LangChain是什么?
在实际企业开发中,大模型应用往往比简单的问答要复杂得多。如果只是简单地向大模型提问并获取回答,那么大模型的许多强大功能都没有被充分利用。
要开始使用LangChain,首先需要安装相关的库:
python
pip install langchain
pip install langchain-openai
pip install langchain-community
pip install langgraph,grandalf与大模型的集成
LangChain支持各种大模型,包括OpenAI的模型、智谱的GLM等,只需更改几个参数即可切换不同的模型:
python
llm = ChatOpenAI(
model="glm-4-plus",
temperature=1.0,
openai_api_key="your_api_key",
openai_api_base="your_api_base_url"
)LangChain的核心概念
提示词模板
在LangChain中,提示词通常通过模板定义,支持参数化,方便动态生成提示词。两个方式的目的都是创建一个提示词模板,可以根据个人喜好选择其中一种使用。
提示词模板有两种创建方式:
1. from_template方式
使用对象方式定义模板。
from_messages方式(更常用)
json方式定义模板:
python
prompt = ChatPromptTemplate.from_messages([
("system", "请把下面的语句翻译成{language}"),
("user", "{user_text}")
])LangChain Expression Language (LCEL)
LCEL允许开发者以声明式的方式链接各个组件,使用竖线"|"操作符来连接不同的组件,创建复杂的处理流程,比如某节点循环、重复等。
串行/并行
-
串行执行:节点按顺序依次执行,前一个节点的输出作为后一个节点的输入。这是最常见的模式,如我们之前示例中的链式结构。
-
并行执行:多个节点同时接收相同的输入,各自处理后再汇总结果。这对于需要从不同角度分析同一数据的场景特别有用。
python
# 串行执行示例
serial_chain = node1 | node2 | node3
# 并行执行示例
parallel_chain = (node1 & node2 & node3) | combine_results链可能会越来越复杂,以下可以可视化链
python
# 可视化链结构
chain.get_graph().print_ascii()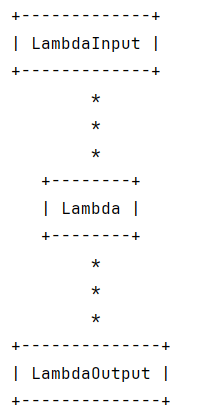
使用串行链案例
python
# 定义大模型
llm = ChatOpenAI(
model="glm-4-plus",
temperature=1.0,
openai_api_key="your_api_key",
openai_api_base="your_api_base_url"
)
# 创建提示词模板
prompt = ChatPromptTemplate.from_messages([
("system", "请把下面的语句翻译成{language}"),
("history", MessagePlaceholder(variable_name="history")),
("user", "{user_text}")
])
# 创建链
chain = prompt | llm | StrOutputParser()
# 调用链并传参
result = chain.invoke({
"language": "日文",
"user_text": "今天天气怎么样?"
})
print(result)RunablePassthrough:灵活的数据处理器
RunablePassthrough是LCEL中处理数据转换的核心工具,它允许我们以字典方式处理链。
使用RunablePassthrough有一个重要前提:它只能处理字典类型的数据。这也符合LangChain中大多数组件的设计理念,使用字典作为标准数据传递格式。
下面是一个简单的示例,展示如何使用RunablePassthrough创建和转换数据:
python
# 创建一个将输入转换为字典的简单节点
r1 = lambda x: {"k1": x}
# 使用RunablePassthrough添加新的键值对
chain = r1 | RunablePassthrough.assign(
k2=lambda inputs: inputs["k1"] * 2,
k3=lambda inputs: inputs["k1"] + 10
)
# 运行链
result = chain.invoke(5)
# 输出: {'k1': 5, 'k2': 10, 'k3': 15}错误处理与后备机制
在生产环境中,错误处理是不可避免的挑战。LCEL提供了优雅的错误处理机制,确保应用的稳定性和可靠性。
错误处理机制在以下场景中特别有价值:
- 外部API集成:当调用第三方服务时,提供平滑的错误处理
- 网络操作:处理网络连接问题和服务中断
- 分布式系统:增强系统在部分组件失败时的弹性
- 用户体验优化:即使在发生错误的情况下,也能确保用户获得有用的反馈
后备选项:优雅处理错误
with_fallbacks方法允许我们为节点指定后备选项,当主要节点报错时启用:
python
from langchain.schema.runnable import RunnableLambda
# 定义一个可能失败的主要节点
def primary_processor(x):
if isinstance(x, int):
return x + 10
else:
raise ValueError("Input must be an integer")
# 定义后备节点
def backup_processor(x):
try:
return int(x) + 20 # 尝试将输入转换为整数后加20
except:
return "Unable to process input"
# 创建带后备的链
resilient_chain = (
RunnableLambda(primary_processor)
.with_fallbacks([RunnableLambda(backup_processor)])
)
# 测试
result_normal = resilient_chain.invoke(5)
print(result_normal) # 正常情况,返回15
result_fallback = resilient_chain.invoke("2")
print(result_fallback) # 主处理器失败,使用后备,返回22在这个例子中,主处理器只接受整数输入。当收到字符串输入时,它会失败并触发后备处理器,后者会尝试将输入转换为整数并加上20。
多级后备链
我们可以设置多个后备选项,系统会按顺序尝试,直到找到一个可成功执行的选项:
python
multi_fallback_chain = primary_node.with_fallbacks([
backup_node1, # 首选后备
backup_node2, # 备选后备
final_fallback # 最后的保障
])这种设计特别适合处理不同类型的错误或异常情况,确保系统在各种条件下都能提供有意义的响应。
重试机制:处理临时故障
对于可能由于网络中断、服务暂时不可用等临时问题导致的失败,LCEL提供了重试机制:
python
# 创建带重试的链
retry_chain = (
network_dependent_node
.with_retry(
max_attempts=4, # 最多尝试4次(初始尝试+3次重试)
stop_after_attempt=4, # 4次尝试后停止
wait_exponential_jitter=True # 使用指数退避策略,避免同时重试
)
)生命周期管理
生命周期管理是指监控和控制节点从创建到销毁整个过程中的各个状态。在LCEL中,每个节点都有一系列生命周期事件,我们可以为这些事件注册回调函数,实现精细的控制和监控。
主要的生命周期事件包括:
- 启动事件(on_start):节点开始执行时触发
- 结束事件(on_end):节点执行完成时触发
- 错误事件(on_error) :节点执行出错时触发
LCEL提供了简洁的API来实现生命周期监听:
python
from langchain.schema.runnable import RunnableLambda
import time
# 定义一个简单的处理节点
def text_processor(seconds):
# 模拟耗时操作
time.sleep(seconds)
return seconds * 2
# 封装为节点
node = RunnableLambda(text_processor)
# 添加生命周期监听器
monitored_node = node.with_listeners(
on_start=lambda run_obj: print(f"节点启动时间: {run_obj.start_time}"),
on_end=lambda run_obj: print(f"节点结束时间: {run_obj.end_time}")
)
# 执行节点
result = monitored_node.invoke(2) # 将休眠2秒,然后返回4在这个例子中,我们为节点添加了两个监听器:一个在节点启动时记录时间,另一个在节点结束时记录时间。这使我们能够精确了解节点的执行持续时间。
历史记录管理
在选择历史记录存储方案时,有几种常见选择:
- 内存存储:简单快速,但存在容量限制。随着用户数量和并发请求的增加,内存占用会迅速增长。
- 磁盘存储:更为持久,通常是通过数据库实现。
对于生产环境,数据库存储是推荐的方案。数据可以存储在本地数据库(如SQLite)或远程服务器上,只需更改连接URL即可切换。
以下是一个使用SQLite实现历史记录管理的示例:
python
def get_session_history(session_id: str):
"""
根据会话ID来读取和保存历史记录
Args:
session_id: 会话的唯一标识符
Returns:
一个消息历史对象
"""
return SQLMessageHistory(
session_id=session_id,
connection_string="sqlite:///history.db"
)
result = chain.run_with_message_history(
{"input": "中国一共有哪些直辖市?"},
get_session_history,
config={"configurable": {"session_id": "user001"}}
)这个函数创建并返回一个SQLMessageHistory对象,该对象负责管理与特定会话ID相关的所有对话历史。
综合案例
串行链:餐厅推荐系统
用户输入需求
↓
需求分析与整理 → [展示整理后的结构化需求]
↓
餐厅推荐生成 → [展示3家符合条件的餐厅]核心价值:将用户非结构化输入转化为结构化决策流程,使整个推荐过程透明可见,帮助用户做出更明智的选择。
以下是一个餐厅推荐系统的设计,它展示了如何处理多步骤的复杂决策流程:
python
from langchain.chat_models import init_chat_model
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
api_key = "X"
api_base = "https://api.deepseek.com/"
llm = init_chat_model(
model="deepseek-chat",
api_key=api_key,
api_base=api_base,
temperature=0,
model_provider="deepseek",
)
# 创建处理用户需求的提示模板
requirement_analysis_prompt = PromptTemplate.from_template(
"""你是一位专业的需求分析师。请对以下用户输入的餐厅选择要求进行归纳总结,
提取关键点,并组织成有逻辑性的结构:
用户原始要求:{user_requirements}
请输出整理后的需求描述:"""
)
# 创建餐厅推荐的提示模板
restaurant_selection_prompt = PromptTemplate.from_template(
"""你是一位美食专家。根据以下用户的需求,推荐3家最符合条件的餐厅:
用户需求:{organized_requirements}
请列出3家餐厅的名称和简要描述:"""
)
# 使用管道操作符直接连接所有节点
restaurant_recommendation_chain = (
requirement_analysis_prompt | llm |
restaurant_selection_prompt | llm | StrOutputParser()
)
# 执行链的示例代码
if __name__ == "__main__":
result = restaurant_recommendation_chain.invoke(
{"user_requirements": "我想找一家餐厅,价格不能太贵,最好有素食选择,环境要安静一点,适合和朋友聊天,最好是亚洲菜系,我不太能吃辣。位置最好在市中心附近,因为我们坐公共交通。"
})
print(result)在这个复杂的推荐系统中,我们看到了几个重要的设计模式:
- 逐步细化处理:从用户的原始(可能混乱)需求开始,逐步进行分析、推荐和评估
- 数据传递与保留 :使用
RunnablePassthrough和Lambda函数确保关键数据在链中被正确传递 - 中间结果可视化:通过定制的处理函数展示每个步骤的输出,使整个流程透明可见
- 模块化设计:将复杂流程分解为可管理的组件,每个组件负责特定功能
动态链:智能选择问题模板
核心要点是创建模板不同,根据用户的输入信息AI判断应该属于什么类。再根据不同类用不同回答
bash
from langchain.chat_models import init_chat_model
from langchain.schema.output_parser import StrOutputParser
from langchain.prompts import PromptTemplate
from langchain.schema.runnable import RunnableLambda
from langchain_core.output_parsers import JsonOutputParser
api_key = "X"
api_base = "https://api.deepseek.com/"
llm = init_chat_model(
model="deepseek-chat",
api_key=api_key,
api_base=api_base,
temperature=0,
model_provider="deepseek",
)
# 定义各领域专用提示词模板
physics_template = PromptTemplate.from_template(
"你是一位物理学专家。请回答以下物理问题:\n\n{input}"
)
math_template = PromptTemplate.from_template(
"你是一位数学专家。请解答以下数学问题:\n\n{input}"
)
history_template = PromptTemplate.from_template(
"你是一位历史学家。请回答以下历史问题:\n\n{input}"
)
computer_science_template = PromptTemplate.from_template(
"你是一位计算机科学家。请回答以下计算机科学问题:\n\n{input}"
)
default_template = PromptTemplate.from_template(
"你输入的内容无法归类到特定领域。我将尽力回答:\n\n{input}"
)
# 定义各领域处理链
physics_chain = physics_template | llm
math_chain = math_template | llm
history_chain = history_template | llm
computer_science_chain = computer_science_template | llm
default_chain = default_template | llm
# 创建分类提示词
classification_prompt = PromptTemplate.from_template(
"""不要回答下面用户的问题,只要根据用户的输入来判断分类。
一共有物理、数学、历史、计算机、其他五种分类。
用户的输入是: {input}
输出格式为JSON,其中类别的key为"type",用户输入内容的key为"input"。
"""
)
# 创建路由函数
def router(input_data):
# 根据分类结果选择合适的处理链
question_type = input_data["type"]
if "物理" in question_type:
print("1号路由:物理问题")
return physics_chain
elif "数学" in question_type:
print("2号路由:数学问题")
return math_chain
elif "历史" in question_type:
print("3号路由:历史问题")
return history_chain
elif "计算机" in question_type:
print("4号路由:计算机问题")
return computer_science_chain
else:
print("5号路由:其他问题")
return default_chain
# 创建路由节点
router_node = RunnableLambda(router)
# 构建完整的智能体链
agent_chain = (
classification_prompt |
llm |JsonOutputParser()|router_node|
StrOutputParser()
)
# 测试智能体
test_questions = [
"什么是黑体辐射?",
"计算1+1的结果",
"第二次世界大战是什么时候爆发的?",
"解释什么是递归算法"
]
for input_question in test_questions:
result = agent_chain.invoke({"input":input_question})
print(f"问题:{input_question}")
print(f"回答:{result}\n")