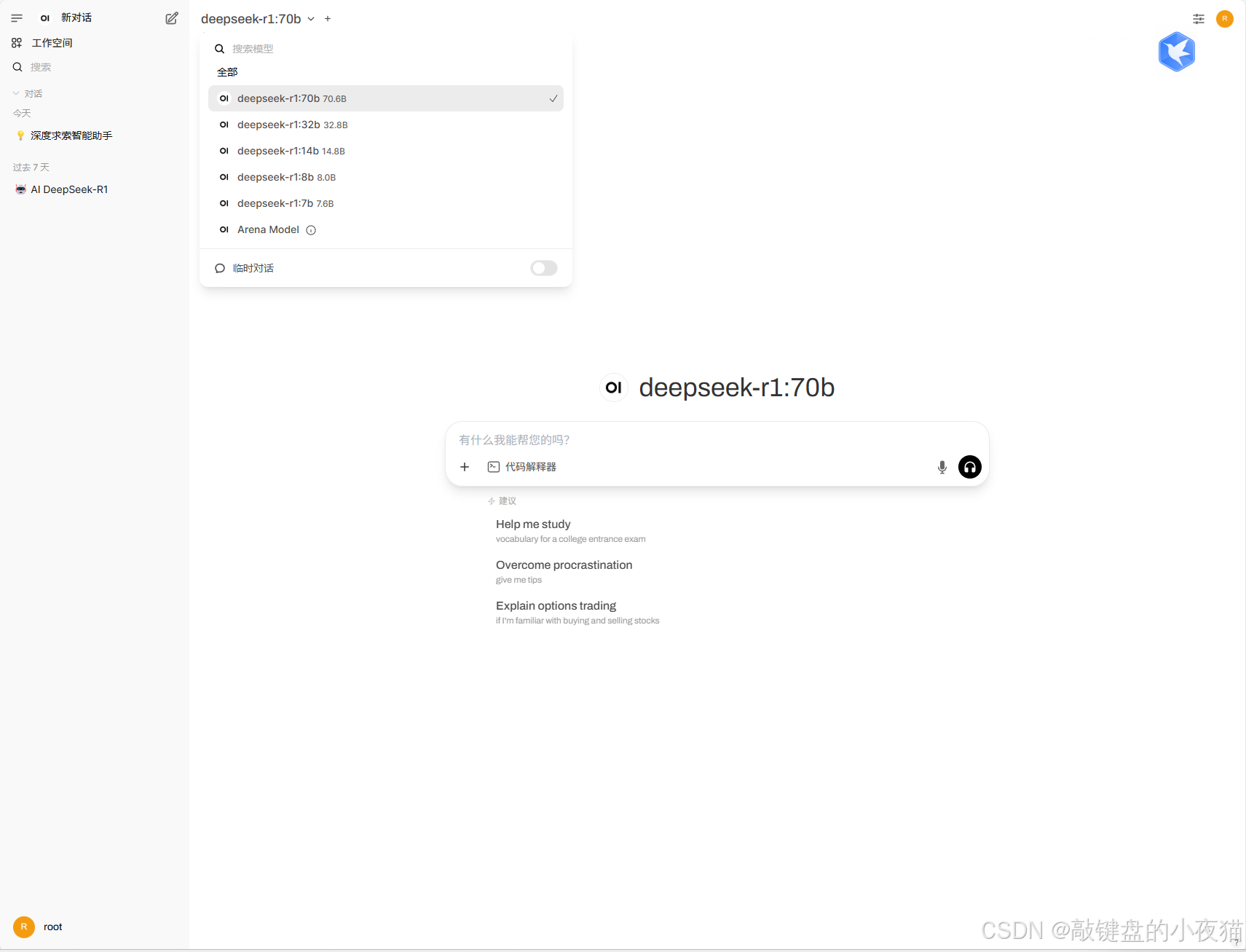
多模型切换: Open-WebUI可以同时连接多个已安装的模型,通过界面右上角的下拉菜单轻松切换不同模型。
参数调整: 通过设置面板可以调整模型的各项参数:
- Temperature(温度):控制输出的随机性
- Top P:控制词汇选择的多样性
- Max Tokens:限制生成文本的最大长度
- Context Window:控制模型可见的上下文窗口大小
提示词模板: 内置多种提示词模板,帮助用户快速构建有效的提示,如:
- 角色扮演模板
- 代码生成模板
- 内容创作