一、目标
如何使用 PyTorch 实现一个简单的深度神经网络(DNN)模型,并用于回归任务。该模型通过训练数据集来预测PM2.5。代码通过读取数据集、数据处理、模型训练和模型评估等步骤,详细展示了整个实现过程。
二、数据集介绍
Data 含有 18 项观测数据 AMB_TEMP(环境温度), CH4(甲烷), CO(一氧化碳), NMHC(非甲烷总烃), NO(一氧化氮), NO2(二氧化氮), NOx(氮氧化物), O3(臭氧), PM10, PM2.5, RAINFALL(降雨量), RH(相对湿度), SO2(二氧化硫), THC(总碳氢化合物), WD_HR(小时平均风向), WIND_DIREC(风向), WIND_SPEED(风速), WS_HR(小时平均风速)。纵向为日期从2014/1/1到2014/12/20,其中每月记录20天,横向为每日24小时每一小时的记录。

三、设计思路
3.1、准备工作
导入模块包
python
import pandas as pd
import numpy as np
import random
import os
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from torch.utils.data import TensorDataset, DataLoader设置随机种子保证结果的可重复性
python
def setup_seed(seed):
# 设置 Numpy 随机数种子,确保Numpy生成的随机数序列一致
np.random.seed(seed)
# 设置Python内置随机数种子,保证Python内置的随机函数生成的随机数一致
random.seed(seed)
# 设置Python哈希种子,避免不同运行环境下哈希结果不同,影响随机数生成
os.environ['PYTHONHASHSEED'] = str(seed)
# 设置PyTorch 随机种子,使PyTorch生成的随机数序列可以重复
torch.manual_seed(seed)
# 检查是否有可用的CUDA设备(GPU)
if torch.cuda.is_available():
# 设置 CUDA 随机种子,保证在GPU上的随即操作可重复
torch.cuda.manual_seed(seed)
# 为所有 GPU 设置随机种子
torch.cuda.manual_seed_all(seed)
# 关闭 cudnn 自动寻找最优算法加速的功能,保证结果可重复
torch.backends.cudnn.benchmark = False
# 设置 cudnn 为确定性算法,确保每次运行结果一致
torch.backends.cudnn.deterministic = True检测是否使用cuda
python
if torch.cuda.is_available():
device = 'cuda'
print('CUDA is useful!!')
else:
device = 'cpu'
print('CUDA is not useful!!')设置 pandas 显示选项
python
# 最多显示1000列
pd.set_option('display.max_columns', 1000)
# 显示宽度为1000
pd.set_option('display.width', 1000)
# 每列最多显示1000个字符
pd.set_option('display.max_colwidth', 1000)3.2、数据操作
读取数据
python
train_data = pd.read_csv('train.csv', encoding='big5')选取特征数据
python
train_data = train_data.iloc[:, 3:]将数组中值为NR的元素替换为0
python
train_data[train_data == 'NR'] = 0查看缺失情况
python
print(train_data.isnull().sum())对数据进行维度变换和重塑,转为DataFrame格式
python
datas = []
# 按照 步长为18 分割数据
for i in range(0, 4320, 18):
datas.append(numpy_data[i:i+18, :])
# 将datas 转换为Numpy数组
datas_array = np.array(datas, dtype=float)
# 对数据进行维度变换和重塑,转为DataFrame格式
train_data = pd.DataFrame(datas_array.transpose(1, 0, 2).reshape(18, -1).T)查看相关性
python
corr=train_data.corr()
sns.heatmap(corr,annot=True)
plt.show()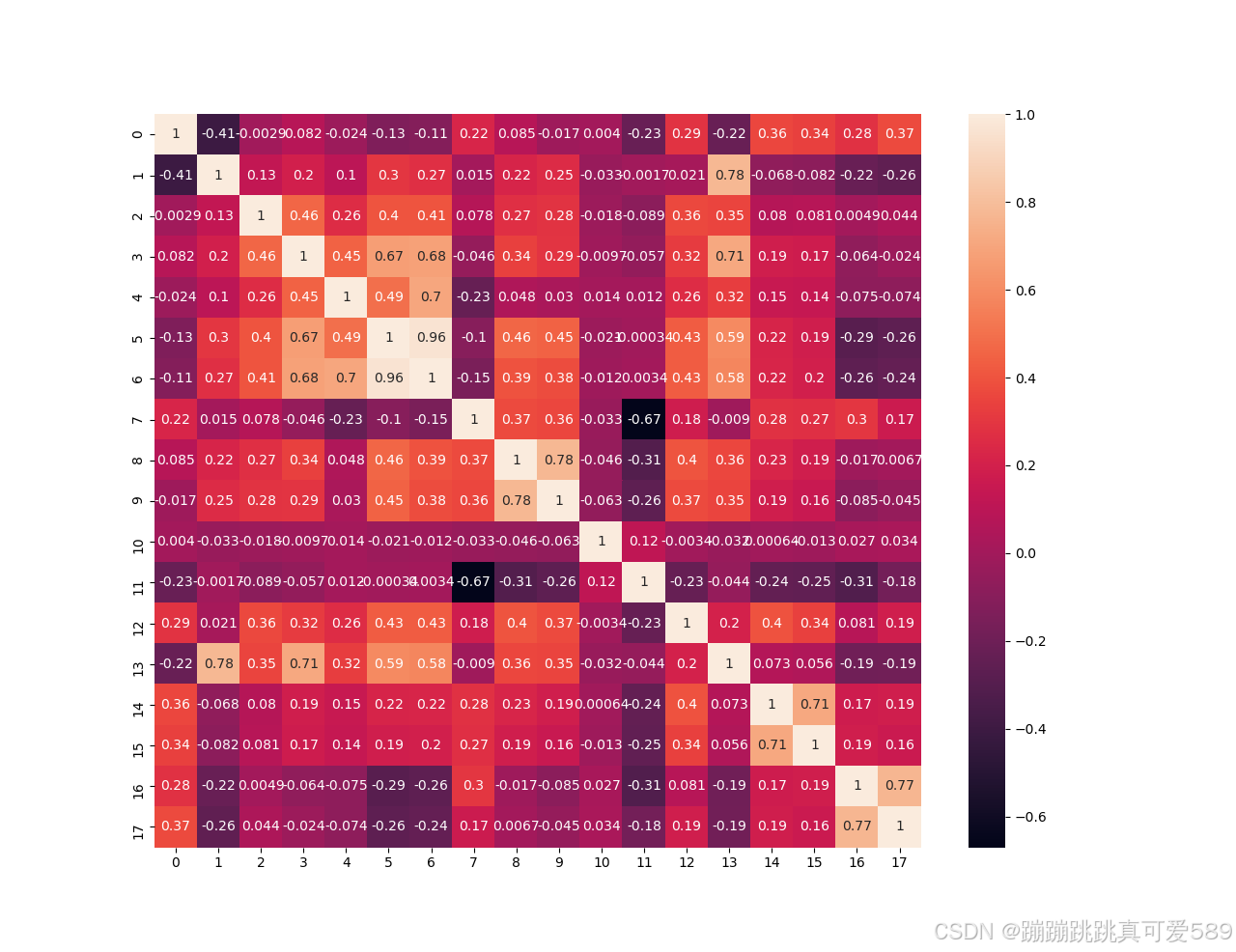
从相关性矩阵里筛选大于0.2的特征
python
important_features = []
for i in range(len(corr.columns)):
if abs(corr.iloc[i, 9]) > 0.2:
important_features.append(corr.columns[i])划分特征和目标
python
X = train_data[important_features].drop(9, axis=1)
# 选取第9列作为目标
y = train_data[9]划分训练集和测试集
python
# 划分训练集和测试集
train_ratio = 0.8
# 训练集特征
X_train = X[:int(train_ratio * len(train_data))]
# 测试集特征
X_test = X[int(train_ratio * len(train_data)):]
# 训练集标签
y_train = y[:int(train_ratio * len(train_data))]
# 测试集标签
y_test = y[int(train_ratio * len(train_data)):]3.3、标准化
python
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)3.4、将数据转换为PyTorch的张量
python
# 训练集的特征张量表示
X_train_tensor = torch.tensor(X_train_scaled, dtype=torch.float32)
# 训练集的标签张量表示
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).view(-1, 1)
# 测试集的特征张量表示
X_test_tensor = torch.tensor(X_test_scaled, dtype=torch.float32)
# 测试集的标签张量表示
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32).view(-1, 1)3.5、使用DataLoader去加载数据集
python
# 创建TensorDataset对象,将训练集特征张量与标签一一组合在一起
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
# 创建DataLoader对象,用于批量加载数据
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)3.6、定义模型
python
class DNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
# 调用父类的构造函数
super(DNN, self).__init__()
# 定义第一个Linear层,输入就是input_size,输出维度就是 hidden_size
self.fc1 = nn.Linear(input_size, hidden_size)
# 定义第二个Linear层,输入是hidden_size,输出维度是 hidden_size
self.fc2 = nn.Linear(hidden_size, hidden_size)
# 定义第三个Linear层,输入是hidden_size,输出维度是 hidden_size
self.fc3 = nn.Linear(hidden_size, hidden_size)
# 定义第四个Linear层,输入是hidden_size,输出维度是 output_size
self.fc4 = nn.Linear(hidden_size, output_size)
# 定义激活函数
self.relu = nn.ReLU()
def forward(self, x):
# 输入数据经过第一个Linear和ReLU激活
x = self.relu(self.fc1(x))
# 输入数据经过第二个Linear和ReLU激活
x = self.relu(self.fc2(x))
# 输入数据经过第三个Linear和ReLU激活
x = self.relu(self.fc3(x))
# 输入数据经过第四个Linear进行输出
x = self.fc4(x)
return x
model = DNN(X_train_tensor.shape[1], 256,1)
# 将模型放到device上
model.to(device)3.7、定义损失函数和优化器
python
# 定义损失函数,使用均方误差损失函数,回归任务
criterion = nn.MSELoss()
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.01)3.8、训练模型
python
for epoch in range(1,1001):
# 将模型设置为训练模式
model.train()
# 初始化总损失
total_loss = 0
# 循环加载dataLoader,每次获取一个批次的数据和标签
for inputs, labels in train_loader:
# 清空优化器梯度
optimizer.zero_grad()
# 将inputs和labels放到device上,即将输入数据放到指定的设备上
inputs = inputs.to(device)
labels = labels.to(device)
# 前向传播,计算输出
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播和优化
loss.backward()
# 更新参数
optimizer.step()
# 累加当前批次的损失
total_loss += loss
# 计算本次epoch的平均损失
avg_loss = total_loss / len(train_loader)
# 每10个epoch打印一次当前模型的训练情况
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{1000}], Loss: {avg_loss:.4f}')3.9、模型评估
python
with torch.no_grad():
# 将模型设置为评估模式
model.eval()
# 将测试集放到模型上计算输出
predict_test = model(X_test_tensor.to(device))
# 计算测试集的损失
test_loss = criterion(predict_test, y_test_tensor.to(device))3.10、 可视化
python
# 将预测值从GPU移动到CPU上再去转换为Numpy
predictions = predict_test.cpu().numpy()
# 将测试集目标值从CPU上移动到CPU上并转换为Numpy
y_test_numpy = y_test_tensor.cpu().numpy()
# 绘制结果,创建一个新的图形窗口
plt.figure(1)
# 绘制散点图,用来显示实际值和预测值的关系
plt.scatter(y_test_numpy, predictions, color='blue')
# 绘制对角线,用来对比
plt.plot([min(y_test_numpy), max(y_test_numpy)], [min(y_test_numpy), max(y_test_numpy)], linestyle='--', color='red', lw=2)
# 设置x轴标签
plt.xlabel('Actual Values')
# 设置y轴标签
plt.ylabel('Predicted Values')
# 设置标题
plt.title('Regression Results')
# 绘制实际值和预测值的曲线
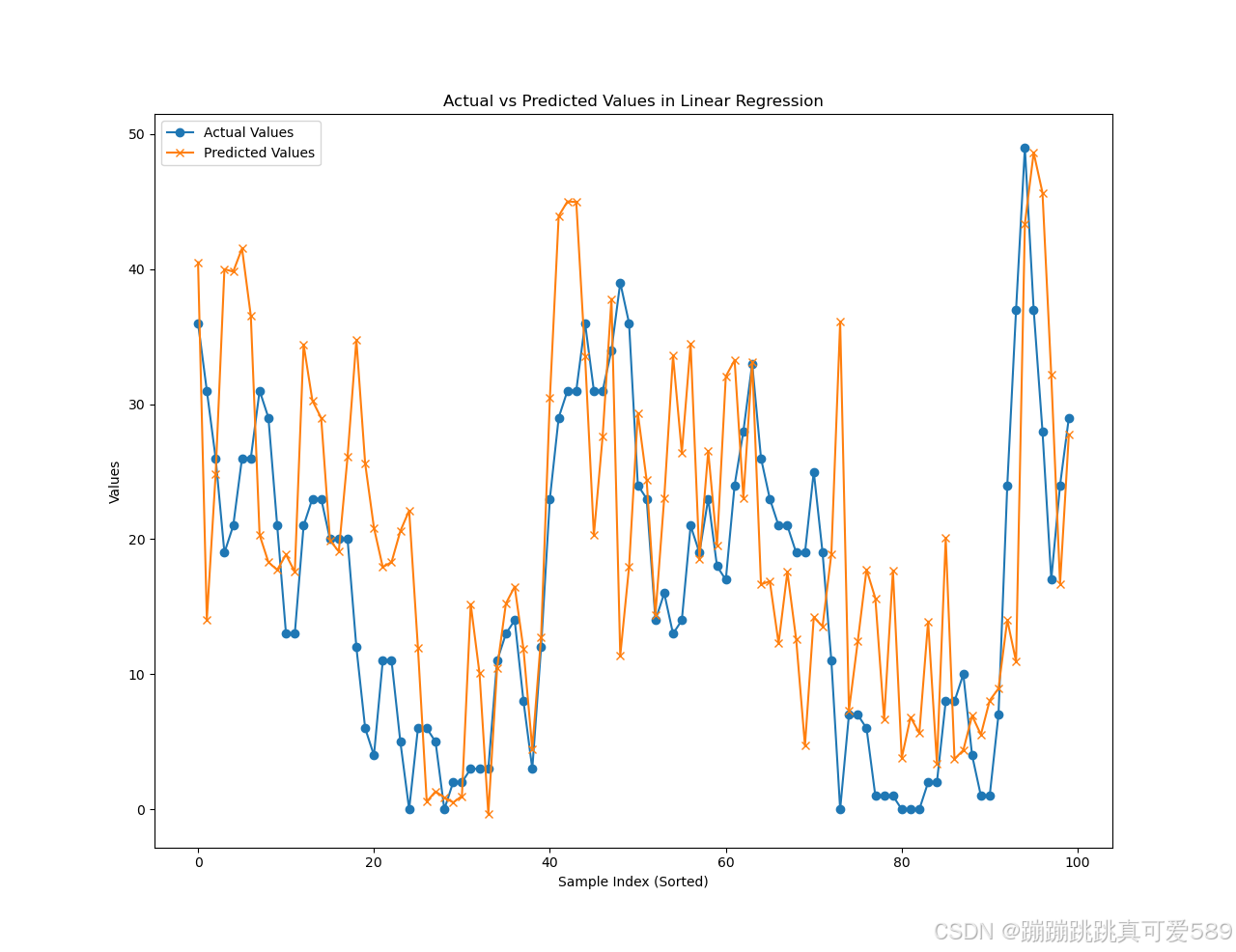
# 创建一个新的图形窗口
plt.figure(2)
# 绘制实际值的曲线,取最后100个样本
plt.plot(y_test_tensor[-100:], label='Actual Values', marker='o')
# 绘制预测值的曲线,取最后100个样本
plt.plot(predictions[-100:], label='Predicted Values', marker='*')
# 设置x轴标签
plt.xlabel('Sample Index')
# 设置y轴标签
plt.ylabel('Values')
# 设置标题
plt.title('Actual vs Predicted Values in Linear Regression')
plt.show()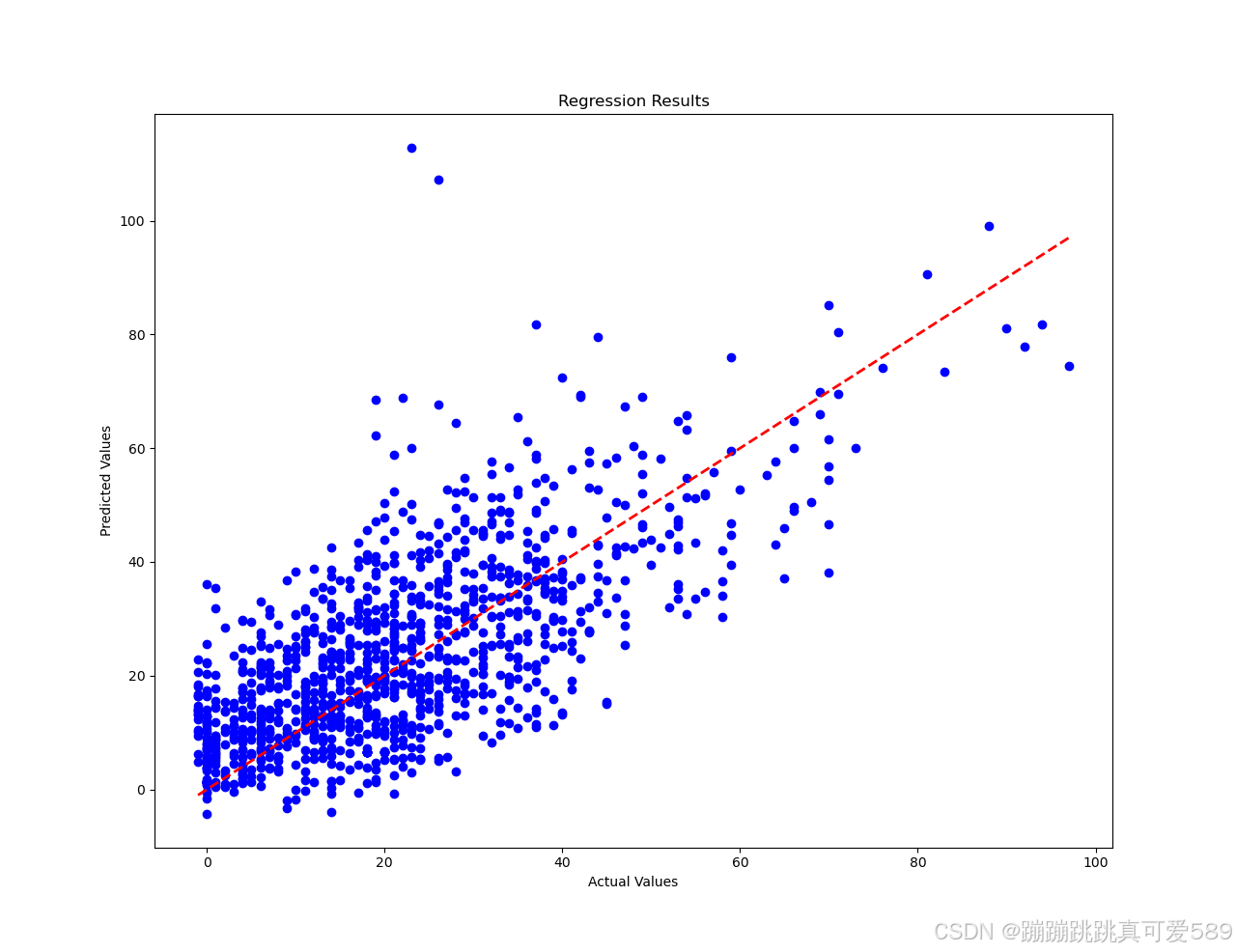
3.11、完整代码
python
# 导入必要的库
import pandas as pd # 数据处理
import numpy as np # 数值计算
import random # 随机数生成
import os # 操作系统功能
import torch # PyTorch库
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化算法
import matplotlib.pyplot as plt # 绘图
import seaborn as sns # 高级可视化工具
from sklearn.preprocessing import StandardScaler # 特征缩放
from torch.utils.data import TensorDataset, DataLoader # 数据集与数据加载器
# 设置随机种子以保证结果的可重复性
def setup_seed(seed):
# 设置 Numpy 随机数种子,确保Numpy生成的随机数序列一致
np.random.seed(seed)
# 设置Python内置随机数种子,保证Python内置的随机函数生成的随机数一致
random.seed(seed)
# 设置Python哈希种子
os.environ['PYTHONHASHSEED'] = str(seed)
# 设置PyTorch随机数种子
torch.manual_seed(seed)
# 检查CUDA设备
if torch.cuda.is_available():
torch.cuda.manual_seed(seed) # 设置CUDA随机种子
torch.cuda.manual_seed_all(seed) # 为所有GPU设置随机种子
torch.backends.cudnn.benchmark = False # 保证结果可重复
torch.backends.cudnn.deterministic = True # 使用确定性算法
# 检测CPU/GPU可用性
if torch.cuda.is_available():
device = 'cuda' # 使用CUDA
print('CUDA is useful!!')
else:
device = 'cpu' # 使用CPU
print('CUDA is not useful!!')
setup_seed(0) # 设置随机种子
# 设置pandas显示选项,以便显示更多列和行
pd.set_option('display.max_columns', 1000) # 最多显示1000列
pd.set_option('display.width', 1000) # 显示宽度为1000
pd.set_option('display.max_colwidth', 1000) # 每列最多显示1000个字符
# 读取数据集
train_data = pd.read_csv('train.csv', encoding='big5') # 注意编码格式
# 查看前5行数据,确保数据读取正确
# print(train_data.head())
# 打印数据集的信息,查看数据集的情况
# print(train_data.info())
# 选取从第3列开始到最后的所有列作为特征数据
train_data = train_data.iloc[:, 3:]
# 将数组中值为'NR'的元素替换为0
train_data[train_data == 'NR'] = 0
# 将train_data转换为Numpy数组
numpy_data = train_data.to_numpy()
# 创建一个列表,用来存储拆分后的数据
datas = []
# 按照步长为18分割数据
for i in range(0, 4320, 18):
datas.append(numpy_data[i:i+18, :])
# 将datas转换为Numpy数组
datas_array = np.array(datas, dtype=float)
# 对数据进行维度变换和重塑,转为DataFrame格式
train_data = pd.DataFrame(datas_array.transpose(1, 0, 2).reshape(18, -1).T)
# 计算特征相关性矩阵
corr = train_data.corr()
# 绘制相关性热图
plt.figure(0)
# 使用seaborn库绘制相关性矩阵的热图
sns.heatmap(corr, annot=True)
# 从相关性矩阵里筛选比较重要的特征(绝对值大于0.2的特征)
important_features = []
for i in range(len(corr.columns)):
if abs(corr.iloc[i, 9]) > 0.2:
important_features.append(corr.columns[i])
# print('比较重要的特征:', important_features)
# 定义特征(X)和目标(y)
X = train_data[important_features].drop(9, axis=1) # 选取重要特征,但排除目标特征
y = train_data[9] # 选取第9列
# 划分训练集和测试集
train_ratio = 0.8 # 设定训练集比例
# 训练集特征
X_train = X[:int(train_ratio * len(train_data))] # 根据比例切分训练集特征
# 测试集特征
X_test = X[int(train_ratio * len(train_data)):] # 根据比例切分测试集特征
# 训练集标签
y_train = y[:int(train_ratio * len(train_data))] # 根据比例切分训练集标签
# 测试集标签
y_test = y[int(train_ratio * len(train_data)):] # 根据比例切分测试集标签
# 使用标准化进行特征缩放
scaler = StandardScaler() # 实例化标准化对象
X_train_scaled = scaler.fit_transform(X_train) # 拟合并转换训练集特征
X_test_scaled = scaler.transform(X_test) # 仅转换测试集特征
# 将数据转换为PyTorch的张量
# 训练集的特征张量表示
X_train_tensor = torch.tensor(X_train_scaled, dtype=torch.float32)
# 训练集的标签张量表示
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).view(-1, 1)
# 测试集的特征张量表示
X_test_tensor = torch.tensor(X_test_scaled, dtype=torch.float32)
# 测试集的标签张量表示
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32).view(-1, 1)
# 使用DataLoader加载数据集
# 创建TensorDataset对象,将训练集特征和标签一一组合在一起
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
# 创建DataLoader对象,用于批量加载数据
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 构建DNN模型
class DNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
# 调用父类的构造函数
super(DNN, self).__init__()
# 定义第一个Linear层,输入维度为input_size,输出维度为hidden_size
self.fc1 = nn.Linear(input_size, hidden_size)
# 定义第二个Linear层,输入是hidden_size,输出维度是hidden_size
self.fc2 = nn.Linear(hidden_size, hidden_size)
# 定义第三个Linear层,输入是hidden_size,输出维度是hidden_size
self.fc3 = nn.Linear(hidden_size, hidden_size)
# 定义第四个Linear层,输入是hidden_size,输出维度是output_size
self.fc4 = nn.Linear(hidden_size, output_size)
# 定义激活函数
self.relu = nn.ReLU() # ReLU激活函数
def forward(self, x):
# 输入数据经过各层和激活函数
x = self.relu(self.fc1(x)) # 第一个Linear和ReLU激活
x = self.relu(self.fc2(x)) # 第二个Linear和ReLU激活
x = self.relu(self.fc3(x)) # 第三个Linear和ReLU激活
x = self.fc4(x) # 最后一层线性输出
return x
# 实例化模型
model = DNN(X_train_tensor.shape[1], 256, 1) # 输入特征维度、隐藏层节点数和输出维度
# 将模型放到指定设备上(GPU或CPU)
model.to(device)
# 定义损失函数,使用均方误差损失函数,适用于回归任务
criterion = nn.MSELoss()
# 定义优化器,使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 进行训练迭代
for epoch in range(1, 1001):
model.train() # 将模型设置为训练模式
total_loss = 0 # 初始化总损失
# 循环加载DataLoader,每次获取一个批次的数据和标签
for inputs, labels in train_loader:
# 清空优化器梯度
optimizer.zero_grad()
# 将inputs和labels放到device上
inputs = inputs.to(device)
labels = labels.to(device)
# 前向传播,计算输出
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播和优化
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
# 累加当前批次的损失
total_loss += loss.item() # 获取当前批次的损失,累加到 total_loss
# 计算本次 epoch 的平均损失
avg_loss = total_loss / len(train_loader)
# 每10个epoch打印一次当前模型的训练情况
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{1000}], Loss: {avg_loss:.4f}')
# 模型的评估
with torch.no_grad(): # 不计算梯度以提高速度和减少内存使用
model.eval() # 将模型切换到评估模式
# 将测试集放到模型上计算输出
predict_test = model(X_test_tensor.to(device))
# 计算测试集的损失
test_loss = criterion(predict_test, y_test_tensor.to(device))
# 打印测试集的损失
print('MSE:', test_loss.item()) # 打印均方误差
# 将预测值和目标值转换为Numpy数组
predictions = predict_test.cpu().numpy() # 将预测值从GPU移到CPU并转换为Numpy
y_test_numpy = y_test_tensor.cpu().numpy() # 将测试集目标值从GPU移动到CPU并转换为Numpy
# 绘制结果,创建一个新的图形窗口
plt.figure(1)
# 绘制散点图,用来显示实际值和预测值的关系
plt.scatter(y_test_numpy, predictions, color='blue', label='Predicted Values')
# 绘制对角线,用来对比预测值与实际值的关系
plt.plot([min(y_test_numpy), max(y_test_numpy)], [min(y_test_numpy), max(y_test_numpy)],
linestyle='--', color='red', lw=2, label='Ideal Prediction')
# 设置x轴标签
plt.xlabel('Actual Values')
# 设置y轴标签
plt.ylabel('Predicted Values')
# 设置标题
plt.title('Regression Results')
plt.legend() # 显示图例
# 绘制实际值和预测值的曲线
plt.figure(2)
# 绘制实际值的曲线,取最后100个样本
plt.plot(y_test_numpy[-100:], label='Actual Values', marker='o')
# 绘制预测值的曲线,取最后100个样本
plt.plot(predictions[-100:], label='Predicted Values', marker='*')
# 设置x轴标签
plt.xlabel('Sample Index')
# 设置y轴标签
plt.ylabel('Values')
# 设置标题
plt.title('Actual vs Predicted Values in Linear Regression')
plt.legend() # 显示图例
plt.show() # 显示所有图形