作者:来自 Elastic Jeffrey Rengifo

讲解如何用 JavaScript 创建一个可用于生产环境的 Elasticsearch 后端。
想获得 Elastic 认证?看看下一期 Elasticsearch 工程师培训什么时候开始吧!
Elasticsearch 拥有大量新功能,能帮助你为你的使用场景构建最佳搜索解决方案。深入了解我们的示例笔记本、开始免费的云端试用,或者立即在本地机器上尝试 Elastic。
这是一个系列文章的第一篇,讲解如何在 JavaScript 中使用 Elasticsearch。在这个系列中,你将学习在 JavaScript 环境中使用 Elasticsearch 的基础知识,并了解创建搜索应用时最相关的功能和最佳实践。到最后,你将掌握使用 JavaScript 运行 Elasticsearch 所需的一切。
在第一部分中,我们将介绍:
- 环境设置
- 前端、后端还是无服务器架构?
- 连接客户端
- 文档索引
- Elasticsearch 客户端
- 语义映射
- 批量助手
- 数据搜索
- 词法查询
- 语义查询
- 混合查询
你可以在这里查看包含示例的源代码。
什么是 Elasticsearch Node.js 客户端?
Elasticsearch Node.js 客户端是一个 JavaScript 库,它将 Elasticsearch API 的 HTTP REST 调用封装成 JavaScript,使处理变得更简单,还提供了一些助手功能,方便执行像批量索引文档这样的任务。
更多阅读,请参阅文章 "Elasticsearch:使用最新的 Nodejs client 8.x 来创建索引并搜索"。
环境
前端、后端,还是无服务器?
为了使用 JavaScript 客户端创建搜索应用,我们至少需要两个组件:一个 Elasticsearch 集群和一个运行客户端的 JavaScript 运行时。
JavaScript 客户端支持所有 Elasticsearch 解决方案(云端、本地部署和无服务器),它在内部处理了各种差异,因此你不需要担心使用哪一种。
不过,JavaScript 运行时必须运行在服务器上,不能直接在浏览器中运行。
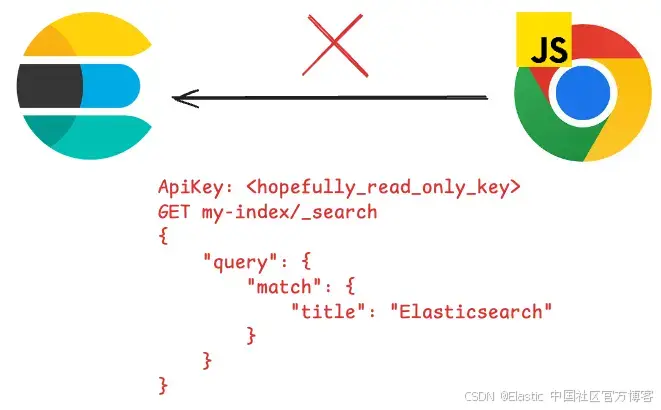
这是因为如果从浏览器直接调用 Elasticsearch,用户可能会获取敏感信息,比如集群的 API 密钥、主机地址或查询本身。Elasticsearch 建议绝不要将集群直接暴露在互联网上 ,而是使用一个中间层来屏蔽这些信息,让用户只能看到参数。你可以在这里阅读更多相关内容。
我们建议使用这样的架构:

在这种情况下,客户端只会发送搜索词和一个用于你服务器的认证密钥,而你的服务器将完全控制查询内容以及与 Elasticsearch 的通信。
连接客户端
首先按照这些步骤创建一个 API 密钥。
根据前面的示例,我们将创建一个简单的 Express 服务器,并通过一个 Node.js 服务器中的客户端与它连接。
我们将使用 NPM 初始化项目,并安装 Elasticsearch 客户端和 Express。Express 是一个在 Node.js 中搭建服务器的库。通过使用 Express,我们可以通过 HTTP 与后端进行交互。
让我们来初始化项目:
npm init -y安装依赖项:
npm install @elastic/elasticsearch express split2 dotenv让我为你拆解说明:
-
@elastic/elasticsearch:这是官方的 Node.js 客户端
-
express:允许我们快速搭建一个轻量级的 Node.js 服务器,用来暴露 Elasticsearch
-
split2:将文本按行拆分成流,便于我们逐行处理 ndjson 文件
-
dotenv:允许我们通过
.env文件管理环境变量
在项目根目录创建一个 .env 文件,并添加以下内容:
ELASTICSEARCH_ENDPOINT="Your Elasticsearch endpoint"
ELASTICSEARCH_API_KEY="Your Elasticssearch API"这样,我们可以使用 dotenv 包导入这些变量。
创建一个 server.js 文件:
const express = require("express");
const bodyParser = require("body-parser");
const { Client } = require("@elastic/elasticsearch");
require("dotenv").config(); //environment variables setup
const ELASTICSEARCH_ENDPOINT = process.env.ELASTICSEARCH_ENDPOINT;
const ELASTICSEARCH_API_KEY = process.env.ELASTICSEARCH_API_KEY;
const PORT = 3000;
const app = express();
app.listen(PORT, () => {
console.log("Server running on port", PORT);
});
app.use(bodyParser.json());
let esClient = new Client({
node: ELASTICSEARCH_ENDPOINT,
auth: { apiKey: ELASTICSEARCH_API_KEY },
});
app.get("/ping", async (req, res) => {
try {
const result = await esClient.info();
res.status(200).json({
success: true,
clusterInfo: result,
});
} catch (error) {
console.error("Error getting Elasticsearch info:", error);
res.status(500).json({
success: false,
clusterInfo: null,
error: error.message,
});
}
});这段代码搭建了一个基础的 Express.js 服务器,监听 3000 端口,并使用 API 密钥连接到 Elasticsearch 集群进行认证。它包含一个 /ping 端点,通过 GET 请求访问时,会使用 Elasticsearch 客户端的 .info() 方法查询集群的基本信息。
如果查询成功,会以 JSON 格式返回集群信息;否则返回错误信息。服务器还使用了 body-parser 中间件来处理 JSON 请求体。
运行该文件启动服务器:
node server.js答案应该是这样的:
Server running on port 3000现在,让我们访问 /ping 端点来检查 Elasticsearch 集群的状态。
curl http://localhost:3000/ping
{
"success": true,
"clusterInfo": {
"name": "instance-0000000000",
"cluster_name": "61b7e19eec204d59855f5e019acd2689",
"cluster_uuid": "BIfvfLM0RJWRK_bDCY5ldg",
"version": {
"number": "9.0.0",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "112859b85d50de2a7e63f73c8fc70b99eea24291",
"build_date": "2025-04-08T15:13:46.049795831Z",
"build_snapshot": false,
"lucene_version": "10.1.0",
"minimum_wire_compatibility_version": "8.18.0",
"minimum_index_compatibility_version": "8.0.0"
},
"tagline": "You Know, for Search"
}
}索引文档
连接成功后,我们可以使用像 semantic_text(语义搜索)和 text(全文查询)这样的映射来索引文档。通过这两种字段类型,我们还可以进行混合搜索(hybrid search)。
我们将创建一个新的 load.js 文件来生成映射并上传文档。
Elasticsearch 客户端
我们首先需要实例化并认证客户端:
const { Client } = require("@elastic/elasticsearch");
const ELASTICSEARCH_ENDPOINT = "cluster/project_endpoint";
const ELASTICSEARCH_API_KEY = "apiKey";
const esClient = new Client({
node: ELASTICSEARCH_ENDPOINT,
auth: { apiKey: ELASTICSEARCH_API_KEY },
});语义映射 - semantic mappings
我们将创建一个包含兽医医院数据的索引。存储的信息包括主人、宠物和就诊详情。
需要进行全文搜索的数据,如姓名和描述,将存为 text 类型。类别数据,如动物的种类或品种,将存为 keyword 类型。
此外,我们会将所有字段的值复制到一个 semantic_text 字段,以便也能针对这些信息进行语义搜索。
const INDEX_NAME = "vet-visits";
const createMappings = async (indexName, mapping) => {
try {
const body = await esClient.indices.create({
index: indexName,
body: {
mappings: mapping,
},
});
console.log("Index created successfully:", body);
} catch (error) {
console.error("Error creating mapping:", error);
}
};
await createMappings(INDEX_NAME, {
properties: {
owner_name: {
type: "text",
copy_to: "semantic_field",
},
pet_name: {
type: "text",
copy_to: "semantic_field",
},
species: {
type: "keyword",
copy_to: "semantic_field",
},
breed: {
type: "keyword",
copy_to: "semantic_field",
},
vaccination_history: {
type: "keyword",
copy_to: "semantic_field",
},
visit_details: {
type: "text",
copy_to: "semantic_field",
},
semantic_field: {
type: "semantic_text",
},
},
});批量助手 - bulk helper
客户端的另一个优势是可以使用批量助手(bulk helper)批量索引。批量助手方便处理并发、重试以及每个文档成功或失败时的处理方式。
这个助手的一个吸引人功能是支持流式处理。它允许你逐行发送文件,而不是将整个文件存入内存后一次性发送给 Elasticsearch。
要上传数据到 Elasticsearch,请在项目根目录创建一个名为 data.ndjson 的文件,并添加以下信息(或者,你也可以从这里下载包含数据集的文件):
{"owner_name":"Alice Johnson","pet_name":"Buddy","species":"Dog","breed":"Golden Retriever","vaccination_history":["Rabies","Parvovirus","Distemper"],"visit_details":"Annual check-up and nail trimming. Healthy and active."}
{"owner_name":"Marco Rivera","pet_name":"Milo","species":"Cat","breed":"Siamese","vaccination_history":["Rabies","Feline Leukemia"],"visit_details":"Slight eye irritation, prescribed eye drops."}
{"owner_name":"Sandra Lee","pet_name":"Pickles","species":"Guinea Pig","breed":"Mixed","vaccination_history":[],"visit_details":"Loss of appetite, recommended dietary changes."}
{"owner_name":"Jake Thompson","pet_name":"Luna","species":"Dog","breed":"Labrador Mix","vaccination_history":["Rabies","Bordetella"],"visit_details":"Mild ear infection, cleaning and antibiotics given."}
{"owner_name":"Emily Chen","pet_name":"Ziggy","species":"Cat","breed":"Mixed","vaccination_history":["Rabies","Feline Calicivirus"],"visit_details":"Vaccination update and routine physical."}
{"owner_name":"Tomás Herrera","pet_name":"Rex","species":"Dog","breed":"German Shepherd","vaccination_history":["Rabies","Parvovirus","Leptospirosis"],"visit_details":"Follow-up for previous leg strain, improving well."}
{"owner_name":"Nina Park","pet_name":"Coco","species":"Ferret","breed":"Mixed","vaccination_history":["Rabies"],"visit_details":"Slight weight loss; advised new diet."}
{"owner_name":"Leo Martínez","pet_name":"Simba","species":"Cat","breed":"Maine Coon","vaccination_history":["Rabies","Feline Panleukopenia"],"visit_details":"Dental cleaning. Minor tartar buildup removed."}
{"owner_name":"Rachel Green","pet_name":"Rocky","species":"Dog","breed":"Bulldog Mix","vaccination_history":["Rabies","Parvovirus"],"visit_details":"Skin rash, antihistamines prescribed."}
{"owner_name":"Daniel Kim","pet_name":"Mochi","species":"Rabbit","breed":"Mixed","vaccination_history":[],"visit_details":"Nail trimming and general health check. No issues."}我们使用 split2 来流式读取文件的每一行,同时批量助手将它们发送到 Elasticsearch。
const { createReadStream } = require("fs");
const split = require("split2");
const indexData = async (filePath, indexName) => {
try {
console.log(`Indexing data from ${filePath} into ${indexName}...`);
const result = await esClient.helpers.bulk({
datasource: createReadStream(filePath).pipe(split()),
onDocument: () => {
return {
index: { _index: indexName },
};
},
onDrop(doc) {
console.error("Error processing document:", doc);
},
});
console.log("Bulk indexing successful elements:", result.items.length);
} catch (error) {
console.error("Error indexing data:", error);
throw error;
}
};
await indexData("./data.ndjson", INDEX_NAME);上面的代码逐行读取 .ndjson 文件,并使用 helpers.bulk 方法批量将每个 JSON 对象索引到指定的 Elasticsearch 索引中。它通过 createReadStream 和 split2 流式读取文件,为每个文档设置索引元数据,并记录处理失败的文档。完成后,会输出成功索引的条目数量。
除了使用 indexData 函数,你也可以通过 Kibana 的 UI 直接上传文件,使用上传数据文件的界面。
我们运行该文件,将文档上传到 Elasticsearch 集群。
node load.js
Creating mappings for index vet-visits...
Index created successfully: { acknowledged: true, shards_acknowledged: true, index: 'vet-visits' }
Indexing data from ./data.ndjson into vet-visits...
Bulk indexing completed. Total documents: 10, Failed: 0搜索数据
回到我们的 server.js 文件,我们将创建不同的端点来执行词法搜索、语义搜索或混合搜索。
简而言之,这些搜索类型不是互斥的,而是取决于你需要回答的问题类型。
| Query type | Use case | Example question |
|---|---|---|
| 词汇搜索 | 问题中的词或词根很可能出现在索引文档中。问题和文档之间的词元相似度。 | I'm looking for a blue sport t-shirt. |
| 语义搜索 | 问题中的词不太可能出现在文档中。问题和文档之间的概念相似度。 | I'm looking for clothing for cold weather. |
| 混合搜索 | 问题包含词法和/或语义成分。问题和文档之间的词元相似度和语义相似度。 | I'm looking for an S size dress for a beach wedding. |
问题的词汇部分很可能是标题、描述或类别名称的一部分,而语义部分是与这些字段相关的概念。Blue 很可能是类别名称或描述的一部分,而 beach wedding 可能不是,但可以与 linen clothing 在语义上相关。
Lexical query (/search/lexic?q=<query_term>)
词法搜索,也叫全文搜索,指的是基于词元相似度的搜索;也就是说,经过分析后,包含搜索词元的文档会被返回。
你可以在这里查看我们的词法搜索实操教程。
app.get("/search/lexic", async (req, res) => {
const { q } = req.query;
const INDEX_NAME = "vet-visits";
try {
const result = await esClient.search({
index: INDEX_NAME,
size: 5,
body: {
query: {
multi_match: {
query: q,
fields: ["owner_name", "pet_name", "visit_details"],
},
},
},
});
res.status(200).json({
success: true,
results: result.hits.hits
});
} catch (error) {
console.error("Error performing search:", error);
res.status(500).json({
success: false,
results: null,
error: error.message,
});
}
});我们用 "nail trimming" 测试。
curl http://localhost:3000/search/lexic?q=nail%20trimming答案:
{
"success": true,
"results": [
{
"_index": "vet-visits",
"_id": "-RY6RJYBLe2GoFQ6-9n9",
"_score": 2.7075968,
"_source": {
"pet_name": "Mochi",
"owner_name": "Daniel Kim",
"species": "Rabbit",
"visit_details": "Nail trimming and general health check. No issues.",
"breed": "Mixed",
"vaccination_history": []
}
},
{
"_index": "vet-visits",
"_id": "8BY6RJYBLe2GoFQ6-9n9",
"_score": 2.560356,
"_source": {
"pet_name": "Buddy",
"owner_name": "Alice Johnson",
"species": "Dog",
"visit_details": "Annual check-up and nail trimming. Healthy and active.",
"breed": "Golden Retriever",
"vaccination_history": [
"Rabies",
"Parvovirus",
"Distemper"
]
}
}
]
}Semantic query (/search/semantic?q=<query_term>)
语义搜索不同于词法搜索,它通过向量搜索找到与搜索词含义相似的结果。
你可以在这里查看我们的语义搜索实操教程。
app.get("/search/semantic", async (req, res) => {
const { q } = req.query;
const INDEX_NAME = "vet-visits";
try {
const result = await esClient.search({
index: INDEX_NAME,
size: 5,
body: {
query: {
semantic: {
field: "semantic_field",
query: q
},
},
},
});
res.status(200).json({
success: true,
results: result.hits.hits,
});
} catch (error) {
console.error("Error performing search:", error);
res.status(500).json({
success: false,
results: null,
error: error.message,
});
}
});我们用 "Who got a pedicure?" 测试。
curl http://localhost:3000/search/semantic?q=Who%20got%20a%20pedicure?答案:
{
"success": true,
"results": [
{
"_index": "vet-visits",
"_id": "-RY6RJYBLe2GoFQ6-9n9",
"_score": 4.861466,
"_source": {
"owner_name": "Daniel Kim",
"pet_name": "Mochi",
"species": "Rabbit",
"breed": "Mixed",
"vaccination_history": [],
"visit_details": "Nail trimming and general health check. No issues."
}
},
{
"_index": "vet-visits",
"_id": "8BY6RJYBLe2GoFQ6-9n9",
"_score": 4.7152824,
"_source": {
"pet_name": "Buddy",
"owner_name": "Alice Johnson",
"species": "Dog",
"visit_details": "Annual check-up and nail trimming. Healthy and active.",
"breed": "Golden Retriever",
"vaccination_history": [
"Rabies",
"Parvovirus",
"Distemper"
]
}
},
{
"_index": "vet-visits",
"_id": "9RY6RJYBLe2GoFQ6-9n9",
"_score": 1.6717153,
"_source": {
"pet_name": "Rex",
"owner_name": "Tomás Herrera",
"species": "Dog",
"visit_details": "Follow-up for previous leg strain, improving well.",
"breed": "German Shepherd",
"vaccination_history": [
"Rabies",
"Parvovirus",
"Leptospirosis"
]
}
},
{
"_index": "vet-visits",
"_id": "9xY6RJYBLe2GoFQ6-9n9",
"_score": 1.5600781,
"_source": {
"pet_name": "Simba",
"owner_name": "Leo Martínez",
"species": "Cat",
"visit_details": "Dental cleaning. Minor tartar buildup removed.",
"breed": "Maine Coon",
"vaccination_history": [
"Rabies",
"Feline Panleukopenia"
]
}
},
{
"_index": "vet-visits",
"_id": "-BY6RJYBLe2GoFQ6-9n9",
"_score": 1.2696637,
"_source": {
"pet_name": "Rocky",
"owner_name": "Rachel Green",
"species": "Dog",
"visit_details": "Skin rash, antihistamines prescribed.",
"breed": "Bulldog Mix",
"vaccination_history": [
"Rabies",
"Parvovirus"
]
}
}
]
}Hybrid query (/search/hybrid?q=<query_term>)
混合搜索允许我们结合语义搜索和词法搜索,从而兼得两者优势:既有基于词元搜索的精准度,也有语义搜索的意义接近性。
app.get("/search/hybrid", async (req, res) => {
const { q } = req.query;
const INDEX_NAME = "vet-visits";
try {
const result = await esClient.search({
index: INDEX_NAME,
body: {
retriever: {
rrf: {
retrievers: [
{
standard: {
query: {
bool: {
must: {
multi_match: {
query: q,
fields: ["owner_name", "pet_name", "visit_details"],
},
},
},
},
},
},
{
standard: {
query: {
bool: {
must: {
semantic: {
field: "semantic_field",
query: q,
},
},
},
},
},
},
],
},
},
size: 5,
},
});
res.status(200).json({
success: true,
results: result.hits.hits,
});
} catch (error) {
console.error("Error performing search:", error);
res.status(500).json({
success: false,
results: null,
error: error.message,
});
}
});我们用 "Who got a pedicure or dental treatment?" 测试。
curl http://localhost:3000/search/hybrid?q=who%20got%20a%20pedicure%20or%20dental%20treatment答案:
{
"success": true,
"results": [
{
"_index": "vet-visits",
"_id": "9xY6RJYBLe2GoFQ6-9n9",
"_score": 0.032522473,
"_source": {
"pet_name": "Simba",
"owner_name": "Leo Martínez",
"species": "Cat",
"visit_details": "Dental cleaning. Minor tartar buildup removed.",
"breed": "Maine Coon",
"vaccination_history": [
"Rabies",
"Feline Panleukopenia"
]
}
},
{
"_index": "vet-visits",
"_id": "-RY6RJYBLe2GoFQ6-9n9",
"_score": 0.016393442,
"_source": {
"pet_name": "Mochi",
"owner_name": "Daniel Kim",
"species": "Rabbit",
"visit_details": "Nail trimming and general health check. No issues.",
"breed": "Mixed",
"vaccination_history": []
}
},
{
"_index": "vet-visits",
"_id": "8BY6RJYBLe2GoFQ6-9n9",
"_score": 0.015873017,
"_source": {
"pet_name": "Buddy",
"owner_name": "Alice Johnson",
"species": "Dog",
"visit_details": "Annual check-up and nail trimming. Healthy and active.",
"breed": "Golden Retriever",
"vaccination_history": [
"Rabies",
"Parvovirus",
"Distemper"
]
}
},
{
"_index": "vet-visits",
"_id": "9RY6RJYBLe2GoFQ6-9n9",
"_score": 0.015625,
"_source": {
"pet_name": "Rex",
"owner_name": "Tomás Herrera",
"species": "Dog",
"visit_details": "Follow-up for previous leg strain, improving well.",
"breed": "German Shepherd",
"vaccination_history": [
"Rabies",
"Parvovirus",
"Leptospirosis"
]
}
},
{
"_index": "vet-visits",
"_id": "8xY6RJYBLe2GoFQ6-9n9",
"_score": 0.015384615,
"_source": {
"pet_name": "Luna",
"owner_name": "Jake Thompson",
"species": "Dog",
"visit_details": "Mild ear infection, cleaning and antibiotics given.",
"breed": "Labrador Mix",
"vaccination_history": [
"Rabies",
"Bordetella"
]
}
}
]
}总结
在本系列的第一部分中,我们讲解了如何搭建环境并创建带有不同搜索端点的服务器,以按照客户端/服务器的最佳实践查询 Elasticsearch 文档。敬请期待第二部分,你将学习生产环境的最佳实践以及如何在无服务器环境中运行 Elasticsearch Node.js 客户端。
原文:https://www.elastic.co/search-labs/blog/how-to-use-elasticsearch-in-javascript-part-i