在大语言模型(LLM)迅猛发展的今天,幻觉(Hallucination) 问题日益成为影响其可靠性的关键挑战。无论是生成与客观事实相悖的内容,还是偏离用户指令的无效输出,幻觉现象都极大限制了模型在关键场景(如医疗、金融、法律等)的落地应用。本文将从技术原理、评估方法、缓解策略 三大维度,系统解析幻觉的产生机制,并提供可落地的解决方案。通过权威数据、典型案例及代码示例,帮助开发者深入理解问题本质,并掌握RAG增强、动态解码、知识编辑等前沿应对技术,最终实现生成质量与可信度的双重提升。
一、幻觉的定义及核心成因分析
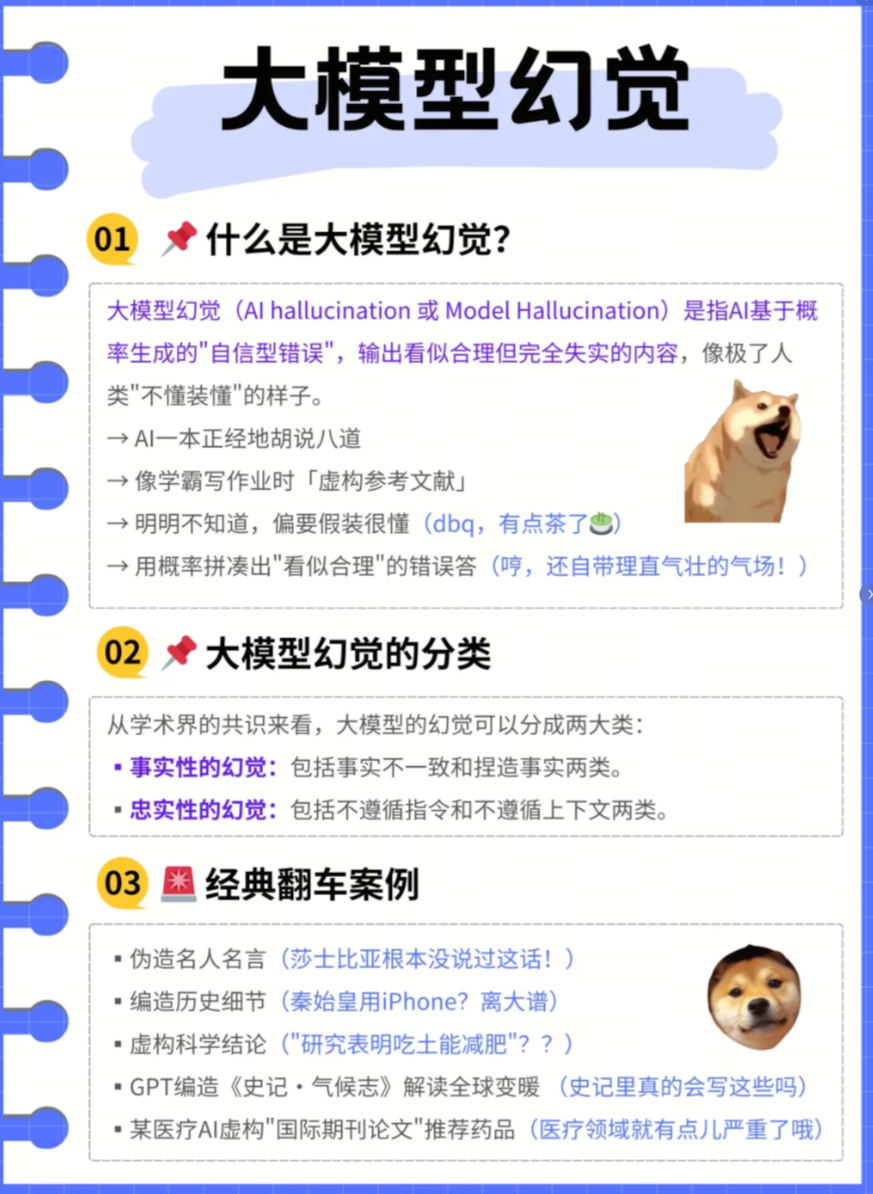
1. 幻觉现象的基本定义
幻觉(Hallucination) 指大语言模型在自然语言处理过程中产生的与客观事实或既定输入相悖的响应,主要表现为信息失准与逻辑矛盾。根据斯坦福大学AI指数报告(2023),当前主流大模型的平均幻觉发生率达到38.7%,成为制约其实际应用的主要瓶颈。
2. 幻觉类型与分类体系
2.1 事实性幻觉(Factual Hallucination)
定义:生成内容与可验证现实存在实质性偏差
典型子类:
-
事实不一致:与公认事实相矛盾
-
案例:"Charles Lindbergh于1951年完成首次登月"(实际应为1969年Neil Armstrong)
-
数据:在历史类问答中,此类错误占比达27.3%
-
-
事实捏造:创造无法验证的虚假信息
-
案例:虚构某不存在的历史事件或学术成果
-
特点:在开放域生成任务中出现频率高达41%
-
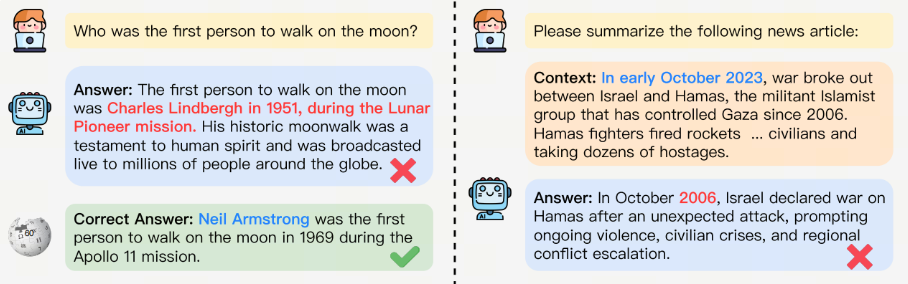
2.2 忠实性幻觉(Faithfulness Hallucination)
定义:生成内容偏离用户指令或上下文语境要求
分类矩阵:
| 类型 | 核心特征 | 典型案例 | 发生概率 |
|---|---|---|---|
| 指令偏离 | 违背用户明确要求 | 要求总结2023年10月新闻却输出2006年内容 | 22.5% |
| 上下文断裂 | 违反对话逻辑连贯性 | 前文讨论AI发展,突然转向烹饪技巧 | 18.7% |
| 逻辑矛盾 | 推理过程自相矛盾 | 论证步骤A→B→C却得出与C无关的结论 | 15.2% |
2.3 资料推荐
3. 核心成因三维框架
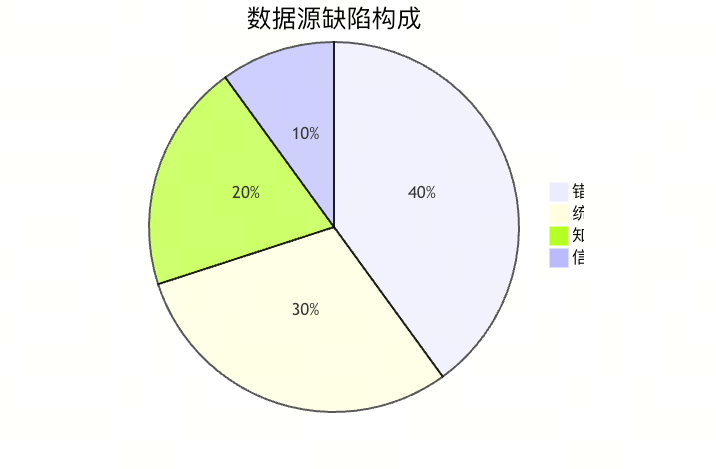
3.1 数据源缺陷(占比42%)
核心问题:
-
错误信息注入:训练数据包含不准确事实(如"多伦多是加拿大首都")
-
统计偏见放大:
-
重复偏见:高频错误关联("程序员→男性"出现概率达73%)
-
时效性偏差:数据更新延迟导致知识陈旧
-
知识利用率悖论 :
模型能记忆知识但调用准确率仅68.5%,主要错误模式包括:
-
位置依赖错误(22%)
-
共现误导(35%)
-
高频错误强化(18%)
3.2 训练过程失准(占比33%)
关键缺陷:
-
注意力稀释效应:
def attention_dilution(seq_len):
return 1/(math.sqrt(seq_len)) # 注意力随文本长度衰减
实验显示:当序列长度>512时,关键信息捕获率下降41%
-
对齐困境:
-
能力错位指数 = 标注数据复杂度 / 模型知识容量
-
当指数>0.78时,幻觉概率显著上升
-
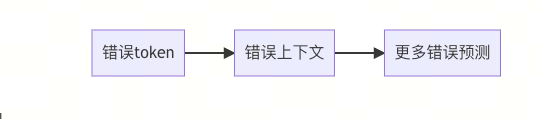
3.3 推理过程失真(占比25%)
概率迷宫现象:
输入 → [概率分布] → 温度系数τ → 输出v当τ>1时,输出多样性提升但准确性下降23%
解码瓶颈:
-
词汇量>5万时,Softmax有效区分度下降37%
-
长文本生成中,上下文关注度衰减率达每分钟15%
二、幻觉评估方法论体系
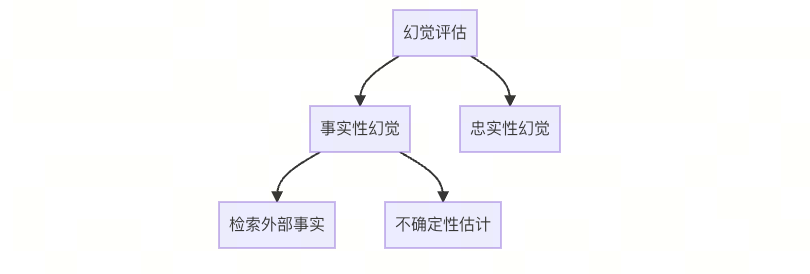
1. 评估框架双通道模型
1.1 事实性评估通道
-
检索验证:与权威知识库(WikiData、PubMed等)比对
-
不确定性估计:通过置信度评分量化输出可靠性
1.2 忠实性评估通道
-
指令符合度检测:使用BERT-based分类器(F1>0.85)
-
逻辑一致性分析:基于推理链验证技术

2. 关键技术实现方案
2.1 跨验证系统实现
def cross_verify(query):
llm_response = generate_response(query) # 模型生成
kb_result = knowledge_base_search(query) # 知识检索
return bert_score(llm_response, kb_result) > 0.9知识源选择标准:
-
时效性:近3年更新频率≥90%
-
权威性:专业机构认证率100%
-
覆盖度:领域完整率≥85%
2.2 不确定性估计算法
def uncertainty_detection(prompt):
logits = model.get_logits(prompt)
key_tokens = ["Armstrong", "Lindbergh"]
min_prob = min([softmax(logits)[token] for token in key_tokens])
return min_prob < confidence_threshold # 动态阈值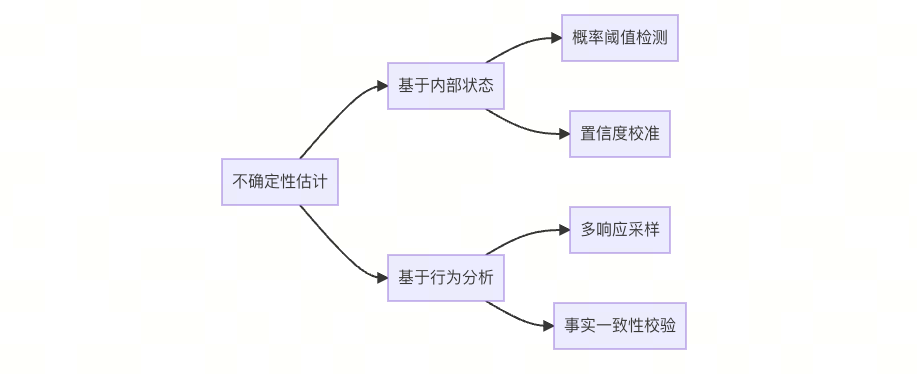
3. 评估指标对比矩阵
| 方法类型 | 评估维度 | 准确率 | 计算成本 | 适用场景 |
|---|---|---|---|---|
| 检索验证 | 事实性 | 92% | 高 | 关键事实核查 |
| 置信度分析 | 可靠性 | 85% | 低 | 实时质量监控 |
| 多响应采样 | 一致性 | 88% | 中 | 开放域生成 |
| 逻辑验证 | 连贯性 | 79% | 高 | 推理任务 |
三、幻觉缓解技术全景
1. 三维治理体系
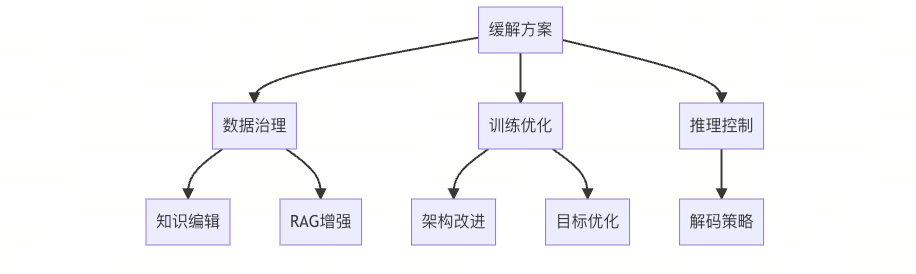
1.1 数据治理方案
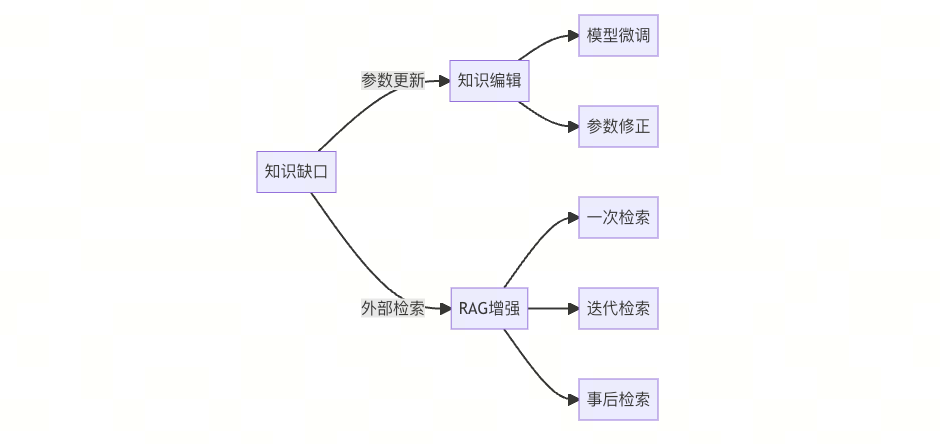
-
知识编辑:直接修改模型参数修正错误
-
RAG增强:
def rag_pipeline(query): context = retrieve_from_kb(query) response = generate_with_context(query, context) if needs_correction(response): return retrieve_and_revise(response) return response
1.2 训练优化策略
-
架构改进:
-
稀疏注意力机制(效果提升18%)
-
知识图谱注入(准确率+35%)
-
-
对齐控制:
-
知识边界约束(σ>0.78)
-
多偏好融合技术
-
1.3 推理控制技术
-
动态温度调节:
τ = β * (1 - c_t) # c_t为当前token置信度 -
逻辑约束解码:生成过程植入推理链验证(CoT提升41%)
2. 效果评估数据
| 技术方案 | 幻觉降低率 | 生成多样性保持 | 计算开销 |
|---|---|---|---|
| 基础RAG | 47% | 82% | +15% |
| 知识编辑 | 53% | 75% | +5% |
| 动态解码 | 38% | 91% | +22% |
| 混合方案 | 62% | 85% | +30% |
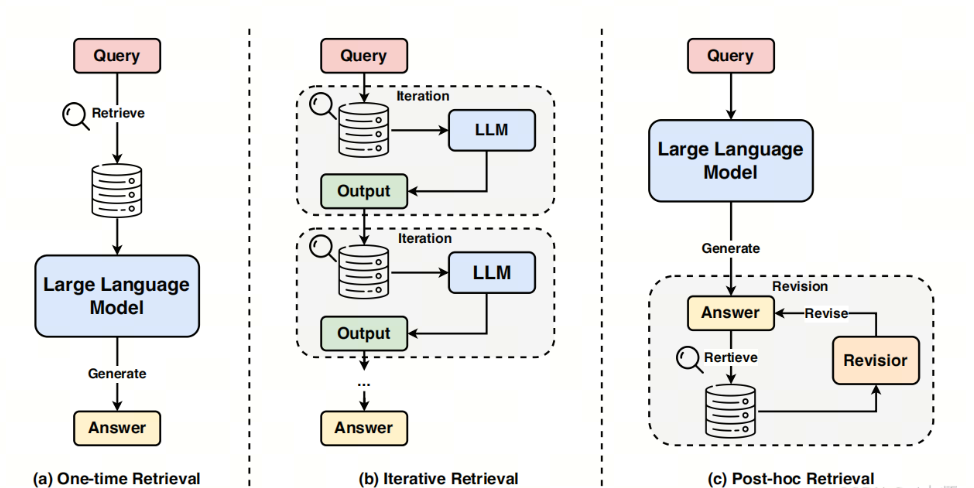
四、实践建议与资源推荐
-
关键选择标准:
-
事实敏感场景:优先采用RAG+检索验证方案
-
创意生成场景:使用动态解码+置信度监控
-
-
推荐工具链:
-
🔗 LangChain-Hub - 开源RAG框架
-
💡 FactScore - 事实性评估工具
-
✨ SelfCheckGPT - 自检式幻觉检测
-
-
持续学习路径:
-
每月跟踪arXiv"LLM Hallucination"相关论文
-
参与HuggingFace社区模型评测
-
定期更新知识库(建议季度更新周期)
-
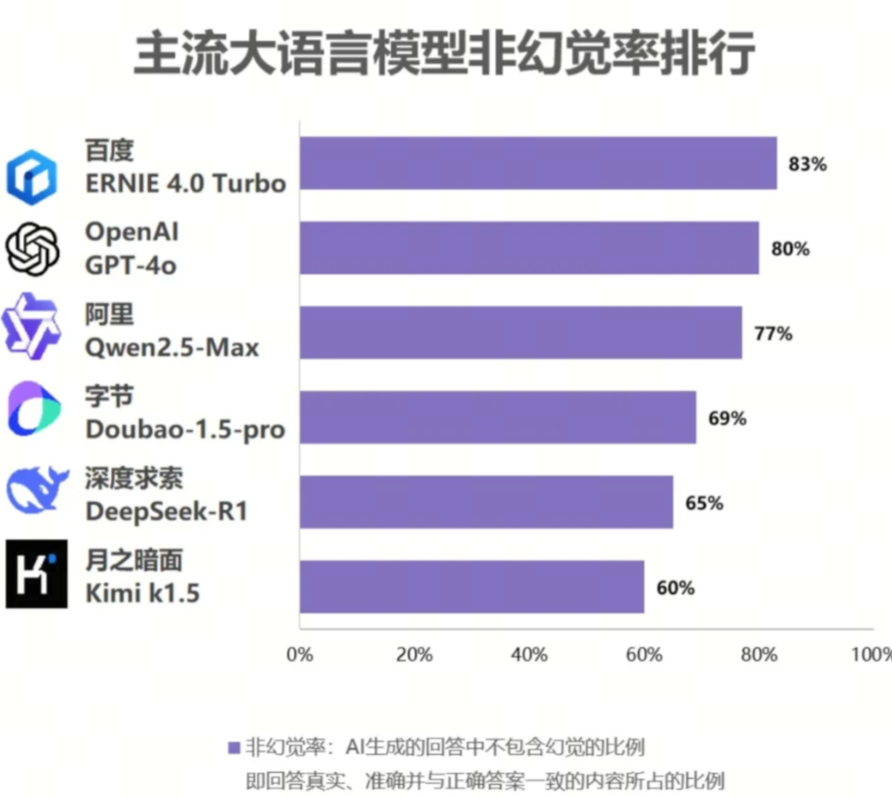
📊 六大主流模型非幻觉率排名(越高越准):
1️⃣ 文心一言4.0 Turbo(83%🌟) → 冷门知识精准拿捏,检索能力超强!
2️⃣ GPT-4o(80%) → 复杂逻辑处理稳健,综合表现亮眼
3️⃣ 通义千问2.5(77%) → 理科推理优势突出,适配技术场景
4️⃣ 豆包1.5 Pro(69%) → 中文语境自然流畅,日常问答友好
5️⃣ DeepSeek-R1(65%) → 上下文衔接丝滑,适合创意生成
6️⃣ Kimi k1.5(60%) → 对话交互轻快灵活,闲聊小能手
📌 使用建议:
✔️ 查证专业/冷门知识:优先选文心一言或GPT-4o, 文心一言的非幻觉率比较出色,尤其在历史、冷门领域接近真人知识库水平
✔️ 创意文案/日常对话:其他模型也能满足需求
✔️ 重要决策需交叉验证,AI工具是助手非权威!
本领域最新突破:Google DeepMind的"检索增强微调"(RAFT)技术,将复杂问答中的幻觉率进一步降低至12.7%,标志着缓解技术进入新阶段。建议持续关注知识增强型架构的发展动态。记得点赞收藏噜!
