文章题目是《A grid‐based classification and box‐based detection fusion model for asphalt pavement crack》
于2023年发表在《Computer‐Aided Civil and Infrastructure Engineering》
论文采用了一种基于网格分类和基于框的检测(GCBD),其中基于网格分类的部分主要用于对裂缝区域进行细粒度划分,是同时进行分类和检测的。
📌文章针对目前存在的问题:
- 网格的局部感受野无法提取裂缝的整体特征难以对横向裂缝、纵向裂缝的宏观特征进行判断
- 目标检测容易产生大量冗余预测框,并且裂缝独特的拓扑结构会干扰通用的非极大值抑制算法的筛选过滤,造成裂缝检测性能的劣化
✨论文的主要贡献:
- 构建了大规模高质量标注沥青路面病害图像双标记数据集
- 模型同时实现分类与检测
- 提出了基于网格的图像分类策略,一次性识别整张图像所有的网格
- 基于改进YOLOv5框的检测
- 构建了一个集成GCBD的融合模型
- 达到工业级的应用性能水平,符合工程标准(《公路技术状况评定标准JTG5210-2018》)
- 输出结果可直接用于计算路面状况指数(PCI)
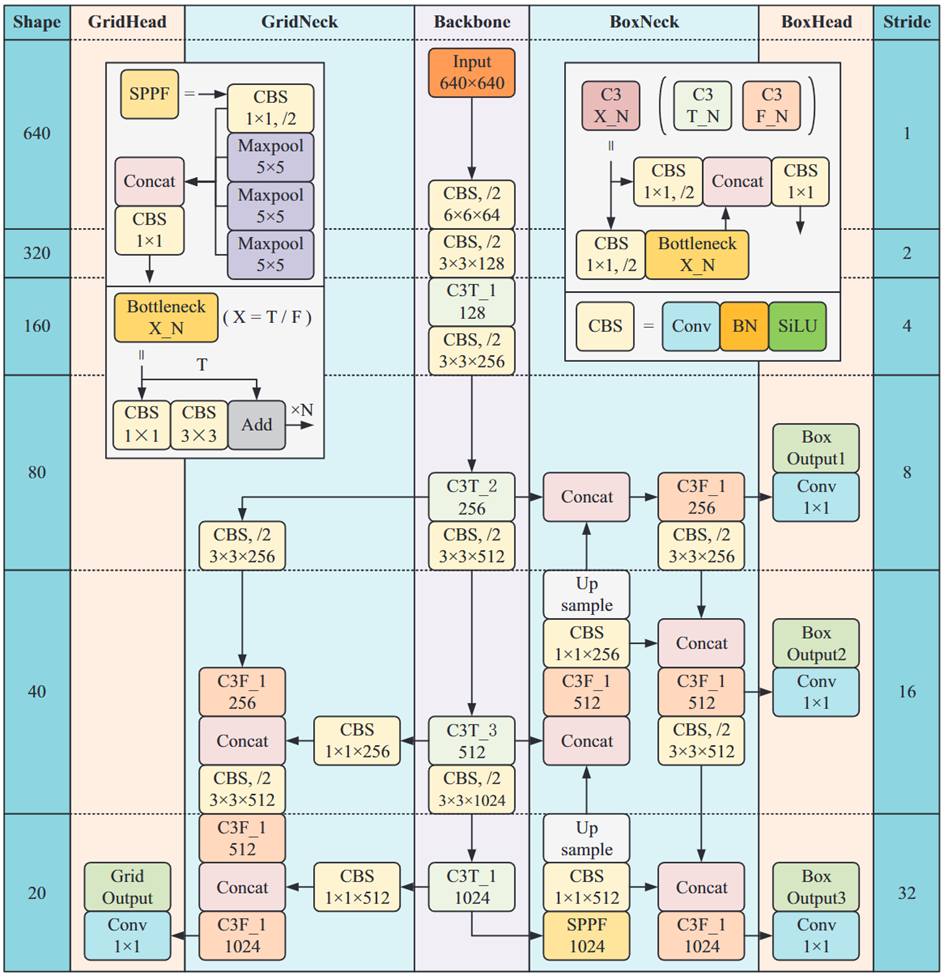
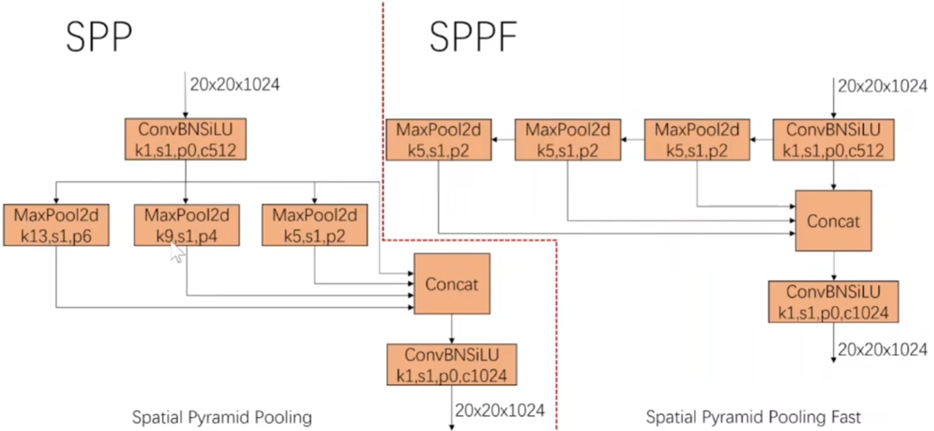
整体的网络结构非常清晰明了,一共就是四步,其中NMS-ARS和MaM是文章提出的后处理方法,分类头和检测头共享骨干网络的参数。
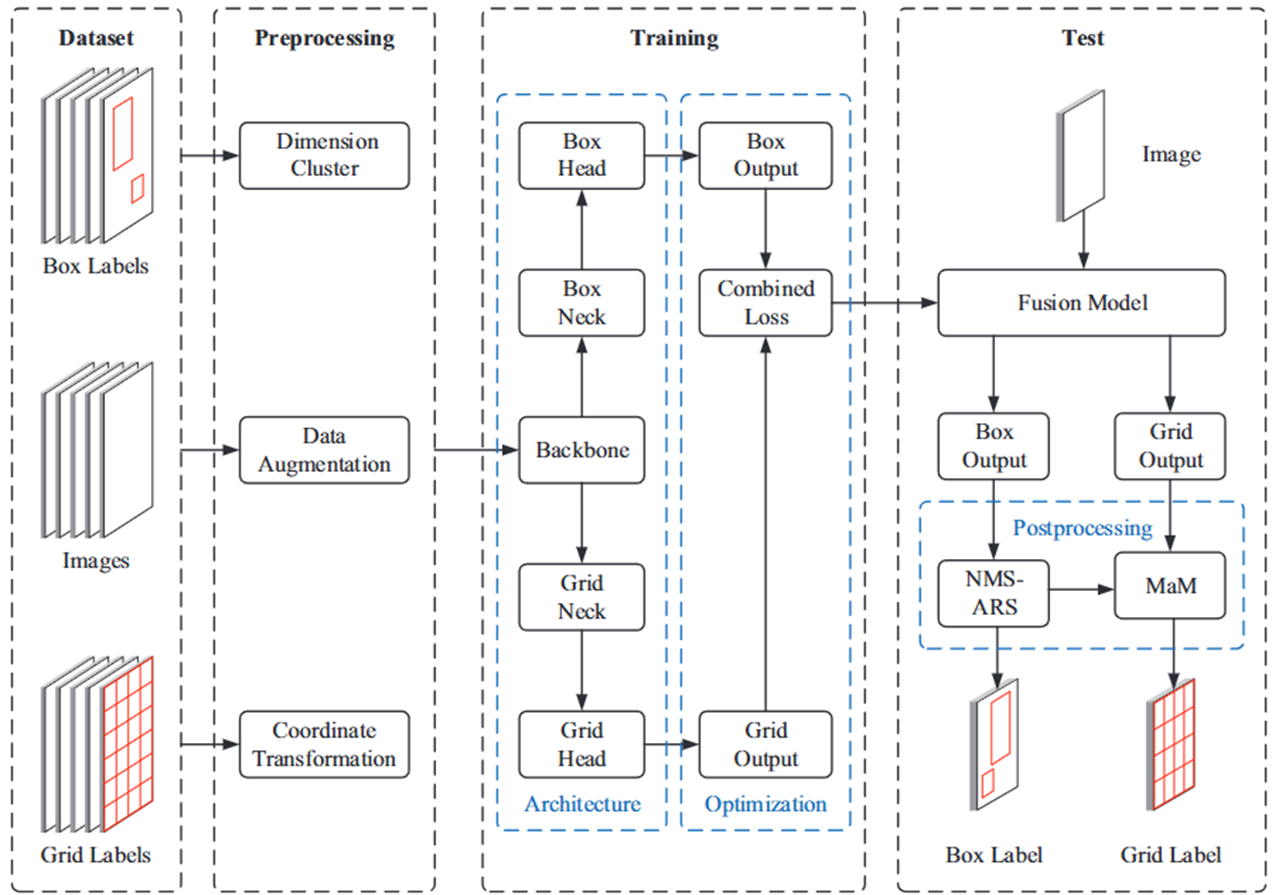 🔢关于数据集
🔢关于数据集
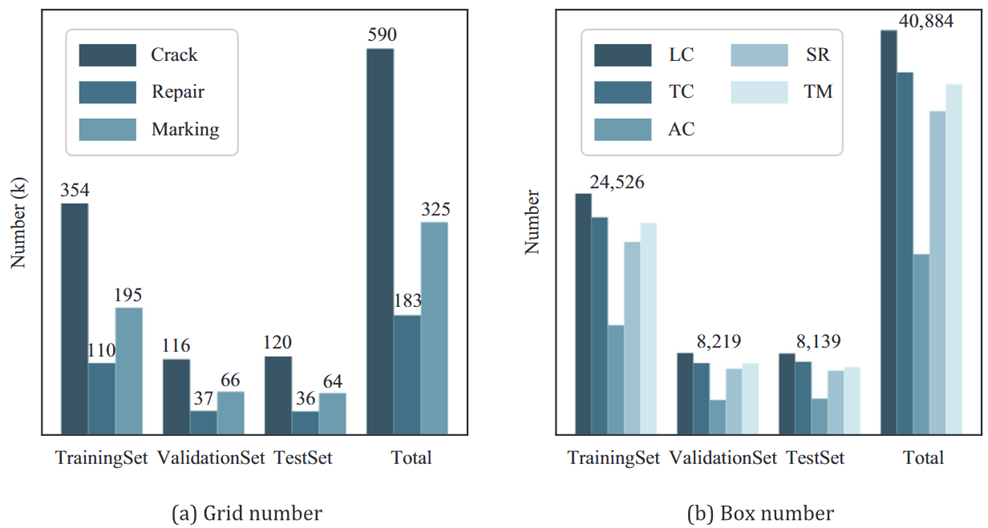
- 图像大小为2048×2048,20000张,按6:2:2划分
- 在自上而下的相机视图中,地面采样距离约为1毫米
- 图像来自北京、湖南、广东、新疆
- 包含多个复杂的场景(如树叶、沙子、水、阴影)
- 所有图像都使用所提出的融合模型的双重方法进行注释
- 基于网格的方法将图像分为20 × 20个单元格,那么对于2048*2048大小的图像来说的话每个单元格就是102.4*102.4像素的,resize到640*640每个单元格就是32*32像素的
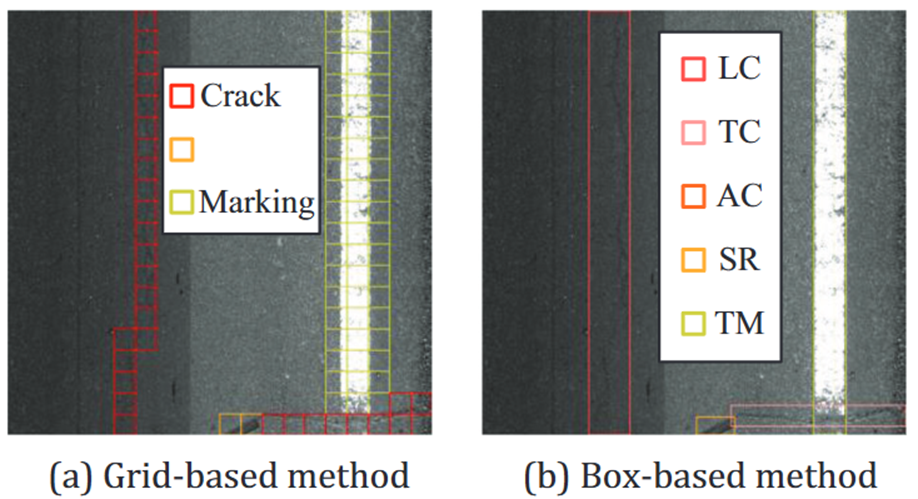
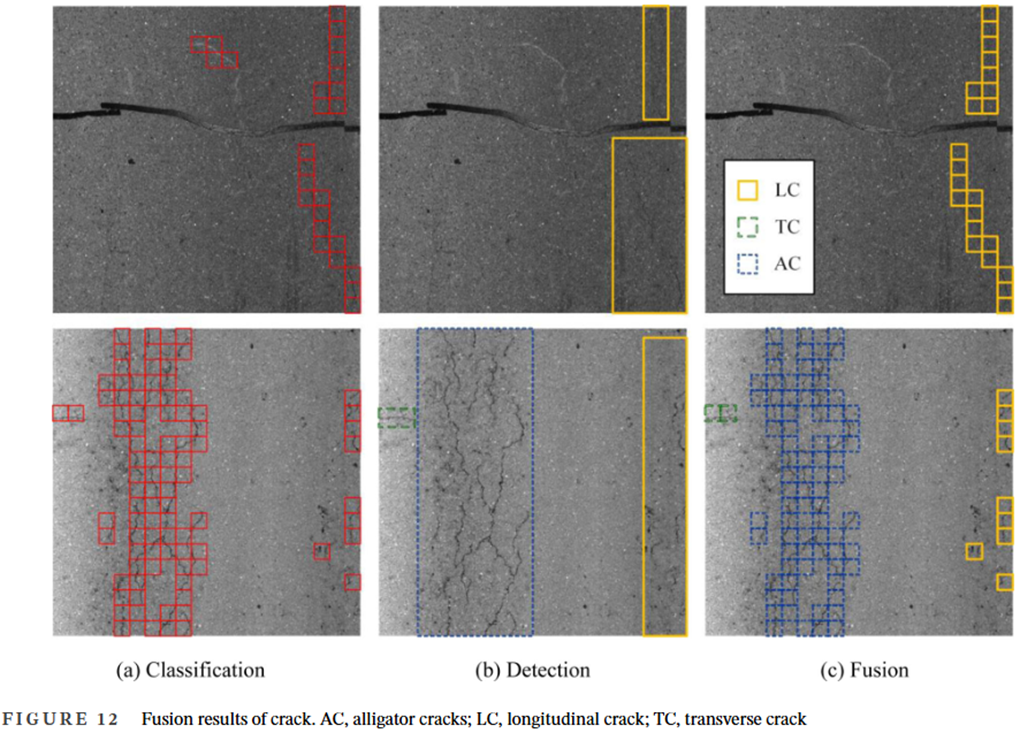
左图中橙色是修补Repair,LC是纵向裂缝,TC是横向裂缝,AC是龟裂,SR是条状修补,TM就是交通标线了,就是道路上的那两条白色线条

💡Preprocessing-Data Augmentation
- 将图像调整为640×640,像素值在0到1之间进行归一化
- 图像增强仅在水平和垂直翻转,概率为50%
- 色调、饱和度和值 (HSV) 颜色空间中的 H、S 和 V 通道中添加扰动来执行颜色抖动
- 路面裂缝图像的色调相对单一,而饱和度和值随环境因素**(如光照)**显著变化。因此,色调的干扰系数较小(0.015), 但饱和度和值较大(分别为 0.7 和 0.4)
- Mosaic增强用于通过四个图像来丰富上下文
- 不能使用翻转,这样的话会混淆TC和LC的

💡Preprocessing-Dimension Cluster
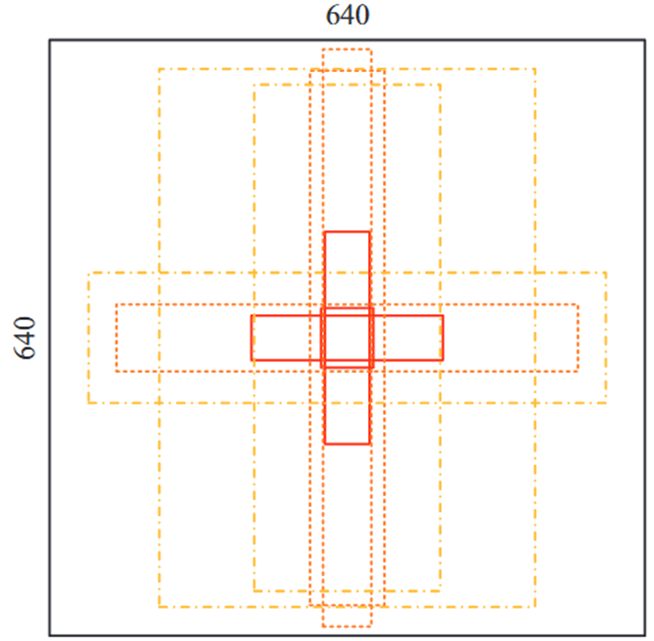
- 采用K-Means聚类和遗传算法生成自适应锚点
- anchor box影响预测框的规模和质量
- p在 1000 代进化锚点后,锚点的大小为 (53, 65)、(206, 48)、(49, 228)、(52, 621)、(496, 73)、(80, 576)、(55, 141)、(201, 543) 和 (405, 577),最好的可能召回率为 99.3%,也就是说可以使用上述锚点检测到最多 99.3% 的对象
💡Preprocessing-Coordinate Transformation
这一步就是将网格标签和检测标签建立在同一坐标系上,换句话说就是,网格标签也采用目标检测的标签形式,只不过网格的类别用负数标记,从-1开始。
3 0.797297 0.350000 0.405405 0.100000
-4 0.851351 0.325000 0.027027 0.050000
-4 0.878378 0.325000 0.027027 0.050000
-4 0.905405 0.325000 0.027027 0.050000
-4 0.932432 0.325000 0.027027 0.050000
-4 0.959459 0.325000 0.027027 0.050000
-4 0.986486 0.325000 0.027027 0.050000
-4 0.608108 0.375000 0.027027 0.050000
-4 0.635135 0.375000 0.027027 0.050000
-4 0.662162 0.375000 0.027027 0.050000
-4 0.689189 0.375000 0.027027 0.050000
-4 0.716216 0.375000 0.027027 0.050000
-4 0.743243 0.375000 0.027027 0.050000
-4 0.770270 0.375000 0.027027 0.050000
-4 0.797297 0.375000 0.027027 0.050000
-4 0.824324 0.375000 0.027027 0.050000
-4 0.851351 0.375000 0.027027 0.050000
🧶Training
- 共享骨干网络联合训练的多视觉任务模型
- 骨干网络提取高维深度特征
- 网络分类分支和标框检测分支分别整合微观和宏观特征
CBS: Conv、BN、sigmoid linear unit(SiLU)
C3T块由三个卷积块和一个瓶颈T_N块组成,集成了特征映射,消耗的计算资源更少
🎨loss function

网格和框损失函数的分配系数是0.2,这可以设置为一个超参数。
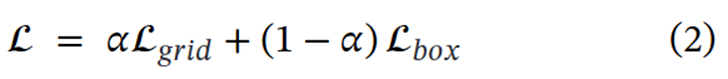
在进行计算损失的时候,box就按照BBR的损失正常计算就行,grid是先将真实标签的box转换为grid网格的形式,用一个常数标记,比如1。
grid的预测值是一个思维张量,形状为B,C,H,W,B就是batch size,C是grid的类别数,H和W是特征图的高宽。预测张量中的每个值表示对应位置的grid单元属于特定类别的概率(经过sigmoid激活后)。
🎨超参数
- 模型采用迁移学习和多任务学习。检测网络在COCO数据集中的常见对象上进行了预训练
- 分类网络和检测网络联合训练小批量大小为****64
- 100个epoch
- SGD优化器,学习率是0.01,动量为0.9
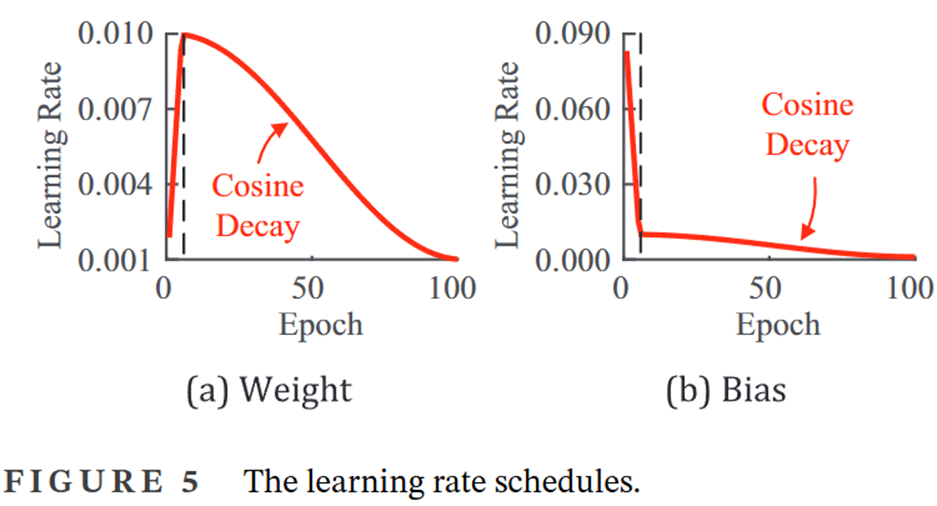
- Weight decay为0.0005,学习率采用warm-up和cosine decay
✨Postprocessing-ARS
NMS以高置信度提出了三个预测框A**、B和C。任意两个框之间的空隙低于通常的阈值,因此预测的裂纹被计数两次。如果IoU值过低,其他裂纹将被错误地过滤掉。**
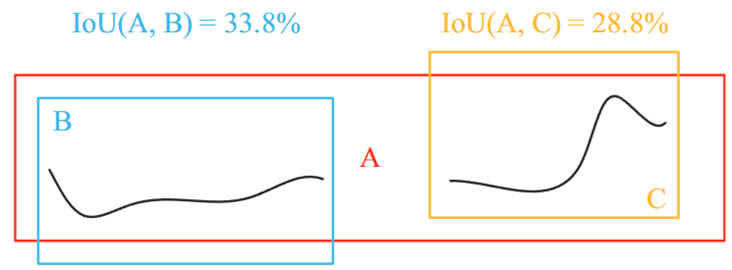
- 针对裂缝自相似性等分形几何拓扑结构,模型改进了标框目标检测后处理的NMS算法
- 提出一种面积减少抑制(ARS)增强NMS,保留高置信度的预测框,抑制具有高重叠区域的预测框的置信度
- 先要进行NMS,后再进行ARS


python
# prediction是经过NMS处理以后预测框的Tensor
def ras(self, prediction):
ars_threshold = 0.5 # ars的阈值
imgs = 640 # 输入图像resize大小
output = [torch.zeros((0, 6), device=prediction[0].device)] * len(prediction)
for xi, x in enumerate(prediction):
n = x.shape[0]
_, order = torch.sort(x[:, 4])
x = x[order]
classes = x[:, 5:6].clone()
classes[(classes == torch.tensor(self.crack_classes, device=x.device)).any(1)] = self.crack_classes[0]
bias = classes * imgs
boxes = x[:, :4] + bias
ioa = box_ioa(boxes, boxes)
mask = torch.arange(n).repeat(n, 1) <= torch.arange(n).view(-1, 1) # mask low conf boxes
ioa[mask] = 0
x = x[ioa.sum(1) < ars_threshold ]
output[xi] = x
return output
def box_ioa(box1, box2):
area = (box1[:, 2] - box1[:, 0]) * (box1[:, 3] - box1[:, 1])
return inter(box1, box2) / area.view(-1, 1) ✨Postprocessing-MaM
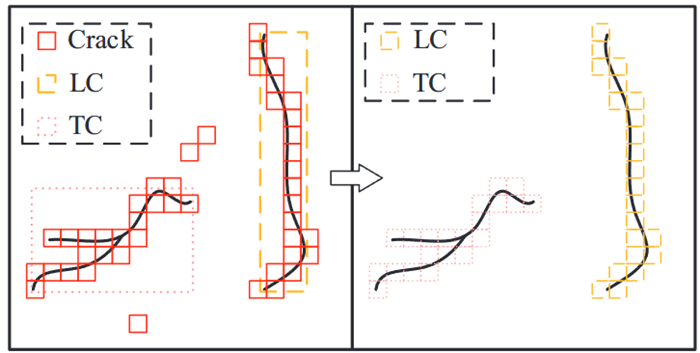
- 提出了MaM来过滤噪声并确定每个网格单元中捕获的裂纹类型
- 将检测盒外的单元格作为噪声滤除,将检测盒内的单元格分类为相应的类

- 第一步计算单元格和所有框之间的IoA,如果最大值为零,则该单元格是噪声过滤。否则,为单元格分配与网格最大值对应的box****类
- 当网格和多个方框的IoA变量同时达到最大值时,按照AC优先级最高、LC优先级最低的原则确定单元格的类别
python
# ratio 列表用于存储原始图像与预处理后(调整大小和填充后的)图像之间的宽高比
# class_grid2box 这个就是grid类别要匹配的box类别
class_grid2box = {0: (0,), 1: (1,), 2: (2,), 3: (3,)}
for i, (d, g, r) in enumerate(zip(box_pred, grid_pred, ratio)):
d[:, :4:2] *= r[0]
d[:, 1:4:2] *= r[1]
g[:, :4:2] *= r[0]
g[:, 1:4:2] *= r[1]
g_class = g[:, 5]
# change crack classes
new_g = []
for gc, v in class_grid2box.items():
for bc in v:
g_tmp = g[g_class == gc].clone()
g_tmp[:, 5:] = bc
new_g.append(g_tmp)
g = torch.cat(new_g)
if g.numel() > 0 and self.match:
d_class = d[:, 5:]
d_boxes = d[:, :4] + d_class * 4096
g_boxes = g[:, :4] + g[:, 5:] * 4096
iou = box_ioa(g_boxes, d_boxes)
index = iou.max(1)[0] > 0 if d.numel() > 0 else torch.zeros(g.shape[0], device=self.device).bool()
g = g[index]
box_pred[i] = d
grid_pred[i] = g🥯Results
- 使用两张内存为80G的NVIDIA A100显卡
- 在测试集上验证了GCBD模型的有效性
中的mAP是grid分类的指标,
是box检测的指标,考虑到分类和检测任务的学习难度,mAP与mAP50的比例为1:9。
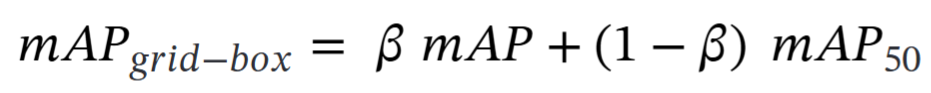
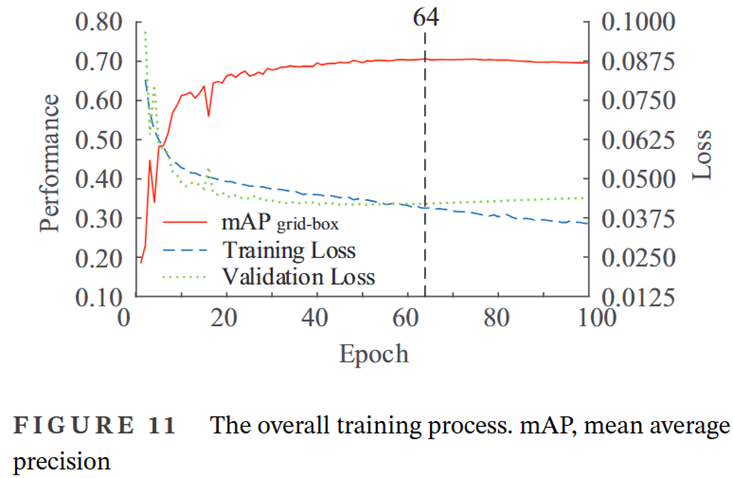
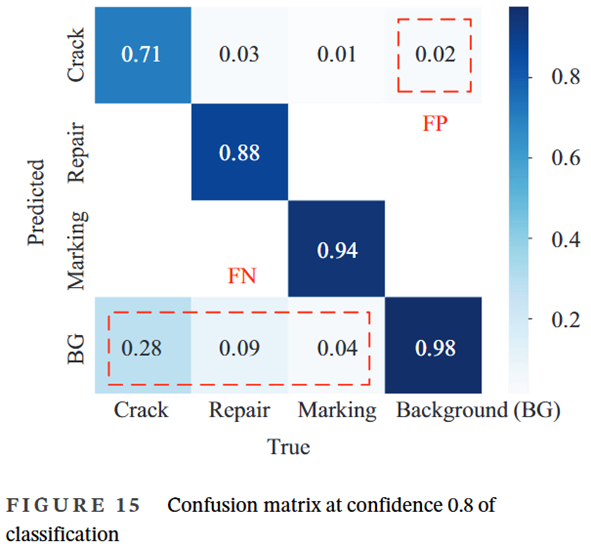
- 对于分类来说,最大F1分数的置信度超过0.8,并且相对接近
- 过拟合阶段的网络主要关注了学习置信度
- 分类混淆矩阵中分别有28%、9%和4%的裂纹、修复和标记与背景没有区别
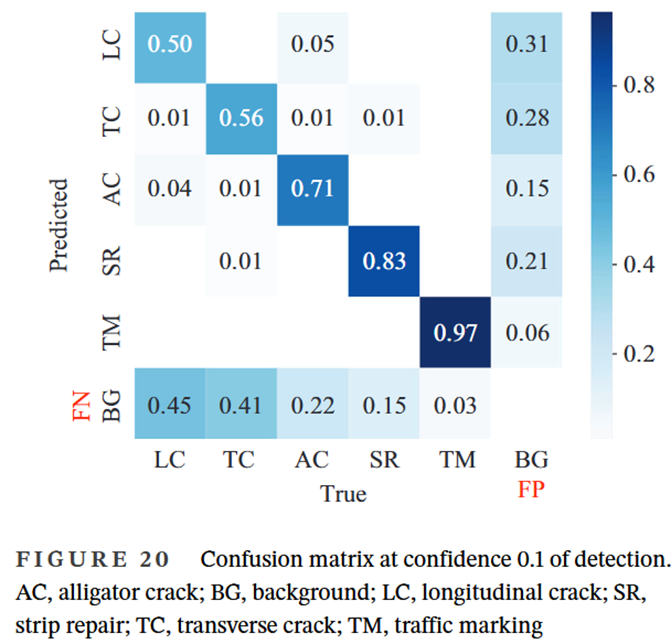
- 对于检测来说,所有类别的最高F1分数表明置信度较低
- 从背景中分别错误地检测到0.31的LC和0.28的TC,这表明线性裂纹的特征与背景相似。需要一个强大的特征提取网络来解决这个问题
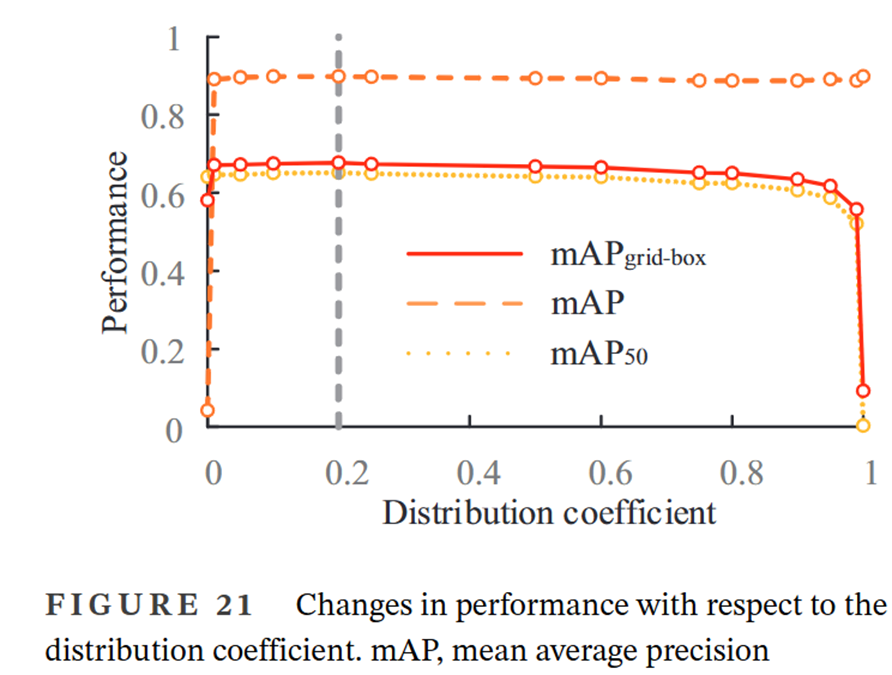
分析联合损失函数下图像分类和目标检测的分配系数,结果表明多视觉任务学习具有较强的鲁棒性,在保证精度不损失甚至略微增长的前提下有效提高裂缝识别的效率
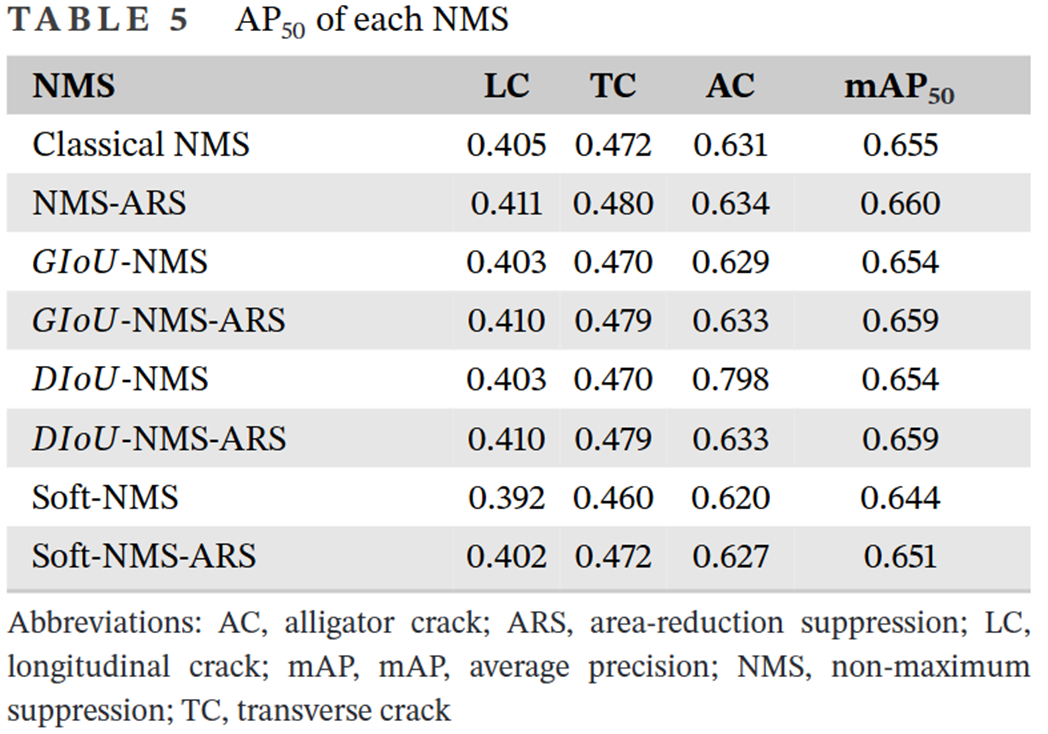
改进的NMS能够有效过滤目标检测的冗余预测框,改进模型性能,并且缓解不同非极大值抑制算法之间的差距
- 基于网格的分类网络的性能高于基于补丁的分类
- 基于网格的分类方法具有较大的感受野,可以使用带有注释裂纹的数据集来训练直接识别不同类型裂纹的分类网络
- 检测网络有效地对裂纹进行分类和定位。在裂缝中,AC最容易识别,而LC最难识别
- 多任务学习和联合训练提高了路面裂缝识别的准确性
- NMS-ARS考虑了裂缝拓扑结构,有效地过滤了冗余的预测框