本文将基于langgraph框架,用LLM查询NEO4J图数据库,构建可定制、能应对复杂场景的工作流!
🌟 核心亮点
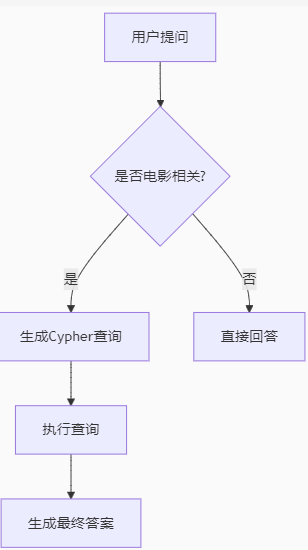
是否用户提问是否电影相关?生成Cypher查询直接回答执行查询生成最终答案
🧩 模块化实现
1️⃣ 定义状态机
from typing import TypedDict, Annotated, List
class InputState(TypedDict):
question: str
class OverallState(TypedDict):
question: str
next_action: str
cypher_statement: str
cypher_errors: List[str]
database_records: List[dict]
steps: Annotated[List[str], add]
class OutputState(TypedDict):
answer: str
steps: List[str]
cypher_statement: str2️⃣ 智能护栏系统
guardrails_system = """
你是智能助手,判断问题是否与电影相关。
相关则返回"movie",否则返回"end"。
"""
guardrails_prompt = ChatPromptTemplate.from_messages([
("system", guardrails_system),
("human", "{question}")
])
def guardrails(state: InputState) -> OverallState:
output = guardrails_chain.invoke({"question": state.get("question")})
if output.decision == "end":
return {"database_records": "问题与电影无关,无法回答"}
return {"next_action": output.decision, "steps": ["guardrail"]}3️⃣ Cypher生成引擎
示例增强提示:
examples = [
{"question": "汤姆·汉克斯演过多少电影?", "query": "MATCH (a:Person {name: 'Tom Hanks'})-[:ACTED_IN]->(m) RETURN count(m)"},
{"question": "《赌场》的演员有哪些?", "query": "MATCH (m:Movie {title: 'Casino'})<-[:ACTED_IN]-(a) RETURN a.name"}
]动态选择最相关示例:
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
OllamaEmbeddings(model="nomic-embed-text"),
Neo4jVector,
k=5
)4️⃣ 查询执行模块
def execute_cypher(state: OverallState) -> OverallState:
records = enhanced_graph.query(state.get("cypher_statement"))
return {
"database_records": records if records else "未找到相关信息",
"next_action": "end",
"steps": ["execute_cypher"],
}5️⃣ 最终回答生成
generate_final_prompt = ChatPromptTemplate.from_messages([
("system", "你是专业电影助手"),
("human", "根据数据库结果回答问题:\n结果: {results}\n问题: {question}")
])🧠 智能工作流构建
from langgraph.graph import StateGraph
# 构建流程图
workflow = StateGraph(OverallState)
workflow.add_node("guardrails", guardrails)
workflow.add_node("generate_cypher", generate_cypher)
workflow.add_node("execute_cypher", execute_cypher)
workflow.add_node("generate_final_answer", generate_final_answer)
# 设置路由逻辑
def route_decision(state):
return "generate_cypher" if state["next_action"] == "movie" else "generate_final_answer"
workflow.add_conditional_edges("guardrails", route_decision)
workflow.add_edge("generate_cypher", "execute_cypher")
workflow.add_edge("execute_cypher", "generate_final_answer")
workflow.add_edge("generate_final_answer", END)
# 编译执行
movie_expert = workflow.compile()🎯 实战演示
案例1:无关问题
ask("西班牙天气怎么样?")输出:
我无法回答电影以外的问题,建议查询天气网站。
案例2:电影查询
ask("电影《赌场》的演员有哪些?")输出:
《赌场》的主演包括:罗伯特·德尼罗、莎朗·斯通、乔·佩西等。
💡 方案优势
| 特性 | 传统方法 | LangGraph方案 |
|---|---|---|
| 定制性 | ❌ 受限 | ✅ 完全可定制 |
| 复杂度 | ⭐ 简单 | ⭐⭐⭐ 复杂场景 |
| 可维护性 | 🟡 一般 | 🟢 模块清晰 |
| 错误处理 | ⚠️ 基础 | 🛡️ 健壮机制 |
📦 资源获取
完整代码已开源:
文件命名与文章编号对应,方便查找!