目录
参考内容: 昇思MindSpore | 全场景AI框架 | 昇思MindSpore社区官网 华为自研的国产AI框架,训推一体,支持动态图、静态图,全场景适用,有着不错的生态
本项目可以在华为云modelart上租一个实例进行,也可以在配置至少为单卡3060的设备上进行
https://console.huaweicloud.com/modelarts/
Ascend环境也适用,但是注意修改device_target参数
需要本地编译器的一些代码传输、修改等可以勾上ssh远程开发
说明:项目使用的数据集来自华为云的数据资源。项目以深度学习任务构建的一般流程展开(数据导入、处理 > 模型选择、构建 > 模型训练 > 模型评估 > 模型优化)。
主线为'一般流程',同时代码中会标注出一些要点(# 要点1-1-1:设置使用的设备
)作为支线,帮助学习mindspore框架在进行深度学习任务时一些与pytorch的差异。
可以只看目录中带数字标签的部分来快速查阅代码。
本系列
MindSpore框架学习项目-ResNet药物分类-数据增强-CSDN博客
MindSpore框架学习项目-ResNet药物分类-构建模型-CSDN博客
MindSpore框架学习项目-ResNet药物分类-模型训练-CSDN博客
MindSpore框架学习项目-ResNet药物分类-模型评估-CSDN博客
MindSpore框架学习项目-ResNet药物分类-模型优化-CSDN博客
5 . 模型优化
5 . 1 模型优化
要求:
通过调整超参数,使得模型在测试集上评价指标acc高出超参调整之前(要点4-1-3输出结果)的5%及以上
此环节一般为深度学习任务在构建模型、探索可行性的最后阶段,用于尽可能地发掘模型适配任务的潜能,为落地部署做准备。需要往上复盘并结合从'模型构建'、'模型训练'到'模型推理'等环节的代码过程,进行参数的调优(优先从超参数入手)。
# 超参数`
`num_epochs =` `10` `# up`
`patience =` `5`
`lr = nn.cosine_decay_lr(min_lr=0.00001, max_lr=0.001, total_step=step_size_train * num_epochs,`
` step_per_epoch=step_size_train, decay_epoch=num_epochs)`
`# 要点3-1-1:定义优化器为Momentum优化器, 动量因子设置为0.9`
`# opt = nn.Momentum(params=network.trainable_params(), learning_rate=lr, momentum=0.9)`
`opt = nn.Adam(params=network.trainable_params(),learning_rate=lr)`
`# 要点3-1-2:定义损失函数为SoftmaxCrossEntropyWithLogits损失函数,sparse=True, reduction='mean'`
`loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')`
`model = ms.Model(network, loss_fn, opt, metrics={'acc'})`
`best_acc =` `0`
`best_ckpt_dir =` `"./BestCheckpoint"`
`best_ckpt_path =` `"./BestCheckpoint/resnet50-best.ckpt"`
`# train`
`def` `train_loop(model, dataset, loss_fn, optimizer):`
`# 要点3-1-3:模型编译:利用函数式编程实现loss的计算,并返回loss和模型预测值logits`
`def` `forward_fn(data, label):`
` logits = model(data)`
` loss = loss_fn(logits,label)`
`return loss, logits`
`# 要点3-1-4:利用value_and_grad API定义反向传播函数`
` grad_fn = ms.ops.value_and_grad(forward_fn,` `None, opt.parameters, has_aux=True)`
`def` `train_step(data, label):`
`(loss, _), grads = grad_fn(data, label)`
` loss = ops.depend(loss, optimizer(grads))`
`return loss`
` size = dataset.get_dataset_size()`
` model.set_train()`
`for batch,` `(data, label)` `in` `enumerate(dataset.create_tuple_iterator()):`
` loss = train_step(data, label)`
`if batch %` `100` `==` `0` `or batch == step_size_train -` `1:`
` loss, current = loss.asnumpy(), batch`
`print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")`
`# test`
`def` `test_loop(model, dataset, loss_fn):`
` num_batches = dataset.get_dataset_size()`
`# 要点3-1-5:设置模型为预测模式`
` model.set_train(False)`
` total, test_loss, correct =` `0,` `0,` `0`
` y_true =` `[]`
` y_pred =` `[]`
`for data, label in dataset.create_tuple_iterator():`
` y_true.extend(label.asnumpy().tolist())`
` pred = model(data)`
` total +=` `len(data)`
` test_loss += loss_fn(pred, label).asnumpy()`
` y_pred.extend(pred.argmax(1).asnumpy().tolist())`
` correct +=` `(pred.argmax(1)` `== label).asnumpy().sum()`
` test_loss /= num_batches`
` correct /= total`
`print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")`
`print(classification_report(y_true,y_pred,target_names=` `list(index_label_dict.values()),digits=3))`
`return correct,test_loss`
`# 重新训练`
`no_improvement_count =` `0`
`acc_list =` `[]`
`loss_list =` `[]`
`stop_epoch = num_epochs`
`for t in` `range(num_epochs):`
`print(f"Epoch {t+1}\n-------------------------------")`
` train_loop(network, dataset_train, loss_fn, opt)`
` acc,loss = test_loop(network, dataset_val, loss_fn)`
` acc_list.append(acc)`
` loss_list.append(loss)`
`# 要点3-2-1:设置条件:利用计算的acc指标,得到训练中得到的最优模型权重`
`if best_acc < acc:`
` best_acc = acc`
`if` `not os.path.exists(best_ckpt_dir):`
` os.mkdir(best_ckpt_dir)`
`# 要点3-2-2:利用save_checkpoint API对模型进行保存, 保存的路径为best_ckpt_path`
` ms.save_checkpoint(network,best_ckpt_path)`
` no_improvement_count =` `0`
`else:`
` no_improvement_count +=` `1`
`if no_improvement_count > patience:`
`print('Early stopping triggered. Restoring best weights...')`
` stop_epoch = t`
`break`
`print("Done!")`
`说明
对于模型调优,先从超参数入手,比如epoch、batch_size等,可以初步判断数据集的质量;再一定程度上acc有所提升后,如果遇到性能瓶颈(通过超参数已经不能让模型精度进一步提高,同时还达不到预期,那就考虑参数--网络结构、激活函数、损失函数等)
这里将epoch从3->10,新一轮训练后的第十轮结果:
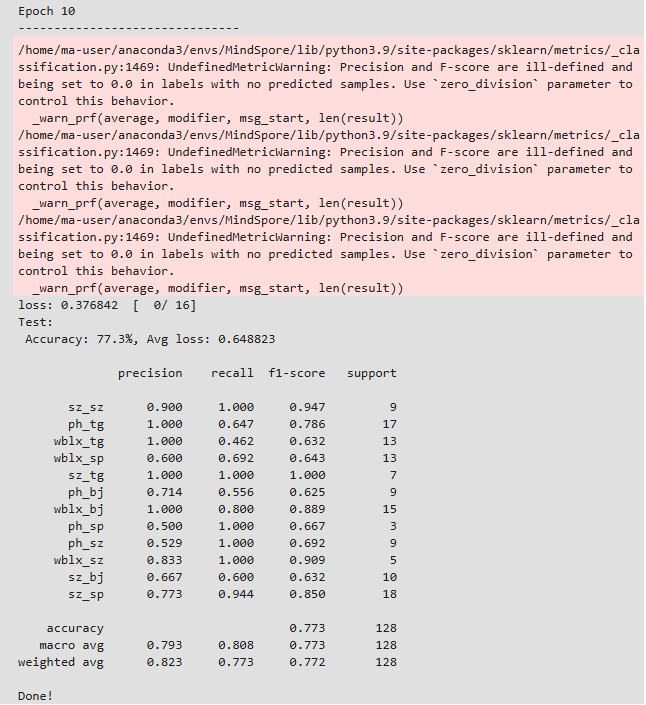
模型在性能上得到一定提升
复用前面的推理代码
# 重新加载模型 'BestCheckpoint/resnet50-best.ckpt'`
`num_class =` `12` `# `
`# 题目4-1-1:实例化resnet50 预测模型`
`net = resnet50(num_classes=num_class)`
`best_ckpt_path =` `'BestCheckpoint/resnet50-best.ckpt'`
`# 题目4-1-2:加载模型参数`
`# 将最优的一次检查点信息(模型-网络权重参数)加载到参数字典`
`param_dict = ms.load_checkpoint(best_ckpt_path)`
`# 将网络权重载入网络结构--模型网络结构里`
`ms.load_param_into_net(net,param_dict)`
`model = ms.Model(net)`
`image_size =` `224`
`workers =` `1`
`# acc`
`test_acc, _ = test_loop(net, dataset_test, loss_fn)`
`print(f'Test Accuracy:{test_acc*100:.2f}%')`
`本次:
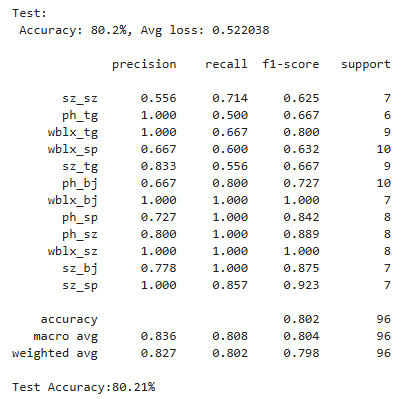
较上次:
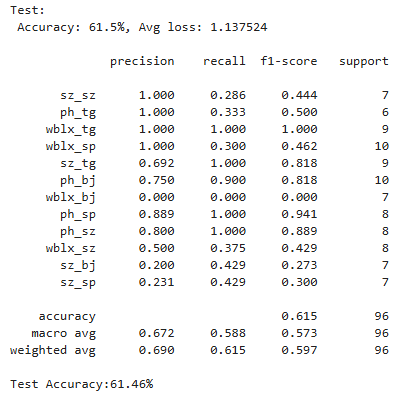
精度提升>5%
6.结语
通过这个用ResNet50进行对中药材的种类及品阶进行12分类的项目,学习mindspore AI框架的使用和深度学习任务的一般流程,熟悉如何通过深度学习的方式来拟合数据,处理生产生活中的问题,为AI赋能的时代贡献点滴实践。