题目
给你一个变量对数组 equations 和一个实数值数组 values 作为已知条件,其中 equationsi = Ai, Bi 和 valuesi 共同表示等式 Ai / Bi = valuesi 。每个 Ai 或 Bi 是一个表示单个变量的字符串。
另有一些以数组 queries 表示的问题,其中 queriesj = Cj, Dj 表示第 j 个问题,请你根据已知条件找出 Cj / Dj = ? 的结果作为答案。
返回 所有问题的答案 。如果存在某个无法确定的答案,则用 -1.0 替代这个答案。如果问题中出现了给定的已知条件中没有出现的字符串,也需要用 -1.0 替代这个答案。
注意:输入总是有效的。你可以假设除法运算中不会出现除数为 0 的情况,且不存在任何矛盾的结果。
注意:未在等式列表中出现的变量是未定义的,因此无法确定它们的答案。
一、代码实现
go
func calcEquation(equations [][]string, values []float64, queries [][]string) []float64 {
// 创建变量名到唯一ID的映射
idMap := make(map[string]int)
id := 0
for _, eq := range equations {
a, b := eq[0], eq[1]
if _, exists := idMap[a]; !exists {
idMap[a] = id
id++
}
if _, exists := idMap[b]; !exists {
idMap[b] = id
id++
}
}
// 初始化并查集的父节点和权重数组
parent := make([]int, id)
weight := make([]float64, id)
for i := 0; i < id; i++ {
parent[i] = i
weight[i] = 1.0
}
// 查找根节点并路径修正返回值括号)
var find func(int) (int, float64)
find = func(x int) (int, float64) { // 此处添加返回值括号
if parent[x] != x {
root, w := find(parent[x])
parent[x] = root
weight[x] *= w
}
return parent[x], weight[x]
}
// 合并节点
for i, eq := range equations {
a, b := eq[0], eq[1]
x, y := idMap[a], idMap[b]
val := values[i]
rootX, wX := find(x)
rootY, wY := find(y)
if rootX != rootY {
parent[rootX] = rootY
weight[rootX] = (val * wY) / wX
}
}
// 处理查询
results := make([]float64, len(queries))
for i, q := range queries {
c, d := q[0], q[1]
idC, okC := idMap[c]
idD, okD := idMap[d]
if !okC || !okD {
results[i] = -1.0
continue
}
rootC, wC := find(idC)
rootD, wD := find(idD)
if rootC != rootD {
results[i] = -1.0
} else {
results[i] = wC / wD
}
}
return results
}二、算法分析
1. 核心思路
- 带权并查集:将每个变量视为节点,维护其到父节点的权重(即变量间的比值)。
- 路径压缩优化:在查找根节点时,直接更新路径上所有节点的父节点为根节点,并同步更新权重。
- 动态合并:根据等式关系调整不同集合的根节点权重,确保比值计算正确。
2. 关键步骤
- 初始化:为每个变量创建独立集合,父节点初始化为自身,权重为1.0。
- 合并集合:遍历等式,通过路径压缩找到变量的根节点,并根据等式值调整根节点权重。
- 查询处理:检查变量是否存在,若存在且同根则返回权重比值,否则返回-1.0。
3. 复杂度
| 指标 | 值 | 说明 |
|---|---|---|
| 时间复杂度 | O(α(n)) | α为阿克曼函数的反函数,接近常数 |
| 空间复杂度 | O(n) | 存储n个变量的父节点和权重 |
三、图解示例
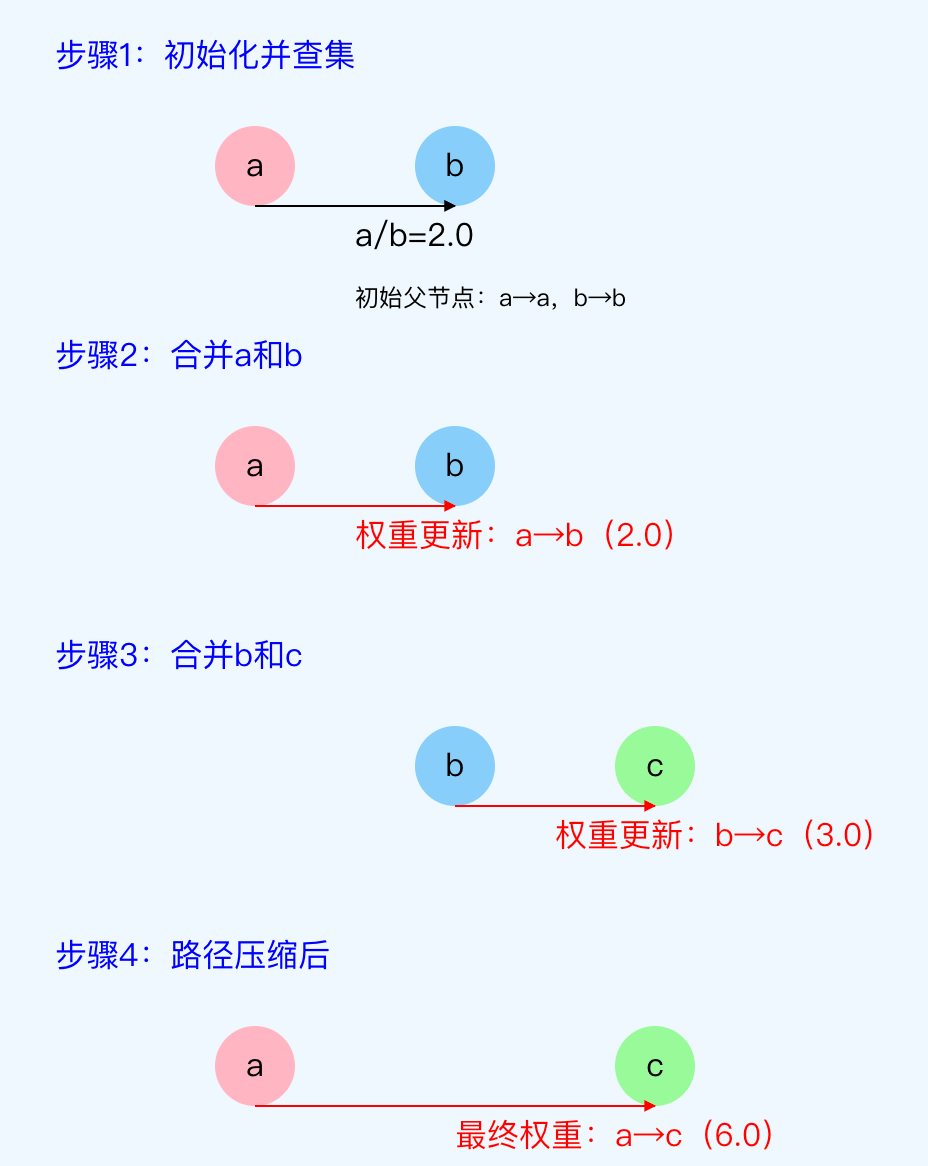
四、边界条件与扩展
1. 特殊场景验证
- 变量未定义 :查询中出现未在等式中出现的变量(如
x/x),返回-1.0。 - 自反查询 :查询相同变量(如
a/a),路径压缩后权重为1.0,返回1.0。 - 多级路径 :链式关系(如
a→b→c→d)通过路径压缩优化为直接连接。
2. 扩展应用
- 动态更新等式:支持实时添加新等式,动态调整并查集结构。
- 图论连通性:判断变量间是否存在连通路径(若根相同则连通)。
- 复杂数学关系:处理包含加减乘除的复合表达式(需扩展权重计算逻辑)。
3. 多语言实现
python
class Solution:
def calcEquation(self, equations, values, queries):
parent = {}
weight = {}
# 初始化并查集
for a, b in equations:
if a not in parent:
parent[a] = a
weight[a] = 1.0
if b not in parent:
parent[b] = b
weight[b] = 1.0
# 路径压缩的查找函数
def find(x):
if parent[x] != x:
orig_parent = parent[x]
parent[x] = find(parent[x])
weight[x] *= weight[orig_parent] # 路径压缩时更新权重
return parent[x]
# 合并操作
for (a, b), val in zip(equations, values):
ra, rb = find(a), find(b)
if ra != rb:
parent[ra] = rb
weight[ra] = (val * weight[b]) / weight[a] # 根据等式调整根节点权重
# 处理查询 (修正continue语句语法错误)
res = []
for c, d in queries:
# Case 1: 变量未定义
if c not in parent or d not in parent:
res.append(-1.0)
continue # 移至下一循环
# Case 2: 计算路径权重
rc, rd = find(c), find(d)
if rc != rd:
res.append(-1.0)
else:
res.append(weight[c] / weight[d])
return res
java
class Solution {
Map<String, String> parent = new HashMap<>();
Map<String, Double> weight = new HashMap<>();
public double[] calcEquation(List<List<String>> equations, double[] values, List<List<String>> queries) {
// 初始化并查集
for (List<String> eq : equations) {
String a = eq.get(0), b = eq.get(1);
parent.putIfAbsent(a, a);
parent.putIfAbsent(b, b);
weight.putIfAbsent(a, 1.0);
weight.putIfAbsent(b, 1.0);
}
// 合并操作
for (int i = 0; i < equations.size(); i++) {
String a = equations.get(i).get(0), b = equations.get(i).get(1);
union(a, b, values[i]);
}
// 处理查询
double[] res = new double[queries.size()];
for (int i = 0; i < queries.size(); i++) {
String c = queries.get(i).get(0), d = queries.get(i).get(1);
if (!parent.containsKey(c) || !parent.containsKey(d)) {
res[i] = -1.0;
continue;
}
String rc = find(c), rd = find(d);
if (!rc.equals(rd)) res[i] = -1.0;
else res[i] = weight.get(c) / weight.get(d);
}
return res;
}
private String find(String x) {
if (!x.equals(parent.get(x))) {
String origParent = parent.get(x);
parent.put(x, find(origParent));
weight.put(x, weight.get(x) * weight.get(origParent));
}
return parent.get(x);
}
private void union(String a, String b, double val) {
String ra = find(a), rb = find(b);
if (ra.equals(rb)) return;
parent.put(ra, rb);
weight.put(ra, (val * weight.get(b)) / weight.get(a));
}
}五、总结与优化
1. 方法对比
| 方法 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| 带权并查集 | 查询高效,支持动态合并 | 实现复杂度较高 | 大规模数据集和频繁查询 |
| DFS/BFS | 实现简单 | 重复计算,时间复杂度高 | 小规模数据或低频查询 |
2. 工程优化
- 路径压缩:确保查找操作接近常数时间复杂度。
- 按秩合并:优化树的高度(可选,Java示例未实现)。
- 内存管理:使用哈希表动态扩展,避免预分配固定大小。