一、概述
CatBoost 是在传统GBDT基础上改进和优化的一种算法,由俄罗斯 Yandex 公司开发,于2017 年开源,在处理类别型特征和防止过拟合方面有独特优势。
在实际数据中,存在大量的类别型特征,如性别、颜色、类别等,传统的算法通常需要在预处理中对这些特征进行独热编码(One-Hot Encoding)或标签编码(Label Encoding)。但这些方法存在一些问题,独热编码会增加数据的维度,导致模型训练时间变长;标签编码可能会引入不必要的顺序关系,影响模型的准确性。CatBoost 采用了一种独特的处理方式,称为 "Ordered Target Statistics"(有序目标统计),它通过对数据进行排序,利用数据的顺序信息来计算类别型特征的统计量,从而将特征有效地融入到模型中,避免了传统编码方式的弊端。
另外,在构建决策树时,CatBoost 采用了对称树的结构,与传统的非对称决策树相比,对称树在生长过程中,每层的节点数量相同,结构更加规整。这种结构使得模型在训练过程中更加稳定,能够减少过拟合的风险,同时也有助于提高训练速度。
二、算法原理
1.对称树结构
对称树结构在形式上是完全二叉树结构,是指在构建决策树时,对于每个节点的分裂,都考虑所有可能的特征和阈值组合,并且在树的同一层中,所有节点的分裂方式是对称的。具体可描述为
特征选择:在构建对称树时,CatBoost 会对所有可用的特征进行评估,计算每个特征对于目标变量的重要性。通过一些统计指标,如信息增益、基尼系数等,来衡量特征对数据划分的有效性,选择具有最高重要性的特征作为当前节点的分裂特征。
阈值确定:对于选定的分裂特征,CatBoost 会遍历该特征的所有可能取值,寻找一个最优的分裂阈值,使得分裂后的两个子节点能够最大程度地分离不同类别的数据,或者使目标变量在两个子节点上的分布具有最大的差异。
对称分裂:一旦确定了分裂特征和阈值,就在当前节点上按照这个特征和阈值进行分裂,将数据集分为左右两个子节点。在树的同一层中,所有节点都按照相同的特征选择和阈值确定方法进行分裂,形成对称的树结构。
2.训练过程
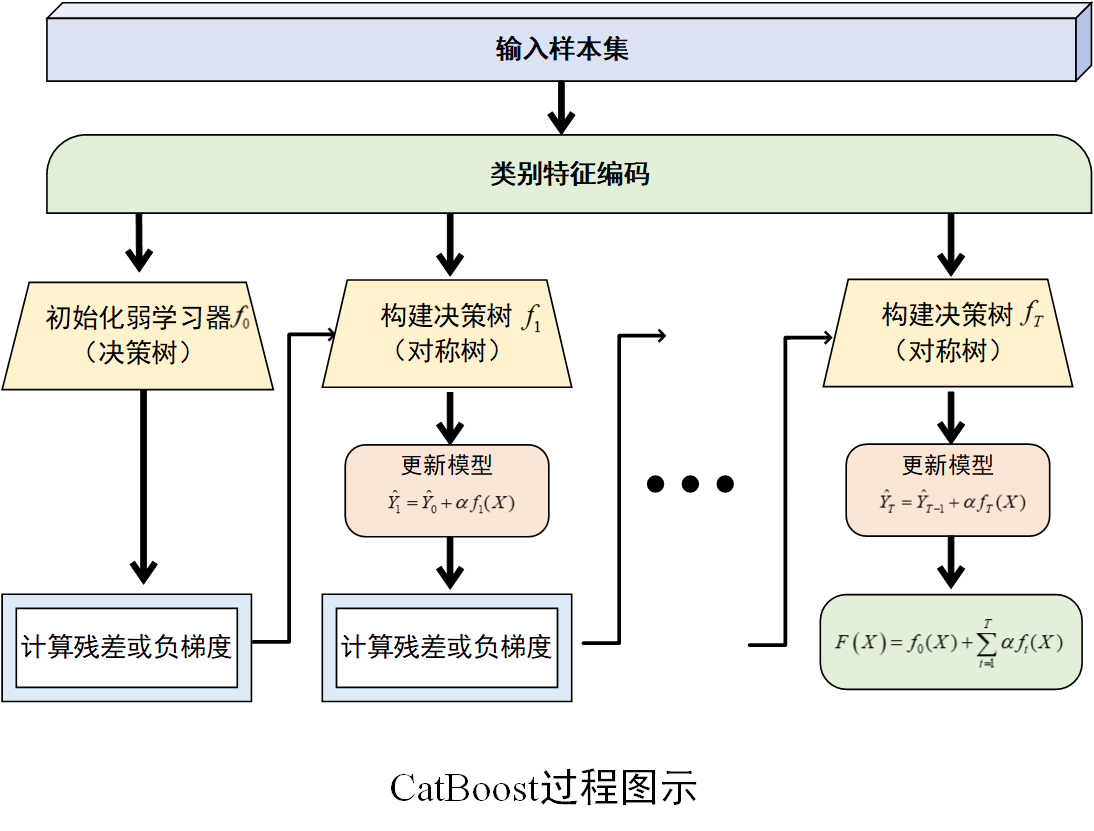
(1) 初始化弱学习器
首先,初始化一个弱学习器,通常是一个决策树(是否对称树结构均可),记为\(f_0(X)\),其预测结果为初始的预测值\(\hat y_0\)。此时,初始预测值与真实值之间存在误差。
(2) 计算残差或负梯度
在回归任务中,计算每个样本的残差,即真实值\(y_i\)与当前模型预测值\(\hat y_{i,t-1}\)的差值\(r_{i,t}=y_i-\hat y_{i,t-1}\),其中表示迭代的轮数。在分类任务中,计算损失函数关于当前模型预测值的负梯度
\g_{i,t}=-\\frac{\\vartheta L(y_i,\\hat y_{i,t-1})}{\\vartheta \\hat y_{i,t-1}} \\
(3) 构建决策树
使用计算得到的残差(回归任务)或负梯度(分类任务)作为新的目标值,使用"对称树结构" 的方式来构建一棵新的决策树\(f_t(X)\)。同时采用一些限制决策树深度、控制叶子节点数量的正则化技术。
(4) 更新模型
根据新训练的决策树,更新当前模型。更新公式为\(\hat y_{i,t}=\hat y_{i,t-1}+\alpha f_t(x_i)\),其中是学习率(也称为步长),用于控制每棵树对模型更新的贡献程度。学习率较小可以使模型训练更加稳定,但需要更多的迭代次数;学习率较大则可能导致模型收敛过快,甚至无法收敛。
(5) 重复迭代
重复步骤 (2)--(4)步,不断训练新的决策树并更新模型,直到达到预设的迭代次数、损失函数收敛到一定程度或满足其他停止条件为止。最终,CatBoost模型由多棵决策树组成,其预测结果是所有决策树预测结果的累加。
过程示意图
三、应用场景
1. 结构化数据预测
在金融领域,CatBoost 可以用于信用评估、风险预测等任务。通过分析客户的各种属性(如年龄、收入、信用记录等分类和数值特征),预测客户的信用等级和违约风险,帮助金融机构做出更准确的决策。在电商领域,它可以用于商品推荐、销售预测等。根据用户的购买历史、浏览行为等特征,预测用户对不同商品的兴趣,为用户提供个性化的推荐服务,同时也可以帮助商家预测商品的销量,合理安排库存。
2.时间序列分析
CatBoost 在时间序列预测方面也有一定的应用。它可以处理具有复杂模式和趋势的时间序列数据,如股票价格预测、能源消耗预测等。通过提取时间序列中的各种特征(如趋势、季节性、周期性等),结合其他相关的影响因素,构建预测模型,为决策提供支持。
3.图像和文本数据的辅助分析
虽然 CatBoost 主要适用于结构化数据,但在一些情况下,它也可以与其他深度学习算法结合,用于图像和文本数据的辅助分析。例如,在图像分类任务中,可以先使用深度学习模型提取图像的特征,然后将这些特征与其他相关的结构化数据(如拍摄时间、地点等)一起输入到 CatBoost 模型中,进行进一步的分类和预测。
四、Python实现
(环境:Python 3.11,scikit-learn 1.6.1)
分类情形
python
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
import catboost as cb
from sklearn import metrics
# 生成数据集
X, y = make_classification(n_samples = 1000, n_features = 6, random_state = 42)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
# 创建CatBoost分类模型
model = cb.CatBoostClassifier()
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pre = model.predict(X_test)
# 性能评价
accuracy = metrics.accuracy_score(y_test,y_pre)
print('预测结果为:',y_pre)
print('准确率为:',accuracy)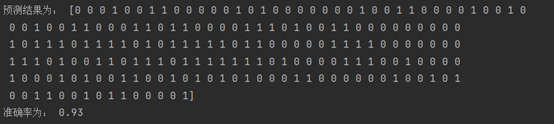
回归情形
python
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
import catboost as cb
from sklearn.metrics import mean_squared_error
# 生成数据集
X, y = make_regression(n_samples = 1000, n_features = 6, random_state = 42)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
# 创建CatBoost回归模型
model = cb.CatBoostRegressor()
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 计算均方误差评估模型性能
mse = mean_squared_error(y_test, y_pred)
print(f"均方误差: {mse}")
五、小结
CatBoost 算法凭借其独特的算法原理和核心特点,在机器学习领域中占据了一席之地。它在处理类别型特征、防止过拟合、训练速度和易用性等方面都表现出色,适用于多种应用场景。无论是在结构化数据预测、时间序列分析还是与其他类型数据的结合应用中,CatBoost 都展现出了强大的能力。随着数据科学的发展,CatBoost 可逐渐在更多领域得到应用,为解决实际问题提供更多有效的帮助。
End.