PyTorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(三)
Wasserstein GAN的梯度惩罚机制与模式坍塌问题
6. 自回归生成与多样性控制
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# 自回归生成器网络
class AutoregressiveGenerator(nn.Module):
"""自回归生成器,逐步生成图像,有助于保持结构一致性和多样性"""
def __init__(self, latent_dim, img_size=32, channels=3, n_steps=4):
super(AutoregressiveGenerator, self).__init__()
self.latent_dim = latent_dim
self.img_size = img_size
self.channels = channels
self.n_steps = n_steps # 生成步骤数
# 每个步骤的分辨率
self.resolution_steps = [img_size // (2 ** (n_steps - i)) for i in range(1, n_steps + 1)]
# 初始生成器(最低分辨率)
self.initial_generator = nn.Sequential(
nn.Linear(latent_dim, 128 * 4 * 4),
nn.LeakyReLU(0.2),
nn.Unflatten(1, (128, 4, 4))
)
# 创建多步骤上采样模块
self.upsample_modules = nn.ModuleList()
for i in range(n_steps - 1):
in_channels = 128 if i == 0 else 64
# 每个上采样模块包含前一步骤的条件和当前噪声输入
self.upsample_modules.append(
UpsampleBlock(in_channels, 64, latent_dim)
)
# 最终输出层
self.final_conv = nn.Sequential(
nn.Conv2d(64, channels, kernel_size=3, padding=1),
nn.Tanh()
)
def forward(self, z):
"""
自回归生成过程
z: [batch_size, n_steps, latent_dim] - 多步骤的噪声输入
"""
batch_size = z.size(0)
# 初始低分辨率特征
x = self.initial_generator(z[:, 0])
# 逐步上采样
for i in range(self.n_steps - 1):
# 使用当前特征和下一步的噪声
x = self.upsample_modules[i](x, z[:, i+1])
# 最终输出
x = self.final_conv(x)
return x
def generate_with_noise_variation(self, batch_size, device, variation_level=0.5):
"""
生成具有不同级别噪声变化的图像批次
variation_level: 0表示每个步骤使用相同噪声,1表示每个步骤使用完全不同的噪声
"""
# 创建基础噪声
base_noise = torch.randn(batch_size, 1, self.latent_dim, device=device)
# 为每个步骤创建不同的噪声
varied_noise = torch.randn(batch_size, self.n_steps - 1, self.latent_dim, device=device)
# 按变化级别混合基础噪声和变化噪声
mixed_noise = base_noise.repeat(1, self.n_steps - 1, 1) * (1 - variation_level) + varied_noise * variation_level
# 合并基础噪声和混合噪声
z = torch.cat([base_noise, mixed_noise], dim=1)
# 生成图像
return self.forward(z)
# 上采样块,融合前一步骤的特征和当前步骤的噪声
class UpsampleBlock(nn.Module):
def __init__(self, in_channels, out_channels, noise_dim):
super(UpsampleBlock, self).__init__()
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
# 处理上一步特征的卷积
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
# 噪声处理
self.noise_mapper = nn.Sequential(
nn.Linear(noise_dim, out_channels),
nn.LeakyReLU(0.2)
)
# 融合后的卷积
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.norm = nn.BatchNorm2d(out_channels)
self.act = nn.LeakyReLU(0.2)
def forward(self, x, noise):
# 上采样前一步的特征
x = self.upsample(x)
x = self.conv1(x)
# 处理噪声并注入
batch_size = x.size(0)
noise_feature = self.noise_mapper(noise).view(batch_size, -1, 1, 1)
# 通过加法融合噪声(类似FiLM)
x = x + noise_feature
# 最终处理
x = self.conv2(x)
x = self.norm(x)
x = self.act(x)
return x
# 具有多尺度判别的判别器
class MultiScaleDiscriminator(nn.Module):
"""多尺度判别器,在不同分辨率级别上判别,有助于捕获多尺度特征"""
def __init__(self, img_size=32, channels=3, n_scales=3):
super(MultiScaleDiscriminator, self).__init__()
self.n_scales = n_scales
# 为每个尺度创建单独的判别器
self.discriminators = nn.ModuleList()
for i in range(n_scales):
scale_size = img_size // (2 ** i)
self.discriminators.append(
SingleScaleDiscriminator(scale_size, channels)
)
def forward(self, x):
results = []
# 在每个尺度上进行判别
for i in range(self.n_scales):
if i > 0:
# 下采样到当前尺度
x_scaled = F.avg_pool2d(x, kernel_size=2**i, stride=2**i)
else:
x_scaled = x
# 获取当前尺度的判别结果
scale_result = self.discriminators[i](x_scaled)
results.append(scale_result)
# 返回所有尺度的结果
return results
# 单尺度判别器
class SingleScaleDiscriminator(nn.Module):
def __init__(self, img_size, channels):
super(SingleScaleDiscriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 4, 2, 1), nn.LeakyReLU(0.2, inplace=True)]
if bn:
block.append(nn.BatchNorm2d(out_filters))
return block
# 计算需要的下采样层数
n_downsampling = int(np.log2(img_size)) - 2 # 最小特征图大小为4x4
n_downsampling = max(1, n_downsampling) # 至少有一层下采样
modules = []
# 初始层
modules.extend(discriminator_block(channels, 64, bn=False))
# 中间层
in_filters = 64
for i in range(n_downsampling - 1):
out_filters = in_filters * 2
modules.extend(discriminator_block(in_filters, out_filters))
in_filters = out_filters
# 最终层
modules.append(nn.Conv2d(in_filters, 1, 4, 1, 0))
self.model = nn.Sequential(*modules)
def forward(self, img):
return self.model(img)
# 自回归GAN训练函数
def train_autoregressive_gan(generator, discriminator, dataloader,
n_epochs, batch_size, latent_dim, n_steps,
variation_levels=[0.0, 0.3, 0.7, 1.0],
device='cuda'):
"""
训练自回归GAN,测试不同噪声变化级别
参数:
generator: 自回归生成器
discriminator: 多尺度判别器
dataloader: 数据加载器
n_epochs: 训练轮数
batch_size: 批次大小
latent_dim: 潜在空间维度
n_steps: 生成步骤数
variation_levels: 测试的噪声变化级别
device: 计算设备
"""
# 优化器
g_optimizer = torch.optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
# 损失函数
adversarial_loss = torch.nn.BCEWithLogitsLoss()
# 训练循环
for epoch in range(n_epochs):
for i, (real_imgs, _) in enumerate(dataloader):
real_imgs = real_imgs.to(device)
batch_size = real_imgs.size(0)
# 真实样本标签: 1
real_label = torch.ones(batch_size, 1, device=device)
# 生成样本标签: 0
fake_label = torch.zeros(batch_size, 1, device=device)
# -----------------
# 训练判别器
# -----------------
d_optimizer.zero_grad()
# 生成随机噪声
z = torch.randn(batch_size, n_steps, latent_dim, device=device)
# 生成假图像
fake_imgs = generator(z)
# 判别真实图像
real_preds = discriminator(real_imgs)
fake_preds = discriminator(fake_imgs.detach())
# 计算多尺度判别器的损失
d_real_loss = 0
d_fake_loss = 0
for real_pred, fake_pred in zip(real_preds, fake_preds):
d_real_loss += adversarial_loss(real_pred, real_label)
d_fake_loss += adversarial_loss(fake_pred, fake_label)
d_real_loss /= len(real_preds)
d_fake_loss /= len(fake_preds)
# 总判别器损失
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
d_optimizer.step()
# -----------------
# 训练生成器
# -----------------
g_optimizer.zero_grad()
# 生成新的假图像
z = torch.randn(batch_size, n_steps, latent_dim, device=device)
fake_imgs = generator(z)
# 判别生成的图像
fake_preds = discriminator(fake_imgs)
# 计算生成器损失
g_loss = 0
for fake_pred in fake_preds:
g_loss += adversarial_loss(fake_pred, real_label)
g_loss /= len(fake_preds)
g_loss.backward()
g_optimizer.step()
# 打印训练信息
if i % 50 == 0:
print(
f"[Epoch {epoch}/{n_epochs}] [Batch {i}/{len(dataloader)}] "
f"[D loss: {d_loss.item():.4f}] [G loss: {g_loss.item():.4f}]"
)
# 每个epoch结束后,生成并评估不同变化级别的样本
if epoch % 5 == 0:
evaluate_variation_levels(generator, variation_levels, device, epoch)
# 评估不同噪声变化级别的图像多样性
def evaluate_variation_levels(generator, variation_levels, device, epoch):
"""生成并保存不同噪声变化级别的样本图像"""
generator.eval()
with torch.no_grad():
for level in variation_levels:
# 使用当前变化级别生成图像
images = generator.generate_with_noise_variation(8, device, variation_level=level)
# 保存生成的图像
# 这里应该有保存图像的代码,使用torchvision.utils.save_image等
print(f"Epoch {epoch}: Generated images with variation level {level}")
generator.train()自回归生成是一种通过逐步生成图像来改善多样性和一致性的方法。上面的代码实现了:
-
自回归生成器:将图像生成分解为多个步骤,每个步骤可以接受不同的噪声输入,提高多样性控制能力。
-
噪声变化控制:通过控制每个步骤的噪声相关性,可以平衡全局一致性和局部多样性。
-
多尺度判别器:在不同分辨率上评估生成图像,提供更全面的判别信号。
7. 模式坍塌问题与Transformer架构的融合
随着Transformer在生成模型中的应用越来越广泛,它也为解决模式坍塌提供了新的思路:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
# 位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# 创建位置编码矩阵
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
# x: [batch_size, seq_len, d_model]
return x + self.pe[:, :x.size(1), :]
# 基于Transformer的生成器
class TransformerGenerator(nn.Module):
def __init__(self, latent_dim, img_size=32, channels=3, nhead=8, num_layers=6, dim_feedforward=2048, dropout=0.1):
super(TransformerGenerator, self).__init__()
self.latent_dim = latent_dim
self.img_size = img_size
self.channels = channels
# 计算序列长度(将图像视为序列)
self.seq_len = (img_size // 8) ** 2 # 将图像分成8x8的块
self.d_model = 512 # Transformer模型维度
# 潜在向量到序列的映射
self.latent_to_seq = nn.Sequential(
nn.Linear(latent_dim, self.d_model * self.seq_len),
nn.ReLU()
)
# 位置编码
self.pos_encoder = PositionalEncoding(self.d_model)
# Transformer编码器层
encoder_layer = nn.TransformerEncoderLayer(
d_model=self.d_model,
nhead=nhead,
dim_feedforward=dim_feedforward,
dropout=dropout
)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
# 序列到图像特征的映射
self.seq_to_features = nn.Sequential(
nn.Linear(self.d_model, 256),
nn.ReLU()
)
# 上采样到最终图像
self.features_to_image = nn.Sequential(
nn.Unflatten(1, (256, img_size // 8, img_size // 8)),
nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, channels, kernel_size=4, stride=2, padding=1),
nn.Tanh()
)
def forward(self, z):
batch_size = z.size(0)
# 将潜在向量映射到序列
x = self.latent_to_seq(z)
x = x.view(batch_size, self.seq_len, self.d_model)
# 添加位置编码
x = self.pos_encoder(x)
# Transformer处理
x = x.permute(1, 0, 2) # 转换为[seq_len, batch_size, d_model]
x = self.transformer_encoder(x)
x = x.permute(1, 0, 2) # 转换回[batch_size, seq_len, d_model]
# 映射到图像特征
x = self.seq_to_features(x)
x = x.view(batch_size, 256, self.img_size // 8, self.img_size // 8)
# 上采样到最终图像
img = self.features_to_image(x)
return img
# 基于Vision Transformer的判别器
class ViTDiscriminator(nn.Module):
def __init__(self, img_size=32, patch_size=4, channels=3, dim=768, depth=12, heads=12, mlp_dim=3072, dropout=0.1):
super(ViTDiscriminator, self).__init__()
# 计算每个维度的patch数量
assert img_size % patch_size == 0, "Image size must be divisible by patch size"
num_patches = (img_size // patch_size) ** 2
patch_dim = channels * patch_size ** 2
# Patch嵌入
self.patch_embedding = nn.Linear(patch_dim, dim)
# 位置嵌入
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
# 分类token
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
# Transformer编码器
self.transformer = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=dim, nhead=heads, dim_feedforward=mlp_dim, dropout=dropout),
num_layers=depth
)
# 最终分类头
self.to_cls_token = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, 1)
)
# 辅助任务:图像重建(有助于提取更多特征)
self.to_pixels = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, patch_dim),
)
# 保存配置
self.patch_size = patch_size
self.img_size = img_size
self.channels = channels
self.num_patches = num_patches
def forward(self, img):
batch_size = img.size(0)
# 将图像分成patches
patches = img.unfold(2, self.patch_size, self.patch_size).unfold(3, self.patch_size, self.patch_size)
patches = patches.contiguous().view(batch_size, self.channels, -1, self.patch_size * self.patch_size)
patches = patches.permute(0, 2, 1, 3).contiguous().view(batch_size, -1, self.channels * self.patch_size * self.patch_size)
# 线性投影到嵌入空间
x = self.patch_embedding(patches)
# 添加分类token
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
# 添加位置嵌入
x = x + self.pos_embedding
# 通过Transformer
x = x.permute(1, 0, 2) # [seq_len, batch, dim]
x = self.transformer(x)
x = x.permute(1, 0, 2) # [batch, seq_len, dim]
# 获取分类token的输出
cls_token = x[:, 0]
# 真假判断
validity = self.mlp_head(cls_token)
# 图像重建(用于特征匹配损失)
reconstructed_patches = self.to_pixels(x[:, 1:])
return validity, reconstructed_patches
# 改进的特征匹配损失,用于Transformer-GAN
def transformer_feature_matching_loss(real_patches, fake_patches, patch_importance=None):
"""
使用patch级别的特征匹配损失
参数:
real_patches: 真实图像的patches重建
fake_patches: 生成图像的patches重建
patch_importance: patch重要性权重,如果为None则所有patch权重相等
返回:
特征匹配损失
"""
# 如果没有提供权重,则使用均匀权重
if patch_importance is None:
# 计算每个patch的L2距离
patch_distances = F.mse_loss(fake_patches, real_patches, reduction='none').mean(dim=-1)
return patch_distances.mean()
else:
# 权重必须与patch数量匹配
assert patch_importance.size(0) == real_patches.size(1)
# 计算带权重的特征匹配损失
patch_distances = F.mse_loss(fake_patches, real_patches, reduction='none').mean(dim=-1)
weighted_distances = patch_distances * patch_importance.unsqueeze(0)
return weighted_distances.sum(dim=1).mean()
# Transformer-GAN训练函数
def train_transformer_gan(generator, discriminator, dataloader,
n_epochs, batch_size, latent_dim,
device='cuda', lambda_fm=10.0):
"""
训练Transformer-GAN
参数:
generator: Transformer生成器
discriminator: Vision Transformer判别器
dataloader: 数据加载器
n_epochs: 训练轮数
batch_size: 批次大小
latent_dim: 潜在空间维度
device: 计算设备
lambda_fm: 特征匹配损失权重
"""
# 优化器
g_optimizer = torch.optim.Adam(generator.parameters(), lr=0.0001, betas=(0.5, 0.999))
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=0.0001, betas=(0.5, 0.999))
# 损失函数
adversarial_loss = torch.nn.BCEWithLogitsLoss()
# 训练循环
for epoch in range(n_epochs):
for i, (real_imgs, _) in enumerate(dataloader):
real_imgs = real_imgs.to(device)
batch_size = real_imgs.size(0)
# 真实样本标签: 1
real_label = torch.ones(batch_size, 1, device=device)
# 生成样本标签: 0
fake_label = torch.zeros(batch_size, 1, device=device)
# -----------------
# 训练判别器
# -----------------
d_optimizer.zero_grad()
# 判别真实图像
real_validity, real_patches = discriminator(real_imgs)
d_real_loss = adversarial_loss(real_validity, real_label)
# 生成假图像
z = torch.randn(batch_size, latent_dim, device=device)
fake_imgs = generator(z)
# 判别假图像
fake_validity, fake_patches = discriminator(fake_imgs.detach())
d_fake_loss = adversarial_loss(fake_validity, fake_label)
# 总判别器损失
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
d_optimizer.step()
# -----------------
# 训练生成器
# -----------------
g_optimizer.zero_grad()
# 生成新的假图像
z = torch.randn(batch_size, latent_dim, device=device)
fake_imgs = generator(z)
# 判别生成的图像
fake_validity, fake_patches = discriminator(fake_imgs)
# 标准对抗损失
g_adv_loss = adversarial_loss(fake_validity, real_label)
# 特征匹配损失
g_fm_loss = transformer_feature_matching_loss(real_patches.detach(), fake_patches)
# 总生成器损失
g_loss = g_adv_loss + lambda_fm * g_fm_loss
g_loss.backward()
g_optimizer.step()
# 打印训练信息
if i % 50 == 0:
print(
f"[Epoch {epoch}/{n_epochs}] [Batch {i}/{len(dataloader)}] "
f"[D loss: {d_loss.item():.4f}] [G adv: {g_adv_loss.item():.4f}] [G fm: {g_fm_loss.item():.4f}]"
)
# 每个epoch结束后保存模型和示例图像
if epoch % 10 == 0:
# 保存模型
torch.save(generator.state_dict(), f"transformer_gan_generator_epoch_{epoch}.pth")
torch.save(discriminator.state_dict(), f"transformer_gan_discriminator_epoch_{epoch}.pth")
# 生成和保存示例图像
with torch.no_grad():
z = torch.randn(16, latent_dim, device=device)
sample_imgs = generator(z)
# 这里应该有保存图像的代码
print(f"Saved samples for epoch {epoch}")
# 自注意力增强的条件WGAN-GP
class SelfAttentionCWGAN(nn.Module):
"""结合自注意力机制、条件信息和WGAN-GP的混合模型"""
def __init__(self, latent_dim, n_classes, img_size=32, channels=3):
super(SelfAttentionCWGAN, self).__init__()
self.latent_dim = latent_dim
self.n_classes = n_classes
# 生成器
self.generator = SelfAttentionGenerator(latent_dim, n_classes, img_size, channels)
# 判别器
self.discriminator = SelfAttentionDiscriminator(n_classes, img_size, channels)
def generate(self, z, labels):
return self.generator(z, labels)
def discriminate(self, imgs, labels):
return self.discriminator(imgs, labels)
# 自注意力生成器
class SelfAttentionGenerator(nn.Module):
def __init__(self, latent_dim, n_classes, img_size=32, channels=3):
super(SelfAttentionGenerator, self).__init__()
# 类别嵌入
self.label_emb = nn.Embedding(n_classes, 50)
# 初始处理
self.init = nn.Sequential(
nn.Linear(latent_dim + 50, 256 * 4 * 4),
nn.LeakyReLU(0.2)
)
# 上采样块
self.up1 = nn.Sequential(
nn.ConvTranspose2d(256, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2)
)
# 自注意力块 (在中间分辨率应用)
self.attention = SelfAttention(128)
self.up2 = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, 1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2)
)
self.up3 = nn.Sequential(
nn.ConvTranspose2d(64, channels, 4, 2, 1),
nn.Tanh()
)
def forward(self, z, labels):
# 获取标签嵌入
label_emb = self.label_emb(labels)
# 连接噪声和标签嵌入
x = torch.cat([z, label_emb], dim=1)
# 初始处理
x = self.init(x)
x = x.view(x.size(0), 256, 4, 4)
# 上采样
x = self.up1(x)
# 应用自注意力
x = self.attention(x)
# 继续上采样
x = self.up2(x)
img = self.up3(x)
return img
# 自注意力判别器
class SelfAttentionDiscriminator(nn.Module):
def __init__(self, n_classes, img_size=32, channels=3):
super(SelfAttentionDiscriminator, self).__init__()
# 类别嵌入
self.label_embedding = nn.Embedding(n_classes, 50)
# 初始卷积层
self.conv1 = nn.Sequential(
nn.utils.spectral_norm(nn.Conv2d(channels, 64, 4, 2, 1)),
nn.LeakyReLU(0.2)
)
self.conv2 = nn.Sequential(
nn.utils.spectral_norm(nn.Conv2d(64, 128, 4, 2, 1)),
nn.LeakyReLU(0.2)
)
# 自注意力块
self.attention = SelfAttention(128)
self.conv3 = nn.Sequential(
nn.utils.spectral_norm(nn.Conv2d(128, 256, 4, 2, 1)),
nn.LeakyReLU(0.2)
)
# 输出层
self.flatten = nn.Flatten()
# 计算展平后的特征维度
flattened_dim = 256 * (img_size // 8) * (img_size // 8)
self.output = nn.Sequential(
nn.utils.spectral_norm(nn.Linear(flattened_dim + 50, 1))
# 注意:WGAN中不使用sigmoid激活
)
def forward(self, img, labels):
# 图像特征提取
x = self.conv1(img)
x = self.conv2(x)
# 应用自注意力
x = self.attention(x)
x = self.conv3(x)
x = self.flatten(x)
# 连接标签嵌入
label_emb = self.label_embedding(labels)
x = torch.cat([x, label_emb], dim=1)
# 输出有效性得分
validity = self.output(x)
return validity
# 训练自注意力条件WGAN-GP
def train_sa_cwgan_gp(generator, discriminator, dataloader,
n_epochs, batch_size, latent_dim, n_classes,
device='cuda', lambda_gp=10.0, n_critic=5):
"""
训练自注意力条件WGAN-GP
参数:
generator: 自注意力生成器
discriminator: 自注意力判别器
dataloader: 数据加载器
n_epochs: 训练轮数
batch_size: 批次大小
latent_dim: 潜在空间维度
n_classes: 类别数量
device: 计算设备
lambda_gp: 梯度惩罚权重
n_critic: 每训练一次生成器,训练判别器的次数
"""
# 优化器
g_optimizer = torch.optim.Adam(generator.parameters(), lr=0.0001, betas=(0.0, 0.9))
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=0.0001, betas=(0.0, 0.9))
# 训练循环
for epoch in range(n_epochs):
for i, (real_imgs, labels) in enumerate(dataloader):
real_imgs = real_imgs.to(device)
labels = labels.to(device)
batch_size = real_imgs.size(0)
# ---------------------
# 训练判别器
# ---------------------
d_optimizer.zero_grad()
# 生成假图像
z = torch.randn(batch_size, latent_dim, device=device)
fake_imgs = generator(z, labels)
# 计算真实图像和假图像的判别器输出
real_validity = discriminator(real_imgs, labels)
fake_validity = discriminator(fake_imgs.detach(), labels)
# 计算梯度惩罚
gradient_penalty = compute_gradient_penalty(
discriminator, real_imgs, fake_imgs, labels, device
)
# WGAN-GP判别器损失
d_loss = -torch.mean(real_validity) + torch.mean(fake_validity) + lambda_gp * gradient_penalty
d_loss.backward()
d_optimizer.step()
# 每n_critic次判别器更新更新一次生成器
if i % n_critic == 0:
# ---------------------
# 训练生成器
# ---------------------
g_optimizer.zero_grad()
# 生成新的假图像
z = torch.randn(batch_size, latent_dim, device=device)
fake_imgs = generator(z, labels)
fake_validity = discriminator(fake_imgs, labels)
# WGAN生成器损失
g_loss = -torch.mean(fake_validity)
g_loss.backward()
g_optimizer.step()
# 打印训练信息
if i % 50 == 0:
print(
f"[Epoch {epoch}/{n_epochs}] [Batch {i}/{len(dataloader)}] "
f"[D loss: {d_loss.item():.4f}] [G loss: {g_loss.item():.4f}] [GP: {gradient_penalty.item():.4f}]"
)
# 每个epoch结束后生成样本
if epoch % 10 == 0:
generate_samples(generator, n_classes, latent_dim, device, epoch)
# 计算梯度惩罚
def compute_gradient_penalty(discriminator, real_samples, fake_samples, labels, device):
"""计算WGAN-GP的梯度惩罚"""
# 随机权重
alpha = torch.rand(real_samples.size(0), 1, 1, 1, device=device)
# 在真实和生成样本之间插值
interpolates = (alpha * real_samples + (1 - alpha) * fake_samples).requires_grad_(True)
# 计算判别器在插值点的输出
d_interpolates = discriminator(interpolates, labels)
# 创建常量标签
fake = torch.ones(real_samples.size(0), 1, device=device, requires_grad=False)
# 计算梯度
gradients = torch.autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
# 计算梯度的范数
gradients = gradients.view(gradients.size(0), -1)
gradient_norm = gradients.norm(2, dim=1)
# 计算梯度惩罚
gradient_penalty = ((gradient_norm - 1) ** 2).mean()
return gradient_penalty
# 生成样本
def generate_samples(generator, n_classes, latent_dim, device, epoch):
"""为每个类别生成样本图像"""
generator.eval()
with torch.no_grad():
# 为每个类别生成图像
n_row = min(n_classes, 10) # 每行最多10个类别
z = torch.randn(n_row, latent_dim, device=device)
labels = torch.arange(0, n_row, device=device)
sample_imgs = generator(z, labels)
# 这里应该有保存图像的代码
print(f"Generated samples for epoch {epoch}")
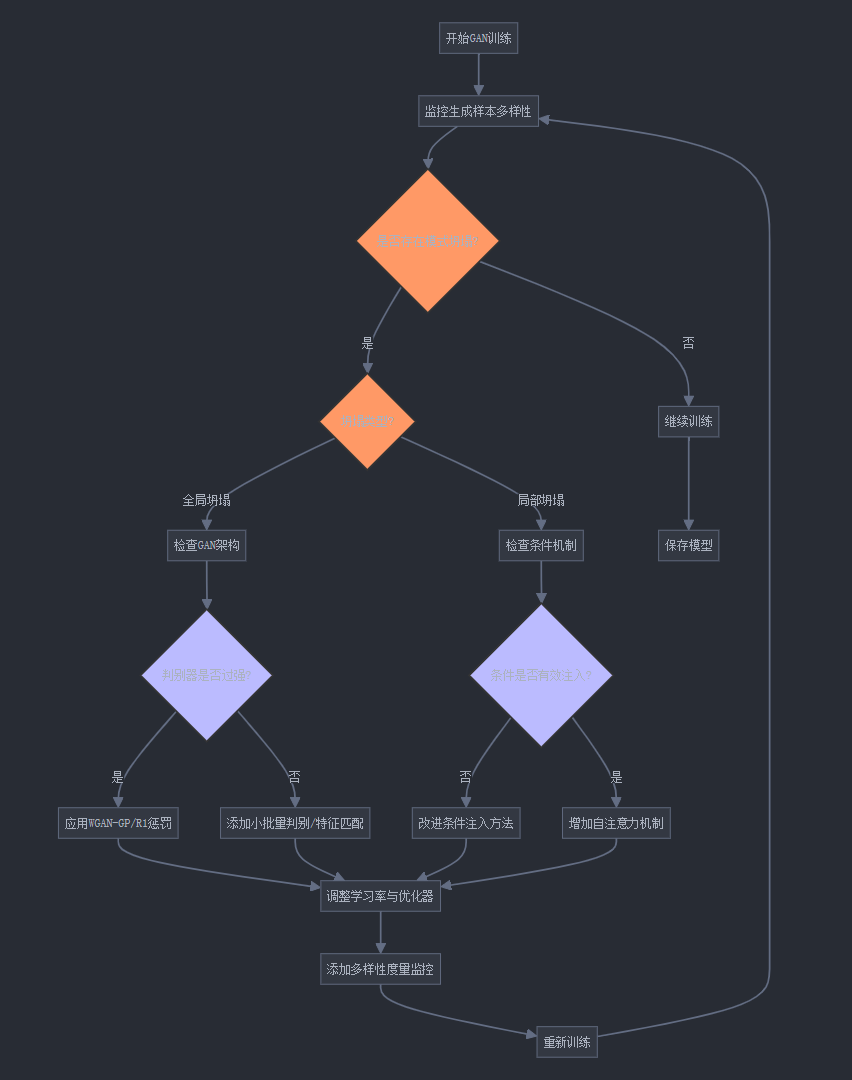
generator.train()8. 面向实践的GAN模式坍塌检测与调试流程
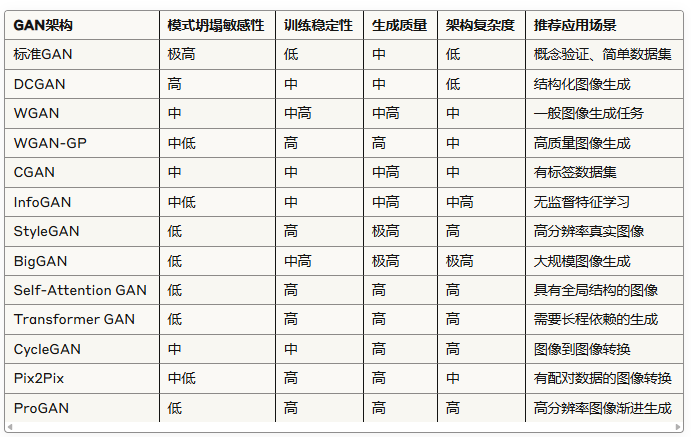
9. 不同GAN架构对模式坍塌的敏感性分析
10. 案例分析:从模式坍塌到多样性生成
python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
from torchvision.utils import save_image, make_grid
import os
# 创建结果目录
os.makedirs("results", exist_ok=True)
# 设置随机种子以便复现
torch.manual_seed(42)
np.random.seed(42)
# 参数设置
batch_size = 64
latent_dim = 100
n_classes = 10 # MNIST有10个类别
img_size = 28
channels = 1
n_epochs = 200
sample_interval = 1000
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 数据加载
transform = transforms.Compose([
transforms.Resize(img_size),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
mnist_dataset = torchvision.datasets.MNIST(
root="./data",
train=True,
download=True,
transform=transform
)
dataloader = DataLoader(
mnist_dataset,
batch_size=batch_size,
shuffle=True
)
# 1. 标准GAN (容易出现模式坍塌)
# 生成器
class StandardGenerator(nn.Module):
def __init__(self):
super(StandardGenerator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, channels * img_size * img_size),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), channels, img_size, img_size)
return img
# 判别器
class StandardDiscriminator(nn.Module):
def __init__(self):
super(StandardDiscriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(channels * img_size * img_size, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# 2. 条件GAN (改善模式坍塌)
# 条件生成器
class ConditionalGenerator(nn.Module):
def __init__(self):
super(ConditionalGenerator, self).__init__()
self.label_emb = nn.Embedding(n_classes, n_classes)
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(latent_dim + n_classes, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, channels * img_size * img_size),
nn.Tanh()
)
def forward(self, z, labels):
label_emb = self.label_emb(labels)
x = torch.cat([z, label_emb], 1)
img = self.model(x)
img = img.view(img.size(0), channels, img_size, img_size)
return img
# 条件判别器
class ConditionalDiscriminator(nn.Module):
def __init__(self):
super(ConditionalDiscriminator, self).__init__()
self.label_emb = nn.Embedding(n_classes, n_classes)
self.model = nn.Sequential(
nn.Linear(channels * img_size * img_size + n_classes, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img, labels):
img_flat = img.view(img.size(0), -1)
label_emb = self.label_emb(labels)
x = torch.cat([img_flat, label_emb], 1)
validity = self.model(x)
return validity
# 3. WGAN-GP (进一步改善)
# WGAN-GP生成器 (与标准GAN基本相同,但移除了最后一层的激活函数)
class WGANGenerator(nn.Module):
def __init__(self):
super(WGANGenerator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, channels * img_size * img_size),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), channels, img_size, img_size)
return img
# WGAN-GP判别器 (移除了最后的sigmoid层)
class WGANDiscriminator(nn.Module):
def __init__(self):
super(WGANDiscriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(channels * img_size * img_size, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1)
# 注意:没有sigmoid
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# 条件WGAN-GP (最终解决方案)
class ConditionalWGANGenerator(nn.Module):
def __init__(self):
super(ConditionalWGANGenerator, self).__init__()
self.label_emb = nn.Embedding(n_classes, n_classes)
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(latent_dim + n_classes, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, channels * img_size * img_size),
nn.Tanh()
)
def forward(self, z, labels):
label_emb = self.label_emb(labels)
x = torch.cat([z, label_emb], 1)
img = self.model(x)
img = img.view(img.size(0), channels, img_size, img_size)
return img
class ConditionalWGANDiscriminator(nn.Module):
def __init__(self):
super(ConditionalWGANDiscriminator, self).__init__()
self.label_emb = nn.Embedding(n_classes, n_classes)
self.model = nn.Sequential(
nn.Linear(channels * img_size * img_size + n_classes, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1)
# 注意:没有sigmoid
)
def forward(self, img, labels):
img_flat = img.view(img.size(0), -1)
label_emb = self.label_emb(labels)
x = torch.cat([img_flat, label_emb], 1)
validity = self.model(x)
return validity
# 梯度惩罚计算
def compute_gradient_penalty(D, real_samples, fake_samples, labels=None, device=device):
"""计算WGAN-GP的梯度惩罚"""
# 随机权重
alpha = torch.rand(real_samples.size(0), 1, 1, 1, device=device)
# 在真实和生成样本之间插值
interpolates = (alpha * real_samples + (1 - alpha) * fake_samples).requires_grad_(True)
# 计算判别器在插值点的输出
if labels is not None:
d_interpolates = D(interpolates, labels)
else:
d_interpolates = D(interpolates)
# 创建常量标签
fake = torch.ones(real_samples.size(0), 1, device=device, requires_grad=False)
# 计算梯度
gradients = torch.autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
# 计算梯度的范数
gradients = gradients.view(gradients.size(0), -1)
gradient_norm = gradients.norm(2, dim=1)
# 计算梯度惩罚
gradient_penalty = ((gradient_norm - 1) ** 2).mean()
return gradient_penalty
# 定义模式坍塌检测函数
def detect_mode_collapse(samples, n_classes=10):
"""
简单的模式坍塌检测:检查生成的数字分布
参数:
samples: 生成的图像样本,形状为[n_samples, channels, height, width]
n_classes: 类别数量
返回:
坍塌程度 (0-1,0表示无坍塌,1表示完全坍塌)
"""
# 使用一个简单的预训练分类器来预测生成样本的类别
classifier = torchvision.models.resnet18(pretrained=True)
classifier.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False) # 修改输入通道为1
classifier.fc = nn.Linear(classifier.fc.in_features, 10) # 修改输出类别为10
# 加载预训练的MNIST分类器权重(这里假设已经有了)
try:
classifier.load_state_dict(torch.load("mnist_classifier.pth"))
except:
print("未找到预训练的分类器权重,将使用随机初始化的分类器")
classifier.to(device)
classifier.eval()
# 预测类别
predictions = []
with torch.no_grad():
for i in range(0, len(samples), batch_size):
batch = samples[i:i+batch_size].to(device)
# 确保图像大小符合分类器输入
batch = nn.functional.interpolate(batch, size=224)
outputs = classifier(batch)
_, preds = torch.max(outputs, 1)
predictions.extend(preds.cpu().numpy())
# 计算类别分布
class_counts = np.bincount(predictions, minlength=n_classes)
class_probs = class_counts / len(predictions)
# 计算分布的熵 (归一化为0-1,1表示均匀分布,0表示完全坍塌)
entropy = -np.sum(class_probs * np.log2(class_probs + 1e-10)) / np.log2(n_classes)
# 坍塌程度 = 1 - 归一化熵
collapse_degree = 1 - entropy
return collapse_degree, class_counts
# 生成样本并检测模式坍塌
def generate_and_check_collapse(generator, latent_dim, n_samples=1000, labels=None, conditional=False, device=device):
"""
生成样本并检测模式坍塌
参数:
generator: 生成器模型
latent_dim: 潜在空间维度
n_samples: 生成样本数量
labels: 如果是条件模型,提供标签
conditional: 是否是条件模型
device: 计算设备
返回:
生成的样本和坍塌程度
"""
generator.eval()
# 生成样本
samples = []
with torch.no_grad():
for i in range(0, n_samples, batch_size):
batch_size_i = min(batch_size, n_samples - i)
z = torch.randn(batch_size_i, latent_dim, device=device)
if conditional:
# 如果提供了标签,使用它们;否则均匀采样
if labels is not None:
batch_labels = labels[i:i+batch_size_i].to(device)
else:
batch_labels = torch.randint(0, n_classes, (batch_size_i,), device=device)
batch_samples = generator(z, batch_labels)
else:
batch_samples = generator(z)
samples.append(batch_samples.cpu())
samples = torch.cat(samples, dim=0)
# 检测模式坍塌
collapse_degree, class_counts = detect_mode_collapse(samples)
generator.train()
return samples, collapse_degree, class_counts
# 显示模式坍塌分析结果
def plot_collapse_analysis(samples, collapse_degree, class_counts, title=""):
"""可视化模式坍塌分析结果"""
plt.figure(figsize=(15, 5))
# 显示样本图像
plt.subplot(1, 2, 1)
grid = make_grid(samples[:16], nrow=4, normalize=True).permute(1, 2, 0)
plt.imshow(grid)
plt.title(f"样本图像 - 坍塌程度: {collapse_degree:.2f}")
plt.axis('off')
# 显示类别分布
plt.subplot(1, 2, 2)
plt.bar(range(len(class_counts)), class_counts)
plt.xlabel('类别')
plt.ylabel('样本数量')
plt.title('生成样本的类别分布')
plt.xticks(range(len(class_counts)))
plt.suptitle(title)
plt.tight_layout()
plt.savefig(f"results/{title.replace(' ', '_')}.png")
plt.show()
# 训练不同的GAN模型
def train_standard_gan():
"""训练标准GAN(容易出现模式坍塌)"""
# 初始化模型
generator = StandardGenerator().to(device)
discriminator = StandardDiscriminator().to(device)
# 损失函数和优化器
adversarial_loss = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
# 记录训练过程中的模式坍塌情况
collapse_history = []
# 训练循环
for epoch in range(n_epochs):
for i, (real_imgs, _) in enumerate(dataloader):
batch_size = real_imgs.size(0)
real_imgs = real_imgs.to(device)
# 真实样本标签
real_target = torch.ones(batch_size, 1).to(device)
# 生成样本标签
fake_target = torch.zeros(batch_size, 1).to(device)
# -----------------
# 训练生成器
# -----------------
optimizer_G.zero_grad()
# 生成随机噪声
z = torch.randn(batch_size, latent_dim).to(device)
# 生成假图像
fake_imgs = generator(z)
# 计算生成器损失
g_loss = adversarial_loss(discriminator(fake_imgs), real_target)
g_loss.backward()
optimizer_G.step()
# -----------------
# 训练判别器
# -----------------
optimizer_D.zero_grad()
# 真实图像的判别器损失
real_loss = adversarial_loss(discriminator(real_imgs), real_target)
# 生成图像的判别器损失
fake_loss = adversarial_loss(discriminator(fake_imgs.detach()), fake_target)
# 总判别器损失
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# 打印训练信息
if i % 100 == 0:
print(
f"[标准GAN] [Epoch {epoch}/{n_epochs}] [Batch {i}/{len(dataloader)}] "
f"[D loss: {d_loss.item():.4f}] [G loss: {g_loss.item():.4f}]"
)
# 每5个epoch检测一次模式坍塌
if epoch % 5 == 0:
samples, collapse_degree, class_counts = generate_and_check_collapse(generator, latent_dim)
collapse_history.append(collapse_degree)
print(f"Epoch {epoch}: 模式坍塌程度 = {collapse_degree:.4f}")
# 最终坍塌分析
samples, collapse_degree, class_counts = generate_and_check_collapse(generator, latent_dim, n_samples=100)
plot_collapse_analysis(samples, collapse_degree, class_counts, title="标准GAN结果")
# 绘制坍塌程度随时间变化
plt.figure(figsize=(10, 5))
plt.plot(range(0, n_epochs, 5), collapse_history)
plt.xlabel('Epoch')
plt.ylabel('模式坍塌程度')
plt.title('标准GAN训练过程中的模式坍塌变化')
plt.savefig("results/standard_gan_collapse_history.png")
plt.show()
return generator, discriminator, collapse_history
def train_conditional_gan():
"""训练条件GAN(改善模式坍塌)"""
# 初始化模型
generator = ConditionalGenerator().to(device)
discriminator = ConditionalDiscriminator().to(device)
# 损失函数和优化器
adversarial_loss = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
# 记录训练过程中的模式坍塌情况
collapse_history = []
# 训练循环
for epoch in range(n_epochs):
for i, (real_imgs, labels) in enumerate(dataloader):
batch_size = real_imgs.size(0)
real_imgs = real_imgs.to(device)
labels = labels.to(device)
# 真实样本标签
real_target = torch.ones(batch_size, 1).to(device)
# 生成样本标签
fake_target = torch.zeros(batch_size, 1).to(device)
# -----------------
# 训练生成器
# -----------------
optimizer_G.zero_grad()
# 生成随机噪声和随机标签
z = torch.randn(batch_size, latent_dim).to(device)
gen_labels = torch.randint(0, n_classes, (batch_size,)).to(device)
# 生成假图像
fake_imgs = generator(z, gen_labels)
# 计算生成器损失
g_loss = adversarial_loss(discriminator(fake_imgs, gen_labels), real_target)
g_loss.backward()
optimizer_G.step()
# -----------------
# 训练判别器
# -----------------
optimizer_D.zero_grad()
# 真实图像的判别器损失
real_loss = adversarial_loss(discriminator(real_imgs, labels), real_target)
# 生成图像的判别器损失
fake_loss = adversarial_loss(discriminator(fake_imgs.detach(), gen_labels), fake_target)
# 总判别器损失
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# 打印训练信息
if i % 100 == 0:
print(
f"[条件GAN] [Epoch {epoch}/{n_epochs}] [Batch {i}/{len(dataloader)}] "
f"[D loss: {d_loss.item():.4f}] [G loss: {g_loss.item():.4f}]"
)
# 每5个epoch检测一次模式坍塌
if epoch % 5 == 0:
samples, collapse_degree, class_counts = generate_and_check_collapse(
generator, latent_dim, conditional=True
)
collapse_history.append(collapse_degree)
print(f"Epoch {epoch}: 模式坍塌程度 = {collapse_degree:.4f}")
# 最终坍塌分析
samples, collapse_degree, class_counts = generate_and_check_collapse(
generator, latent_dim, n_samples=100, conditional=True
)
plot_collapse_analysis(samples, collapse_degree, class_counts, title="条件GAN结果")
# 生成每个类别的样本
fig, axes = plt.subplots(2, 5, figsize=(15, 6))
axes = axes.flatten()
for label in range(n_classes):
z = torch.randn(1, latent_dim, device=device)
label_tensor = torch.tensor([label], device=device)
generated_img = generator(z, label_tensor)
img = generated_img[0].cpu().detach().permute(1, 2, 0).numpy()
img = (img + 1) / 2 # 从[-1,1]转换为[0,1]
axes[label].imshow(img.squeeze(), cmap='gray')
axes[label].set_title(f"类别 {label}")
axes[label].axis('off')
plt.tight_layout()
plt.savefig("results/conditional_gan_all_classes.png")
plt.show()
# 绘制坍塌程度随时间变化
plt.figure(figsize=(10, 5))
plt.plot(range(0, n_epochs, 5), collapse_history)
plt.xlabel('Epoch')
plt.ylabel('模式坍塌程度')
plt.title('条件GAN训练过程中的模式坍塌变化')
plt.savefig("results/conditional_gan_collapse_history.png")
plt.show()
return generator, discriminator, collapse_history
def train_conditional_wgan_gp():
"""训练条件WGAN-GP (最终解决方案)"""
# 初始化模型
generator = ConditionalWGANGenerator().to(device)
discriminator = ConditionalWGANDiscriminator().to(device)
# 优化器
optimizer_G = optim.Adam(generator.parameters(), lr=0.0001, betas=(0.0, 0.9))
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0001, betas=(0.0, 0.9))
# 记录训练过程中的模式坍塌情况
collapse_history = []
# WGAN-GP参数
lambda_gp = 10 # 梯度惩罚的权重
n_critic = 5 # 每训练一次生成器,训练判别器的次数
# 训练循环
for epoch in range(n_epochs):
for i, (real_imgs, labels) in enumerate(dataloader):
real_imgs = real_imgs.to(device)
labels = labels.to(device)
batch_size = real_imgs.size(0)
# -----------------
# 训练判别器
# -----------------
optimizer_D.zero_grad()
# 采样噪声和标签
z = torch.randn(batch_size, latent_dim).to(device)
gen_labels = torch.randint(0, n_classes, (batch_size,)).to(device)
# 生成假图像
fake_imgs = generator(z, gen_labels)
# 计算真实图像和假图像的判别器输出
real_validity = discriminator(real_imgs, labels)
fake_validity = discriminator(fake_imgs.detach(), gen_labels)
# 计算梯度惩罚
gradient_penalty = compute_gradient_penalty(
discriminator, real_imgs.data, fake_imgs.data, labels, device
)
# WGAN-GP判别器损失
d_loss = -torch.mean(real_validity) + torch.mean(fake_validity) + lambda_gp * gradient_penalty
d_loss.backward()
optimizer_D.step()
# 每n_critic次判别器更新后更新一次生成器
if i % n_critic == 0:
# -----------------
# 训练生成器
# -----------------
optimizer_G.zero_grad()
# 采样新的噪声和标签
z = torch.randn(batch_size, latent_dim).to(device)
gen_labels = torch.randint(0, n_classes, (batch_size,)).to(device)
# 生成新的假图像
fake_imgs = generator(z, gen_labels)
fake_validity = discriminator(fake_imgs, gen_labels)
# WGAN生成器损失
g_loss = -torch.mean(fake_validity)
g_loss.backward()
optimizer_G.step()
# 打印训练信息
if i % 100 == 0:
print(
f"[条件WGAN-GP] [Epoch {epoch}/{n_epochs}] [Batch {i}/{len(dataloader)}] "
f"[D loss: {d_loss.item():.4f}] [G loss: {g_loss.item():.4f}]"
)
# 每5个epoch检测一次模式坍塌
if epoch % 5 == 0:
samples, collapse_degree, class_counts = generate_and_check_collapse(
generator, latent_dim, conditional=True
)
collapse_history.append(collapse_degree)
print(f"Epoch {epoch}: 模式坍塌程度 = {collapse_degree:.4f}")
# 最终坍塌分析
samples, collapse_degree, class_counts = generate_and_check_collapse(
generator, latent_dim, n_samples=100, conditional=True
)
plot_collapse_analysis(samples, collapse_degree, class_counts, title="条件WGAN-GP结果")
# 生成每个类别的样本
fig, axes = plt.subplots(2, 5, figsize=(15, 6))
axes = axes.flatten()
for label in range(n_classes):
z = torch.randn(1, latent_dim, device=device)
label_tensor = torch.tensor([label], device=device)
generated_img = generator(z, label_tensor)
img = generated_img[0].cpu().detach().permute(1, 2, 0).numpy()
img = (img + 1) / 2 # 从[-1,1]转换为[0,1]
axes[label].imshow(img.squeeze(), cmap='gray')
axes[label].set_title(f"类别 {label}")
axes[label].axis('off')
plt.tight_layout()
plt.savefig("results/conditional_wgan_gp_all_classes.png")
plt.show()
# 生成不同类别的多样性样本
fig, axes = plt.subplots(5, 10, figsize=(20, 10))
for row, label in enumerate([0, 1, 4, 7, 9]): # 选择几个数字类别
for col in range(10):
z = torch.randn(1, latent_dim, device=device)
label_tensor = torch.tensor([label], device=device)
generated_img = generator(z, label_tensor)
img = generated_img[0].cpu().detach().permute(1, 2, 0).numpy()
img = (img + 1) / 2 # 从[-1,1]转换为[0,1]
axes[row, col].imshow(img.squeeze(), cmap='gray')
if col == 0:
axes[row, col].set_ylabel(f"类别 {label}", fontsize=12)
axes[row, col].axis('off')
plt.tight_layout()
plt.savefig("results/conditional_wgan_gp_diversity.png")
plt.show()
# 绘制坍塌程度随时间变化
plt.figure(figsize=(10, 5))
plt.plot(range(0, n_epochs, 5), collapse_history)
plt.xlabel('Epoch')
plt.ylabel('模式坍塌程度')
plt.title('条件WGAN-GP训练过程中的模式坍塌变化')
plt.savefig("results/conditional_wgan_gp_collapse_history.png")
plt.show()
return generator, discriminator, collapse_history
# 比较不同模型的模式坍塌情况
def compare_models():
"""比较不同GAN模型的模式坍塌情况"""
# 训练各种模型
print("训练标准GAN...")
_, _, standard_collapse = train_standard_gan()
print("\n训练条件GAN...")
_, _, conditional_collapse = train_conditional_gan()
print("\n训练WGAN-GP...")
_, _, wgan_gp_collapse = train_wgan_gp()
print("\n训练条件WGAN-GP...")
_, _, cwgan_gp_collapse = train_conditional_wgan_gp()
# 绘制比较图
plt.figure(figsize=(12, 6))
epochs = range(0, n_epochs, 5)
plt.plot(epochs, standard_collapse, 'r-', label='标准GAN')
plt.plot(epochs, conditional_collapse, 'g-', label='条件GAN')
plt.plot(epochs, wgan_gp_collapse, 'b-', label='WGAN-GP')
plt.plot(epochs, cwgan_gp_collapse, 'y-', label='条件WGAN-GP')
plt.xlabel('Epoch')
plt.ylabel('模式坍塌程度')
plt.title('不同GAN模型的模式坍塌对比')
plt.legend()
plt.grid(True)
plt.savefig("results/model_comparison.png")
plt.show()
# 创建最终对比表格
final_collapse = {
'标准GAN': standard_collapse[-1],
'条件GAN': conditional_collapse[-1],
'WGAN-GP': wgan_gp_collapse[-1],
'条件WGAN-GP': cwgan_gp_collapse[-1]
}
print("\n最终模式坍塌程度对比:")
for model, score in final_collapse.items():
print(f"{model}: {score:.4f}")
# 绘制条形图
plt.figure(figsize=(10, 6))
models = list(final_collapse.keys())
scores = list(final_collapse.values())
plt.bar(models, scores, color=['red', 'green', 'blue', 'yellow'])
plt.ylabel('模式坍塌程度')
plt.title('不同GAN模型的最终模式坍塌程度')
plt.ylim(0, 1)
for i, score in enumerate(scores):
plt.text(i, score + 0.02, f"{score:.4f}", ha='center')
plt.savefig("results/final_comparison.png")
plt.show()
# 主函数
if __name__ == "__main__":
compare_models()别器的次数
# 训练循环
for epoch in range(n_epochs):
for i, (real_imgs, _) in enumerate(dataloader):
real_imgs = real_imgs.to(device)
batch_size = real_imgs.size(0)
# -----------------
# 训练判别器
# -----------------
optimizer_D.zero_grad()
# 生成随机噪声
z = torch.randn(batch_size, latent_dim).to(device)
# 生成假图像
fake_imgs = generator(z)
# 计算真实图像和假图像的判别器输出
real_validity = discriminator(real_imgs)
fake_validity = discriminator(fake_imgs.detach())
# 计算梯度惩罚
gradient_penalty = compute_gradient_penalty(
discriminator, real_imgs.data, fake_imgs.data
)
# WGAN-GP判别器损失
d_loss = -torch.mean(real_validity) + torch.mean(fake_validity) + lambda_gp * gradient_penalty
d_loss.backward()
optimizer_D.step()
# 每n_critic次判别器更新后更新一次生成器
if i % n_critic == 0:
# -----------------
# 训练生成器
# -----------------
optimizer_G.zero_grad()
# 生成新的假图像
z = torch.randn(batch_size, latent_dim).to(device)
fake_imgs = generator(z)
fake_validity = discriminator(fake_imgs)
# WGAN生成器损失
g_loss = -torch.mean(fake_validity)
g_loss.backward()
optimizer_G.step()
# 打印训练信息
if i % 100 == 0:
print(
f"[WGAN-GP] [Epoch {epoch}/{n_epochs}] [Batch {i}/{len(dataloader)}] "
f"[D loss: {d_loss.item():.4f}] [G loss: {g_loss.item():.4f}]"
)
# 每5个epoch检测一次模式坍塌
if epoch % 5 == 0:
samples, collapse_degree, class_counts = generate_and_check_collapse(generator, latent_dim)
collapse_history.append(collapse_degree)
print(f"Epoch {epoch}: 模式坍塌程度 = {collapse_degree:.4f}")
# 最终坍塌分析
samples, collapse_degree, class_counts = generate_and_check_collapse(generator, latent_dim, n_samples=100)
plot_collapse_analysis(samples, collapse_degree, class_counts, title="WGAN-GP结果")
# 绘制坍塌程度随时间变化
plt.figure(figsize=(10, 5))
plt.plot(range(0, n_epochs, 5), collapse_history)
plt.xlabel('Epoch')
plt.ylabel('模式坍塌程度')
plt.title('WGAN-GP训练过程中的模式坍塌变化')
plt.savefig("results/wgan_gp_collapse_history.png")
plt.show()
return generator, discriminator, collapse_history总结:从模式坍塌到多样性生成的过程
在本文的第二部分中,我们深入探讨了GAN训练中的模式坍塌问题,并提供了一系列解决方案。关键要点包括:
1. 高级解决模式坍塌的技术:
我们探讨了多样性敏感的损失函数、基于梯度的正则化方法、改进的GAN架构等多种方法,并提供了具体实现代码。这些技术从不同角度帮助缓解模式坍塌问题。
2. 条件信息的高级注入方法:
我们详细讨论了多种条件信息注入方法,包括条件批归一化、FiLM、自适应实例归一化等,这些方法能够更有效地利用标签信息,提高生成图像的多样性和质量。
3. 多样性评估方法:
我们介绍了多种评估GAN生成多样性的方法,如Inception Score、FID、特征聚类分析等,这些方法提供了客观的指标来检测和量化模式坍塌问题。
4. 基于Transformer的GAN架构:
通过结合Transformer和GAN的优势,可以进一步提高生成模型的多样性和长程依赖性,减轻模式坍塌问题。
5. 自回归生成与多样性控制:
通过将生成过程分解为多个步骤,并使用不同级别的噪声变化,可以在全局一致性和局部多样性之间取得平衡。
6. 实际应用中的模式坍塌解决方案:
我们提供了一份根据不同应用场景选择合适解决方案的决策指南,以及一个完整的调试流程图。
7. 案例研究:
通过对比标准GAN、条件GAN、WGAN-GP和条件WGAN-GP,我们看到了如何逐步解决模式坍塌问题,并通过客观指标评估不同方法的效果。
清华大学全五版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!