1.摘要
HunyuanVideo是一个全新的开源视频基础模型,其视频生成性能堪比领先的闭源模型,甚至超越它们。我们采用了多项模型学习的关键技术,通过有效的模型架构和数据集扩展策略,我们成功训练了一个拥有超过 130 亿个参数的视频生成模型,使其成为所有开源模型中规模最大的模型。
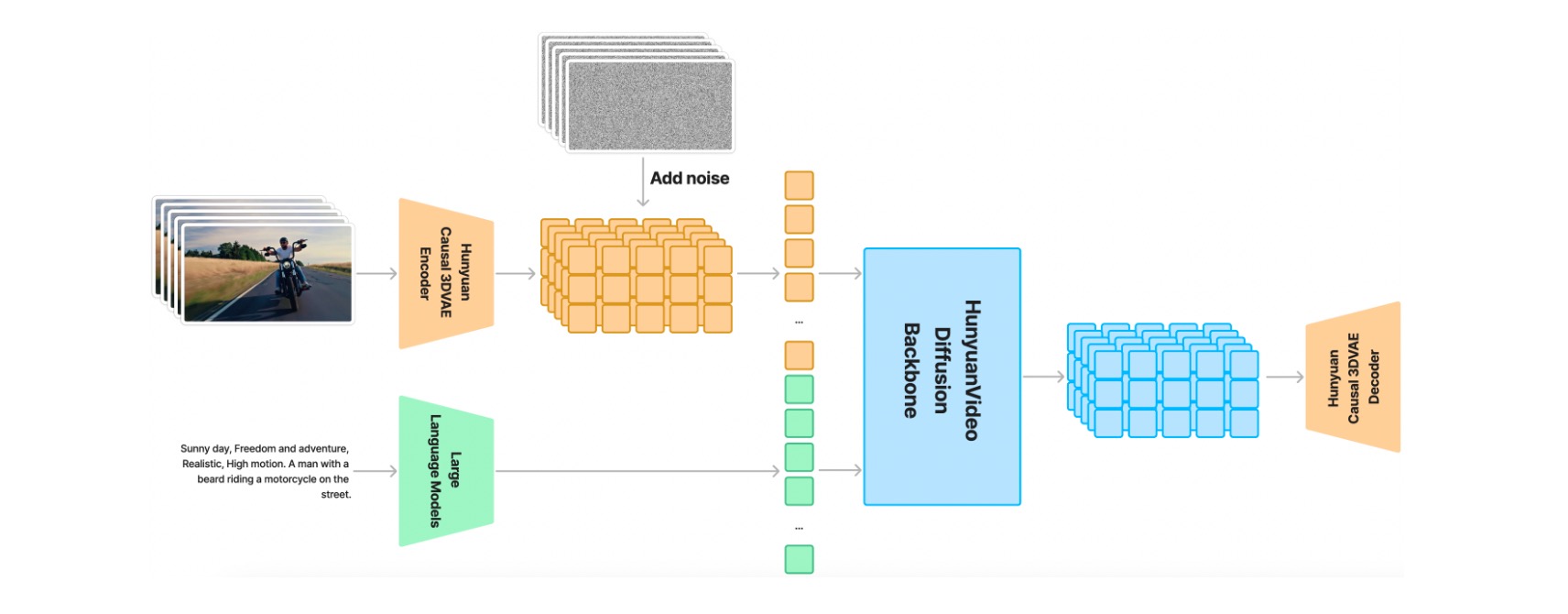
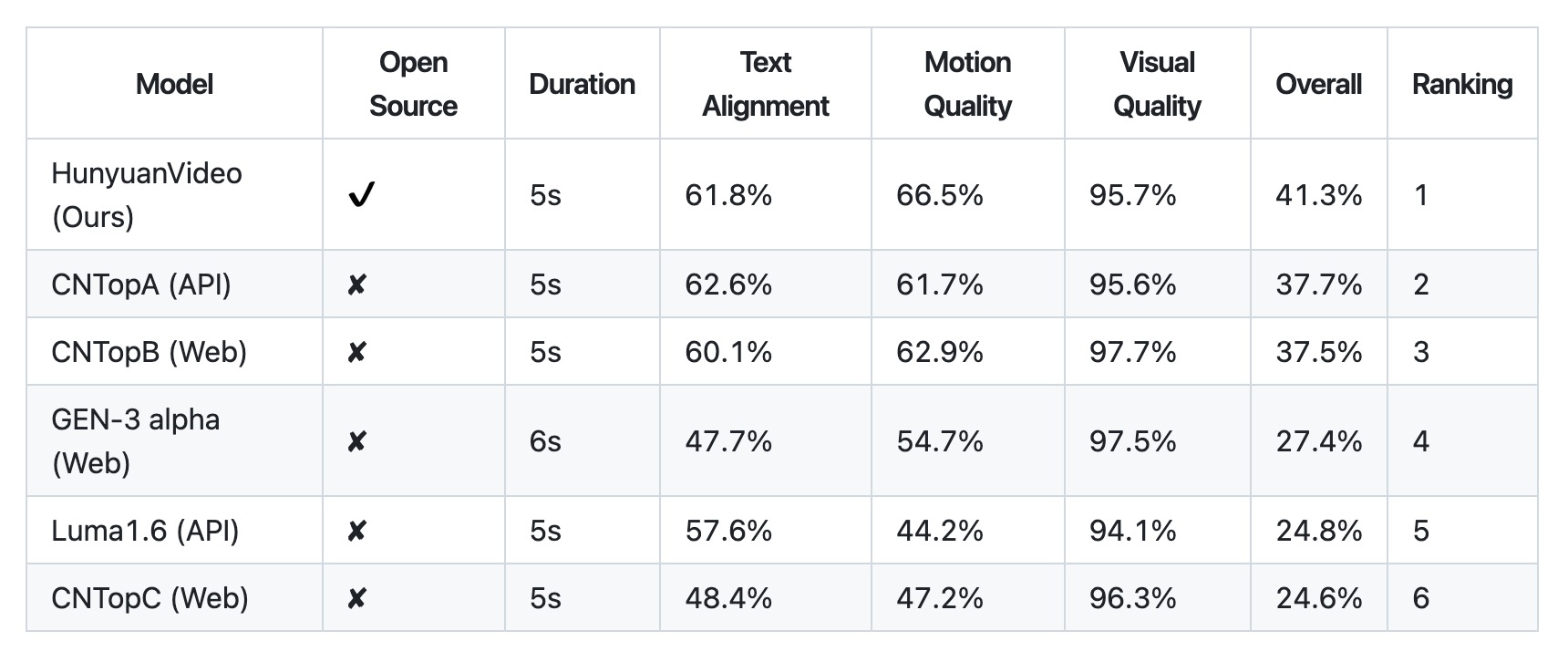
部署环境为:linux服务器,GPU大小为64G。
2. 安装
2.1 下载项目代码
git clone https://github.com/tencent/HunyuanVideo
cd HunyuanVideo
2.2 linux 环境部署
#1. Create conda environment
conda create -n HunyuanVideo python==3.10.9
2. Activate the environment
conda activate HunyuanVideo
3. Install PyTorch and other dependencies using conda
For CUDA 11.8
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidia
For CUDA 12.4
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.4 -c pytorch -c nvidia
conda install pytorch-cuda -c pytorch -c nvidia
4. Install pip dependencies
python -m pip install -r requirements.txt
5. Install flash attention v2 for acceleration (requires CUDA 11.8 or above)
python -m pip install ninja
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.6.3
6. Install xDiT for parallel inference (It is recommended to use torch 2.4.0 and flash-attn 2.6.3)
python -m pip install xfuser==0.4.0
2.3 模型下载
https://huggingface.co/tencent/HunyuanVideo/tree/refs%2Fpr%2F18
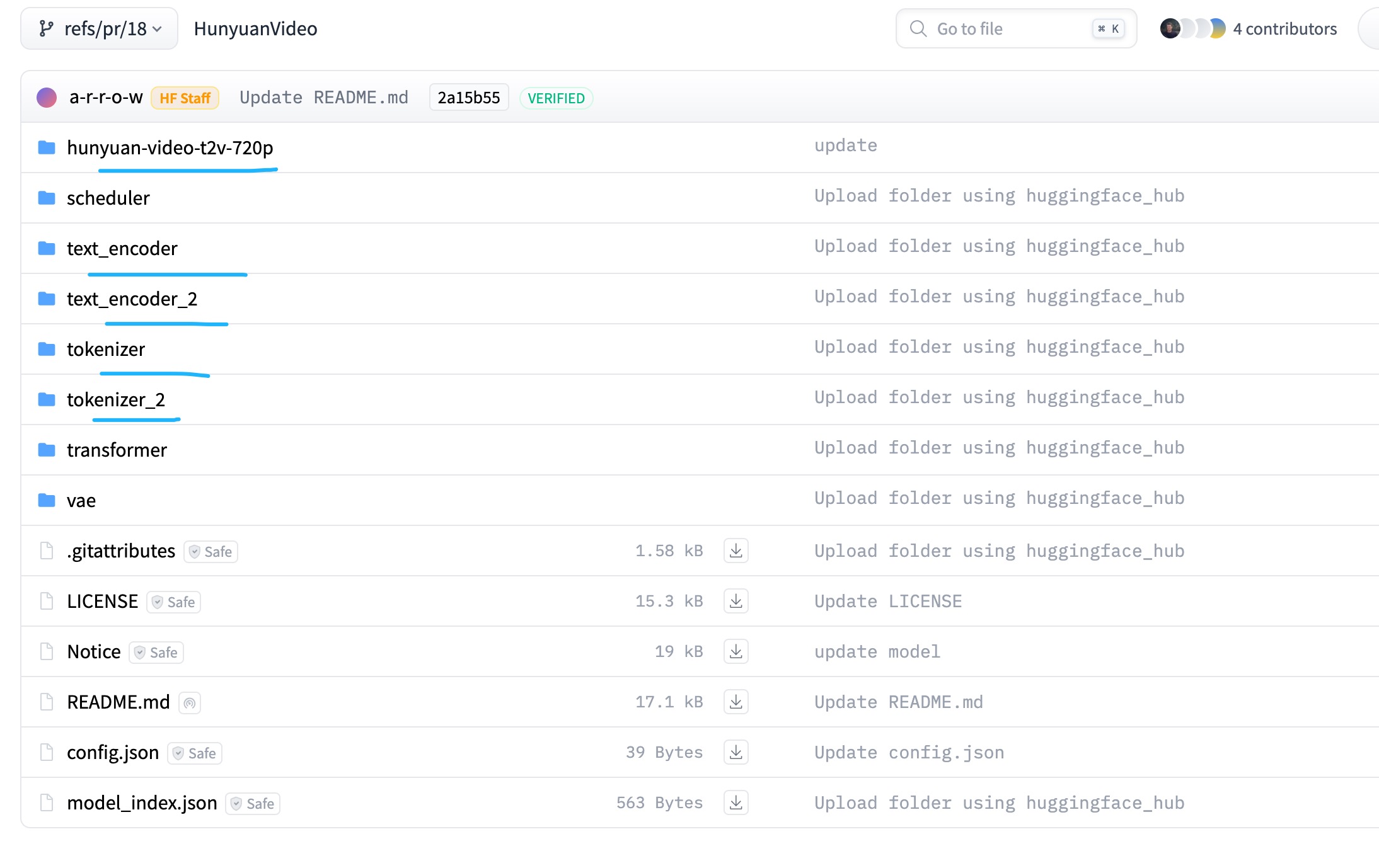
- 需要下载hunyuan-video-t2v-720p,text_encoder,text_encoder_2,tokenizer,tokenizer_2这5个。
- 下载完成以后需要把tokenizer里面的内容放到text_encoder内。需要把tokenizer_2里面的内容放到text_encoder_2内。
cp tokenizer/* text_encoder
cp tokenizer_2/* text_encoder_2
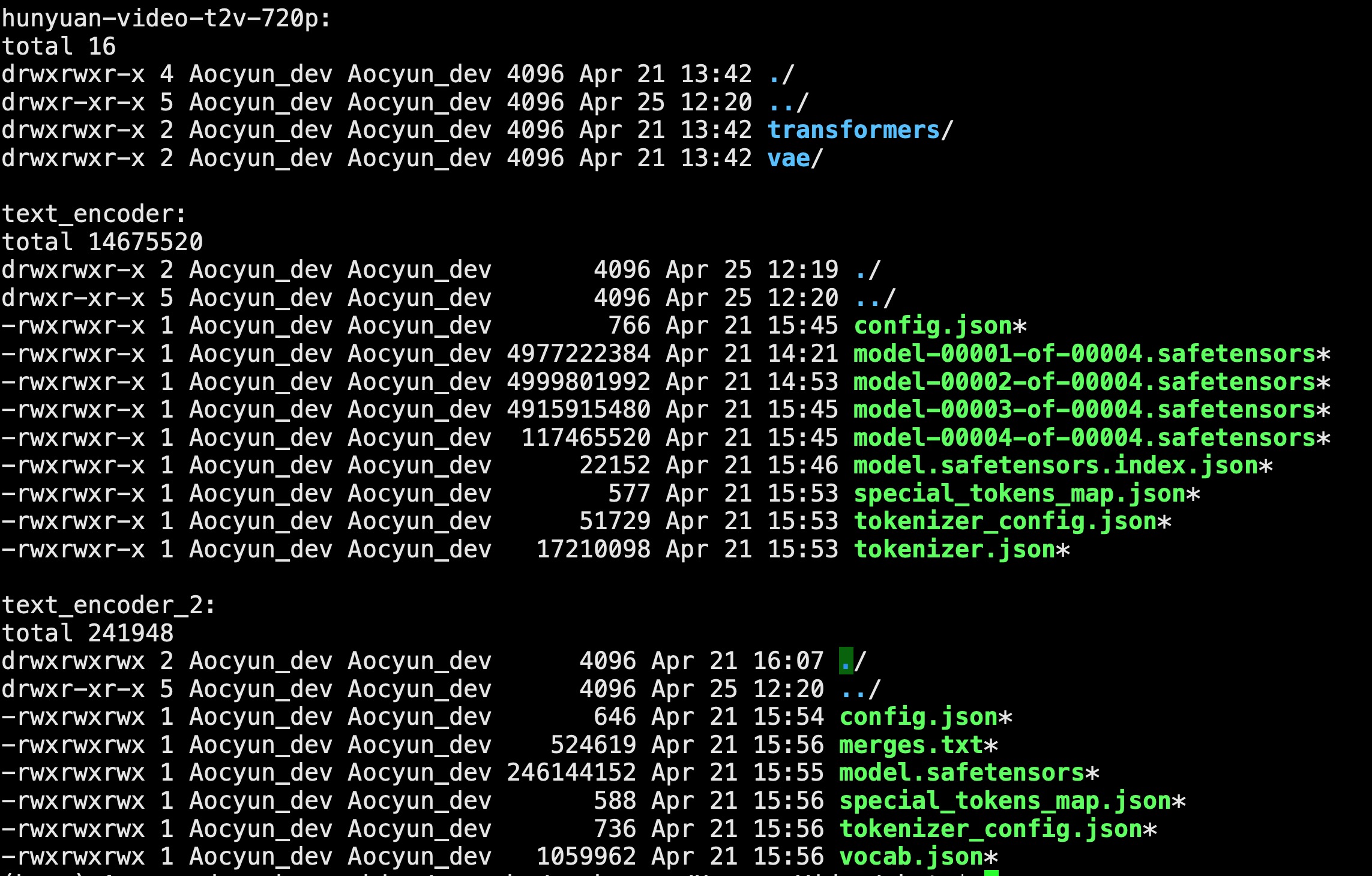
- 把hunyuan-video-t2v-720p,text_encoder,text_encoder_2放到目录HunyuanVideo/ckpts下面:
- 目录结构:

3. 生成视频
3.1 本地生成
cd HunyuanVideo
CUDA_VISIBLE_DEVICES=0 python sample_video.py \
--video-size 544 544 \
--video-length 129 \
--infer-steps 50 \
--prompt "A cat walks on the grass, realistic style." \
--flow-reverse \
--use-cpu-offload \
--save-path ./results
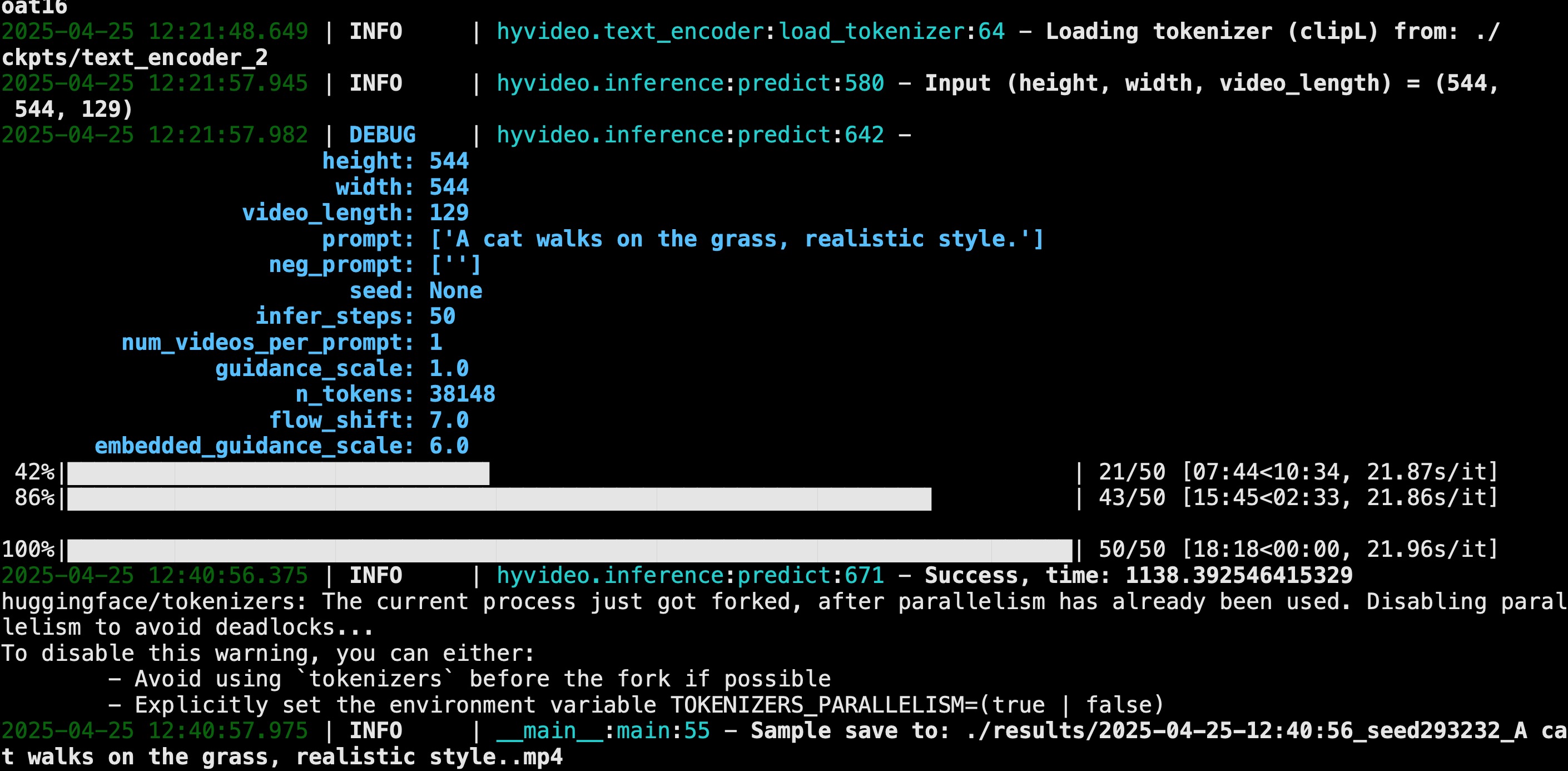
文本生成视频成功,视频时长5秒,生成用时18分钟。
生成的视频在results目录下面:

最后去掉引号:
mv '2025-04-25-12:40:56_seed293232_A cat walks on the grass, realistic style..mp4' cat.mp4
3.2 运行Gradio Server
3.2.1 启动服务
Python gradio_server.py --flow-reverse
由于本机端口占用,所以我把端口改成了8881.
运行成功:
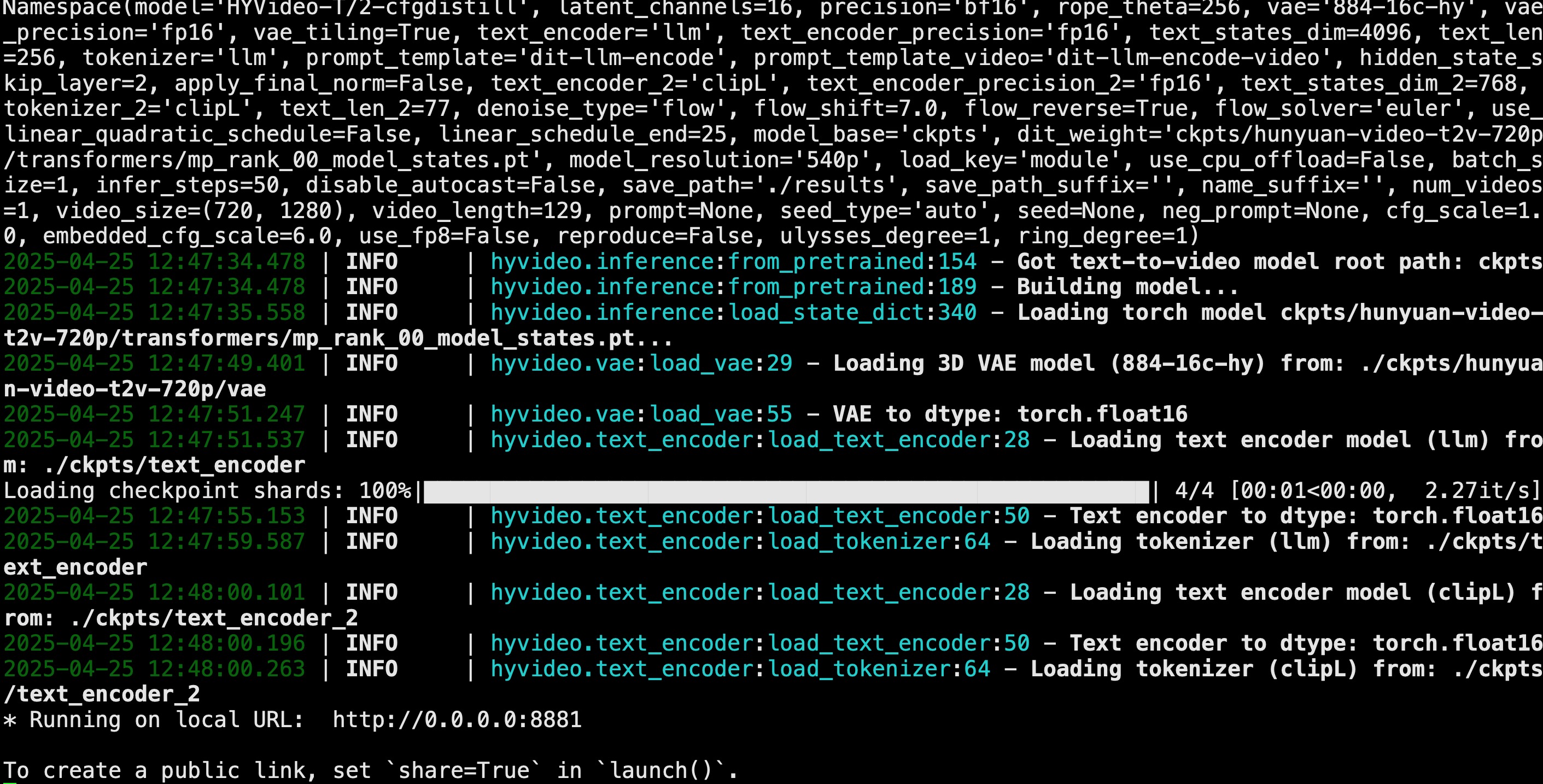
3.2.2 网页生成视频
由于GPU才64G,所以Number of Inference Steps设置为20。
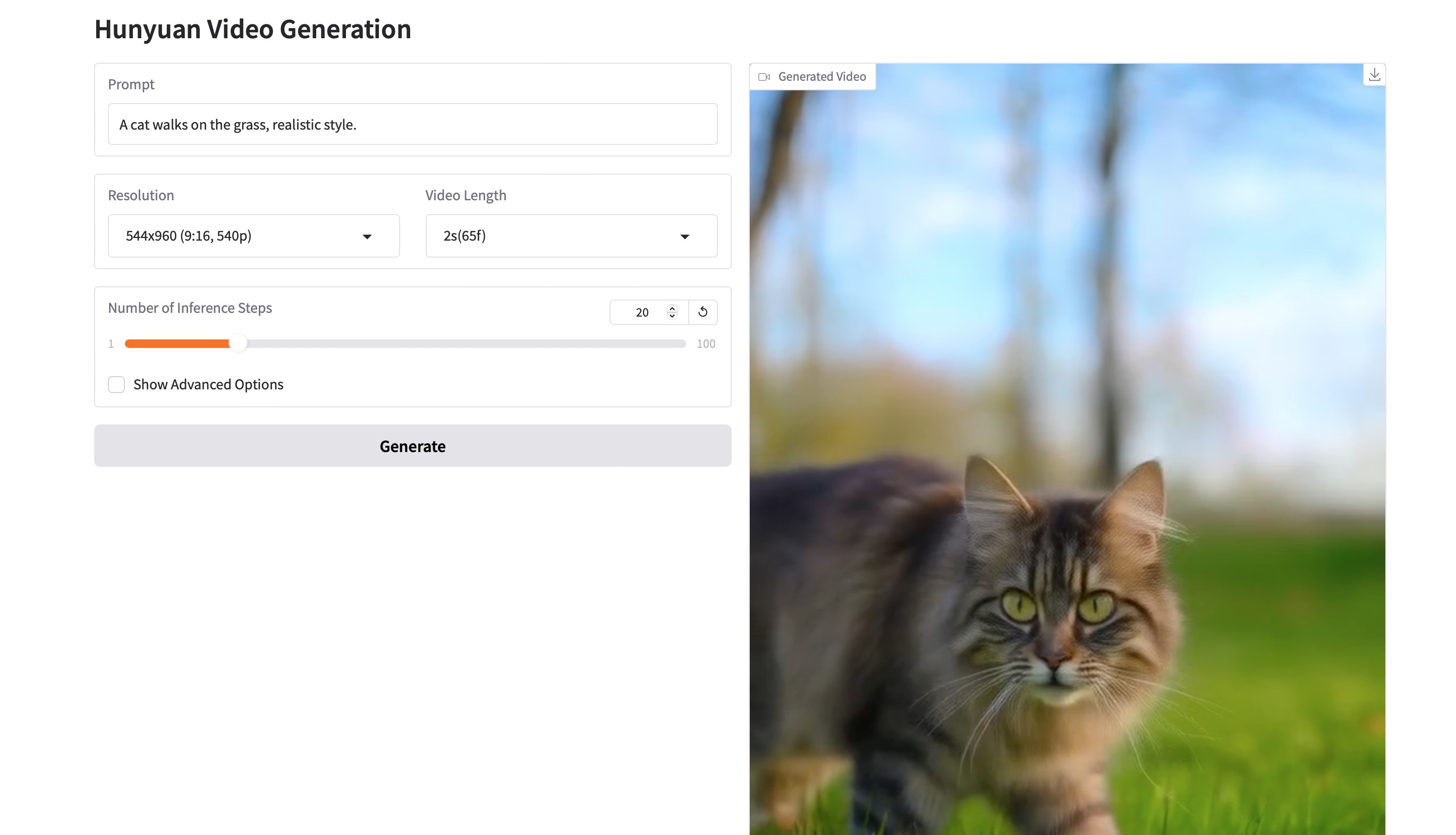
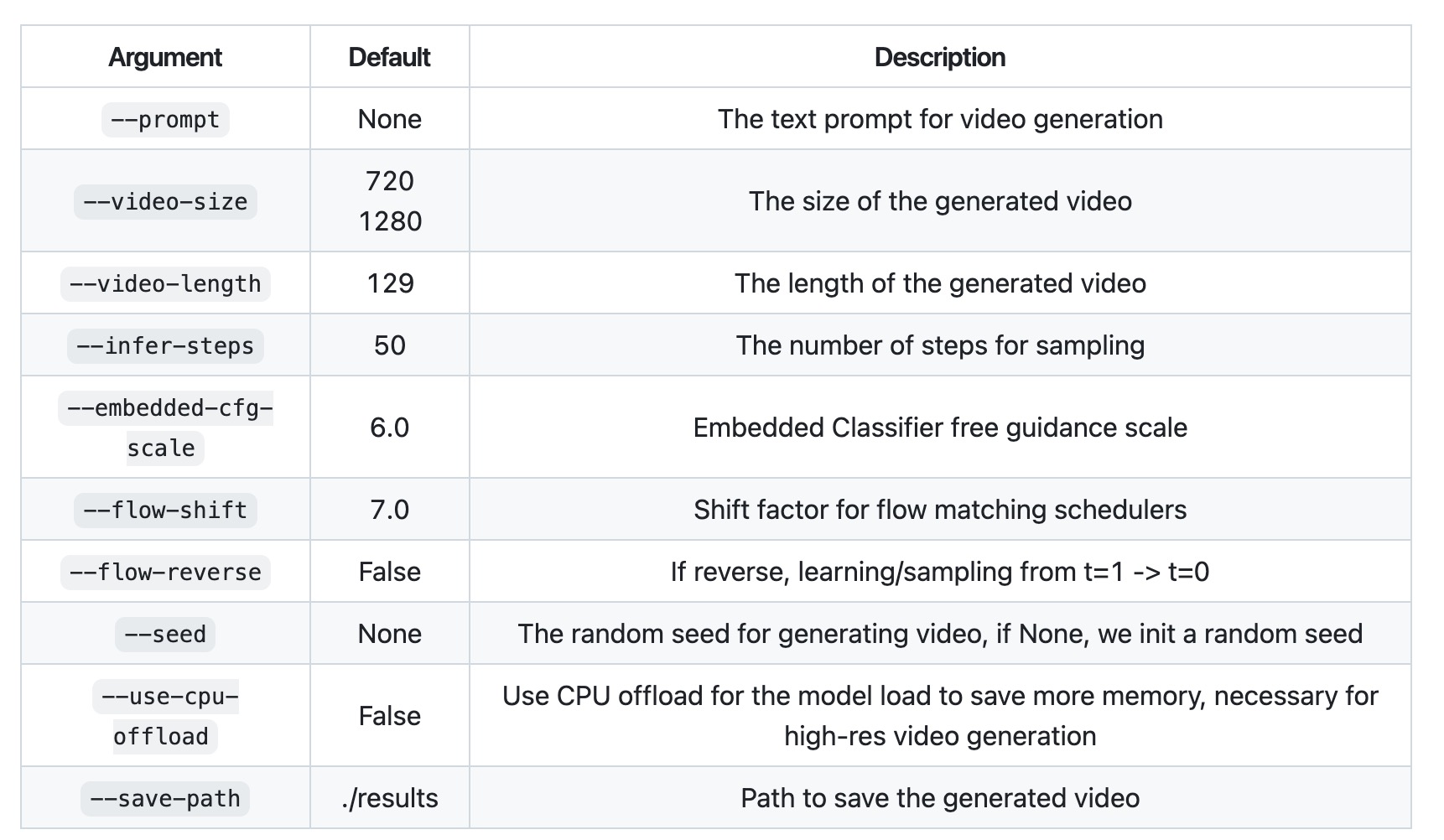
3.3 参数详解
4. 可能遇到的问题及解决方法
4.1 问题1
TypeError: argument of type 'bool' is not iterable
ValueError: When localhost is not accessible, a shareable link must be created. Please set share=True or check your proxy settings to allow access to localhost.

解决方案:
pydantic这个包版本的问题,退回2.10.6版本即可 pip install pydantic==2.10.6,完美解决。
4.2 问题2
RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
解决方案:
在gradio_server.py中增加以下代码:
import torch
torch.backends.cudnn.benchmark = True
4.3 问题3
ffmpy.ffmpy.FFExecutableNotFoundError: Executable 'ffprobe' not found
解决方案:
sudo apt-get install ffmpeg