一、图的定义与基本术语
图(Graph)是一种非线性数据结构,由顶点(Vertex)和边(Edge)组成。它包含以下基本术语:
-
顶点(Vertex) :是图中的数据元素。
-
边(Edge) :连接两个顶点的线,可以是有向的(表示两个顶点之间的关系有方向)或无向的(表示两个顶点之间的关系无方向)。
-
无向图(Undirected Graph) :图中的边没有方向。
-
有向图(Directed Graph) :图中的边有方向。
-
完全图(Complete Graph) :每一对不同的顶点都有一条边相连。
-
子图(Subgraph) :相对于某一图来说,由部分顶点和边组成的图。
-
连通图(Connected Graph) :在无向图中,任意两个顶点都是连通的。
-
强连通图(Strongly Connected Graph) :在有向图中,任意两个顶点之间都存在互相可达的路径。
-
连通分量(Connected Component) :无向图中的极大连通子图。
-
强连通分量(Strongly Connected Component) :有向图中的极大强连通子图。
-
生成树(Spanning Tree) :一个连通图的生成树是一个极小连通子图,它包含图中所有顶点和能构成树的边。
-
网(Network) :带权的图。
二、图的存储结构
邻接矩阵
邻接矩阵是用两个数组来表示图。一个一维数组存储顶点信息,一个二维数组存储边的信息。
无向图的邻接矩阵是对称矩阵,有向图的邻接矩阵不一定对称,带权图的邻接矩阵中对应项存放边的权值。
邻接表
邻接表是一种链式存储结构,为每个顶点建立一个单链表,每个链表的表头保存该顶点的信息,链表中的结点保存与该顶点相邻的顶点的信息。
优点是便于增删顶点和边,节省空间;缺点是不便于判断任意两个顶点之间是否有边。
十字链表
十字链表是有向图的另一种链式存储结构,把有向图中所有边弧结点按入度和出度组织成多个循环链表。
每个边弧结点包含边的相关信息,如起点、终点、权值等。它便于对有向图进行操作,如求每个顶点的入度和出度等。
邻接多重表
邻接多重表是无向图的另一种链式存储结构,将邻接点链接起来,同时记录边的相关信息,如边的两端点、权值等。它便于对无向图进行操作,如删除一条边等。
三、图的遍历
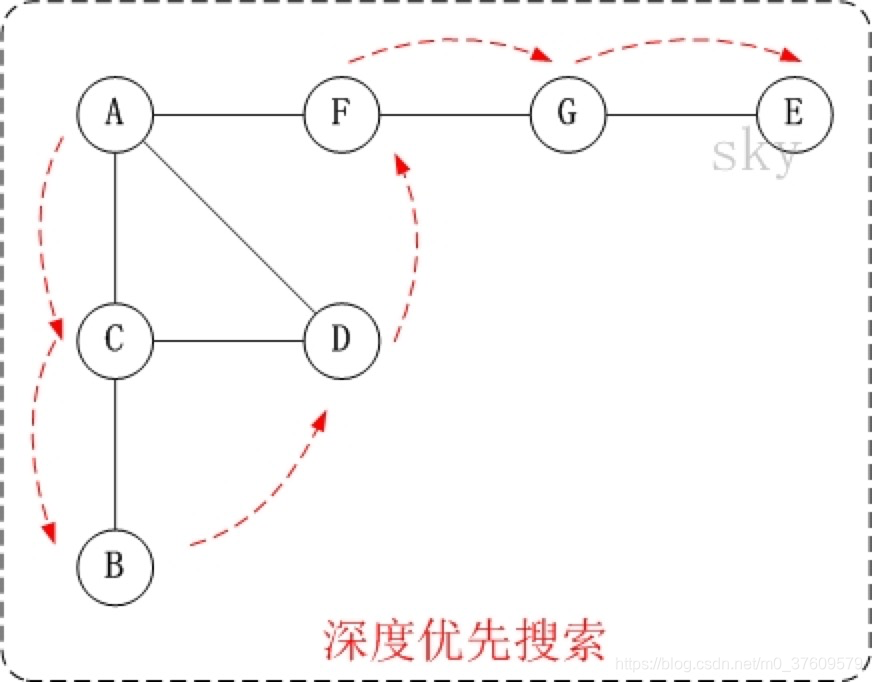
深度优先搜索
深度优先搜索(DFS)类似于树的先序遍历,从某个顶点出发,访问该顶点,然后递归地对各个邻接点进行深度优先搜索。
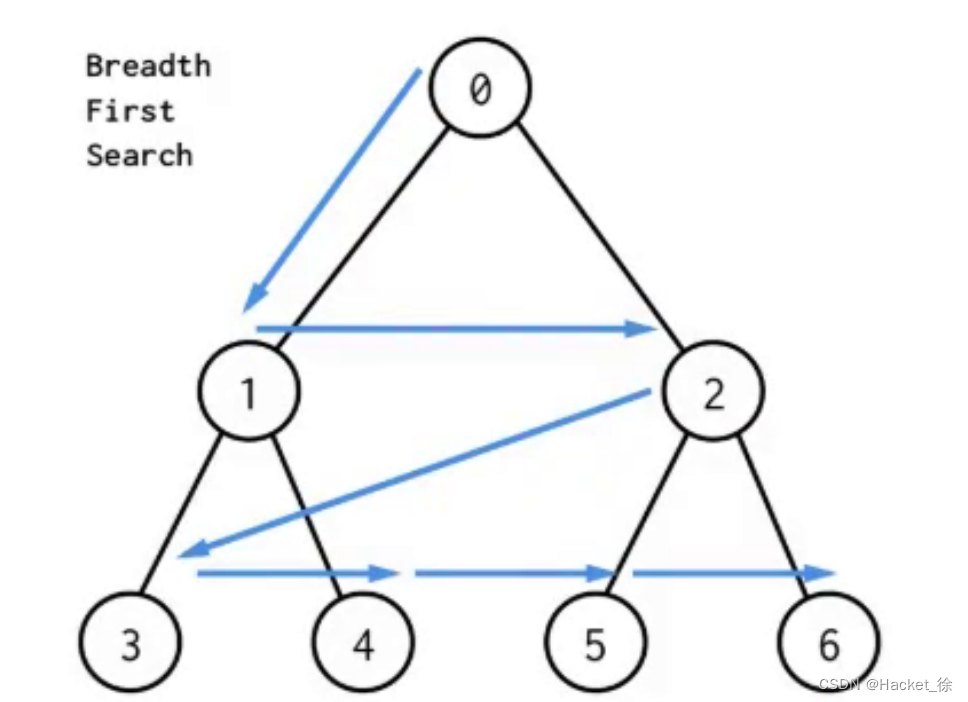
广度优先搜索
广度优先搜索(BFS)类似于树的按层遍历,从某个顶点出发,先访问该顶点,然后依次访问其各个未被访问过的邻接点,再依次访问这些邻接点的邻接点,直到所有顶点都被访问过为止
 。
。
四、图的应用
图的连通性问题
-
生成树 :通过遍历连通图可以得到生成树,生成树可以用于网络的设计和优化。
-
连通分量 :对于非连通图,可以求出其连通分量,以了解图的结构。
有向无环图的应用
-
拓扑排序 :将有向无环图中的顶点按一定顺序排列,使得对于每一条有向边 (u, v),u 都在 v 的前面。拓扑排序可以用于任务调度、课程安排等问题。
-
关键路径 :在带权的有向无环图中,找出从源点到汇点的最长路径,即关键路径。关键路径可以用于项目管理,确定项目的关键任务和完成时间。
最短路径问题
-
单源最短路径 :从一个源点到其他各个顶点的最短路径,常用的算法有 Dijkstra 算法(适用于非负权值的图)和 Bellman-Ford 算法(适用于可能存在负权值的图)。
-
每对顶点之间的最短路径 :常用的算法有 Floyd 算法,它通过动态规划的方法,逐步求出每对顶点之间的最短路径。
五、总结与提高
时间性能分析
| 遍历算法 | 时间复杂度 |
|---|---|
| 深度优先搜索 | O(n + e)(n 为顶点数,e 为边数) |
| 广度优先搜索 | O(n + e) |
空间性能分析
| 存储结构 | 空间复杂度 |
|---|---|
| 邻接矩阵 | O(n²) |
| 邻接表 | O(n + e) |
应用场景
| 应用场景 | 适用的图结构 |
|---|---|
| 社交网络分析 | 无向图 |
| 网页链接关系 | 有向图 |
| 交通网络 | 带权图 |
六、代码实现
C 语言实现
#include <stdio.h>
#include <stdlib.h>
#define MAX_VERTEX_NUM 20 // 最大顶点数
#define INFINITY 65535
typedef int VertexType; // 顶点的数据类型
typedef int EdgeType; // 带权图中边上权值的数据类型
// 邻接矩阵存储结构
typedef struct {
VertexType vexs[MAX_VERTEX_NUM]; // 顶点表
EdgeType arc[MAX_VERTEX_NUM][MAX_VERTEX_NUM]; // 邻接矩阵,边表
int vexnum, arcnum; // 图的当前顶点数和弧数
} MGraph;
// 创建无向图的邻接矩阵
void CreateUDN(MGraph *G) {
int i, j, k;
printf("请输入顶点数和边数:");
scanf("%d %d", &G->vexnum, &G->arcnum);
// 输入顶点信息
printf("请输入顶点信息:\n");
for (i = 0; i < G->vexnum; i++) {
scanf("%d", &G->vexs[i]);
}
// 初始化邻接矩阵
for (i = 0; i < G->vexnum; i++) {
for (j = 0; j < G->vexnum; j++) {
G->arc[i][j] = INFINITY;
}
}
// 输入边的信息
printf("请输入边的信息(顶点1 顶点2 权值):\n");
for (k = 0; k < G->arcnum; k++) {
int v1, v2, w;
scanf("%d %d %d", &v1, &v2, &w);
i = v1 - 1; // 转换为顶点在数组中的索引
j = v2 - 1;
G->arc[i][j] = w; // 无向图,所以两个方向都要赋值
G->arc[j][i] = w;
}
}
// 深度优先搜索
void DFS(MGraph G, int visited[], int v) {
printf("%d ", G.vexs[v]); // 访问当前顶点
visited[v] = 1; // 标记为已访问
for (int w = 0; w < G.vexnum; w++) {
if (G.arc[v][w] != INFINITY && !visited[w]) { // 如果存在边且未访问过
DFS(G, visited, w); // 递归访问邻接点
}
}
}
// 广度优先搜索
void BFS(MGraph G, int visited[], int v) {
int queue[MAX_VERTEX_NUM]; // 队列
int front = 0, rear = 0;
printf("%d ", G.vexs[v]); // 访问当前顶点
visited[v] = 1; // 标记为已访问
queue[rear++] = v; // 入队
while (front != rear) {
int u = queue[front++]; // 出队
for (int w = 0; w < G.vexnum; w++) {
if (G.arc[u][w] != INFINITY && !visited[w]) { // 如果存在边且未访问过
printf("%d ", G.vexs[w]); // 访问邻接点
visited[w] = 1;
queue[rear++] = w; // 入队
}
}
}
}
int main() {
MGraph G;
CreateUDN(&G); // 创建图
int visited[MAX_VERTEX_NUM] = {0}; // 初始化访问标记数组
printf("深度优先遍历:");
for (int i = 0; i < G.vexnum; i++) {
if (!visited[i]) { // 如果顶点未被访问过
DFS(G, visited, i);
}
}
printf("\n");
for (int i = 0; i < G.vexnum; i++) {
visited[i] = 0; // 重置访问标记数组
}
printf("广度优先遍历:");
for (int i = 0; i < G.vexnum; i++) {
if (!visited[i]) { // 如果顶点未被访问过
BFS(G, visited, i);
}
}
printf("\n");
return 0;
}C++ 实现
cpp
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
// 邻接表存储结构
class Graph {
public:
int numVertices;
vector<vector<int>> adjLists;
Graph(int vertices) {
numVertices = vertices;
adjLists.resize(vertices);
}
void addEdge(int src, int dest) {
adjLists[src].push_back(dest); // 无向图,所以两个方向都要添加
adjLists[dest].push_back(src);
}
// 深度优先搜索
void DFS(int startVertex) {
vector<bool> visited(numVertices, false);
dfsUtil(startVertex, visited);
}
void dfsUtil(int v, vector<bool>& visited) {
visited[v] = true;
cout << v << " ";
for (int adj : adjLists[v]) {
if (!visited[adj]) {
dfsUtil(adj, visited);
}
}
}
// 广度优先搜索
void BFS(int startVertex) {
vector<bool> visited(numVertices, false);
queue<int> q;
q.push(startVertex);
visited[startVertex] = true;
cout << startVertex << " ";
while (!q.empty()) {
int u = q.front();
q.pop();
for (int adj : adjLists[u]) {
if (!visited[adj]) {
visited[adj] = true;
cout << adj << " ";
q.push(adj);
}
}
}
}
};
int main() {
Graph g(5);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(1, 3);
g.addEdge(2, 4);
cout << "深度优先遍历:";
g.DFS(0);
cout << "\n广度优先遍历:";
g.BFS(0);
return 0;
}
Java 实现
cpp
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.Queue;
public class Graph {
private int numVertices;
private ArrayList<ArrayList<Integer>> adjLists;
public Graph(int vertices) {
numVertices = vertices;
adjLists = new ArrayList<>(vertices);
for (int i = 0; i < vertices; i++) {
adjLists.add(new ArrayList<>());
}
}
public void addEdge(int src, int dest) {
adjLists.get(src).add(dest); // 无向图,所以两个方向都要添加
adjLists.get(dest).add(src);
}
// 深度优先搜索
public void DFS(int startVertex) {
boolean[] visited = new boolean[numVertices];
dfsUtil(startVertex, visited);
}
private void dfsUtil(int v, boolean[] visited) {
visited[v] = true;
System.out.print(v + " ");
for (int adj : adjLists.get(v)) {
if (!visited[adj]) {
dfsUtil(adj, visited);
}
}
}
// 广度优先搜索
public void BFS(int startVertex) {
boolean[] visited = new boolean[numVertices];
Queue<Integer> q = new LinkedList<>();
q.add(startVertex);
visited[startVertex] = true;
System.out.print(startVertex + " ");
while (!q.isEmpty()) {
int u = q.poll();
for (int adj : adjLists.get(u)) {
if (!visited[adj]) {
visited[adj] = true;
System.out.print(adj + " ");
q.add(adj);
}
}
}
}
public static void main(String[] args) {
Graph g = new Graph(5);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(1, 3);
g.addEdge(2, 4);
System.out.print("深度优先遍历:");
g.DFS(0);
System.out.print("\n广度优先遍历:");
g.BFS(0);
}
}
Python 实现
python
class Graph:
def __init__(self, vertices):
self.numVertices = vertices
self.adjLists = [[] for _ in range(vertices)]
def addEdge(self, src, dest):
self.adjLists[src].append(dest) # 无向图,所以两个方向都要添加
self.adjLists[dest].append(src)
# 深度优先搜索
def DFS(self, startVertex):
visited = [False] * self.numVertices
self.dfsUtil(startVertex, visited)
def dfsUtil(self, v, visited):
visited[v] = True
print(v, end=" ")
for adj in self.adjLists[v]:
if not visited[adj]:
self.dfsUtil(adj, visited)
# 广度优先搜索
def BFS(self, startVertex):
visited = [False] * self.numVertices
q = []
q.append(startVertex)
visited[startVertex] = True
print(startVertex, end=" ")
while q:
u = q.pop(0)
for adj in self.adjLists[u]:
if not visited[adj]:
visited[adj] = True
print(adj, end=" ")
q.append(adj)
if __name__ == "__main__":
g = Graph(5)
g.addEdge(0, 1)
g.addEdge(0, 2)
g.addEdge(1, 3)
g.addEdge(2, 4)
print("深度优先遍历:", end="")
g.DFS(0)
print("\n广度优先遍历:", end="")
g.BFS(0)