Joint Deep Modeling of Users and Items Using Reviews for Recommendation
题目翻译:利用评论对用户和项目进行联合深度建模进行推荐
原文地址:点这里
关键词: DeepCoNN、推荐系统、卷积神经网络、评论建模、协同建模、评分预测、联合建模
摘要
用户撰写的大量评论 包含着丰富的信息,而目前的大多数推荐系统忽视了这部分资源。本文提出了一个深度模型,名为 DeepCoNN ,用于从评论中同时学习商品属性和用户行为 。该模型由两个并行神经网络组成,分别利用用户撰写的评论和商品收到的评论进行建模,最终在顶部的共享层将二者耦合。这个共享层允许用户和商品的隐变量交互,类似因子分解模型的方式。实验表明,DeepCoNN 在多个数据集上显著优于所有的基线模型
一、前言
在过去十年里,商品和服务的种类和数量显著增加,虽然这为用户提供了更多选择,但也使他们更难做出决策。推荐系统应运而生,它们通过分析用户的偏好、需求和历史行为,向用户推荐可能感兴趣的商品,如网购、阅读文章、观看电影等场景中广泛使用。
当前主流的推荐系统方法主要基于 协同过滤(Collaborative Filtering, CF) ,尤其是基于 矩阵分解(Matrix Factorization) 的方法,它通过发现用户和商品之间的潜在因子(如电影的类型、演员等)来预测评分。这些方法虽然在多个应用中取得了成功,但也存在一个关键问题------稀疏性问题:用户评分(显式)过少,导致模型难以准确建模。
为了解决评分数据不足的问题,有研究尝试引入用户评论信息。用户在撰写评论时会表达对商品的看法,这些评论中包含了对评分背后的解释和情感信息,是评分矩阵之外的重要信息源。然而,大多数现有方法仍然忽视了这部分内容,仅基于评分建模用户和商品。
为此,本文提出了一个新的基于深度神经网络的模型,名为 DeepCoNN(Deep Cooperative Neural Networks) ,该模型从评论文本中联合建模用户行为和商品属性,从而提高评分预测的准确性。其核心思想如下:
- 使用两个并行神经网络分别对用户和商品进行建模;
- 每个网络的输入是该用户或该商品的所有评论;
- 顶部引入一个共享层,让用户和商品的潜在特征能够交互,类似于矩阵分解方法;
- 采用预训练词向量(如Word2Vec) 表示评论,提升语义建模效果。
论文的实验表明,DeepCoNN 在多个真实世界的数据集上(如 Yelp、Amazon、Beer)表现出显著优于现有方法的准确性,特别是在应对用户和商品评分稀缺的情况下,更能有效缓解稀疏性问题。
二、方法
表一:符号总结
| 符号 | 定义与描述 |
|---|---|
| d u 1 : n d_u^{1:n} du1:n | 用户或物品 u u u 的评论文本,由 n n n 个单词组成 |
| V u 1 : n V_u^{1:n} Vu1:n | 用户或物品 u u u 的词向量矩阵 |
| w u i w_{ui} wui | 用户 u u u 对物品 i i i 所写的评论文本 |
| o j o_j oj | 第 j j j 个卷积层神经元的输出 |
| n i n_i ni | 第 i i i 层神经元的数量 |
| K j K_j Kj | 第 j j j 个卷积核(Kernel) |
| b j b_j bj | 第 j j j 个卷积核的偏置项 |
| g g g | 全连接层的偏置项 |
| z j z_j zj | 第 j j j 个卷积特征图(Feature Map) |
| W W W | 全连接层的权重矩阵 |
| t t t | 卷积核的窗口大小(即卷积覆盖的词数) |
| c c c | 词向量的维度(例如 Word2Vec 常为 300) |
| x u x_u xu | 用户网络 Net u _u u 的输出向量 |
| y i y_i yi | 物品网络 Net i _i i 的输出向量 |
| λ \lambda λ | 学习 |
图1
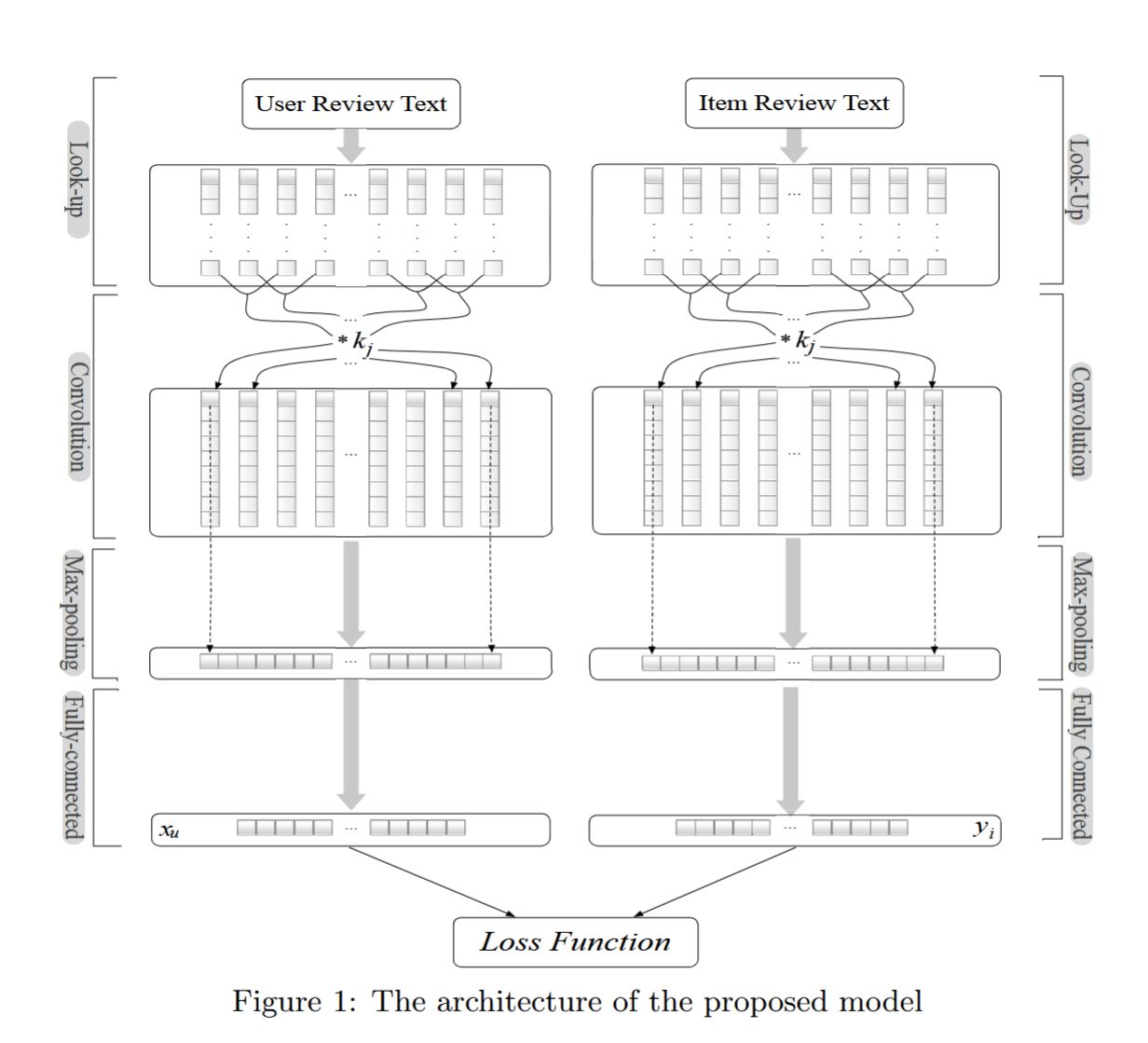
2.2 模型架构
评分预测任务中所提出模型的结构如图1所示。该模型由两个并行的神经网络 构成,在最后一层进行耦合:一个网络用于用户建模(记作 Net u _u u),另一个用于商品建模(记作 Net i _i i)。用户撰写的评论和商品收到的评论分别作为输入传递给 Net u _u u 和 Net i _i i,最终输出预测评分。
模型的第一层被称为 查找层(look-up layer) ,它将评论文本转化为词嵌入矩阵(word embedding matrices),以提取评论中的语义信息。接下来的几层则是 CNN 中常用的结构,用于提取用户和商品的多层次特征,包括:
- 卷积层(convolution layer)、
- 最大池化层(max pooling layer)、
- 全连接层(fully connected layer)。
在两个网络的顶端,模型引入了一个 共享层(top shared layer) ,用于让用户和商品的隐向量进行交互。该层通过 Net u _u u 和 Net i _i i 输出的隐变量计算预测评分误差,即优化目标函数。
2.3 词嵌入表示
词嵌入是一种将单词映射为向量 的参数化函数,记作 f : M → R n f : M \rightarrow \mathbb{R}^n f:M→Rn,其中 M M M 表示词汇表,函数 f f f 将每个单词映射为一个 n n n 维的分布式向量。近年来,这种表示方式在许多自然语言处理(NLP)任务中显著提升了性能【参考文献12, 7】。
在 DeepCoNN 模型中,采用这种表示技术来挖掘评论文本中的语义信息。在模型的第一层,即查找层(look-up layer),评论被表示为一个词嵌入矩阵,以提取其中的语义特征。
具体做法是:将用户 u u u 撰写的所有评论合并为一个整体文档,记作 d u 1 : n d_u^{1:n} du1:n,该文档由总共 n n n 个单词组成。随后,为用户 u u u 构建其对应的词向量矩阵 V u 1 : n V_u^{1:n} Vu1:n,公式如下:
V u 1 : n = ϕ ( d u 1 ) ⊕ ϕ ( d u 2 ) ⊕ ϕ ( d u 3 ) ⊕ ⋯ ⊕ ϕ ( d u n ) V_u^{1:n} = \phi(d_u^1) \oplus \phi(d_u^2) \oplus \phi(d_u^3) \oplus \cdots \oplus \phi(d_u^n) Vu1:n=ϕ(du1)⊕ϕ(du2)⊕ϕ(du3)⊕⋯⊕ϕ(dun)
其中, d u k d_u^k duk 表示文档 d u 1 : n d_u^{1:n} du1:n 中的第 k k k 个单词,查找函数 ϕ ( d u k ) \phi(d_u^k) ϕ(duk) 返回该单词对应的 c c c 维词向量,符号 ⊕ \oplus ⊕ 表示向量拼接操作。
需要特别指出的是,这种表示方法保留了词语的顺序信息,这是它相较于传统的"词袋模型(bag-of-words)"方法的一大优势。
2.4 卷积神经网络层
接下来的几层包括 卷积层(convolution layer) 、最大池化层(max pooling) 和 全连接层(fully connected layer),这些结构遵循文献 7 中提出的 CNN 模型设计。
- 卷积层 由 m m m 个神经元组成,每个神经元通过在用户 u u u 的词向量矩阵 V u 1 : n V_u^{1:n} Vu1:n 上应用卷积操作来提取新的特征。
- 每个卷积神经元 j j j 使用一个大小为 c × t c \times t c×t 的卷积核 K j K_j Kj,在长度为 t t t 的词窗口上滑动进行计算。
- 卷积操作的结果如下式所示:
z j = f ( V u 1 : n ∗ K j + b j ) (2) z_j = f(V_u^{1:n} * K_j + b_j) \tag{2} zj=f(Vu1:n∗Kj+bj)(2)
其中:
- ∗ * ∗ 表示卷积操作符;
- b j b_j bj 是该卷积核的偏置项;
- f f f 是激活函数。
在本模型中,我们使用 ReLU(修正线性单元) 作为激活函数,其定义如下:
f ( x ) = max { 0 , x } (3) f(x) = \max\{0, x\} \tag{3} f(x)=max{0,x}(3)
使用 ReLU 的深度卷积神经网络相比使用 tanh 单元的网络训练速度更快【参考文献14】。
- 接下来,按照文献 7 的方法,我们在每个卷积特征图上执行 最大池化操作(max pooling),并取最大值作为该卷积核提取的代表性特征:
o j = max { z 1 , z 2 , ... , z n − t + 1 } (4) o_j = \max\{z_1, z_2, \dots, z_{n-t+1}\} \tag{4} oj=max{z1,z2,...,zn−t+1}(4)
此方法可以自然地应对评论文本长度不一的问题。最大池化之后,卷积结果被压缩成一个固定大小的向量。
- 上述过程描述了一个卷积核提取一个特征的流程。实际模型中使用多个卷积核来提取不同的特征,其卷积层输出向量为:
O = { o 1 , o 2 , o 3 , ... , o n 1 } (5) O = \{o_1, o_2, o_3, \dots, o_{n_1}\} \tag{5} O={o1,o2,o3,...,on1}(5)
其中, n 1 n_1 n1 表示卷积层中卷积核的数量。
- 然后,将最大池化层的输出 O O O 输入到一个全连接层,使用权重矩阵 W W W 和偏置 g g g 进行线性变换并激活,得到用户 u u u 的特征向量 x u x_u xu:
x u = f ( W × O + g ) (6) x_u = f(W \times O + g) \tag{6} xu=f(W×O+g)(6)
最终,我们可以分别获得用户端 CNN 的输出 x u x_u xu 和物品端 CNN 的输出 y i y_i yi,作为后续评分预测的输入。
2.5 共享层
尽管用户和物品的输出向量 x u x_u xu 和 y i y_i yi 可以被视为各自的特征表示,但它们可能处于不同的特征空间 ,因此彼此之间不可直接比较或交互。
为了解决这个问题,本文在两个神经网络的顶部引入了一个共享层(shared layer) ,用于将 Net u _u u 和 Net i _i i 的输出耦合在一起。
具体做法是,将用户和物品的向量拼接成一个新的向量:
z ^ = ( x u , y i ) \hat{z} = (x_u, y_i) z^=(xu,yi)
为了建模该拼接向量 z ^ \hat{z} z^ 中所有特征之间的高阶交互关系 ,我们引入了 因子分解机(Factorization Machine, FM)【参考文献24】作为评分预测的估计器。
因此,给定一个包含 N N N 个训练样本的批次 T T T,我们定义其损失函数(代价函数)如下:
J = w ^ 0 + ∑ i = 1 ∣ z ^ ∣ w ^ i z ^ i + ∑ i = 1 ∣ z ^ ∣ ∑ j = i + 1 ∣ z ^ ∣ ⟨ v ^ i , v ^ j ⟩ z ^ i z ^ j (7) J = \hat{w}0 + \sum{i=1}^{|\hat{z}|} \hat{w}i \hat{z}i + \sum{i=1}^{|\hat{z}|} \sum{j=i+1}^{|\hat{z}|} \langle \hat{v}_i, \hat{v}_j \rangle \hat{z}_i \hat{z}_j \tag{7} J=w^0+i=1∑∣z^∣w^iz^i+i=1∑∣z^∣j=i+1∑∣z^∣⟨v^i,v^j⟩z^iz^j(7)
其中:
- w ^ 0 \hat{w}_0 w^0 是全局偏置项;
- w ^ i \hat{w}_i w^i 表示 z ^ \hat{z} z^ 中第 i i i 个变量的权重;
- ⟨ v ^ i , v ^ j ⟩ \langle \hat{v}_i, \hat{v}_j \rangle ⟨v^i,v^j⟩ 表示变量 i i i 和 j j j 的二阶交互项,定义为向量内积:
⟨ v ^ i , v ^ j ⟩ = ∑ f = 1 ∣ z ^ ∣ v ^ i , f ⋅ v ^ j , f \langle \hat{v}i, \hat{v}j \rangle = \sum{f=1}^{|\hat{z}|} \hat{v}{i,f} \cdot \hat{v}_{j,f} ⟨v^i,v^j⟩=f=1∑∣z^∣v^i,f⋅v^j,f
x和y处于不同的特征空间,不能直接比较,采用耦合
2.6 网络训练(Network Training)
我们的模型通过最小化公式(7)所表示的损失函数 J J J 来进行训练。对该函数关于 z ^ i \hat{z}_i z^i 求导后,得到如下导数表达式(公式8):
∂ J ∂ z ^ i = w ^ i + ∑ j = i + 1 ∣ z ^ ∣ ⟨ v ^ i , v ^ j ⟩ z ^ j (8) \frac{\partial J}{\partial \hat{z}_i} = \hat{w}i + \sum{j=i+1}^{|\hat{z}|} \langle \hat{v}_i, \hat{v}_j \rangle \hat{z}_j \tag{8} ∂z^i∂J=w^i+j=i+1∑∣z^∣⟨v^i,v^j⟩z^j(8)
对于网络中其他层的参数,其梯度可以通过链式法则(chain rule)进一步求得。
给定一个包含 N N N 个样本元组的训练集 T T T,我们采用 RMSprop 优化器【参考文献30】在随机打乱后的小批量(mini-batches)上进行模型优化。
RMSprop 是一种自适应版本的梯度下降算法,它根据梯度的绝对值动态调整学习率。其做法是:用当前梯度的平方值对历史梯度进行加权平均,从而缩放每个权重参数的更新量。
其参数 θ \theta θ 的更新规则如下:
r t ← 0.9 ( ∂ J ∂ θ ) 2 + 0.1 ⋅ r t − 1 (9) r_t \leftarrow 0.9 \left( \frac{\partial J}{\partial \theta} \right)^2 + 0.1 \cdot r_{t-1} \tag{9} rt←0.9(∂θ∂J)2+0.1⋅rt−1(9)
θ ← θ − ( λ r t + ε ) ⋅ ∂ J ∂ θ (10) \theta \leftarrow \theta - \left( \frac{\lambda}{\sqrt{r_t} + \varepsilon} \right) \cdot \frac{\partial J}{\partial \theta} \tag{10} θ←θ−(rt +ελ)⋅∂θ∂J(10)
其中:
- λ \lambda λ 是学习率;
- ε \varepsilon ε 是为避免数值不稳定性而加入的一个很小的常数。
此外,为了防止过拟合,在两个神经网络的全连接层中还使用了 dropout 策略【参考文献28】。
思考
1. DeepCoNN模型解决一个什么问题
显示评分数据少且评论信息为利用
2. DeepCoNN模型怎么解决这个问题
-
联合建模评论文本
- 对每个用户与每个物品分别汇总其所有评论,输入到两条并行的卷积神经网络(Netₙᵤ 和 Netᵢₜₑₘ),自动抽取深层语义特征。
-
词嵌入 + CNN 提取特征
- 使用预训练的词向量保留评论的语义与词序;
- 通过卷积层 + 最大池化获得固定维度的特征向量,捕捉局部 n-gram 信息。
-
共享交互层
- 将用户向量 x u x_u xu 与物品向量 y i y_i yi 拼接,输入因子分解机(FM),同时建模一阶偏置项和二阶交互项,输出评分预测。
3. DeepCoNN模型在当时创新点是什么
- 首个深度联合模型:将用户和物品的评论文本放入两条并行 CNN,同时学习并耦合二者的隐向量,用于评分预测;
- 语义与词序保留:通过预训练词嵌入和卷积操作,克服了 Bag‑of‑Words/主题模型忽视词序与词语语义多样性的局限;
- 与经典矩阵分解融合 :在顶层采用因子分解机(FM)建模高阶交互,将深度特征与协同过滤思想有机结合;
和二阶交互项,输出评分预测。
3. DeepCoNN模型在当时创新点是什么
- 首个深度联合模型:将用户和物品的评论文本放入两条并行 CNN,同时学习并耦合二者的隐向量,用于评分预测;
- 语义与词序保留:通过预训练词嵌入和卷积操作,克服了 Bag‑of‑Words/主题模型忽视词序与词语语义多样性的局限;
- 与经典矩阵分解融合:在顶层采用因子分解机(FM)建模高阶交互,将深度特征与协同过滤思想有机结合;
- 缓解稀疏与冷启动:实验证明,在用户或物品评分极少(甚至仅一条评论)时,DeepCoNN 仍能显著降低预测误差。