KIMI-VL:具有增强推理能力的有效开源视觉语言模型
原文地址:https://arxiv.org/pdf/2504.07491v1
开源地址:https://github.com/MoonshotAI/Kimi-VL
目录
简介
视觉语言模型 (VLM) 在人工智能领域正变得越来越重要,使系统能够处理和理解视觉和文本信息。Kimi-VL 代表了开源 VLM 的一项重大进步,解决了开源模型与 GPT-4o 和 Google Gemini 等专有解决方案之间的性能差距。该模型由 Moonshot AI 的 Kimi 团队开发,在效率、可扩展性和推理能力方面进行了创新。
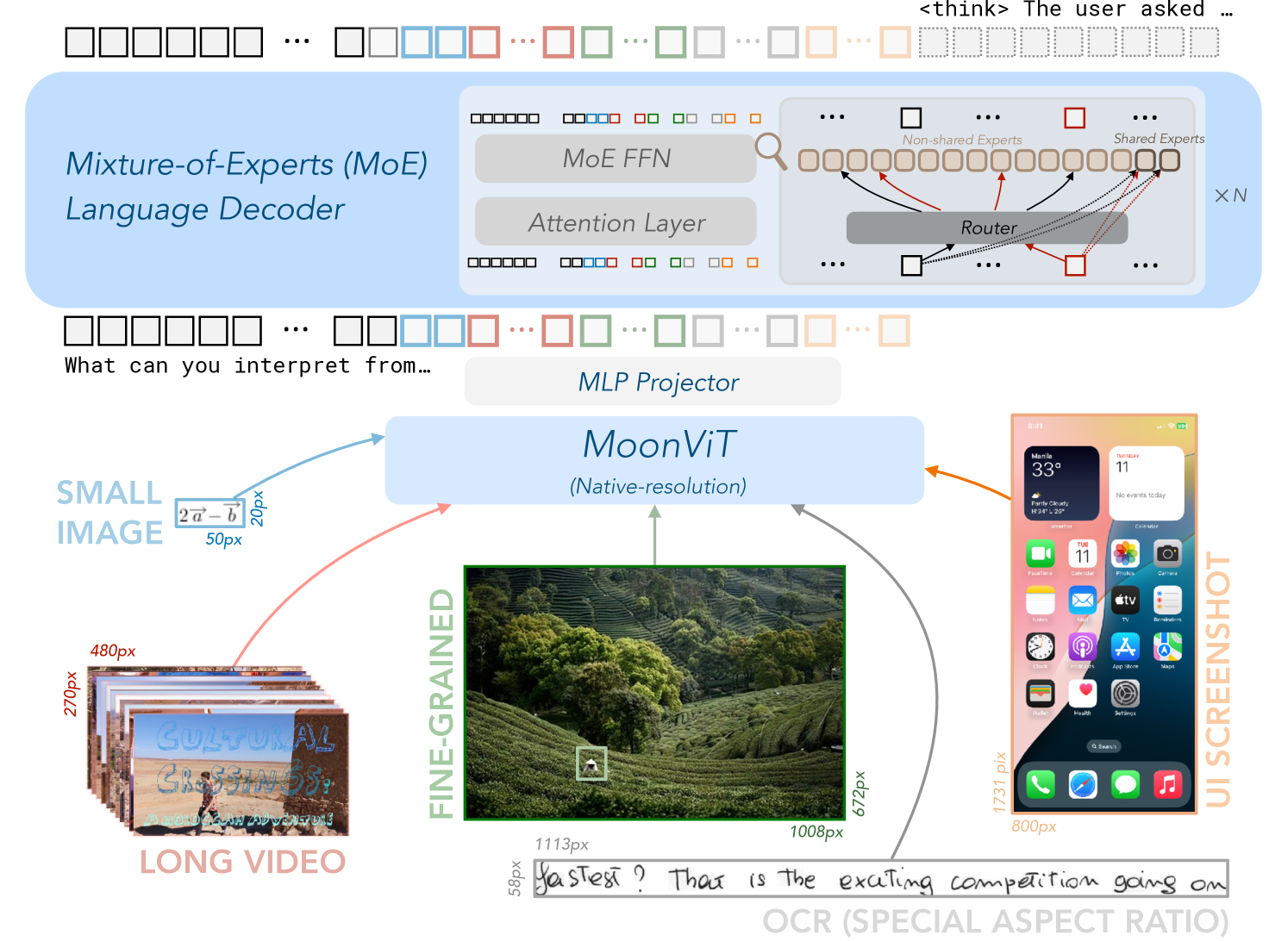
图 1:Kimi-VL 架构,展示了 MoonViT 视觉编码器处理各种输入类型、MLP 投影仪和混合专家 (MoE) 语言模型。
Kimi-VL 的独特之处在于其混合专家 (MoE) 架构,该架构允许构建更高效的模型,仅激活 28 亿个参数(总共 160 亿个),同时保持与更大模型相媲美的性能。该模型还具有原生分辨率视觉编码器 (MoonViT),可以处理原始分辨率的图像而无需子图像分割,并支持 128K tokens 的扩展上下文窗口,使其能够处理复杂的、多轮交互和长篇内容。
架构概述
Kimi-VL 的架构包含三个主要组成部分:
-
MoonViT 视觉编码器:一种原生分辨率视觉编码器,可以处理各种分辨率的图像,而无需进行子图像分割。这使得 Kimi-VL 能够处理各种视觉输入,包括小图像、精细细节、长视频、UI 截图以及具有特殊纵横比的 OCR 内容。该编码器采用了一种打包方法和 2D 旋转位置嵌入 (RoPE) 来保持空间关系。
-
MLP 投影仪:用作视觉编码器和语言模型之间的桥梁,将视觉特征与语言表示空间对齐。
-
MoE 语言模型 (Moonlight):基于 DeepSeek-V3,该组件使用 MoE 架构,激活了 28 亿个参数(总共 160 亿个)。MoE 方法使模型能够在保持高性能的同时,保持可控的计算成本。
整个训练过程中使用的优化器是 Muon 的增强版本,它仔细调整了每个参数的更新规模,并包括权重衰减以提高训练稳定性和模型性能。
训练方法
Kimi-VL 的开发遵循结构化的多阶段方法:

图 2:Kimi-VL 的预训练阶段,展示了从文本预训练到联合预训练、冷却和长上下文激活的进展。
-
预训练阶段:
- 使用 5.2T 数据进行文本预训练
- 使用 2.0T 数据进行视觉编码器 (ViT) 训练
- 使用 1.4T 数据进行联合预训练(高达 40% 的多模态)
- 使用 0.6T 高质量文本和多模态数据进行联合冷却
- 使用 0.3T 数据进行联合长上下文激活,将 RoPE 基数从 50,000 扩展到 800,000
-
后训练阶段:

图 3:后训练流程,展示了监督微调、长链思考 (CoT) 监督微调和强化学习阶段。
- 联合监督微调 (SFT) 以增强指令遵循能力
- 长链思维 (CoT) SFT 以实现详细的推理
- 强化学习进一步提高推理能力,并对过长的回复进行惩罚
-
数据构建: 训练利用了多样化的多模态数据,包括字幕数据、交错数据、OCR 数据、知识数据、代理数据和视频数据,这些数据经过精心策划,以确保高质量和非重复性。
-
基础设施: 训练采用了 4D 并行(数据、专家、流水线和上下文并行)和 ZeRO1 优化策略,以提高内存效率并减少通信开销。
关键能力
Kimi-VL 展示了几个关键能力,使其区别于其他模型:
-
原生高分辨率处理: MoonViT 编码器可以处理原始分辨率的图像,从而能够精确理解视觉细节和复杂文档。
-
长上下文理解: 凭借 128K 的上下文窗口,Kimi-VL 可以处理冗长的文档、视频和多轮对话,并在整个过程中保持上下文感知。
-
OCR 和文档理解: 该模型擅长解析表格、数学方程式和图像中的文本,并将其准确地转换为 Markdown 等结构化格式。
-
多语言支持: Kimi-VL 在理解和生成多种语言(包括中文)的内容方面表现出强大的性能,正如其解决中文几何问题的能力所表明的那样。
-
UI 导航和交互: 该模型可以解释 UI 元素并引导用户浏览应用程序界面,如 Chrome 设置导航示例所示。
-
强大的视觉推理: 通过其增强的推理能力,Kimi-VL 可以解决需要视觉感知和逻辑推理的复杂问题。
性能基准
Kimi-VL 在各种基准测试中都取得了具有竞争力的性能,特别是与参数数量相似或更大的模型相比:
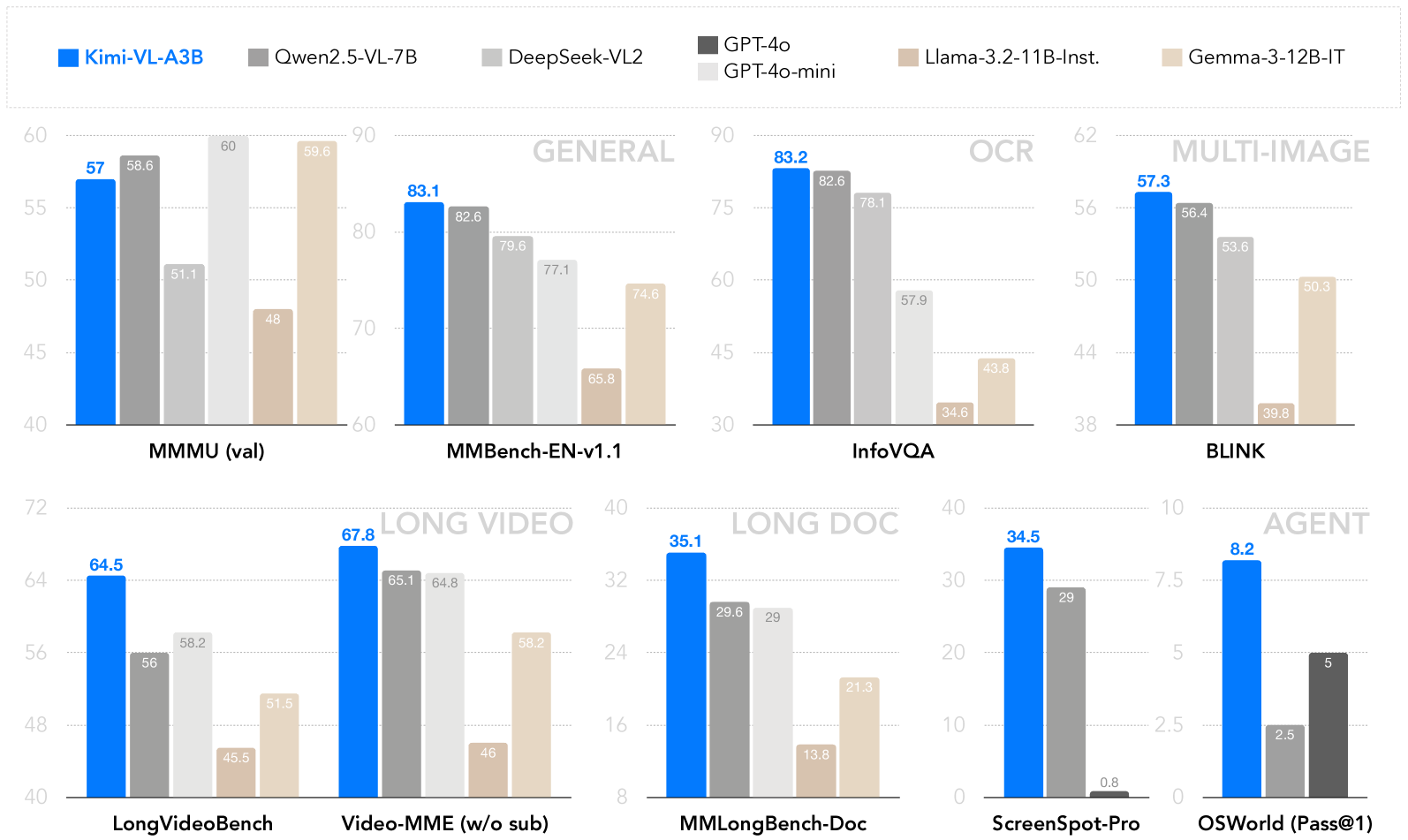
图 4:Kimi-VL-A3B 在各种基准类别中的比较性能,包括通用 VLM 任务、OCR、多图像处理、长视频理解、文档理解和代理能力。
在数学推理任务中,Kimi-VL-Thinking 以最少的参数展示了卓越的性能:
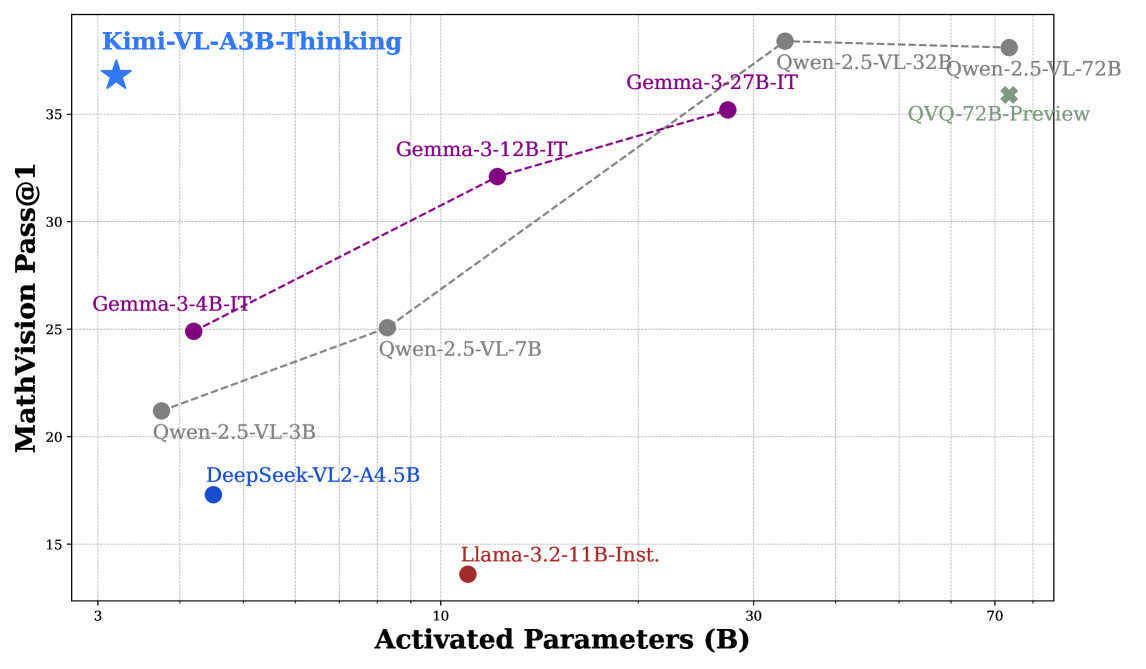
图 5:MathVision 性能比较,显示 Kimi-VL-A3B-Thinking 以更少的激活参数实现了优于其他模型的结果。
该模型在以下方面表现出强大的性能:
- MMMU (Massive Multitask Multimodal Understanding) 准确率 57%
- MMBench-EN 准确率 83.1%
- InfoVQA 准确率 83.2%
- LongVideoBench 准确率 64.5%
- MMLongBench-Doc 准确率 35.1%
- ScreenSpot-Pro 准确率 34.5%
通过长链思维增强推理能力
Kimi-VL 尤其值得关注的一个方面是通过实施长链思维 (CoT) 处理来增强推理能力。 这种方法最终促成了 Kimi-VL-Thinking 的开发,通过以下方式显着提高了模型解决复杂问题的能力:
- 将复杂的任务分解为更小、更易于管理的步骤
- 明确详细地描述其推理过程
- 在提供最终答案之前评估和改进其方法

图 6:Kimi-VL 分析爱因斯坦手稿的思维过程示例,展示了详细的逐步推理。
这种方法的有效性体现在模型性能随思维 token 长度的扩展上:
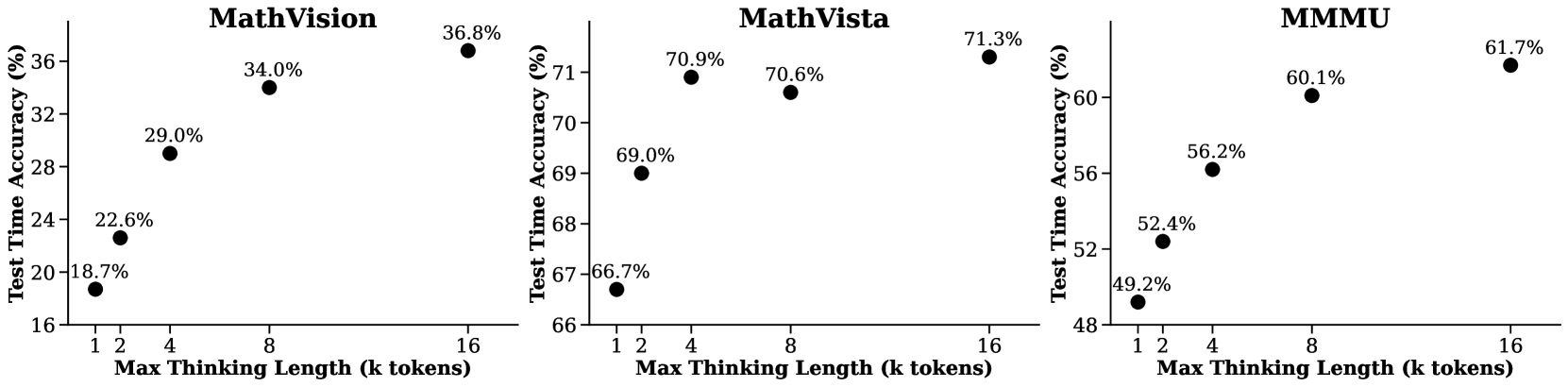
图 7:在 MathVision、MathVista 和 MMMU 基准测试中,测试时准确率随最大思考长度的变化而变化。
如图所示,将最大思考 token 长度从 1k 增加到 16k,可以显著提高数学推理基准测试的准确性:MathVision(从 18.7% 提高到 36.8%),MathVista(从 66.7% 提高到 71.3%),以及 MMMU(从 49.2% 提高到 61.7%)。这表明,允许模型拥有更多的"思考空间"可以使其更有效地解决复杂问题。
应用
Kimi-VL 的能力使其适用于广泛的应用:
- UI 导航和指导:该模型可以指导用户完成复杂的界面,如其在 Chrome 设置中导航的能力所示。
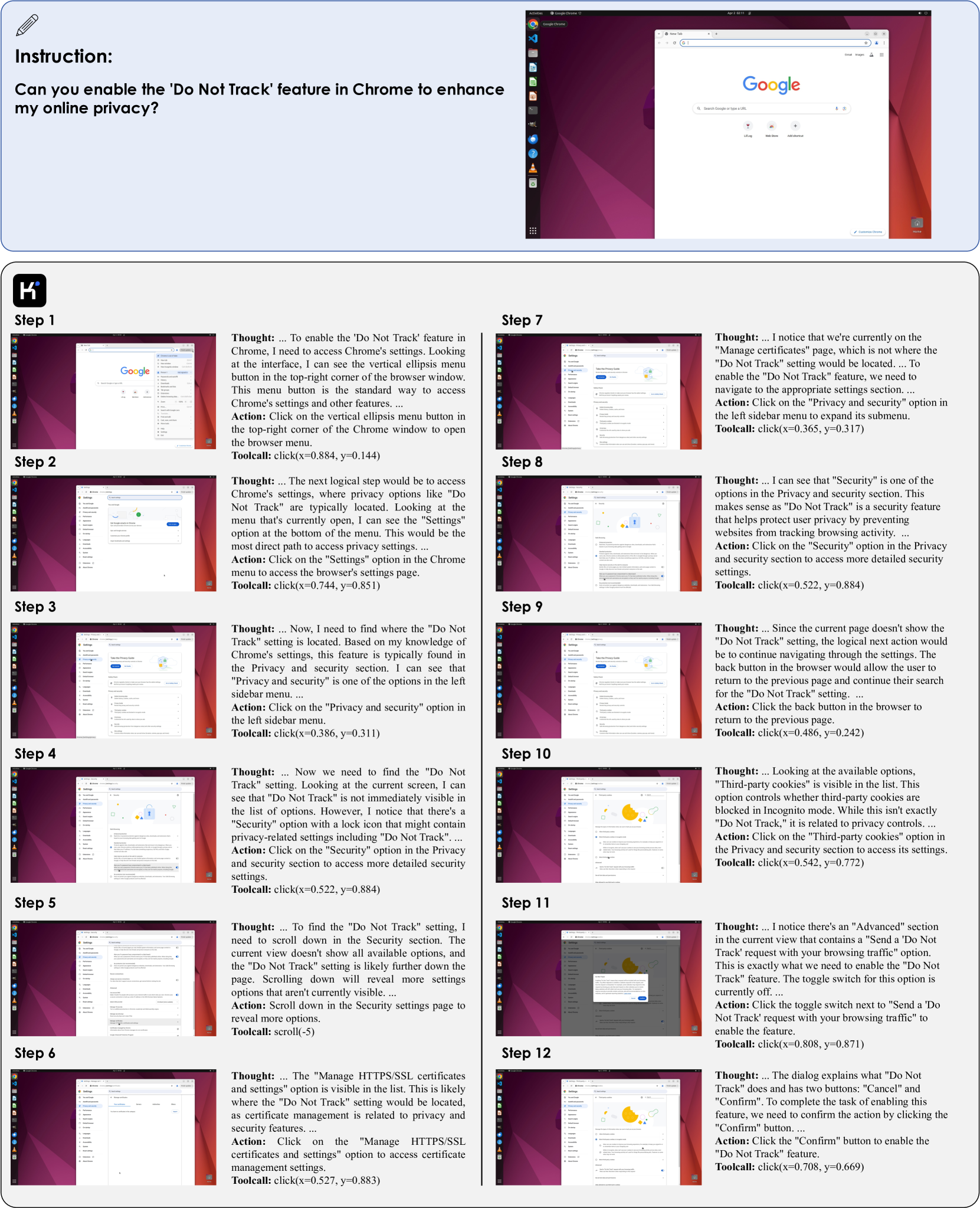
图 8:Kimi-VL 演示逐步 UI 导航以启用 Chrome 中的"请勿跟踪"功能。
- 视频理解:该模型可以从视频内容中提取信息和见解,理解事件的进展和随时间变化的内容。
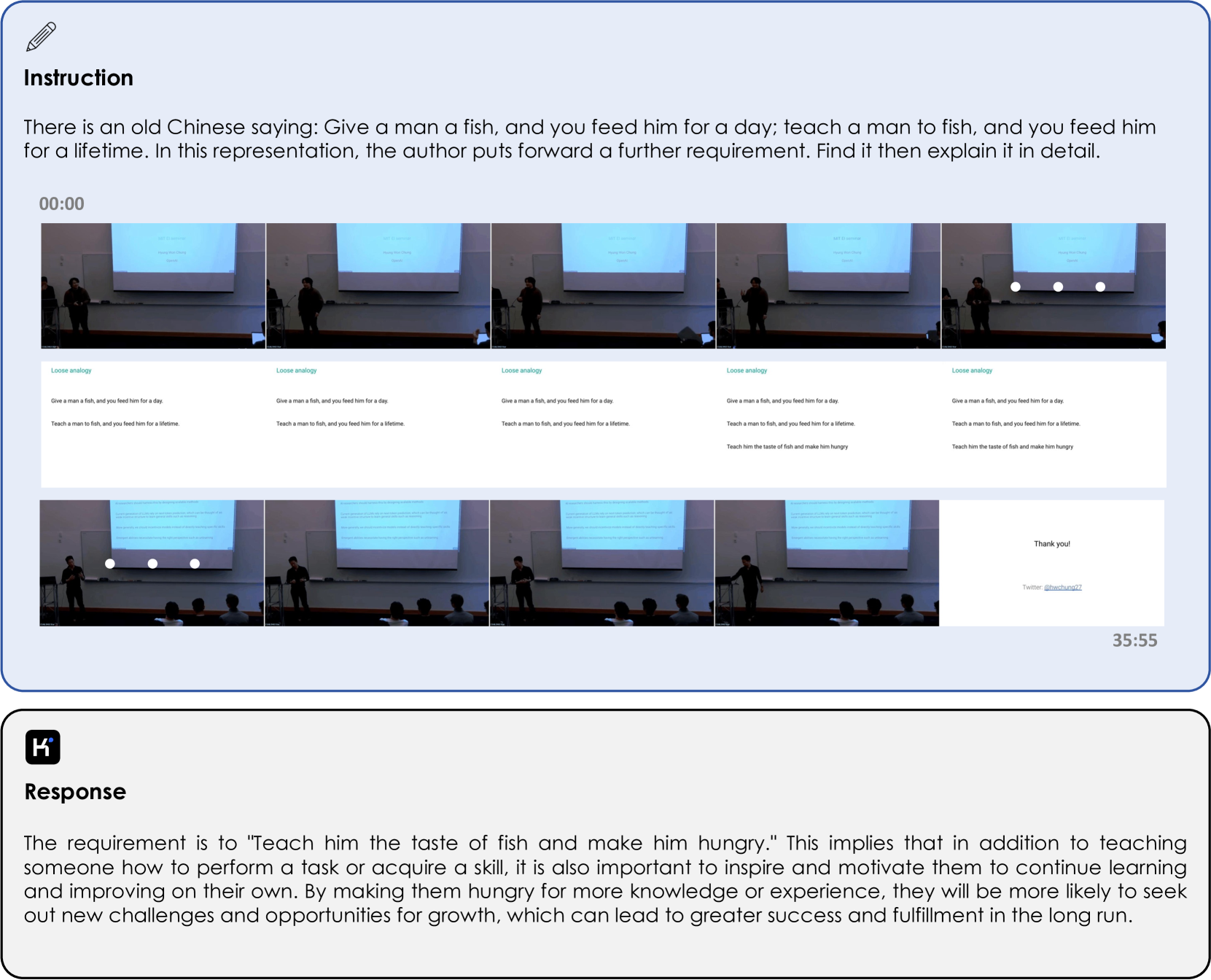
图 9:Kimi-VL 分析视频内容以识别和解释演示文稿中对中国谚语的修改。
- 文档分析:Kimi-VL 擅长从复杂文档(包括表格和公式)中提取和格式化信息。
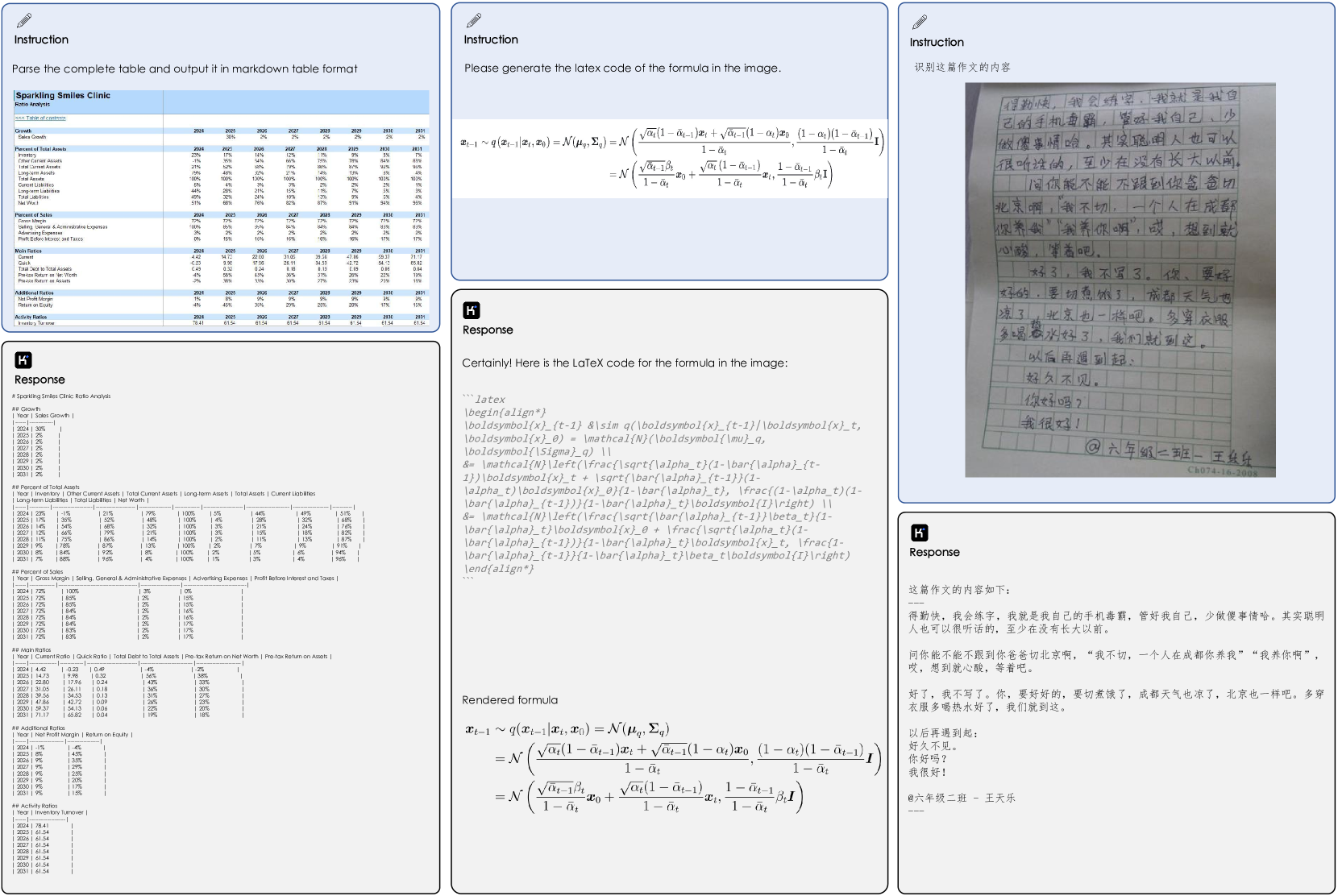
图 10:Kimi-VL 处理表格、数学公式和手写文本的示例。
- 视觉问答:该模型可以高精度地回答有关图像的问题,即使是对于复杂的场景或专业知识也是如此。

图 11:Kimi-VL 回答各种视觉问题的示例,从识别地标到识别视频游戏环境。
- 数学问题解决:Kimi-VL 可以理解和解决以视觉方式呈现的数学问题,并逐步展示其工作过程。

图 12:Kimi-VL 解决了一个用中文呈现的几何问题,展示了语言的多功能性和数学推理能力。
结论
Kimi-VL 代表了开源视觉语言模型领域的重大进步。通过将高效的 MoE 架构与原生分辨率视觉编码器和扩展的上下文窗口相结合,该模型在广泛的任务中实现了有竞争力的性能,同时保持了合理的计算要求。
通过 Long-CoT 监督微调和强化学习开发的 Kimi-VL-Thinking 进一步增强了模型的推理能力,使其能够解决需要视觉理解和逻辑推理的复杂问题。
Kimi-VL 的主要贡献包括:
- 一种高效的开源 VLM,仅激活 2.8B 参数,即可实现与更大的模型相比具有竞争力的性能
- 一种原生分辨率视觉编码器,可以处理各种视觉输入,而没有分辨率限制
- 一个 128K 上下文窗口,可以处理长文档、视频和多轮对话
- 通过 Long-CoT 处理增强推理能力
- 在通用 VLM 任务、OCR、文档理解和数学推理方面表现出色
这些进步使 Kimi-VL 成为一个多功能的工具,适用于广泛的应用,从 UI 导航和文档处理到复杂的问题解决和教育辅助。作为一种开源模型,Kimi-VL 有助于先进 AI 能力的民主化,使研究人员、开发者和终端用户更容易获得强大的多模态理解能力。